
在5月18日谷歌在I/O开发者大会上宣布,将Kotlin语言作为安卓开发的一级编程语言。并且会在Android Studio 3.0版本全面支持Kotlin。
Kotlin是一个基于JVM的新的编程语言,由JetBrains开发。JetBrains作为目前广受欢迎的Java IDE IntelliJ的提供商,在Apache许可下已经开源其Kotlin编程语言。Kotlin可以编译成Java字节码,也可以编译成JavaScript,方便在没有JVM的设备上运行。Kotlin已正式成为Android官方开发语言。
JetBrains这家公司非常牛逼,开发了很多著名的软件,他们在使用Java的过程中发现java比较笨重不方便,所以就开发了kotlin,kotlin是
一种全栈的开发语言,可以用它进行开发web、web后端、Android等。
但是JetBrains团队设计Kotlin所要面临的第一个问题就是必须兼容他们所拥有的数百万行Java代码库,这也代表了Kotlin基于整个Java社区所承载的使命之一,
即需要与现有的Java代码完全兼容。这个背景也决定了Kotlin的核心目标--为Java程序员提供一门更好的编程语言。
很多开发者都说Google学什么不好,非要学苹果,出个android的swift版本,一定会搞不起来没人用,所以不用浪费时间去学习。在这里想引用马云
的一句话:
拥抱变化
Google做事,向来言出必行,之前在推行Android Studio时也是一片骂声,吐槽各种不好用,各种慢。但是现在Android Studio基本都已经普及了。
我相信Kotlin也不会例外。所以我们不仅要学,还要要认真的学。
- 它更加易表现:这是它最重要的优点之一。你可以编写少得多的代码。
Kotlin是一种兼容Java的语言Kotlin比Java更安全,能够静态检测常见的陷阱。如:引用空指针Kotlin比Java更简洁,通过支持variable type inference,higher-order functions (closures),extension functions,mixins and first-class delegation等实现Kotlin可与Java语言无缝通信。这意味着我们可以在Kotlin代码中使用任何已有的Java库;同样的Kotlin代码还可以为Java代码所用Kotlin在代码中很少需要在代码中指定类型,因为编译器可以在绝大多数情况下推断出变量或是函数返回值的类型。这样就能获得两个好处:简洁与安全Kotlin是一种静态类型的语言。这意味着,类型将在编译时解析且从不改变
- 全面支持
Lambda表达式 - 数据类
Data classes - 函数字面量和内联函数
Function literals & inline functions - 函数扩展
Extension functions - 空安全
Null safety - 智能转换
Smart casts - 字符串模板
String templates - 主构造函数
Primary constructors - 类委托
Class delegation - 类型推判
Type inference - 单例
Singletons - 声明点变量
Declaration-site variance - 区间表达式
Range expressions
上面说简洁简洁,到底简洁在哪里?这里先用一个例子开始,在Java开发过程中经常会写一些Bean类:
package com.charon.kotlinstudydemo;
public class Person {
private int age;
private String name;
private float height;
private float weight;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public float getHeight() {
return height;
}
public void setHeight(float height) {
this.height = height;
}
public float getWeight() {
return weight;
}
public void setWeight(float weight) {
this.weight = weight;
}
@Override
public String toString() {
return "Person name is : " + name + " age is : " + age + " height is :"
+ height + " weight is :" + weight;
}
}使用Kotlin:
package com.charon.kotlinstudydemo
data class Person(
var name: String,
var age: Int,
var height: Float,
var weight: Float)这个数据类,它会自动生成所有属性和它们的访问器,以及一些有用的方法,比如toString()方法。
这里插一嘴,从上面的例子中我们可以看到对于包的声明基本是一样的,唯一不同的是kotlin中后面结束不用分号。
Google宣布在Android Studio 3.0版本会全面支持Kotlin,
直接通过New Project创建就可以,与创建普通Java项目唯一不同的是要勾选Include Kotlin support的选项。
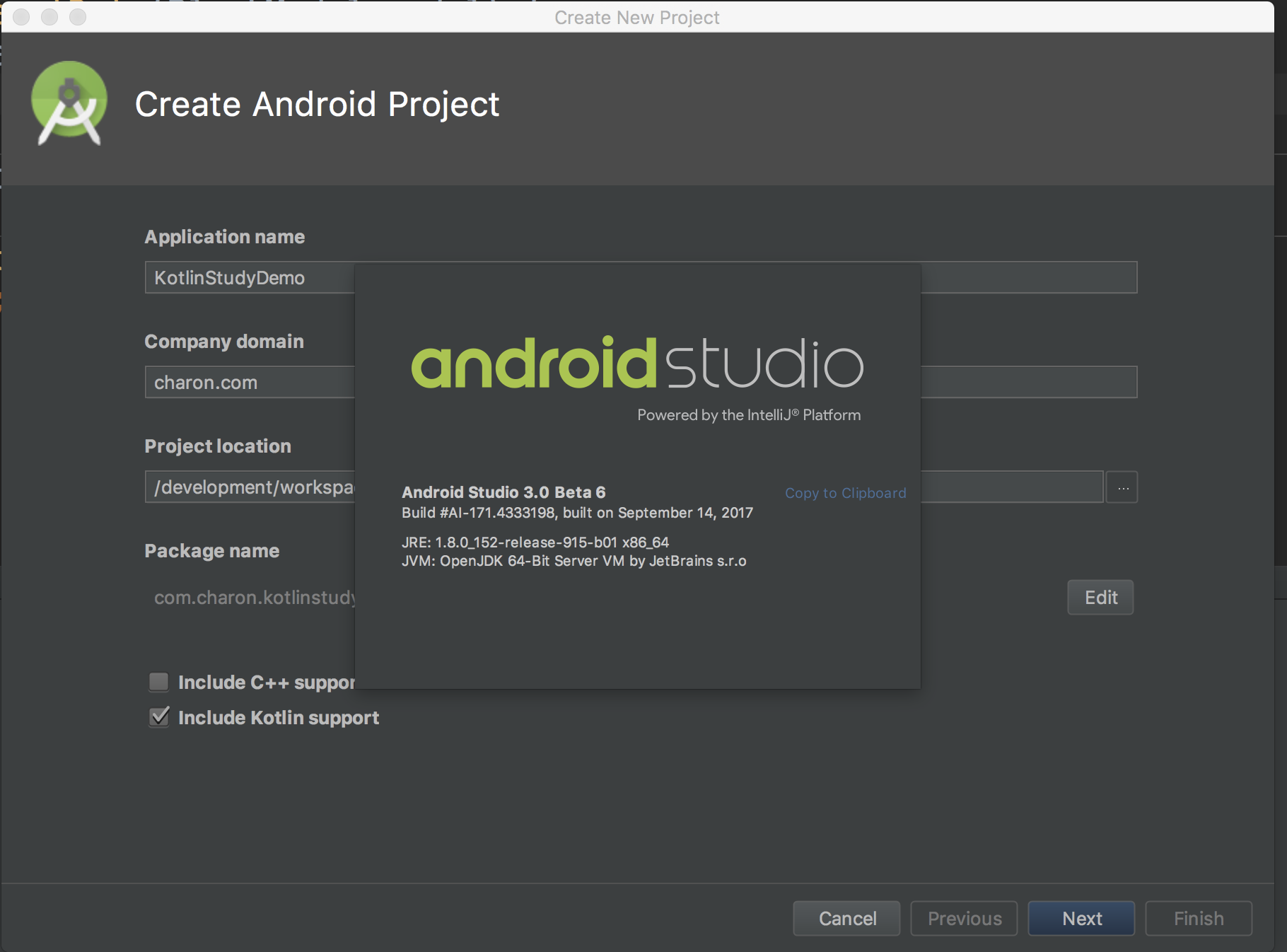
创建完成后我们看一下MainActivity的代码:
// 定义包
package com.charon.kotlinstudydemo
// 导入
import android.support.v7.app.AppCompatActivity
import android.os.Bundle
// 定义类,继承AppCompatActivity
class MainActivity : AppCompatActivity() {
// 重写方法用overide,函数名用fun声明 参数是a: 类型的形式 ?是啥?它是指明该对象可能为null,
// 如果有了?那在调用该方法的时候参数可以传递null进入,如果没有?传递null就会报错
override fun onCreate(savedInstanceState: Bundle?) {
// super
super.onCreate(savedInstanceState)
// 调用方法
setContentView(R.layout.activity_main)
}
}变量可以很简单地定义成可变var(可读可写)和不可变val(只读)的变量。如果var代表了variable(变量),那么val可看成value(值)的缩写,
但是也有人觉得这样并不直观或准确,而是把val解释成variable+final,即通过val声明的变量具有Java中的final关键字的
效果(我们通过查看对val语法反编译后转化的java代码,从中可以很清楚的发现它是用final实现的),也就是引用不可变。
因此,val声明的变量是只读变量,它的引用不可更改,但并不代表其引用对象也不可变。事实上,我们依然可以修改引用对象的可变成员。
声明:
var age: Int = 18
val name: String = "charon"
val book = Book("Thinking in Java") // 用val声明的book对象的引用不可变
book.name = "Diving into Kotlin"
book.printName() // Diving into Kotlin再提示一下:kotlin中每行代码结束不需要分号了,不要和java是的每行都带分号
字面上可以写明具体的类型。这个不是必须的,但是一个通用的Kotlin实践是省略变量的类型我们可以让编译器自己去推断出具体的类型,
Kotlin拥有比Java更加强大的类型推导功能,这避免了静态类型语言在编码时需要书写大量类型的弊端:
var age = 18 // int
val name = "charon" // string
var height = 180.5f // flat
var weight = 70.5 // double在Kotlin中,一切都是对象。没有像Java中那样的原始基本类型。
当然,像Integer,Float或者Boolean等类型仍然存在,但是它们全部都会作为对象存在的。基本类型的名字和它们工作方式都是与Java非常相似的,
但是有一些不同之处你可能需要考虑到:
-
数字类型中不会自动转型。举个例子,你不能给
Double变量分配一个Int。必须要做一个明确的类型转换,可以使用众多的函数之一:private var age = 18 private var weight = age.toFloat()
-
字符(
Char)不能直接作为一个数字来处理。在需要时我们需要把他们转换为一个数字:val c: Char='c' val i: Int = c.toInt()
-
位运算也有一点不同。在
Android中,我们经常在flags中使用或:// Java int bitwiseOr = FLAG1 | FLAG2; int bitwiseAnd = FLAG1 & FLAG2;
// Kotlin val bitwiseOr = FLAG1 or FLAG2 val bitwiseAnd = FLAG1 and FLAG2
-
一个
String可以像数组那样访问,并且也可以被迭代:var s = "charon" var c = s[2] for (a in s) { Log.e("@@@", a + ""); }
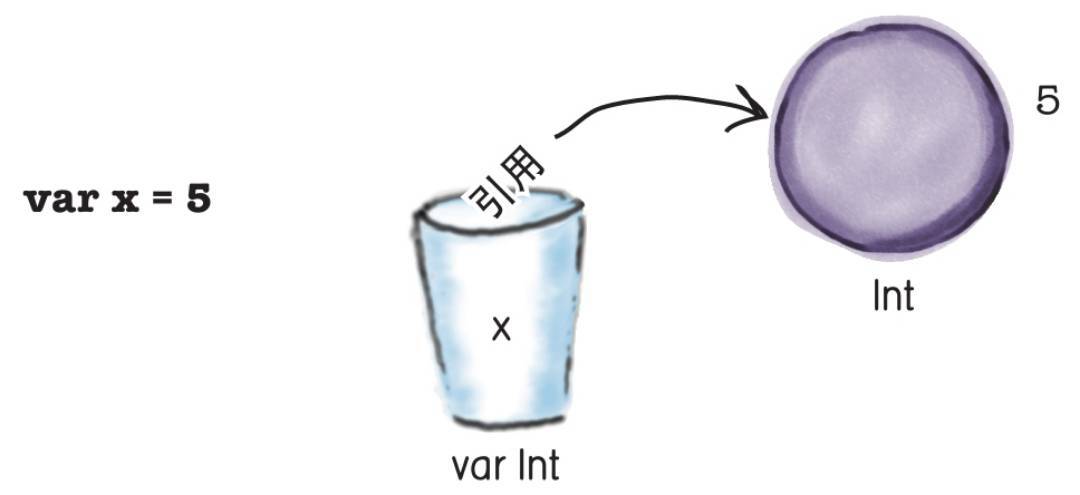
当该对象被赋值给变量时,这个对象本身并不会被直接赋值给当前的变量。相反,该对象的引用会被赋值给该变量。 因为当前的变量存储的是对象的引用,因此它可以访问该对象。
如果你使用val来声明一个变量,那么该变量所存储的对象的引用将不可修改。然而如果你使用var声明了一个变量,你可以对该变量重新赋值。
例如,如果我们使用代码: x = 6,将x的值赋为6,此时会创建一个值为6的新Int对象,并且x会存放该对象的引用。下面新的引用会替代原有的引用值被存放在x中:
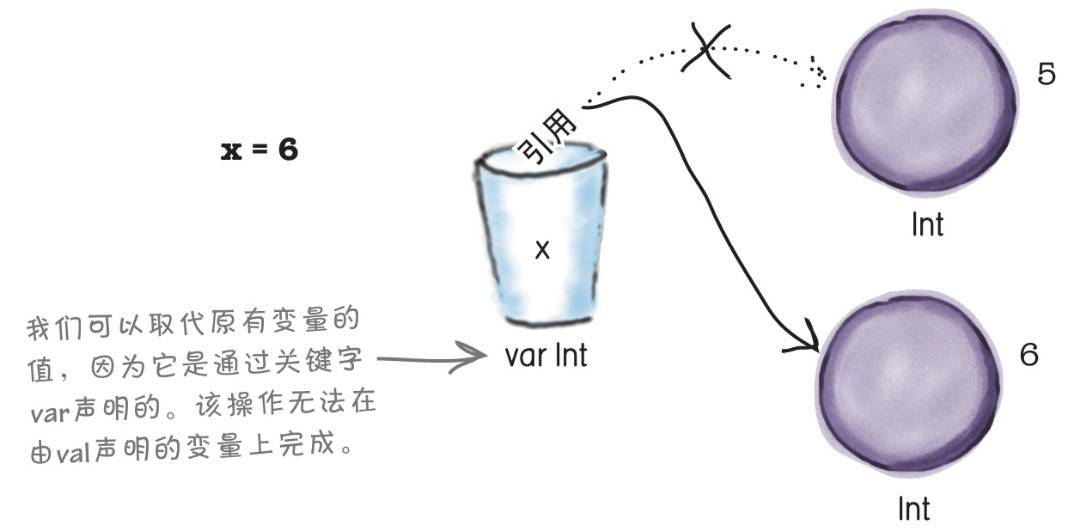
注意: 在Java中,数字类型是原生类型,所以变量存储的是实际数值。但是在Kotlin中的数字也是对象,而变量仅仅存储该数字对象的引用,并非对象本身。
在很多Kotlin的学习资料中,都会传递一个原则:优先使用val来声明变量。这相当正确,但更好的理解可以是:尽可能采用val、不可变对象及纯函数来设计程序。 关于纯函数的概念,其实就是没有副作用的函数,具备引用透明性。
简单来说,副作用就是修改了某处的某些东西,比如说:
- 修改了外部变量的值
- IO操作,如写数据到磁盘
- UI操作,如修改了一个按钮的可操作状态
来看一个实际的例子:先用var来声明一个变量a,然后在count函数内部对其进行自增操作:
var a = 1
fun count(x: Int) {
a = a + 1
println(x + a)
}如果执行两次count(1)函数,第一次的执行结果是3、第二次的执行结果是4。这显然是受到了外部变量a的影响,这个就是典型的副作用。
已知值的属性可以使用const修饰符标记为编译期常量(类似java中的public static final)。
const只能修复val不能修复var,这些属性需要满足以下要求:
- 位于顶层或者是
object的一个成员 - 用
String或原生类型值初始化 - 没有自定义
getter
// Const val are only allowed on top level or in objects
const val NAME: String = "charon"
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
}
}Kotlin会默认创建set get方法,我们也可以自定义get set方法:
在kotlin的getter和setter是不允许调用本身的局部变量的,因为属性的调用也是对get的调用,因此会产生递归,造成内存溢出。
例如:
var count = 1
var size: Int = 2
set(value) {
Log.e("text", "count : ${count++}")
size = if (value > 10) 15 else 0
}这个例子中就会内存溢出。
kotlin为此提供了一种我们要说的后端变量,也就是field。编译器会检查函数体,如果使用到了它,就会生成一个后端变量,否则就不会生成。
我们在使用的时候,用field代替属性本身进行操作。按照惯例set参数的名称是value,但是如果你喜欢你可以选择一个不同的名称。
setter通过field标识更新变量属性值。field指的是属性的支持字段,你可以将其视为对属性的底层值的引用。在getter和setter中使用field代替属性名称
很重要,因为这样可以阻止你陷入无限循环中。
class A {
var count = 1
var size: Int = 2
set(value) {
field = if (value > 10) 15 else 0
}
get() {
return if (field == 15) 1 else 0
}
}
fun main() {
val a = A()
a.size = 11
println("${a.size}")
}
//
1如果我们不手动写getter和setter方法,编译器会在编译代码时添加以下代码段:
var myProperty: String
get() = field
set(value) {
field = value
}自定义set和get的重点在field,field指代当前参数,类似于java的this关键字。
这意味着无论何时当你使用点操作符来获取或设置属性值时,实际上你总是调用了属性的getter或是setter。那么,为什么编译器要这么做呢? 为属性添加getter和setter意味着有访问该属性的标准方法。getter处理获取值的所有请求,而setter处理所有属性值设置的请求。 因此,如果你想要改变处理这些请求的方式,你可以在不破坏任何人代码的前提下进行。通过将其包装在getter和setter中来输出对属性的直接访问称为数据隐藏。
在某些情况下,无参的函数与只读属性可互换通用。虽然语义相似,但在以下情况中,更多的是选择使用属性而不是方法。
- 不会抛出任何异常。
- 具有O(1)的复杂度。
- 容易计算(或者运行一次之后缓存结果)。
- 每次调用返回同样的结果。
它实际上是一个隐含的对属性值的初始化声明。能有效避免空指针问题的产生。
var size: Int = 2;
private var _table: Map<toString, Int>? = null
val table: Map<String, Int>
get() {
if (_table == null) {
_table = HashMap()
}
return _table ?: throw AssertionError("Set to null by another thread")
}在Java中,访问private成员变量需要通过getter和setter来实现,此处通过table来获取_table变量,优化了Java中函数调用带来的开销。
在类内声明的属性必须初始化,如果设置非null的属性,应该将此属性在构造器内进行初始化。
假如想在类内声明一个null属性,在需要时再进行初始化(最典型的就是懒汉式单例模式),这就与Kotlin的规则是相背的,此时我们可以声明一个属性并
延迟其初始化,此属性用lateinit修饰符修饰。
class MainActivity : AppCompatActivity() {
lateinit var name : String
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
var test = MainActivity()
// 要先调用方法让其初始化
test.init()
// 再使用其属性
Log.e("@@@", test.name)
}
fun init() {
// 延迟初始化
name = "charon"
}
}需要注意的是,我们在使用的时候,一定要确保属性是被初始化过的,通常先调用初始化方法,否则会有异常。
如果只是用lateinit声明了,但是还没有调用初始化方法就使用,哪怕你判断了该变量是否为null也是会crash的:
private lateinit var test: String
private fun switchFragment(position: Int) {
if (test == null) {
LogUtil.e("@@@", "test is null")
} else {
LogUtil.e("@@@", "test is not null")
check(test)
}
}会报kotlin.UninitializedPropertyAccessException: lateinit property test has not been initialized
We’ve added a new reflection API allowing you to check whether a lateinit variable has been initialized: 这里想要判断是否初始化了,需要用isInitialized来判断:
class MyService{
fun performAction(): String = "foo"
}
class Test{
private lateinit var myService: MyService
fun main(){
// 如果 myService 对象还未初始化,则进行初始化
if(!::myService.isInitialized){
println("hha")
myService = MyService()
}
}
}注意: ::myService.isInitialized可用于判断adapter变量是否已经初始化。虽然语法看上去有点奇怪,但这是固定的写法。::前缀不能省。::是一个引用运算符,一般用于反射相关的操作中,可以引用属性或者函数。
这里可以写成::myService.isInitialized或this::myService.isInitialized。
如果在listener或者内部类中,可以这样写this@OuterClassName::myService.isInitialized
那lateinit有什么用呢? 每次使用还要判断isInitialized。
The primary use-case for lateinit is when you can't initialize a property in the constructor but can guarantee that it's initialized "early enough" in some sense that most uses won't need an isInitialized check. E.g. because some framework calls a method initializing it immediately after construction.
Lateinit Initialization is used when you want to initialize a variable at a later stage, especially when it's non-null and must be initialized before use. It's commonly used in dependency injection and testing.
除了使用lateinit外还可以使用by lazy {}效果是一样的:
private val test by lazy { "haha" }
private fun switchFragment(position: Int) {
if (test == null) {
LogUtil.e("@@@", "test is null")
} else {
LogUtil.e("@@@", "test is not null ${test}")
check(test)
}
} 执行结果:
test is not null haha
那lateinit和by lazy有什么区别呢?
by lazy{}只能用在val类型而lateinit只能用在var类型lateinit不能用在可空的属性上和java的基本类型上,否则会报lateinit错误- lateinit在分配之前不会初始化变量,而by lazy在第一次访问时初始化它。
- 如果在初始化之前访问,lateinit会抛出异常,而lazy则可以确保已初始化。 lazy的背后是接收一个lambda并返回一个Lazy实例的函数,第一次访问该属性时,会执行lazy对应的Lambda表达式并记录结果,后续访问该属性时只是返回记录的结果。
另外系统会给lazy属性默认加上同步锁,也就是LazyThreadSafetyMode.SYNCHRONIZED,它在同一时刻只允许一个线程对lazy属性进行初始化,所以它是线程安全的。 但若你能确认该属性可以并行执行,没有线程安全问题,那么可以给lazy传递LazyThreadSafetyMode.PUBLICATION参数。 你还可以给lazy传递LazyThreadSafetyMode.NONE参数,这将不会有任何线程方面的开销,当然也不会有任何线程安全的保证。例如:
val sex: String by lazy(LazyThreadSafetyMode.PUBLICATION) {
// 并行模式
if (color == "yellow") "male" else "female"
}
val sex: String by lazy(LazyThreadSafetyMode.NONE) {
// 不做任何线程保证也不会有任何线程开销
if (color == "yellow") "male" else "female"
}- 尽量不要使用lateinit来定义不可空类型的变量,可能会在使用时出现null的情况
- 只读变量(val修饰)可以使用by lazy { }实现懒加载,可变变量(var修饰)使用改写get方法的形式实现懒加载
// 只读变量
private val lazyImmutableValue: String by lazy {
"Hello"
}
// 可变变量
private var lazyValue: Fragment? = null
get() {
if (field == null) {
field = Fragment()
}
return field
}当您稍后需要在代码中初始化var时,请选择lateinit,它将被重新分配。当您想要初始化一个val值一次时,特别是当初始化的计算量很大时,请选择by lazy。
val name: String by lazy {getName()}这样,当第一次使用name引用时,getName()函数只会被调用一次。此外,还可以使用函数引用代替lambda表达式:
val name: String by lazy(::getName)
fun getName() : String {
println("computing name")
return "Mockey"
}在Kotlin中,@操作符主要有两个作用:
- 限定this的对象类型
class User {
inner class State {
fun getUser(): User {
return this@User // 返回User
}
fun getState(): State {
return this@State // 返回State
}
}
}- 作为标签使用 当把@操作符作为标签使用时,可以跳出双层for循环和forEach函数。 例如:
val listA = listOf(1, 2, 3, 4, 5, 6)
val listB = listOf(2, 3, 4, 5, 6, 7 )
loop@ for(itemA in listA) {
var i: Int = 0
for (itemB in listB) {
i++
if (item > 2) {
break @loop // 当itemB > 2时,跳出循环
}
println("itemB: $itemB")
}
}当你在定义类的时候,需要想想该类所创建的对象需要什么:
-
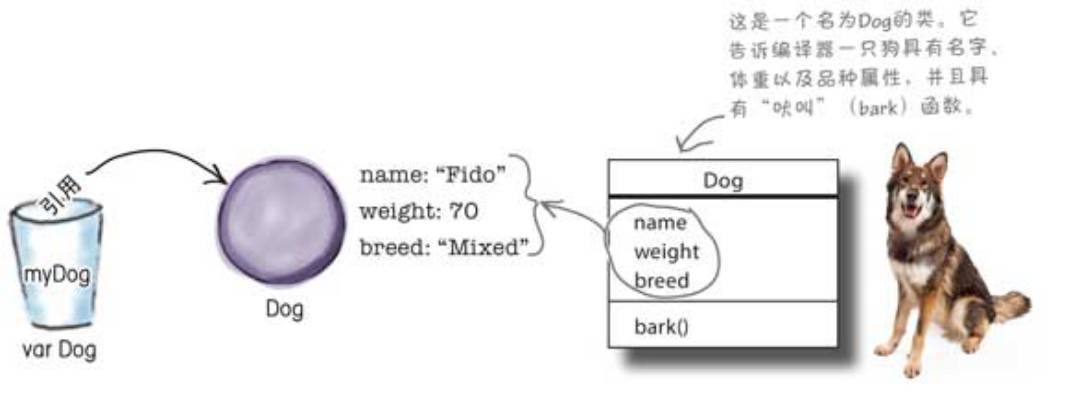
每个对象自身的特点
对象自身的特点称为属性(properties)。它们代表了对象自身的状态(数据),并且该类中的每一个对象都有自己独特的数值。 例如,一个狗(Dog)类可能有名字(name)、体重(weight)和品种(breed)属性。一个歌曲(Song)类可能有标题(title)和演唱者(artist)属性。
-
每个对象的行为
对象的行为是它们的函数(functions)。它们决定了对象的行为,并且可能会使用对象的属性。例如,上面提到的Dog类,可能具有吠叫(bark)函数; Song这个类可能会有播放(play)函数。
类可以包含:
- 构造函数和初始化块
- 函数
- 属性
- 嵌套类和内部类
- 对象声明
你可以将类想象成一个对象的模板,因为它告诉编译器如何创建该特定类的对象。它还将告诉编译器每个对象应该具有哪些属性,并且从该类生成的每个对象都可以 拥有自己独有的属性值。例如,每个Dog对象都有自己的名称、重量和品种属性,每个Dog的属性值都可以是不同的。

class Dog(val name: String, var weight: Int, val breed: String){
fun bark() {
}
}如果有参数的话你只需要在类名后面写上它的参数,如果这个类没有任何内容可以省略大括号:
class Dog(val name: String, var weight: Int, val breed: String)val myDog = Dog("Fido", 70, "Mixed" )上面的类有一个默认的构造函数。
注意:创建类的实例不用new了啊。

类中所定义的函数又称为成员函数,有时也被称为方法。
var myDog = Dog("Fido", 70, "Mixed")- 系统会为每个传入Dog构造函数的参数创建一个对象。它会创建一个值为“Fido”的String,一个值为70的Int,以及一个值为“Mixed”的String。
- 系统会为一个新的Dog对象分配空间,并且Dog构造函数会被调用。
- Dog构造函数定义了三个属性:名称、重量以及品种。在这个现象背后,每一个属性实际上是一个变量。对于构造函数中定义的每个属性,都会有一个相应类型的变量被创建。
- 相应的变量的引用将会被赋值给Dog的属性。例如,值为“Fido”的String将会被赋值给name属性。
- 最后,这个新的Dog对象的引用将会被赋值给名为myDog的Dog变量。
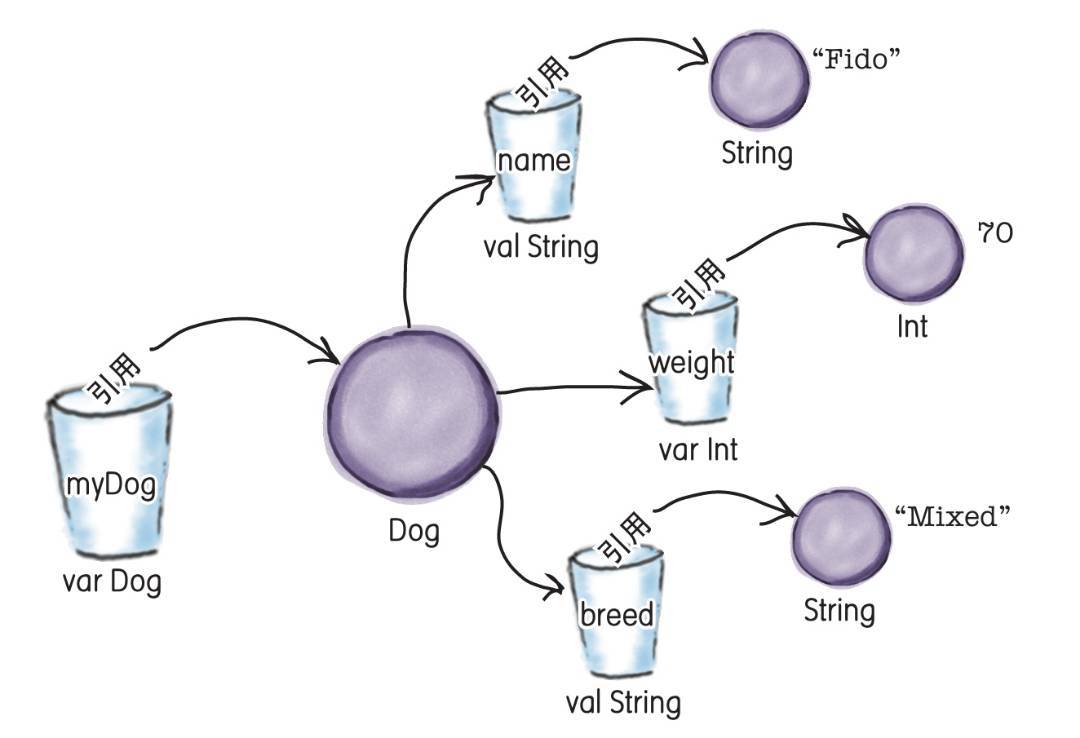
构造函数包含了初始化对象所需的代码。它在对象被分配给引用之前运行,这意味着你有机会对对象进行一些内部操作以便其被使用。大多人使用构造函数来定义对 象的属性,并且给这些属性赋值。每当你创建一个新的对象,该对象所属的类的构造函数将会被调用。构造函数在你初始化对象时被调用。它通常被用于定义对象的 属性,并且对属性赋值。
在Kotlin中的一个类可以有一个主构造函数和一个或多个次构造函数。
主构造函数是类头的一部分:它跟在类名(和可选的类型参数)后:
class Person constructor(name: String, surname: String) {
}如果主构造函数没有任何注解或者可见性修饰符,可以省略constructor关键字:
class Person(name: String, surname: String) {
}主构造函数不能包含任何的代码。初始化的代码可以放到以init关键字作为前缀的初始化块中:
class Person constructor(name: String, surname: String) {
init {
print("name is $name and surname is $surname")
}
}如果构造函数有注解或可见性修饰符,那么constructor关键字是必需的,并且这些修饰符在它前面:
class Person private @Inject constructor(name: String, surname: String) {
init {
print("name is $name and surname is $surname")
}
}类也可以声明前缀有constructor的次构造函数:
class Person{
constructor(name: String) {
print("name is $name")
}
}如果类有一个主构造函数,每个次构造函数都需要委托给主构造函数(不然会报错), 可以直接委托或者通过别的次构造函数间接委托。
委托到同一个类的另一个构造函数用this关键字即可:
class Person constructor(name: String) {
constructor(name: String, surName: String) : this(name) {
Log.d("@@@", "name is : $name surName is : $surName")
}
}使用该对象:
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
Person("charon", "chui")
}
}就会在logcat上打印:
09-20 16:51:19.738 6010-6010/com.charon.kotlinstudydemo D/@@@: name is : charon surName is : chui
如果一个非抽象类没有声明任何(主或次)构造函数,它会有一个生成的不带参数的主构造函数。构造函数的可见性是public。
如果你不希望你的类有一个公有构造函数,你需要声明一个带有非默认可见性的空的主构造函数:
class Person private constructor(name: String) {
}open class Base(p: Int)
class Example(p: Int) : Base(p)如果该类有一个主构造函数,那么其基类型可以用主构造函数的参数进行初始化。
如果该类没有主构造函数,那么每个次构造函数必须使用super关键字初始化其类型,或者委托给另一个构造函数初始化。如:
class Example : View {
constructor(ctx: Context) : super(ctx)
constructor(ctx: Context, attrs: AttributeSet) : super(ctx, attrs)
}class Bird(val weight: Double = 0.00, val age: Int = 0, val color: String = "blue")
val bird1 = Bird(color = "black")
val bird2 = Bird(weight = 1000.00, color = "black")上面在Bird类中使用了val或者var来声明构造方法的参数。这一方面代表了参数的引用可变性,另一方面也使得我们在构造类的语法上得到了简化。事实上, 构造方法的参数名前当然可以没有val和var。然而带上它们之后就等价于在Bird类内部声明了一个同名的属性,我们可以用this来进行调用。 比如,上面定义的Bird类就类似于一下实现:
// 构造方法参数名前没有val
class Bird (weight: Double = 0.00, age: Int = 0, color: String = "blue"){
val weight: Double
val age: Int
val color: String
init {
this.weight = weight // 构造方法参数可以在init语句中被调用
this.age = age
this.color = color
}
}Kotlin引入了一种叫作init语句块的语法,它属于上述构造方法的一部分,两者在表现形式上却是分离的。Bird类的构造方法在类的外部,它只能对参数进行赋值。 如果我们需要在初始化时进行其他的额外操作,那么我们就可以使用init语句块来执行。比如:
class Bird(weight: Double, age: Int, color: String) {
init {
println("the weight is ${weight}")
}
}当没有val或者var的时候,构造函数的参数可以在init语句块被直接调用。除此之外,不能在其他地方使用。以下是一个错误的用法:
class Bird(weight: Double, age: Int, color: String) {
fun printWeight() {
print(weight) // Unresolved reference: weight
}
}事实上,我们的构造方法还可以拥有多个init,他们会在对象被创建时按照类中从上到下的顺序先后执行。例如:
class Bird(weight: Double, aget: Int, color: String) {
val weight: Double
val age: Int
val color: String
init {
this.weight = weight
this.age = age
}
init {
this.color = color
}
}可以发现,多个init语句块有利于进一步对初始化的操作进行职能分离,这在复杂的业务开发中显得特别有用。
数据类通常需要重写equals()、hashCode()、toString()这几个方法。其中,equals()方法用于判断两个数据类是否相等。 hashCode()方法作为equals()的配套方法,也需要一起重写,否则会导致HashMap、HashSet等hash相关的系统类无法正常工作。 toString()方法用于提供更清晰的输入日志,否则一个数据类默认打印出来的就是一行内存地址。所以我们在Java中创建一个数据类时要写很多代码, 但是在Kotlin中你只需要一行代码。
数据类是一种非常强大的类:
public class Artist {
private long id;
private String name;
private String url;
private String mbid;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getMbid() {
return mbid;
}
public void setMbid(String mbid) {
this.mbid = mbid;
}
@Override public String toString() {
return "Artist{" +
"id=" + id +
", name='" + name + '\'' +
", url='" + url + '\'' +
", mbid='" + mbid + '\'' +
'}';
}
}使用Kotlin:
data class Artist(
var id: Long,
var name: String,
var url: String,
var mbid: String)数据类自动覆盖它们的equals方法以改变==操作符的行为,由此通过检查对象的每个属性值来判断是否相等。
例如,假设你创建了两个属性值完全相同的Artist对象,
使用==操作符对它们进行比较将返回true,因为它们存放了相同的数据:除了提供从Any父类继承的equals方法的新实现,数据类还覆盖了hashCode和toString方法。
通过数据类,会自动提供以下函数:
- 所有属性的
get() set()方法 equals()hashCode()copy()toString()componentN()
如果我们使用不可修改的对象,就像我们之前讲过的,假如我们需要修改这个对象状态,必须要创建一个新的或者多个属性被修改的实例。 这个任务是非常重复且不简洁的。
举个例子,如果要修改Person类中charon的age:
data class Person(val name: String,
val age: Int)val charon = Person("charon", 18)
val charon2 = charon.copy(age = 19)如上,我们拷贝了charon对象然后只修改了age的属性而没有修改这个对象的其它状态。
如果你要在Kotlin声明一个数据类,必须满足以下几点条件:
- 数据类必须拥有一个构造方法,该方法至少包含一个参数,一个没有数据的数据类是没有任何用处的。
- 与普通的类不同,数据类构造方法的参数强制使用var或者val进行声明
- data class之前不能用abstract、open、sealed或者inner进行修饰
- 在Kotlin 1.1版本前数据类只允许实现接口,之后的版本既可以实现接口也可以继承类, 更多可看Feedback Request: Limitations on Data Classes
与任何其他类一样,你可以向数据类添加属性和方法,只需要将它们包含在类主体中。但是有一个大问题,就是在编译器生成数据类的方法实现时, 比如覆盖equals方法和创建copy方法,它仅包含在主构造函数中定义的属性。因此如果你在数据类主体中定义添加的属性,则它们不会被包含到任何编译器生成的方法中。
定义数据类时,编译器会自动向该类添加一组方法,你可以将其作为访问对象属性值的替代方法。它们被称为componentN方法,其中N表示被访问属性的编号(按声明排序)。
多声明,也可以理解为变量映射,这就是编译器自动生成的componentN()方法。
var personD = PersonData("PersonData", 20, "male")
var (name, age) = personD
Log.d("test", "name = $name, age = $age")
//输出
// name = PersonData, age = 20上面的多声明,大概可以翻译成这样:
var name = f1.component1()
var age = f1.component2()数据类的缺点,数据类虽然使用的时候很简单,但是因为它会默认帮我们自动生成很多代码,里面的有些代码其实在某些情况下我们并不需要,例如copy、component等, 如果在项目中使用了大量的数据类,那就会引起包大小增加的问题。 具体可见Data classes in Kotlin: how do they impact application size
虽然对于release包,使用了R8,ProGuard,DexGuard等优化器。这些可以删除未使用的方法,这意味着它们可以优化数据类。 像componentN()、copy()如果没有使用的话,会默认给删除。但是对于toString()、equals()、hashCode()方法则不会删除。 对于有些不需要toString()、equals()、hashCode()方法的类如果使用数据类就会导致多生成这些代码,所以在使用数据类的时候不要去为了简单而乱用, 也要去想想是否需要这些方法?是否需要设计成数据类。
fun main(args: Array<String>) {
var user = User::special
// 调用invoke函数执行
user.invoke(User("Jack", 30))
// 利用反射机制获取指定方法的内容
var method = User::class.java.getMethod("special")
method.invoke(User("Tom", 20))
}
class User(val name: String, val age: Int) {
fun special() {
println("name:${name") age:${age}");
}
}在上面的实例中,User类还有一个special函数,使用User::special可以获取成员函数的对象,然后使用invoke函数调用special函数,以获取该函数的内容。
构造函数的引用和属性、方法类似,构造函数可以作用于任何函数类型的对象,该函数的对象与构造函数的参数相同,可以使用::操作符加类名的方式来引用构造函数。
class Foo
fun function(factory: () -> Foo) {
val x: Foo = factory()
}
// 使用::Foo方式调用类Foo的无参数构造函数
fun main() {
function(::Foo)
}在Kotlin中所有类都有一个共同的超类Any,这对于没有超类型声明的类是默认超类:
class Person // 从 Any 隐式继承Any不是java.lang.Object。它除了equals()、hashCode()和toString()外没有任何成员。
在Java中,类默认是可以被继承的,除非你主动加final修饰符。而在Kotlin中恰好相反,默认是不可被继承的,除非你主动加可以继承的修饰符,那便是open,
如果不加open,那它在转化为Java代码时就是final的:
class Bird {
val weight: Double = 500.0
val color: String = "blue"
val age: Int = 1
fun fly() {}
}将Bird类编译后转换为Java的代码:
public final class Bird {
private final double weight = 500.0;
private final String color = "blue";
private final int age = 1;
public final double getWeight() {
return this.weight;
}
public final String getColor() {
return this.color;
}
public final int getAge() {
return this.age;
}
public final void fly() {
}
}所以Kotlin中所有的类默认都是不可继承的(final),为什么要这样设计呢?引用Effective Java书中的第17条:要么为继承而设计,并提供文档说明,
要么就禁止继承。所以我们只能继承那些明确声明open或者abstract的类:要声明一个显式的超类型,我们把类型放到类头的冒号之后:
open class Person(num: Int)
// 继承
class SuperPerson(num: Int) : Person(num)冒号后面的Person(num)会调用Person类的构造函数,以确保所有的初始化代码(例如给属性赋值)能够被执行。 调用父类构造函数是强制性的:如果父类有主构造函数,你必须在子类头中调用它,否则代码将无法通过编译。 请记住,即使你没有在父类中显式地添加构造函数,编译器也会在编译代码的时候自动创建一个空构造函数。 假如我们不想为Person类添加构造函数,因此编译器在编译代码的时候创建了一个空构造函数。该构造函数通过使用Person()被调用。
注意: 上面在说到继承的时候class SuperPerson(num: Int) : Person(num)在父类后面必须加上括号,这是为了能够调用到父类的主构造函数。
Kotlin中规定,当一个类既有主构造函数又有次构造函数时,所有的次构造函数都必须调用主构造函数(包括间接调用)。
但是如果类没有主构造函数,那么每个次构造函数必须使用super关键字初始化其基类型,或委托给另一个构造函数做到这一点。 这里很特殊,在Kotlin
中是允许类中只有次构造函数,没有主构造函数的。当一个类没有显式的定义主构造函数且定义了次构造函数时,它就是没有主构造函数的。
如果该类有一个主构造函数,其基类必须用基类型的主构造函数参数就地初始化。
如果类没有主构造函数,那么每个次构造函数必须使用super关键字初始化其基类型,或委托给另一个构造函数做到这一点。
注意,在这种情况下,不同的次构造函数可以调用基类型的不同的构造函数:
class MyView : View {
constructor(ctx: Context) : super(ctx)
constructor(ctx: Context, attrs: AttributeSet) : super(ctx, attrs)
}也就是MyView类的后面没有显式的定义主构造函数,同时又定义了次构造函数。所以现在MyView类是没有主构造函数的。
那么既然没有主构造函数,继承View类的时候也就不需要再在View类后加上括号了。
其实原因就是这么简单,只是很多人在刚开始学习Kotlin的时候没能理解这对括号的意义和规则,因此总感觉继承的 写法有时候要加上括号,有时候又不要加,搞得晕头转向的,而在你真正理解了规则之后,就会发现其实还是很好懂的。
另外,由于没有主构造函数,次构造函数只能直接调用父类的构造函数,上述代码也是将this关键字换成了super关键字,这部分就很好理解了。
我们都知道,Java并不能在真正意义上被称为一门"纯面向对象"语言,因为它的原始类型(如int)的值与函数等并不能被视作对象。
但是Kotlin不同,在Kotlin的类型系统中,并不区分原始类型(基本数据类型)和包装类型,我们使用的始终是同一个类型。虽然从严格意义上,我们不能说 Kotlin是一门纯面向对象的语言,但它显然比Java有更纯的设计。
与Object作为Java类层级结构的顶层类似,Any类型是Kotlin中所有非空类型(如String、Int)的超类,如:
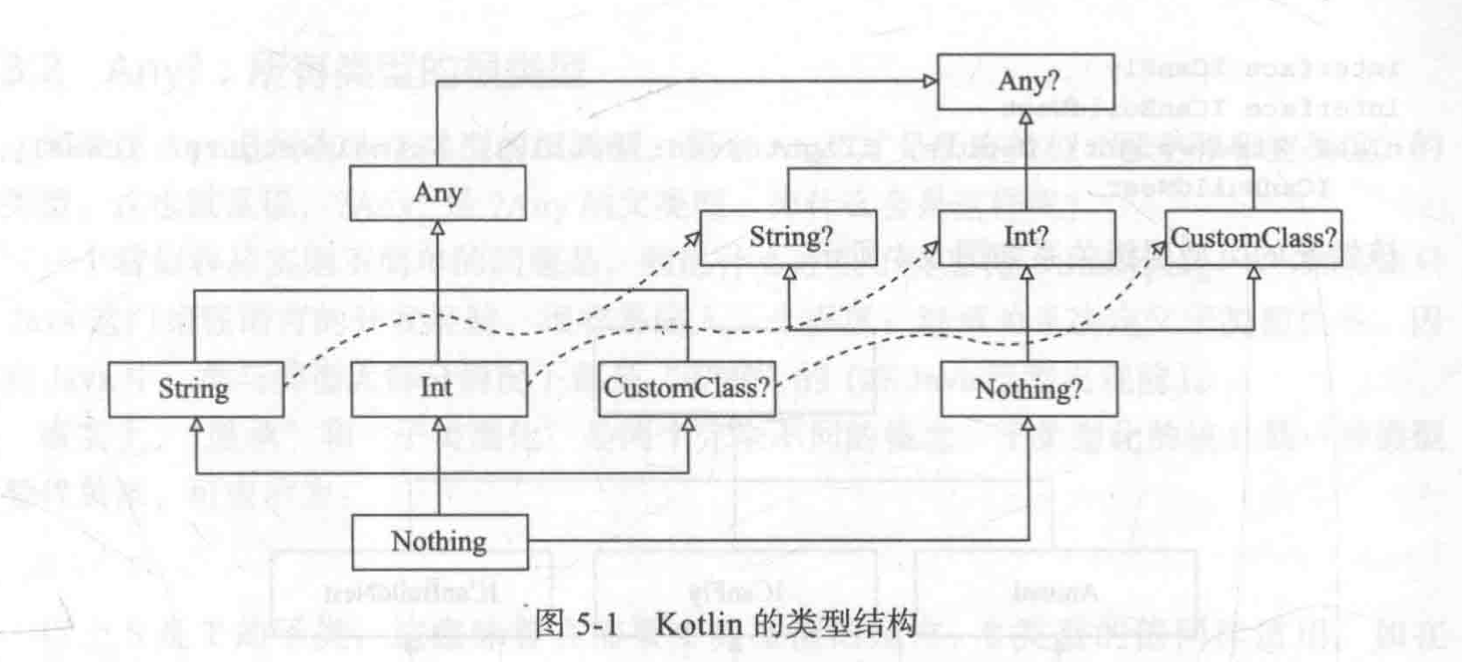
与Java不同的是,Kotlin不区分"原始类型"(primitive type)和其他的类型,他们都是同一类型层级结构的一部分。 如果定义了一个没有指定父类型的类型, 则该类型将是Any的直接子类型。如:
class Animal(val weight: Double)如果说Any是所有非空类型的根类型,那么Any?才是所有类型(可空和非空类型)的根类型。这也就是说?Any?是?Any的父类型。
只能重写显示标注可覆盖的方法:
open class Person(num: Int) {
open fun changeName(name: String) {
}
fun changeAge(age: Int) {
}
}
class SuperPerson(num: Int) : Person(num) {
override fun changeName(name: String) {
// 通过super关键字调用超类实现
super.changeName(name)
}
}SuperPerson.changeName()方法前面必须加上override标注,不然编译器将会报错。如果像上面Person.changeAge()方法没有标注open,
则子类中不能定义相同的方法:
class SuperPerson(num: Int) : Person(num) {
override fun changeName(name: String) {
super.changeName(name)
}
// 编译器报错
fun changeAge(age: Int) {
}
// 重载是可以的
fun changeAge(name: String) {
}
// 重载是可以的
fun changeAge(age: Int, name: String) {
}
}标记为override的成员本身是开放的,也就是说,它可以在子类中覆盖。如果你想禁止再次覆盖,可以使用final关键字:
open class SuperPerson(num: Int) : Person(num) {
final override fun changeName(name: String) {
super.changeName(name)
}
}属性覆盖与方法覆盖类似,只能覆盖显式标明open的属性,并且要用override开头:
open class Person(num: Int) {
open val name: String = ""
open fun changeName(name: String) {
}
fun changeAge(age: Int) {
}
}
open class SuperPerson(num: Int) : Person(num) {
override val name: String
get() = super.name
final override fun changeName(name: String) {
super.changeName(name)
}
}每个声明的属性可以由具有初始化器的属性或者具有get方法的属性覆盖,如果某个属性在父类中被定义为val,你可以在子类中使用var属性覆盖它。
只需要覆盖该属性并将其声明为var即可。请注意,这只适用于这一种方式。如果尝试使用val覆盖var属性,编译器将会感到沮丧并拒绝编译你的代码。
类和其中的某些成员可以声明为abstract。抽象成员在本类中可以不用实现。需要注意的是,我们并不需要用open标注一个抽象类或者函数——因为这不言而喻。
我们可以用一个抽象成员覆盖一个非抽象的开放成员:
open class Base {
open fun f() {}
}
abstract class Derived : Base() {
override abstract fun f()
}和Java差不多
// 这是一个行注释
/* 这是一个多行的
块注释。 */接口可以让你在父类层次结构之外定义共同的行为,接口用于为共同行为定义协议,使你可以不依赖严格的继承结构却又可以利用多态。与抽象类类似,接口不能被 实例化且可以定义抽象或具体的方法和属性,但两者有一个关键的不同点:类可以实现多个接口,但是只能继承于一个直接父类。所以接口不仅拥有抽象类的优点, 而且使用起来更加灵活。
interface FlyingAnimal {
fun fly()
}虽然Kotlin接口支持属性声明,然而它在Java源码中是通过一个get方法来实现的。在接口的属性并不能像Java接口那样,被直接赋值一个常量。如以下这样是错误的:
interface Flyer {
val height = 1000 // error Property initializers are not allowed in interfaces
val speed: Int
// 可以支持默认实现方法,反编译可以看到是通过静态内部类来提供fly方法的默认实现的,Java8也开始支持了接口方法的默认实现
fun fly() {
println("I can fly")
}
}Kotlin提供了另外一种方式来实现这种效果:
interface Flyer {
val height
get() = 1000
}一个类实现接口时:
class Bird() : Flyer {
// ...
}接口的后面不用加上括号,因为它没有构造函数可以去调用。
fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
}如果你没有指定它的返回值,它就会返回Unit,Unit与Java中的void类似,但是Unit是一个类型,而void只是一个关键字。Unit可以省略。
你当然也可以指定任何其它的返回类型:
fun maxOf(a: Int, b: Int): Int {
if (a > b) {
return a
} else {
return b
}
}如果函数返回Unit类型,该返回类型应该省略:
fun foo() { // 省略了 ": Unit"
}之所以不能说Java中的函数调用皆是表达式,是因为存在特例void。众所周知,在Java中如果声明的函数没有返回值,那么它就需要用void来修饰,如:
void foo() {
System.out.println("return nothing")
}所以foo()就不具有值和类型信息,它就不能算作一个表达式。在Kotlin中,函数在所有的情况下都具有返回类型,所以他们引入了Unit来替代Java中的void关键字。
Unit与Int一样,都是一种类型,然而它不代表任何信息,用面向对象的术语来描述就是一个单例,它的实例只有一个,可写为()。
如果一个函数的返回的结果可以使用一个表达式计算出来,你可以不使用括号而是使用等号:
fun add(x: Int,y: Int) : Int = x + y // 省略了{}Kotlin支持这种单行表达式与等号的语法来定义函数,叫做表达式函数体,作为区分,普通的函数声明则可以叫做代码块函数体。
如你所见,在使用表达式函数体的情况下我们可以不声明返回值类型,这进一步简化了语法。
我们可以给参数指定一个默认值使的它们变的可选,这是非常有帮助的。这里有一个例子,在Activity中创建了一个函数用来Toast一段信息:
fun toast(message: String, length: Int = Toast.LENGTH_SHORT) {
Toast.makeText(this, message, length).show()
}上面代码中第二个参数length指定了一个默认值。这意味着你调用的时候可以传入第二个值或者不传,这样可以避免你需要的重载函数:
toast("Hello")
toast("Hello", Toast.LENGTH_LONG)如果你使用的是Kotlin1.2或更早的版本,若想正常运行程序,你的主函数必须写成如下形式:
fun main(args: Array<String>) {
// ...
}从Kotlin1.3版本起,你可以忽略main函数的参数,写成如下形式:
fun main() {
// ...
}fun vars(vararg v: Int){
for(vt in v){
print(vt)
}
}
// 测试
fun main(args: Array<String>) {
vars(1,2,3,4,5) // 输出12345
}如果你有一个现有的值数组,则可以通过在数组名前加上*来将这些值传递给该函数。星号(*)被称为扩展运算符,以下是它的一些使用示例:
val myArray = arrayOf(1, 2, 3, 4, 5)
val mList = vars(*myArray)
val mList2 = vars(0, *myArray, 6, 7)在Kotlin中,方法调用也被定义为二元操作运算符,而这些方法往往可以转化为invoke函数。 例如 a(i)方法的对应转换方法为 a.invoke(i)
如果拿不准的时候,默认使用Java的编码规范,比如:
- 使用驼峰法命名(并避免命名含有下划线)
- 类型名以大写字母开头
- 方法和属性以小写字母开头
- 使用4个空格缩进
- 公有函数应撰写函数文档,这样这些文档才会出现在
Kotlin Doc中
通常,一个类的内容按以下顺序排列:
- 属性声明与初始化块
- 次构造函数
- 方法声明
- 伴生对象
不要按字母顺序或者可见性对方法声明排序,也不要将常规方法与扩展方法分开。而是要把相关的东西放在一起,这样从上到下阅读类的人就能够跟进所发生事情的 逻辑。选择一个顺序(高级别优先,或者相反)并坚持下去。
将嵌套类放在紧挨使用这些类的代码之后。如果打算在外部使用嵌套类,而且类中并没有引用这些类,那么把它们放到末尾,在伴生对象之后。
在实现一个接口时,实现成员的顺序应该与该接口的成员顺序相同(如果需要,还要插入用于实现的额外的私有方法)
在类中总是将重载放在一起。
类型和超类型之间的冒号前要有一个空格,而实例和类型之间的冒号前不要有空格:
interface Foo<out T : Any> : Bar {
fun foo(a: Int): T
}有少数几个参数的类可以写成一行:
class Person(id: Int, name: String)具有较长类头的类应该格式化,以使每个主构造函数参数位于带有缩进的单独一行中。此外,右括号应该另起一行。如果我们使用继承, 那么超类构造函数调用或者实现接口列表应位于与括号相同的行上:
class Person(
id: Int,
name: String,
surname: String
) : Human(id, name) {
// ……
}对于多个接口,应首先放置超类构造函数调用,然后每个接口应位于不同的行中:
class Person(
id: Int,
name: String,
surname: String
) : Human(id, name),
KotlinMaker {
// ……
}- 邮箱 :charon.chui@gmail.com
- Good Luck!