输入两个链表,找出它们的第一个公共结点。(注意因为传入数据是链表,所以错误测试数据的提示是用其他方式显示的,保证传入数据是正确的)
第一种做法,直接依赖于HashSet,遍历第一个链表的时候,将所有的节点,添加到hashset中,遍历第二个链表的时候直接判断是否包含即可,属于空间换时间的做法。
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
//创建集合set
Set<ListNode> set = new HashSet<>();
while (pHead1 != null) {
set.add(pHead1);
pHead1 = pHead1.next;
}
while (pHead2 != null) {
if (set.contains(pHead2))
return pHead2;
pHead2 = pHead2.next;
}
return null;
}C++代码如下:
ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2) {
set<ListNode*> mySet ;
while (pHead1 != NULL) {
mySet.insert(pHead1);
pHead1 = pHead1->next;
}
while (pHead2 != NULL) {
if (mySet.count(pHead2)>0)
return pHead2;
pHead2 = pHead2->next;
}
return NULL;
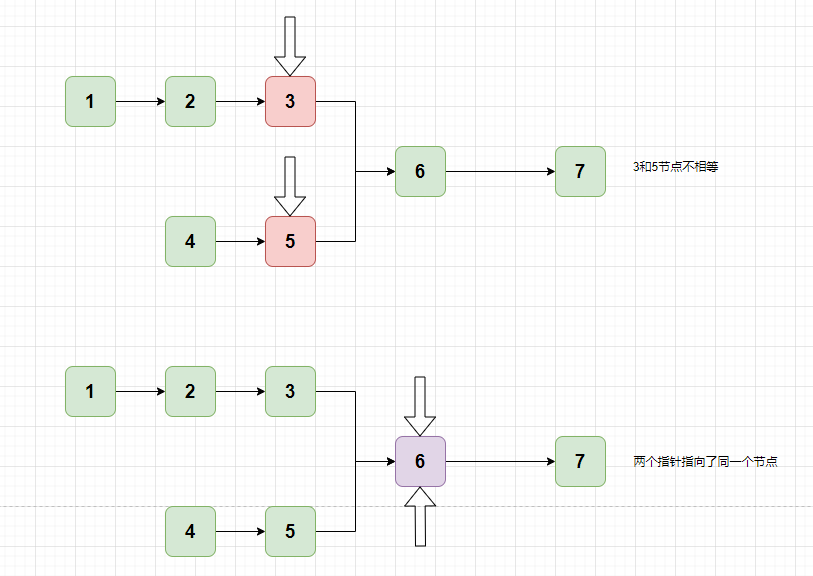
}譬如现在有一个链表1->2->3->6->7,另外一个链表4->5->6->7,明显可以看出第一个公共节点是 6 。

最直接的方法,每一个链表都遍历一次,计算链表中的个数,比如1->2->3->6->7个数为5,4->5->6->7个数为4,两者相差1(设为k)个。
我们可以使用两个指针,分别指向链表的头部。然后让第一个链表的指针先走k=1步。

就可以开始比较,如果不相等,则两个指针都往后移动即可,知道节点为null。
代码如下:
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
// 只要有一个为空,就不存在共同节点
if (pHead1 == null || pHead2 == null) {
return null;
}
// 计算链表1中的节点个数
int numOfListNode1 = 0;
ListNode head1 = pHead1;
while (head1 != null) {
numOfListNode1++;
head1 = head1.next;
}
// 计算链表2中节点个数
int numOfListNode2 = 0;
ListNode head2 = pHead2;
while (head2 != null) {
numOfListNode2++;
head2 = head2.next;
}
// 比较两个链表的长度
int step = numOfListNode1 - numOfListNode2;
if (step > 0) {
// 链表1更长,链表1移动
while (step != 0) {
pHead1 = pHead1.next;
step--;
}
} else {
// 链表2更长,链表2移动
while (step != 0) {
pHead2 = pHead2.next;
step++;
}
}
// 循环遍历后面的节点,相等则返回
while (pHead1 != null && pHead2 != null) {
if (pHead1 == pHead2) {
return pHead1;
} else {
pHead1 = pHead1.next;
pHead2 = pHead2.next;
}
}
return null;
}
}C++ 代码如下:
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2) {
// 只要有一个为空,就不存在共同节点
if (pHead1 == NULL || pHead2 == NULL) {
return NULL;
}
// 计算链表1中的节点个数
int numOfListNode1 = 0;
ListNode* head1 = pHead1;
while (head1 != NULL) {
numOfListNode1++;
head1 = head1->next;
}
// 计算链表2中节点个数
int numOfListNode2 = 0;
ListNode* head2 = pHead2;
while (head2 != NULL) {
numOfListNode2++;
head2 = head2->next;
}
// 比较两个链表的长度
int step = numOfListNode1 - numOfListNode2;
if (step > 0) {
// 链表1更长,链表1移动
while (step != 0) {
pHead1 = pHead1->next;
step--;
}
} else {
// 链表2更长,链表2移动
while (step != 0) {
pHead2 = pHead2->next;
step++;
}
}
// 循环遍历后面的节点,相等则返回
while (pHead1 != NULL && pHead2 != NULL) {
if (pHead1 == pHead2) {
return pHead1;
} else {
pHead1 = pHead1->next;
pHead2 = pHead2->next;
}
}
return NULL;
}
};但是上面的做法,如果公共节点在最后一个,假设一个链表长度为n,一个为m,那么计算个数就要全部遍历,需要n+m。两个链表都移动,到最后一个节点的时候才相等,也是n+m,也就是O(2*(n+m))。
有没有更加好用的做法呢?肯定有,我们来看:
两个链表分别是:

如果我在第一个链表后面拼接上第二个链表,第二个链表后面拼接上第一个链表,就会变成下面的样子:

发现了一个规律,也就是拼接之后的链表,是等长度的,第一个和第二个链表都从第一个开始比较,只要相等,就说明是第一个公共节点。也就是上面被圈起来的6节点。
代码如下:
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
// 只要有一个为空,就不存在共同节点
if (pHead1 == null || pHead2 == null) {
return null;
}
ListNode head1 = pHead1;
ListNode head2 = pHead2;
while (head1 !=head2) {
// 如果下一个节点为空,则切换到另一个链表的头节点,否则下一个节点
head1 = (head1 == null) ? pHead2 : head1.next;
head2 = (head2 == null) ? pHead1 : head2.next;
}
return head1;
}
}C++ 代码如下:
class Solution {
public:
ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2) {
// 只要有一个为空,就不存在共同节点
if (pHead1 == NULL || pHead2 == NULL) {
return NULL;
}
ListNode* head1 = pHead1;
ListNode* head2 = pHead2;
while (head1 !=head2) {
// 如果下一个节点为空,则切换到另一个链表的头节点,否则下一个节点
head1 = (head1 == NULL) ? pHead2 : head1->next;
head2 = (head2 == NULL) ? pHead1 : head2->next;
}
return head1;
}
};时间复杂度:O(n+m)
空间复杂度:O(1)