Allow for concurrent queries form a single BlazingContext #1290
Comments
current api should definitely not change, theres no reason to keep using the .sql() api for different things thats not intuitive. |
|
From the ‘clarity’ of API point of view — I think I like API A. It's clear and doesn't introduce new concepts like |
after receving clarifying remarks this is equivalent to Option A |
|
Oh, now I see... Here's how I would make it a bit clearer to me (purely naming) query0 = 'SELECT * FROM my_table where columnA > 0'
query1 = 'SELECT * FROM my_table where columnB < 0'
queryId_0 = bc.sql(query0, async=True)
queryId_1 = bc.sql(query1, async=True)
result0 = bc.fetch(queryId_0)
result1 = bc.fetch(queryId_1) |
|
Python has syntax for async workflows. If a function returns a coroutine object: async def Foo():
return ...some_future_object
result = await Foo()So, API C can be used in simple way writing: result = await bc.sql(query, async=True) # where bs.sql returns the future objectAnd the same API can be used (no await statement) routine = bc.sql(query, async=True)
if routine.cr_running is False:
# the routine is still runningi.e., python has its own API to get information about async functions. |
|
@gcca How we handle multiple queries at the same time is very dependant on our engine and a little on dask. I dont think we would want to use the coroutine class. But what you are saying here makes me think that we should not use the word |
|
@williamBlazing would this method be the way to handle multiple queries without using BCs in multiple threads? Eg If you wanted to build a "server" that would serve bsql queries, then the server main function would create 1 global BC then enter a loop forever. The loop will: check if there is a query request, run BC.sql() async, check if it's ready, keep looping and serve other queries, when a query is finished return results, keep looping. Is there a reason you can't just support multi threads and BC? |
|
@chardog I do this right now by having some mechanism for locking the conversion of sql to relational algebra or converting the algebra before hand. The only thing preventing you from running multiple queries at the same time WITHOUT dask is actually just the way we leveraged calcite. I have added a comment about this to my review of this PR #1289 So an option before this pr is something like this What is happening here is that instead of sending it bc.sql a query to be parsed and then run, you are instead parsing the query in one step and running it in another. The lock ensures only one thread is converting a query to algebra at a time. Everything else should work from multiple threads without dask. The PR mentioned above will resolve both the issue mentioned here so that you can access bc and run .sql from multiple threads either by implementing the lock inside the query or by making it so that we actually have a pool of planners initialized. We do not want to create a planner every time we run a query because this can take dozens of milliseconds. |
|
Thanks @felipeblazing . Can you please clarify one sentence you wrote. Where you used the word "WITHOUT" in uppercase, I'm confused with that sentence. Thanks |
|
@felipeblazing I found with threads that the BC fails on the .sql() and the .explain() functions. The failure is a Java failure. |
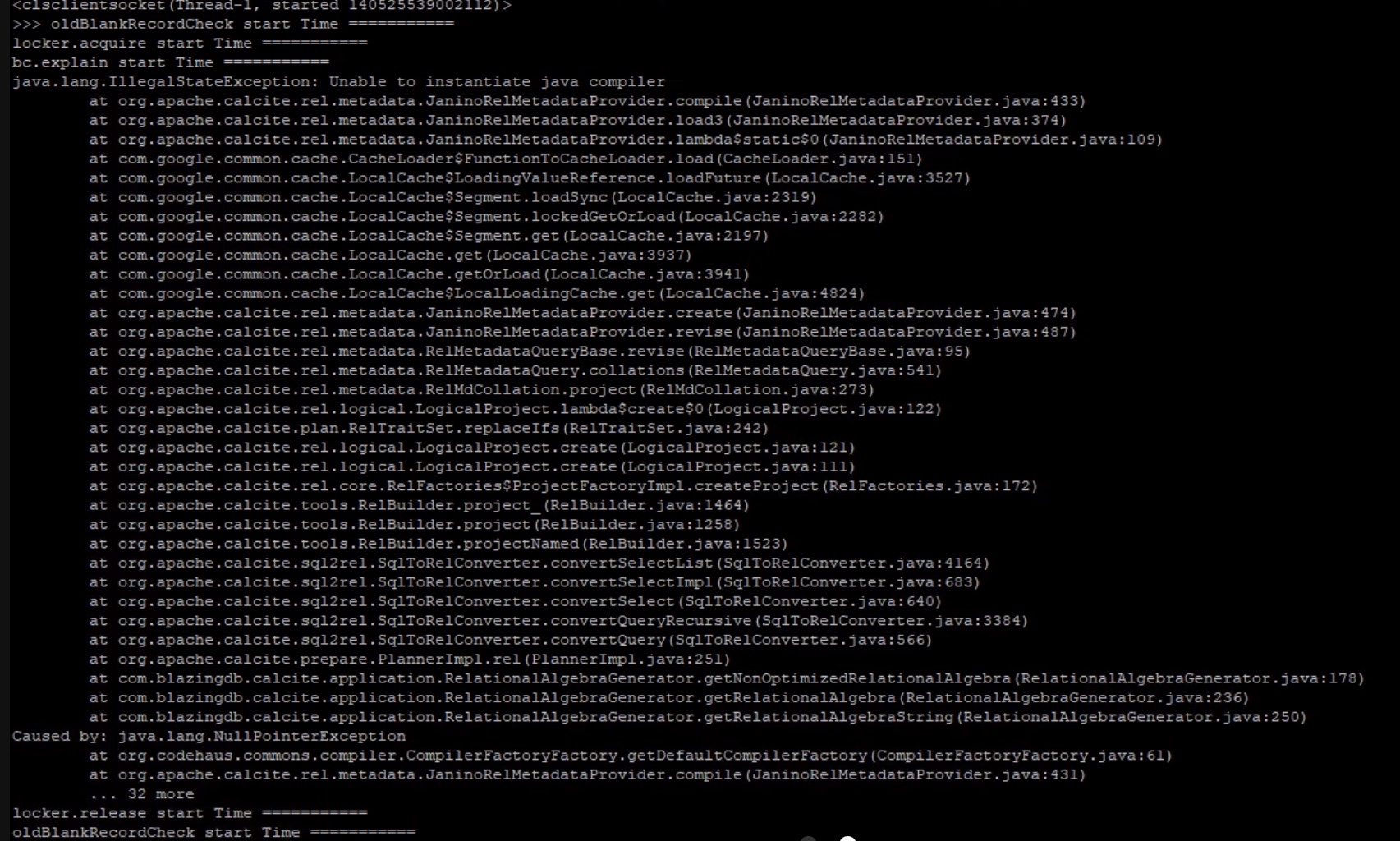
|
Sample code to reproduce Java problem above inside the thread: |
|
When I run the script on Blazingsql.com JupyterLab server with the latest build I get a different error to the java error that I get on my system: |

Sorry, I think i had a copy paste error there. I edited it. |
|
@chardog one thing william noticed is that if you don't call a bc.explain() at least once time in the main thread before calling threading it seems to always fail. Can you try this and see if that fixes it? The issue you are describing here is a failed calcite parsing. That being said I would not recommend performing any DML type operations like create_table outside of the main thread. |
|
@felipeblazing I think the java path error I have may not be related. Do you think the java path error when I use BC inside a thread has something to do with my environment variables? (I don't know why or if they would change in a thread vs outside a thread) |
|
The error you are seeing is the one that happens when bc.explain() is failing. If you were to change bc.sql to bc.explain you would see the error more closely. |
|
@felipeblazing running bc.explain() one time in the main() first made the bc.explain() inside the thread start working, as well as the bc.sql() in the thread. Nice. Is there a reason you recommend I not load a table in the thread? What if I use a locker around the table load in the thread? Does the PR William is working on have any affect when you use Dask + BC together with multiple workers ? Or is it only related to BC standalone? |
This is the API we will go with. It seems like this is what everyone likes the most. Its the Option A stated above, with the addition of a |
|
As part of implementing this feature, we need to add E2E tests that run multiple queries simulatenously. Additionally, we need to thoroughly test to make sure we dont have issues from Calcite and Java when trying to generate multiple relational algebra plans simulatenously. I think there is already a lock in place. We should double check |
Right now when you do:
bc.sql()execution on the python script halts until that function call returns when the function returns with the result of the query.You used to be able to use the option
return_futuresbut that feature is now obsolete due to #1289On the other hand #1289 makes it easy to implement multiple concurrent queries.
This feature request is to propose an API and user experience for multiple concurrent queries support from a single BlazingContext.
The proposed API would be something as follows:
Proposed API A
In this case
token0andtoken1would be int32s which are actually just the queryId.In this case
bc.fetchwould halt execution until the results are available.We would also implement a function (which would be optional) that would look like this:
done = bc.is_query_done(token0)which would return a boolean, simply indicating if the query is done.
Other ways we could do this are:
Proposed API B:
Proposed API C:
Feel free to propose other APIs.
This internally, this would just use the APIs that are now part of #1289, which allow us to start a query, check its status and get the results. Internally what happens is that when multiple queries are running at the same time is that each query has its own graph, and each graph is generating compute tasks. The compute tasks are then processed by the executor as resources allow. Right now the tasks would be processed FIFO (with a certain amount of parallelism depending on resources and configuration). Eventually we can set prioritization policies for which tasks get done first. For example tasks from the first query to start are given priority, or tasks which are most likely to reduce memory pressure are prioritized, etc...
The text was updated successfully, but these errors were encountered: