H.264是一种高性能的视频编解码技术。目前国际上制定视频编解码技术的组织有两个,一个是“国际电联”,它制定的标准有H.261、H.263、H.263+等,另一个是“国际标准化组织(ISO)”它制定的标准有MPEG-1、MPEG-2、MPEG-4等。而H.264则是由两个组织联合组建的联合视频组(JVT)共同制定的新数字视频编码标准,所以它既是ITU-T的H.264,又是ISO/IEC的MPEG-4高级视频编码,而且它将成为MPEG-4标准的第10部分。因此,不论是MPEG-4 AVC、MPEG-4 Part 10,还是ISO/IEC 14496-10,都是指H.264。
H.264是在MPEG-4技术的基础之上建立起来的,其编解码流程主要包括5个部分:帧间和帧内预测、变换和反变换、量化和反量化、环路滤波、熵编码。
H.264/MPEG-4 AVC(H.264)是1995年自MPEG-2视频压缩标准发布以后的最新、最有前途的视频压缩标准。H.264是由ITU-T和ISO/IEC的联合开发组共同开发的最新国际视频编码标准。通过该标准,在同等图象质量下的压缩效率比以前的标准提高了2倍以上,因此,H.264被普遍认为是最有影响力的行业标准。
H.264在1997年ITU的视频编码专家组提出时被称为H.26L,在ITU与ISO合作研究后被称为MPEG4 Part10或H.264(JVT)。H.264标准的主要目标是:与其它现有的视频编码标准相比,在相同的带宽下提供更加优秀的图象质量。
而,H.264与以前的国际标准如H.263和MPEG-4相比,最大的优势体现在以下四个方面:
- 将每个视频帧分离成由像素组成的块,因此视频帧的编码处理的过程可以达到块的级别。
- 采用空间冗余的方法,对视频帧的一些原始块进行空间预测、转换、优化和熵编码(可变长编码)。
- 对连续帧的不同块采用临时存放的方法,这样,只需对连续帧中有改变的部分进行编码。该算法采用运动预测和运动补偿来完成。对某些特定的块,在一个或多个已经进行了编码的帧执行搜索来决定块的运动向量,并由此在后面的编码和解码中预测主块。
- 采用剩余空间冗余技术,对视频帧里的残留块进行编码。例如:对于源块和相应预测块的不同,再次采用转换、优化和熵编码。
具体优势表现为:
- 低码流:和MPEG2和MPEG4 ASP等压缩技术相比,在同等图像质量下,采用H.264技术压缩后的数据量只有MPEG2的1/8,MPEG4的1/3。显然,H.264压缩技术的采用将大大节省用户的下载时间和数据流量收费。
- 高质量的图象:H.264能提供连续、流畅的高质量图象(DVD质量)。
- 容错能力强:H.264提供了解决在不稳定网络环境下容易发生的丢包等错误的必要工具。
- 网络适应性强:H.264提供了网络适应层, 使得H.264的文件能容易地在不同网络上传输(例如互联网,CDMA,GPRS,WCDMA,CDMA2000等)。
H.264和以前的标准一样,也是DPCM加变换编码的混合编码模式。但它采用“回归基本”的简洁设计,不用众多的选项,获得比H.263++好得多的压缩性能;加强了对各种信道的适应能力,采用“网络友好”的结构和语法,有利于对误码和丢包的处理;应用目标范围较宽,以满足不同速率、不同解析度以及不同传输(存储)场合的需求。
帧内编码用来缩减图像的空间冗余。为了提高H.264帧内编码的效率,在给定帧中充分利用相邻宏块的空间相关性,相邻的宏块通常含有相似的属性。因此,在对一给定宏块编码时,首先可以根据周围的宏块预测(典型的是根据左上角的宏块,因为此宏块已经被编码处理),然后对预测值与实际值的差值进行编码,这样,相对于直接对该帧编码而言,可以大大减小码率。
帧间预测编码利用连续帧中的时间冗余来进行运动估计和补偿。H.264的运动补偿支持以往的视频编码标准中的大部分关键特性,而且灵活地添加了更多的功能,除了支持P帧、B帧外,H.264还支持一种新的流间传送帧——SP帧,如图3所示。码流中包含SP帧后,能在有类似内容但有不同码率的码流之间快速切换,同时支持随机接入和快速回放模式。
在变换方面,H.264使用了基于4×4像素块的类似于DCT的变换,但使用的是以整数为基础的空间变换,不存在反变换,因为取舍而存在误差的问题,变换矩阵如图5所示。与浮点运算相比,整数DCT变换会引起一些额外的误差,但因为DCT变换后的量化也存在量化误差,与之相比,整数DCT变换引起的量化误差影响并不大。此外,整数DCT变换还具有减少运算量和复杂度,有利于向定点DSP移植的优点。
H.264中可选32种不同的量化步长,这与H.263中有31个量化步长很相似,但是在H.264中,步长是以12.5%的复合率递进的,而不是一个固定常数。
在H.264中,变换系数的读出方式也有两种:之字形(Zigzag)扫描和双扫描,如图6所示。大多数情况下使用简单的之字形扫描;双扫描仅用于使用较小量化级的块内,有助于提高编码效率。
视频编码处理的最后一步就是熵编码,在H.264中采用了两种不同的熵编码方法:通用可变长编码(UVLC)和基于文本的自适应二进制算术编码(CABAC)。
在H.263等标准中,根据要编码的数据类型如变换系数、运动矢量等,采用不同的VLC码表。H.264中的UVLC码表提供了一个简单的方法,不管符号表述什么类型的数据,都使用统一变字长编码表。其优点是简单;缺点是单一的码表是从概率统计分布模型得出的,没有考虑编码符号间的相关性,在中高码率时效果不是很好。
因此,H.264中还提供了可选的CABAC方法。算术编码使编码和解码两边都能使用所有句法元素(变换系数、运动矢量)的概率模型。为了提高算术编码的效率,通过内容建模的过程,使基本概率模型能适应随视频帧而改变的统计特性。内容建模提供了编码符号的条件概率估计,利用合适的内容模型,存在于符号间的相关性可以通过选择目前要编码符号邻近的已编码符号的相应概率模型来去除,不同的句法元素通常保持不同的模型。
目前,H.264已被广泛应用于实时视频应用中,相比以往的方案使得在同等速率下,H.264能够比H.263减小50%的码率。也就是说,用户即使是只利用 384kbit/s的带宽,就可以享受H.263下高达 768kbit/s的高质量视频服务。H.264 不但有助于节省庞大开支,还可以提高资源的使用效率,同时令达到商业质量的实时视频服务拥有更多的潜在客户。
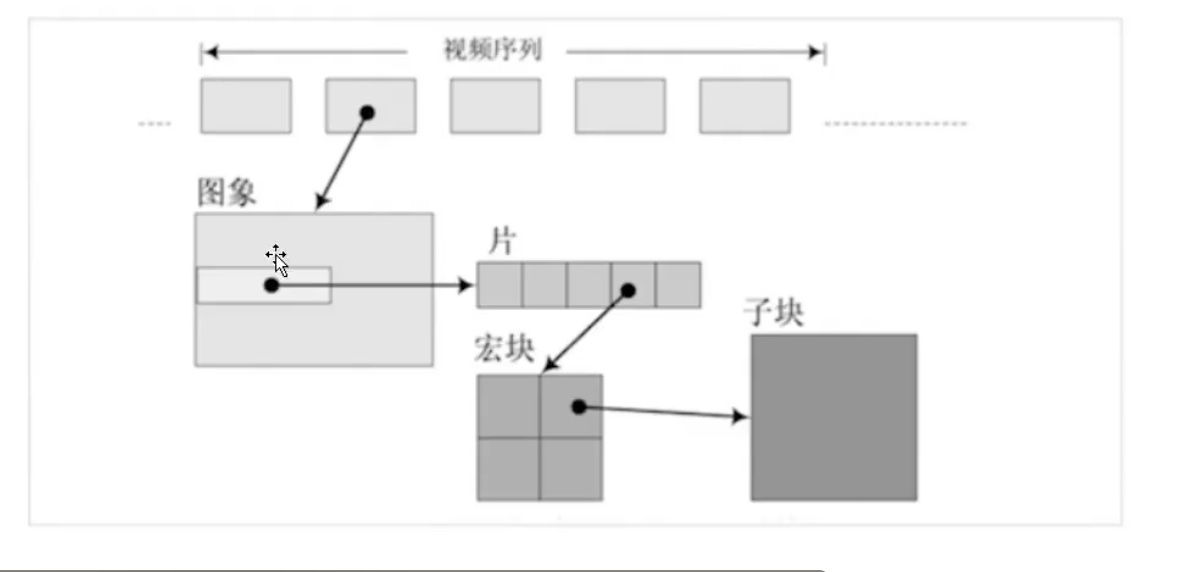
H264 结构中,一个视频图像编码后的数据叫做一帧,一帧由一个片(slice)或多个片组成,一个片由一个或多个宏块(MB)组成,一个宏块由16x16 的yuv数据组成。宏块作为H264 编码的基本单位。
在H264 协议内定义了三种帧,分别是I 帧、B 帧与P 帧:
- I 帧就是之前所说的一个完整的图像帧,而B、帧与P 帧所对应的就是之前说 的不编码全部图像的帧。
- P 帧与B 帧的差别就是P 帧是参考之前的I 帧而生成的,而B 帧是参考前后图 像帧编码生成的。
GOP 我个人也理解为跟序列差不多意思,就是一段时间内变化不大的图像集。 GOP 结构一般有两个数字,如M=3,N=12。 M 指定I 帧和P 帧之间的距离,N 指定两个I 帧之间的距离。上面的M=3,N=12,GOP 结构为:IBBPBBPBBPBBI。在一个GOP 内I frame 解码不依赖任何的其它帧,p frame 解码则依赖前面的I frame 或P frame,B frame 解码依赖前最近的一个I frame 或P frame 及其后最近的一个P frame。
在编码解码中为了方便,将GOP 中首个I 帧要和其他I 帧区别开,把第一个I 帧叫IDR,这样方便控制编码和解码流程,所以IDR 帧一定是I 帧,但I 帧不一定是IDR 帧;IDR 帧的作用是立刻刷新,使错误不致传播,从IDR 帧开始算新的序列开始编码。I 帧有被跨帧参考的可能,IDR 不会。I 帧不用参考任何帧,但是之后的P 帧和B 帧是有可能参考这个I 帧之前的帧的。 IDR 就不允许这样,例如: IDR1 P4 B2 B3 P7 B5 B6 I10 B8 B9 P13 B11 B12 P16 B14 B15 这里的B8 可以跨过I10 去参考P7
IDR1 P4 B2 B3 P7 B5 B6 IDR8 P11 B9 B10 P14 B11 B12 这里的B9 就只能参照IDR8 和P11,不可以参考IDR8 前面的帧
H.264 引入IDR 图像是为了解码的重同步,当解码器解码到IDR 图像时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始一个新的序列。这样,如果前一个序列出现重大错误,在这里可以获得重新同步的机会。IDR 图像之后的图像永远不会使用IDR 之前的图像的数据来解码。
- Step1:分组,也就是将一系列变换不大的图像归为一个组,也就是一个序列,也可以叫GOP(画面组);
- Step2:定义帧,将每组的图像帧归分为I 帧、P 帧和B 帧三种类型;
- Step3:预测帧, 以I 帧做为基础帧,以I 帧预测P 帧,再由I 帧和P 帧预测B 帧;
- Step4:数据传输, 最后将I 帧数据与预测的差值信息进行存储和传输。
H264 的主要目标是为了有高的视频压缩比和良好的网络亲和性,为了达成这两个目标,H264的解决方案是将系统框架分为两个层面,分别是视频编码层面(VCL)和网络抽象层面(NAL),
视频编码中采用的如预测编码、变化量化、熵编码等编码工具主要工作在slice层或以下,这一层通常被称为视频编码层(Video Coding Layer, VCL)。
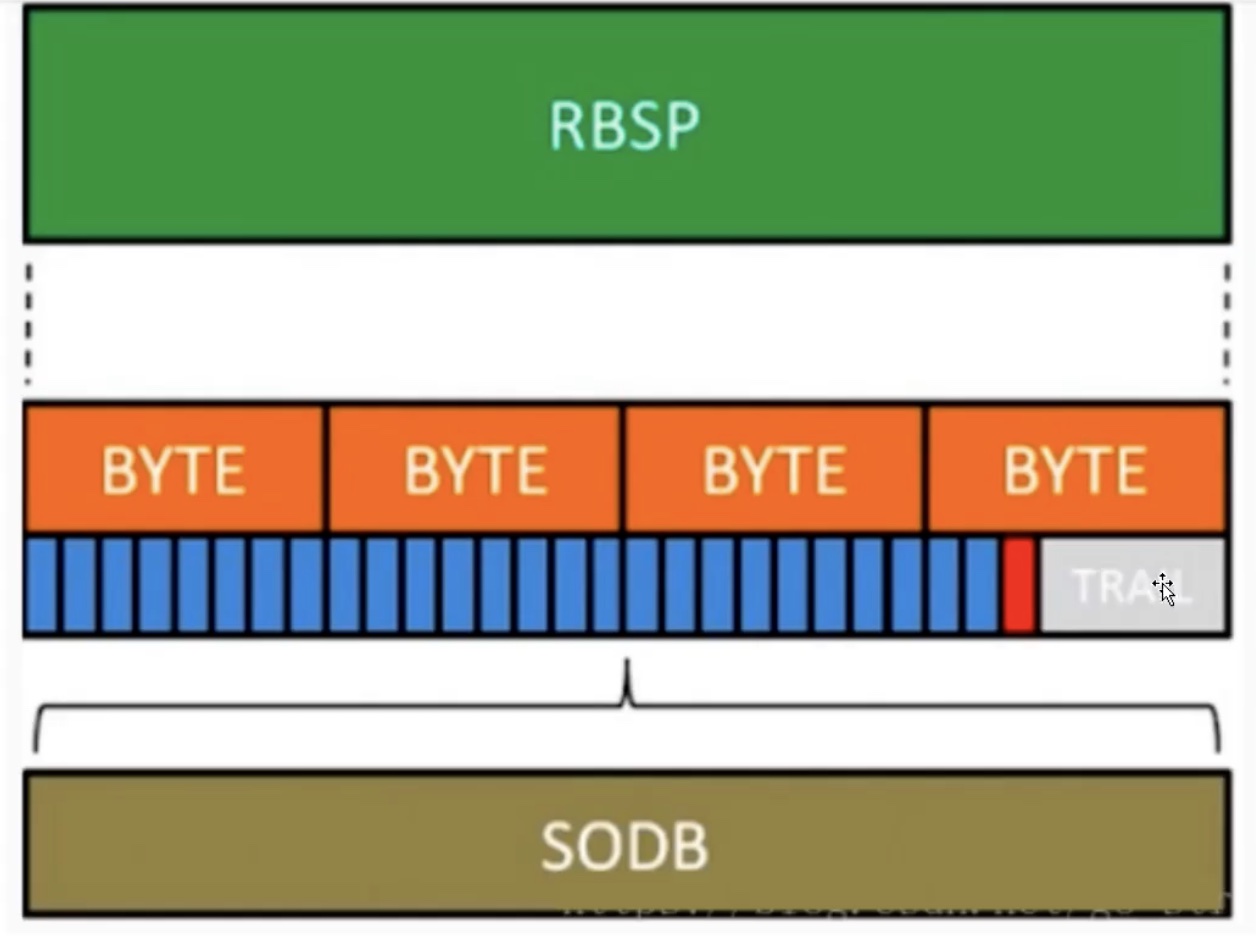
VCL层是对核心算法引擎、块、宏块及片的语法级别的定义,负责有效展示视频数据的内容,最终输出编码完的数据SODB。
相对的,在slice以上所进行的数据和算法通常称之为网络抽象层(Network Abstraction Layer, NAL)。 NAL层定义了片级以上的语法级别(如序列参数集和图像参数集,针对网络传输),负责以网络所要求的恰当方式去格式化数据并提供头信息,以保证数据适合各种信道和存储介质熵的传输。NAL层将SODB打包成RBSP,然后加上NAL头组成一个NALU单元。
SODB:数据比特串,是编码后的原始数据。 RBSP:原始字节序列载荷,是在原始编码数据后面添加了结尾比特,一个bit 1和若干个比特 0,用于字节对齐.
 设计定义NAL层的主要意义在于提升H.264格式的视频对网络传输和数据存储的亲和性。
设计定义NAL层的主要意义在于提升H.264格式的视频对网络传输和数据存储的亲和性。
- SODB(String of Data Bits,数据比特串):最原始,未经过处理的编码数据
- RBSP(Raw Byte Sequence Payload,原始字节序列载荷):在SODB 的后面填加了结尾bit(RBSP trailing bits 一个bit ‘1’)若干bit ‘0’,以便字节对齐。
- EBSP(Encapsulated Byte Sequence Payload, 扩展字节序列载荷):NALU 的起始码为0x000001 或0x00000001(起始码包括两种:3 字节(0x000001)和4 字节(0x00000001),在SPS、PPS 和Access Unit 的第一个NALU 使用4 字节起始码,其余情况均使用3 字节起始码。)
在经过编码后的H264码流是由一个个的NAL单元组成,其中SPS、PPS、IDR和SLICE是NAL单元某一类型的数据,如下:
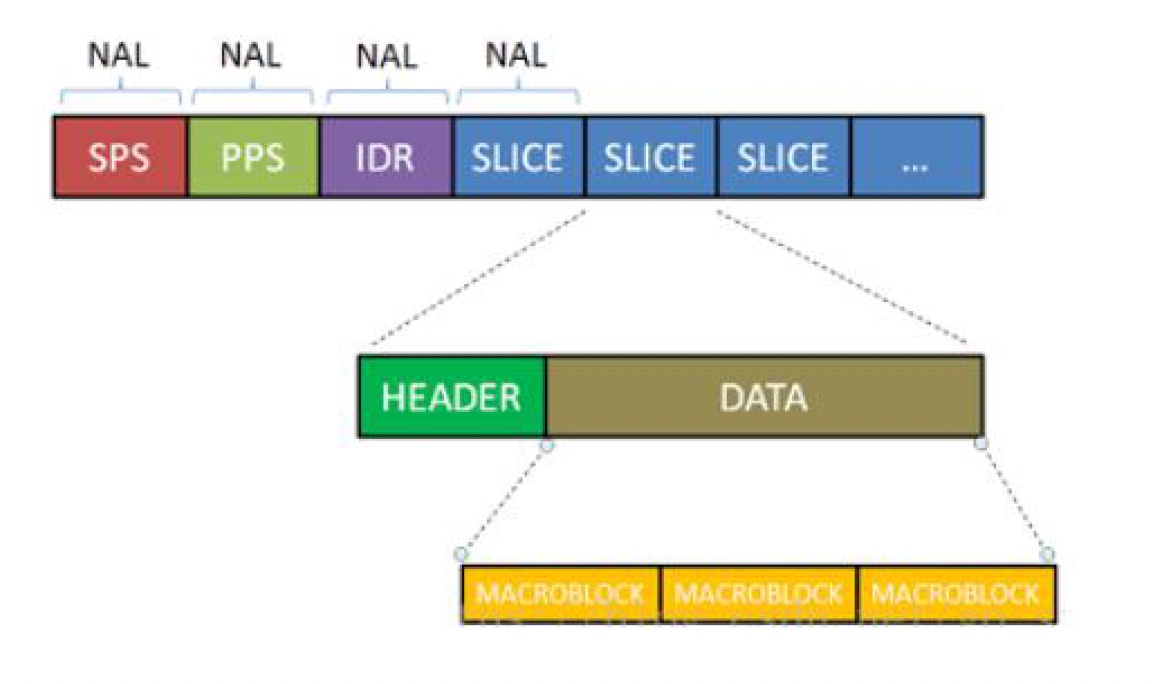
在实际的网络数据传输过程中H264 的数据结构是以NALU(NAL 单元)进行传输的,
传输数据结构组成为[NALU Header]+[RBSP],如下图所示:

VCL 层编码后的视频帧数据,帧有可能是I/B/P 帧,这些帧也可能是属于不同的序列之中; 同一序列也还有相应的序列参数集与图片参数集; 综上所述,想要完成准确无误视频的解码,除了需要VCL 层编码出来的视频帧数据,同时还需要传输序列参数集和图像参数集等等,所以RBSP不单纯只保存I/B/P 帧的数据编码信息,还有其他信息也可能出现在里面。 上面知道NAL 单元是作为实际视频数据传输的基本单元,NALU 头是用来标识后面RBSP 是什么类型的数据,同时记录RBSP 数据是否会被其他帧参考以及网络传输是否有错误,
NAL 单元的头部是由forbidden_bit(1bit),nal_reference_bit(2bits)(优先级), nal_unit_type(5bits)(类型)三个部分组成的,组成如图6 所示: 1、F(forbiden):禁止位,占用NAL 头的第一个位,当禁止位值为1 时表示语法错误; 2、NRI:参考级别,占用NAL 头的第二到第三个位;值越大,该NAL 越重要。 3、Type:Nal 单元数据类型,也就是标识该NAL 单元的数据类型是哪种,占用NAL 头的第 四到第8 个位;

码流分析工具: elecard streameye
- 邮箱 :charon.chui@gmail.com
- Good Luck!