Memory leak in latest version of dd-trace #759
Comments
|
Do you have runtime metrics enabled? In most cases, these metrics are able to pinpoint the issue fairly quickly. The most important charts to look at are: type of memory consumed, number of spans in heap, and async resources. |
|
Not at the moment, but thanks for the advice. I'll take a look at enabling it, and seeing what the metrics say. |
|
I'm currently collecting debug tracing on Datadog's request. For reference, my support ticket with Datadog is |
|
If followed up in the ticket so I can look into your account. Did you enable runtime metrics? |
|
Not in the flare I sent earlier. I only had the agent debugging enabled as well as the tracer debugging. I'll send another flare with both tracer debugging and runtime metrics enabled, once the application has run for 30 minutes. |
|
Uploaded another flare with the runtime metrics enabled, as well as debug tracing. |
|
I looked at the runtime metrics, and it seems there are a lot of promises that are kept in memory (you can see that with the Said that, I would say the first step here would be to try and figure out whether it's the tracer that is somehow holding the promise resources. The following snippet added to the app with the tracer disabled or removed would keep a count of promises held in memory: const promises = new Set()
setInterval(() => {
console.log(`Promises in memory: ${promises.size}`) // use a metric instead if possible and convenient
}, 30000)
require('async_hooks').createHook({
init: (asyncId, type) => {
if (type === 'PROMISE) {
promises.add(asyncId)
}
},
destroy: () => {
promises.delete(asyncId)
}
}).enable()If you see the count increasing while the tracer is disabled, this would indicate an existing leak. In that case, looking at a heap dump or heap profile would help finding where exactly it comes from. If the count does not increase, then the tracer is probably at fault. If that's the case, the sample applies for a heap dump or heap profile, but in this case it would be best to send it to support in the ticket so I can take a look. |
|
Thank you @rochdev! Your debug code has been most helpful. I'm able to confirm that the promises keep increasing even with tracing disabled. I also discovered that the promises are related to some promise wrapped DB code. I'm going to refactor some of the code and use the promise code native to the library ( |
|
Just a quick update. There seems to be a couple of issues at play. It seems to be a combination of sql promise / connection pool issue, as well as a dialogflow session management issue. I'm looking at another application of ours that's also affected to try and isolate at least one of the problems. I'll provide updates here if I find anything else. |
|
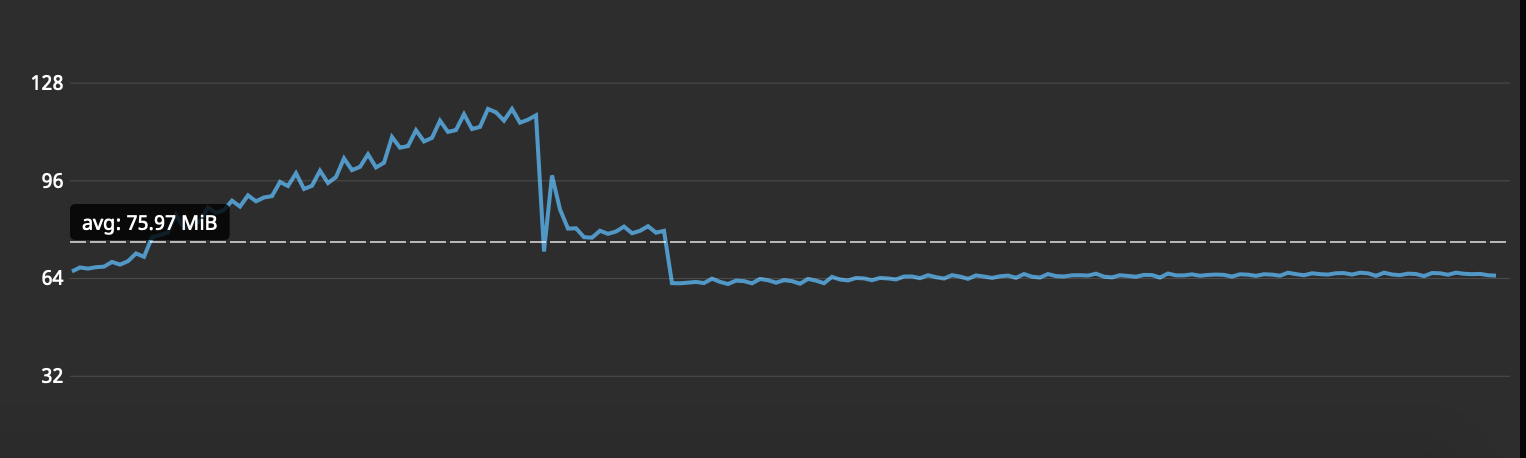
Okay, I think I have managed to isolate a service that seems most affected by this issue. As a test, I briefly enabled tracing and saw a definite continued increase in memory usage on the service that is otherwise running stable:
For reference, this service runs fairly stable at around 60 to 64 MB of memory on average, with tracing disabled. I've booked a slot for tomorrow to gather another flare for this service. Is there anything you want me to enable for the flare? Aside from:
Will 15 minutes be enough, before requesting the flare? |
|
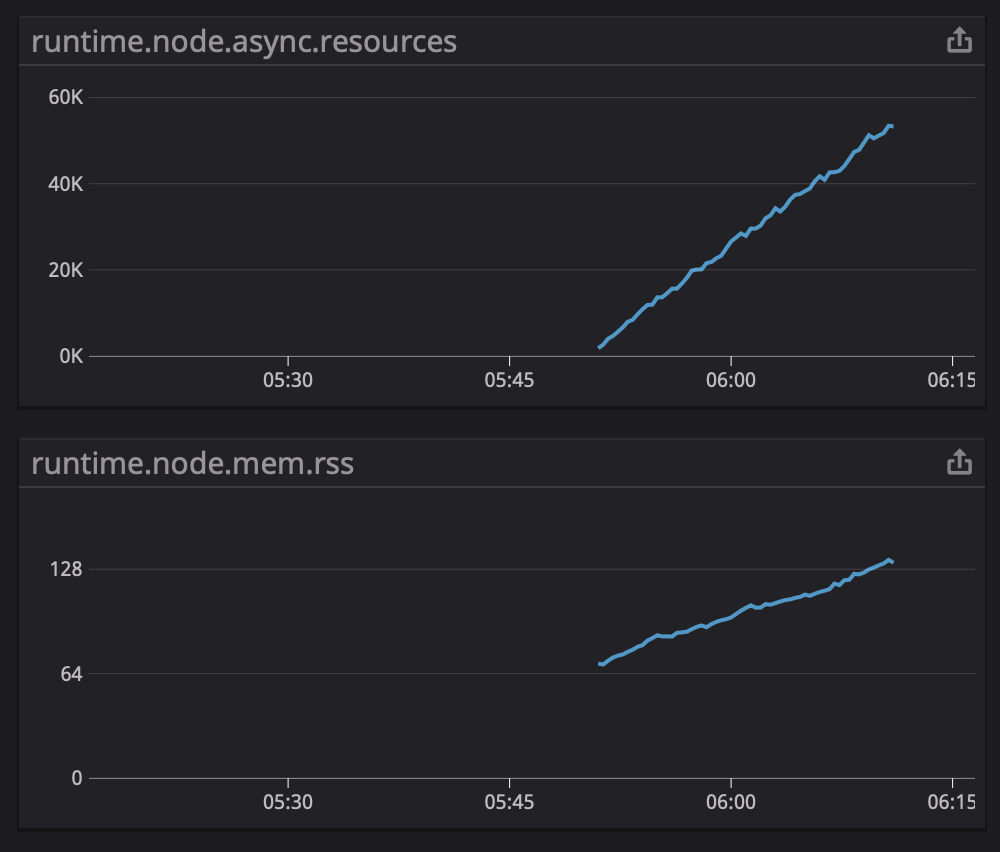
Uploaded another flare after running the application for 15 minutes: Also kept an eye on the runtime metrics while it was running: Unfortunately still not able to reproduce this locally. I do see the promise count increase, but as soon as I attach the node debugger locally and start recording, these are reclaimed by gc. |
|
Flares will not really help for this kind of issue, since it's isolated to the app and unrelated to the agent. The way the tracer is designed, we use async resources to propagate the context automatically. This is the only construct provided by Node to achieve this. If async resources are leaking, then any span associated with that resource will also be retained. From the above charts, it looks like this is the case. The existing leak would need to be fixed so that spans are not held in memory by the leaking resources. Given the above, there are 2 options:
|
Actually, this is interesting. If the GC is able to clean the promises, in theory it should mean that they are not leaking. The GC should trigger earlier when it sees that the memory is increasing a lot from the objects that are held. Can you try to trigger the GC automatically on a timer and see if it helps? For example, every 15 minutes call One thing worth noting also is that attaching the Node debugger impacts how |
|
Okay cool. I'll give that a try! Any idea why we don't see this happening in production with tracing disabled? Also, I forgot to mention that we recently upgraded to the latest Node LTS (v12), in case that makes a difference. |
Just to make sure I didn't read this wrong, I thought you said above that you were able to confirm the promise resources still increasing in production with the tracer disabled? Or do you just mean that you don't see the increase in memory in production? If that's the case, then it would be because promise resources are very lightweight C++ objects, so you would probably need hundreds of thousands of them in memory to even start noticing a leak. On the other hand, the spans that we attach to these resources hold much more memory, so you would start seeing the leak sooner. One additional thing I'd like to check to make sure that there isn't another issue at play, do you see a high count for |
|
Sorry for the miscommunication. You are right. I meant that I only noticed the memory increase with tracing enabled. I checked now and didn't see any high count for the spans, both finished or unfinished: |
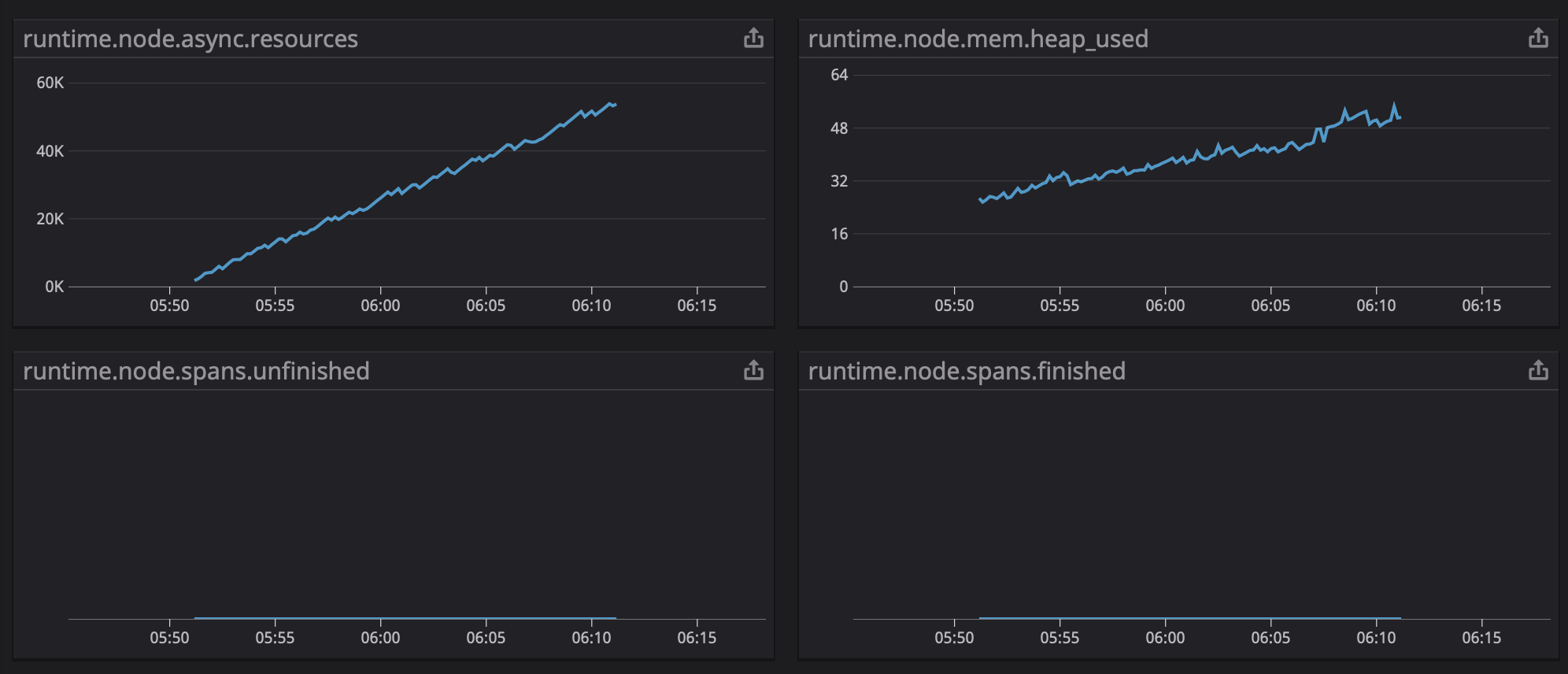
|
Here are the logs from running the test with the following parameters:
Note that the "..." indicate omitted calls to the From what I saw when I had the debugger attached, the 10 promises that always remain in memory are related to database connections in the connection pool (from Any idea if Node changes the way the GC works in the latest LTS? We have the following runtime flags that haven't changed in a couple of years (with the exception of us adding |
Not that I know of. Is the issue not present on older versions? When the promises are garbage collected, do you see the memory going down as well? |
|
I did some further tests and found that if I give the container less memory, Node consistantly runs GC whenever the memory usage hits around 50-60%. For the test, I once again used the following runtime parameters, with the only difference being the I was doing about a 100 requests per second and the logs end at around 10k requests: Is there perhaps anything the tracer does that would prevent the GC from running or reclaiming the promises? |
I tested and there were no real differences between Node v10 (previous LTS) and Node v12 (current LTS). There's slightly more memory available in the latter, but the rest of the behavior remains consistent. |
In general, Node GC is very lazy when there is enough memory available. I've seen environments that reach almost 100,000 spans in memory before the GC removes them. What could be happening is that the GC sees a lot of promises, but they are very lightweight so it decides to skip them. Then the tracer keeps the span based on the ID on the resource and not the resource itself, so there is no relationship, and this is memory the GC cannot reclaim. Once the available memory gets low enough, major GC is triggered which cleans up everything, including the promise resources and the spans. One thing to note however, is that we also remove the spans from memory when the promise is resolved/rejected, so it probably means there are a lot of promises that never get resolved or rejected in the app. |
Hmm. Would that not mean that they would not be eligible for reclamation by the GC then? I know you said the node debugger affects the way async works, but the only promises that remain around are the ones for the |
|
The way promises work in Node, if it's never resolved/rejected, but there is nothing in code that references either the promise, or the |
|
That's a good point to note. There aren't any obvious cases like that for the application code, but it may be a shared dependency. I'll do some more testing to see if I can narrow down the debugging surface area. By the way, did anything else stand out from the flare I sent earlier today? |
Not really. In general flares are mostly useful to troubleshoot issues with the agent, backend, or when we are not sure where the issue comes from. In this case the issue is clearly within the app and the interaction with the tracer, so flares wouldn't really provide more information. |
This got me thinking so I added to the I basically added the Here is the output of my tests with node available memory set to 45MB: Here is the code that generated the above: logger.info('Setting log level to "info"...')
logger.level = 'info'
const memoryInMb = raw => (raw / 1024 / 1024).toFixed(2)
const totalMb = memoryInMb(totalHeapSize)
const displayMemoryUsage = () => {
const usedHeapSize = v8.getHeapStatistics().used_heap_size
const usedMb = memoryInMb(usedHeapSize)
const usedPercentage = (usedHeapSize / totalHeapSize).toLocaleString(undefined, { style: 'percent', minimumFractionDigits: 2 })
logger.info({ used: Math.round(usedMb), total: Math.round(totalMb), usedPercentage }, 'Memory (MB):')
}
let created = 0
const current = new Set()
const unresolved = new Set()
setInterval(() => {
logger.info({ created, current: current.size, unresolved: unresolved.size }, 'Promises:')
displayMemoryUsage()
}, 5000)
require('async_hooks').createHook({
init: (asyncId, type) => {
if (type === 'PROMISE') {
current.add(asyncId)
unresolved.add(asyncId)
created++
}
},
destroy: (asyncId) => {
current.delete(asyncId)
},
promiseResolve: (asyncId) => {
unresolved.delete(asyncId)
}
}).enable()I'll deploy something similar to our staging environment and see if any promise leak shows up there. |
|
Definitely make sure to check the metric in Datadog as well to make sure it matches what you see in your logs. |
After running the tests locally I added the code to our boilerplate project that we use as a starting point for our backend services. From the start of the chart we had No artificial load was created on the application. It's basically the k8s health check hitting the
|
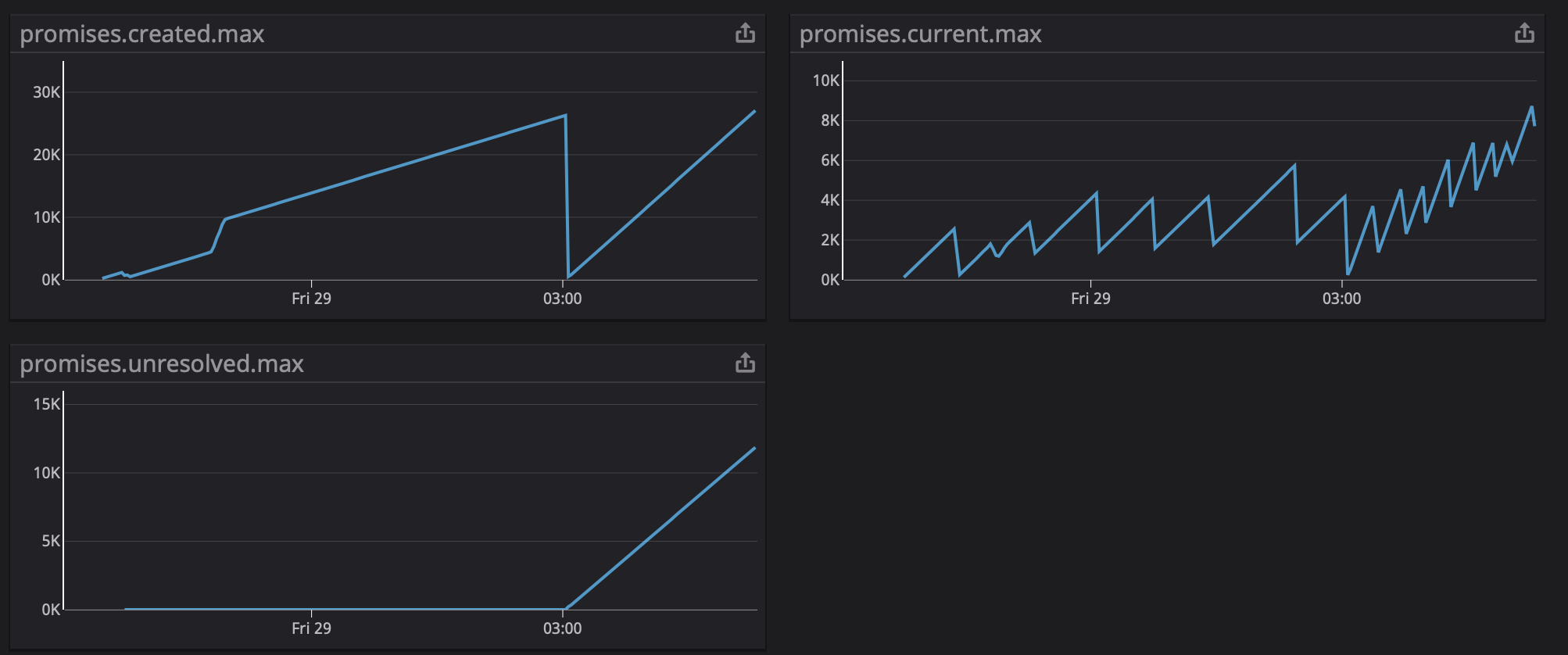
|
Is the boilerplate code public? Reproducing this locally would help me a lot to find what could be holding promises. |
|
Unfortunately not, but I can attach it to the support ticket by replying to the email thread if that can work? |
|
That works. As soon as it's on the ticket I'll look into it. |
|
Thank you. Email sent. |
|
Can you try with |
That definitely made a difference. The
It's only run for 30 minutes, but it looks really promising. |

|
It looks like the issue could be coming from our scope tracking for non-native promises when using async/await. If you do not use non-native promises, it should be safe to keep the option off. In any case, the worst that could happen without the option is a disconnected trace, which is definitely better than a memory leak. I'll continue to investigate with the boilerplate, but this is a good starting point to narrow down the issue. |
|
Awesome! Thanks for being so supportive and responsive! We almost exclusively use async/await where we can, so I'm happy with the trade-off. Please let me know if you want me to try anything else. I'm happy to help! 😄 |
|
I fixed the issue where the promise created by the Can you try with 0.17.0-beta.10 and re-enable |
|
Great, thanks! I'll try it today and report back. |
I can confirm that the fix works as expected. In the case of the boilerplate, the unresolved promise count remains at 2, even with tracing and track async scope enabled. |
|
Perfect! The fix will be in the next release which will be published this week. Thanks a lot for the very thorough details provided, it helped me a lot to pinpoint the exact issue. |
|
Just released 0.16.2 with the fix. Please let me know if that fixes the memory increase. |
|
We've been running this fix on staging for about 6 hours, and I can confirm the memory doesn't increase. Thanks again @rochdev! 🙌 |
Describe the bug
We're experiencing several crashes per day caused by out of memory exceptions. After debugging for a while we discovered that disabling tracing resolved the issue. We also tried disabling all plugins, but that still resulted in the out of memory exceptions.
Environment
The text was updated successfully, but these errors were encountered: