Implementation of MSTDP and MSTDPET #217
Comments
|
Yeah, we haven't really been able to get MSTDP or MSTDPET to work on anything, and we aren't actively working on it. If you can fix it and demonstrate that it works on some task, that would be a big win for anyone who wants to use BindsNET with reward-modulated learning rules. |
|
Ok so far I've managed to replicate Figure 1 from Florian 2007 (see https://gist.github.com/Huizerd/3dc3bfa79cfb721aea491b94dc04efa7). So the code for the learning rules seems to be right, at least. Now I'm replicating one of his experiments, however he uses connections between two layers of neurons where half of the weights are negatively bounded (inhibitory) and half of them are positively bounded (excitatory). Is there a way I could implement this with BindsNET? |
|
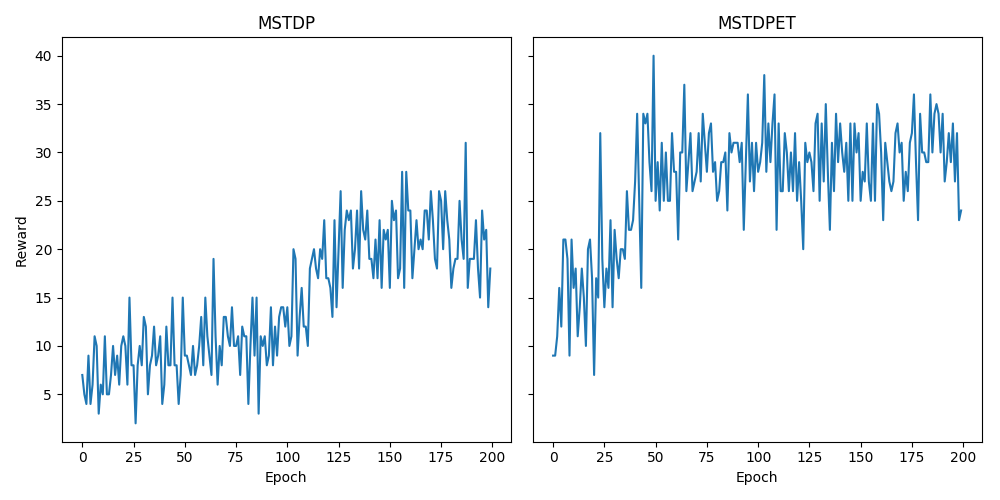
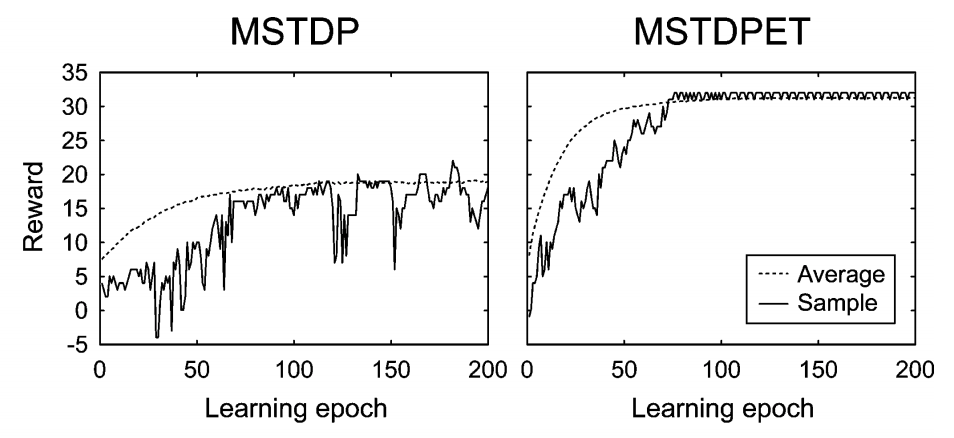
I implemented experiment 4.3 from the paper by R. Florian, see the code here: https://gist.github.com/Huizerd/9c794260e629613b66750043d583a1a2 and the modifications to BindsNET needed here: master...Huizerd:mstdp. It resulted in the following learning curves:
Which show similar patterns to those in the paper:
The code is still very rough, as I first wanted to hear your opinions. If all is well, I will make it all nice and compatible and do a PR! Note that I also made some changes to the LIF neuron to make it more similar to the one used in the paper. |
|
Really impressive work!
You can create two connections, one negatively bounded and the other positively bounded. You could also implement this feature within BindsNET: for each weight, include a
Yes, I think the correct MSTDP and MSTDPET algorithms would be an awesome addition to the library! Maybe create a new Do you have plans to write a paper on this? Seems like there's a lot of interesting applications of this method. I'm open to collaboration 😃 |
|
Hi everyone, Take a look at my branch devdhar-master. https://github.com/Hananel-Hazan/bindsnet/blob/devdhar-master/examples/XOR/mstdp.py I have made similar changes to MSTDP method. Not the MSTDP-ET method though. The wmin and wmax feature has been implemented in that branch. 5e990f7 |
|
Since @Huizerd has fixes for both methods, I think a PR from his branch would be preferable. You could make a PR against his (once it's made) if you want to propose changes to his implementation. |
|
I meant the wmax wmin update since it is not done by @Huizerd and would be easier for him to implement his experiments. In terms of implementing the experiments on Bindsnet there is also the question of handling the reward for each step. The reward can be different for each timestep. How are we planning to implement that? The fix I have is that I pass the desired output to the network.run function and the reward is calculated depending on the output during each step. |
I'm not sure what you mean by this, can you explain / link me to the implementation?
We could pass in a reference to a reward function. In the constructor of a reward-modulated learning rule, we could pass in a reward function that takes |
|
In this commit: 5e990f7 I have implemented what you said:
I have also modified the network.run to accept the desired output and calculate the reward based on that. Basically in the Florian experiments, reward is given when the output neuron either spikes or does not spike. Therefore, you can only know the reward while simulating. |
|
@dee0512 I made some comments on your commit, to help me understand some things. |
I think something like this is preferred, however a reward function that accepts The approach by @dee0512 modifies the I calculated the reward inside the loop where but I think @djsaunde's way (or something analogous to it) is the cleanest solution. |
|
Also, if we can't come up with a universal solution (so to speak), you could simply sub-class This is essentially what is being done in @dee0512 's approach, except in the base |
|
I don't see the problem by having two run methods. It should simplify the use, one for situation where the reward already been known (or simple inference) and other for RL learning where the reward been calculated base on the activity and desired output. |
I'm currently working on reward-modulated STDP, and noticed that there are some discrepancies between the Florian 2007 paper and your MSTDP(ET) implementation. This was already mentioned in #140 and fixed (it seems) in #141, however these changes were reverted in #165. Was this intentional? I was planning on fixing everything with some PRs, but if there are reasons why you wouldn't want the original paper implementation in BindsNET and thus reverted the fixes, I would like to know 😄
The text was updated successfully, but these errors were encountered: