xVATrainer is the companion app to xVASynth, the AI text-to-speech app using video game voices. xVATrainer is used for creating the voice models for xVASynth, and for curating and pre-processing the datasets used for training these models. With this tool, you can provide new voices for mod authors to use in their projects.
v1.0 Showcase/overview:
Links: Steam Nexus Discord Patreon
Check the descriptions on the nexus page for the most up-to-date information.
--
There are three main components to xVATrainer:
- Dataset annotation - where you can adjust the text transcripts of existing/finished datasets, or record new data for it over your microphone
- Data preparation/pre-processing tools - Used for creating datasets of the correct format, from whatever audio data you may have
- Model training - The bit where the models actually train on the datasets
The main screen of xVATrainer contains a dataset explorer, which gives you an easy way to view, analyse, and adjust the data samples in your dataset. It further provides recording capabilities, if you need to record a dataset of your own voice, straight through the app, into the correct format.
There are several data pre-processing tools included in xVATrainer, to help you with almost any data preparation work you may need to do, to prepare your datasets for training. There is no step-by-step order that they need to be operated in, so long as your datasets end up as 22050Hz mono wav files of clean speech audio, up to about 10 seconds in length, with an associated transcript file with each audio file's transcript. Depending on what sources your data is from, you can pick which tools you need to use, to prepare your dataset to match that format. The included tools are:
- Audio formatting - a tool to convert from most audio formats into the required 22050Hz mono .wav format
- AI speaker diarization - an AI model that automatically extracts short slices of speech audio from otherwise longer audio samples (including feature length movie sized audio clips). The audio slices are additionally separated automatically into different individual speakers
- AI source separation - an AI model that can remove background noise, music, and echo from an audio clip of speech
- Audio Normalization - a tool which normalizes (EBU R128) audio to standard loudness
- WEM to OGG - a tool to convert from a common audio format found in game files, to a playable .ogg format. Use the "Audio formatting" tool to convert this to the required .wav format
- Cluster speakers - a tool which uses an AI model to encode audio files, and then clusters them into a known or unknown number of clusters, either separating multiple speakers, or single-speaker audio styles
- Speaker similarity search - a tool which encoders some query files, a larger corpus of audio files, and then re-orders the larger corpus according to each file's similarity to all the query files
- Speaker cluster similarity search - the same as the "Speaker similarity search" tool, but using clusters calculated via the "Cluster speakers" tool as data points in the corpus to sort
- Transcribe - an AI model which automatically generates a text transcript for audio files
- WER transcript evaluation - a tool which examines your dataset's transcript against one auto-generated via the "Transcribe" tool to check for quality. Useful when supplying your own transcript, and checking if there are any transcription errors.
- Remove background noise - a more traditional noise removal tool, which uses a clip of just noise as reference to remove from a larger corpus of audio which consistently has matching background noise
- Silence Split - A simple tool which splits long audio clips based on configurable silence detection
xVATrainer contains AI model training, for the FastPitch1.1 (with a custom modified training set-up), and HiFi-GAN models (the xVASynth "v2" models). The training follows a multi-stage approach especially optimized for maximum transfer learning (fine-tuning) quality. The generated models are exported into the correct format required by xVASynth, ready to use for generating audio with.
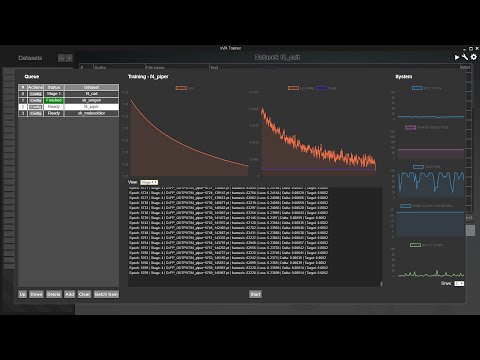
Batch training is also supported, allowing you to queue up any number of datasets to train, with cross-session persistence. The training panel shows a cmd-like textual log of the training progress, a tensorboard-like visual graph for the most relevant metrics, and a task manager-like set of system resources graphs.
You don't need any programming or machine learning experience. The only required input is to start/pause/stop the training sessions, and everything within is automated.
Note: these installation instructions are for Windows. Use the requirements_linux_py3_10_6.txt file for Linux installation.
Create the environment using virtualenv and python 3.10 (pre-requisite: Python 3.10)
virtualenv envXVATrainerP310 --python=C:\Users\Dan\AppData\Local\Programs\Python\Python310\python.exe
Activate your environment. Do this every time you launch a new terminal to work with xVATrainer
envXVATrainerP310\Scripts\activate
Install PyTorch v2.0.x with CUDA. Get the v2.0 link from the pytorch website (pre-requisite: CUDA drivers from nvidia) eg (might be outdated): pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Install the dependencies through pip: pip install -r reqs_gpu.txt
Copy the folders from ./lib/_dev into the environment (into envXVATrainerP310/Lib/site-packages). These are some library files which needed custom modifications/bug fixes to integrate with everything else. Overwrite as necessary
Make sure that you're using librosa==0.8.1 (check with pip list. uninstall and re-install with this version if not)
If you'd like to help improve xVATrainer, get in touch (eg an Issue, though best on Discord), and let me know. The main areas of interest for community contributions are (though let me know your ideas!):
- Training optimizations (speed)
- Model quality improvements
- New tools
- Bug fixes
- Quality of life improvements
A current issue/bug is that I can't get the HiFi-GAN to train with num_workers>0, as the training always cuts out after a deterministic amount of time - maybe something to do with the training loop being inside a secondary thread (FastPitch works fine though). Help with this would be especially welcome.
In a similar vein (and maybe caused by the same issue), I can only set tools' maximum number of multi-processing workers to just under half the total CPU thread count, else it can only run once, after which the app needs re-starting to use again.