Ristretto是一个自动化的CNN近似工具,可以压缩32位浮点网络。
Ristretto是Caffe的扩展,允许以有限的数字精度测试、训练和微调网络。
本文介绍了几种网络压缩的方法,压缩特征图和参数。
方法包括:
定点法(Fixed Point Approximation)、
动态定点法(Dynamic Fixed Point Approximation)、
迷你浮点法(Minifloat Approximation)和
乘法变移位法(Turning Multiplications Into Bit Shifts),
所压缩的网络包括LeNet、CIFAR-10、AlexNet和CaffeNet等。
注:Ristretto原指一种特浓咖啡(Caffe),本文的Ristretto沿用了Caffe的框架。
Ristretto: Hardware-Oriented Approximation of Convolutional Neural Networks
Ristretto工具使用不同的比特宽度进行数字表示,
执行自动网络量化和评分,以在压缩率和网络准确度之间找到一个很好的平衡点。
Ristretto工具可以自动量化32位浮点网络,使用缩小字宽算法。
ristretto命令行接口根据用户指定的最大精度下降量找到尽可能最小的位宽表示。
而且,该工具生成量化网络的protocol buffer定义文件。
该工具被编译为./build/tools/ristretto。不带参数运行ristretto可输出帮助
例子:
以下命令将LeNet量化为动态固定点:
./build/tools/ristretto quantize --model=examples/mnist/lenet_train_test.prototxt \
--weights=examples/mnist/lenet_iter_10000.caffemodel \
--model_quantized=examples/mnist/quantized.prototxt \
--iterations=100 --gpu=0 --trimming_mode=dynamic_fixed_point --error_margin=1
参数:
model:32位浮点网络的网络定义。
weights:32位浮点网络的训练网络参数。
trimming_mode:量化策略可以是dynamic_fixed_point、minifloat或integer_power_of_2_weights。*
model_quantized:由此产生的量化的网络定义。
error_margin:与32位浮点数网络相比绝对精度下降百分比。
GPU:GPU ID,Ristretto支持CPU和GPU模式。
iterations:用于评分网络的批次迭代次数。
*在早期版本的Ristretto(在提交fc109ba之前),trimming_mode曾经是fixed_point、mini_floating_point、power_of_2_weights。
Ristretto重新实现Caffe层并模拟缩短字宽的算术。
测试和训练:
由于将Ristretto平滑集成Caffe,可以改变网络描述文件来量化不同的层。
不同层所使用的位宽以及其他参数可以在网络的prototxt文件中设置。
这使得我们能够直接测试和训练压缩后的网络,而不需要重新编译。
Ristretto允许以三种不同的量化策略来逼近卷积神经网络:
1、动态固定点:修改的定点格式。
2、Minifloat:缩短位宽的浮点数。
3、两个幂参数:当在硬件中实现时,具有两个幂参数的层不需要任何乘法器。
这个改进的Caffe版本支持有限数值精度层。所讨论的层使用缩短的字宽来表示层参数和层激活(输入和输出)。
由于Ristretto遵循Caffe的规则,已经熟悉Caffe的用户会很快理解Ristretto。
下面解释了Ristretto的主要扩展:
Ristretto引入了新的有限数值精度层类型。
这些层可以通过传统的Caffe网络描述文件(* .prototxt)使用。
下面给出一个minifloat卷积层的例子:
layer {
name: "conv1"
type: "ConvolutionRistretto"
// 其他类还有 FcRistretto(全连接层),LRNRistretto(局部响应归一化)、DeconvolutionRistretto(反卷积)。
bottom: "data"
top: "conv1"
convolution_param {
num_output: 96
kernel_size: 7
stride: 2
weight_filler {
type: "xavier"
}
}
quantization_param {
precision: MINIFLOAT # MANT:mantissa,尾数(有效数字)
// precision 量化策略 DYNAMIC_FIXED_POINT \ MINIFLOAT 或 INTEGER_POWER_OF_2_WEIGHTS
// rounding_scheme 量化的舍入方案 最近偶数(NEAREST)或随机舍入(STOCHASTIC)
mant_bits: 10 // [default:23]:用于表示尾数的位数
exp_bits: 5 /
}
}
//////////////////////////
Minifloat
精度类型:MINIFLOAT
参数:
mant_bits[默认值:23]:用于表示尾数的位数
exp_bits[default:8]:用于表示指数的位数
默认值对应于单精度格式
////////////////////////////
整数幂参数
精度类型:INTEGER_POWER_OF_2_WEIGHTS
参数:
exp_min[默认值:-8]:使用的最小指数
exp_max[默认值:-1]:使用的最大指数
对于默认值,网络参数可以用硬件中的4位表示(1个符号位,3位指数值)
该层将使用半精度(16位浮点)数字表示。
卷积内核、偏差以及层激活都被修剪为这种格式。
注意与传统卷积层的三个不同之处:
1、type变成了ConvolutionRistretto;
2、增加了一个额外的层参数:quantization_param;
3、该层参数包含用于量化的所有信息。
Ristretto允许精确模拟资源有限的硬件加速器。
为了与Caffe规则保持一致,Ristretto在层参数和输出中重用浮点Blob。
这意味着有限精度数值实际上都存储在浮点数组中。
对于量化网络的评分,Ristretto要求
a. 训练好的32位FP网络参数
b. 网络定义降低精度的层
第一项是Caffe传统训练的结果。Ristretto可以使用全精度参数来测试网络。
这些参数默认情况下使用最接近的方案,即时转换为有限精度。
至于第二项——模型说明——您将不得不手动更改Caffe模型的网络描述,
或使用Ristretto工具自动生成Google Protocol Buffer文件。
# score the dynamic fixed point SqueezeNet model on the validation set*
./build/tools/caffe test --model=models/SqueezeNet/RistrettoDemo/quantized.prototxt \
--weights=models/SqueezeNet/RistrettoDemo/squeezenet_finetuned.caffemodel \
--gpu=0 --iterations=2000
了提高精简网络的准确性,应该对其进行微调。
在Ristretto中,Caffe命令行工具支持精简网络微调。
与传统训练的唯一区别是网络描述文件应该包含Ristretto层。
微调需要以下项目:
1、32位FP网络参数, 网络参数是Caffe全精度训练的结果。
2、用于训练的Solver和超参数
解算器(solver)包含有限精度网络描述文件的路径。
这个网络描述和我们用来评分的网络描述是一样的。
# fine-tune dynamic fixed point SqueezeNet*
./build/tools/caffe train \
--solver=models/SqueezeNet/RistrettoDemo/solver_finetune.prototxt \
--weights=models/SqueezeNet/squeezenet_v1.0.caffemodel 在这个再训练过程中,网络学习如何用限定字参数对图像进行分类。
由于网络权重只能具有离散值,所以主要挑战在于权重更新。
我们采用以前的工作(Courbariaux等1)的思想,它使用全精度因子权重(full precision shadow weights)。
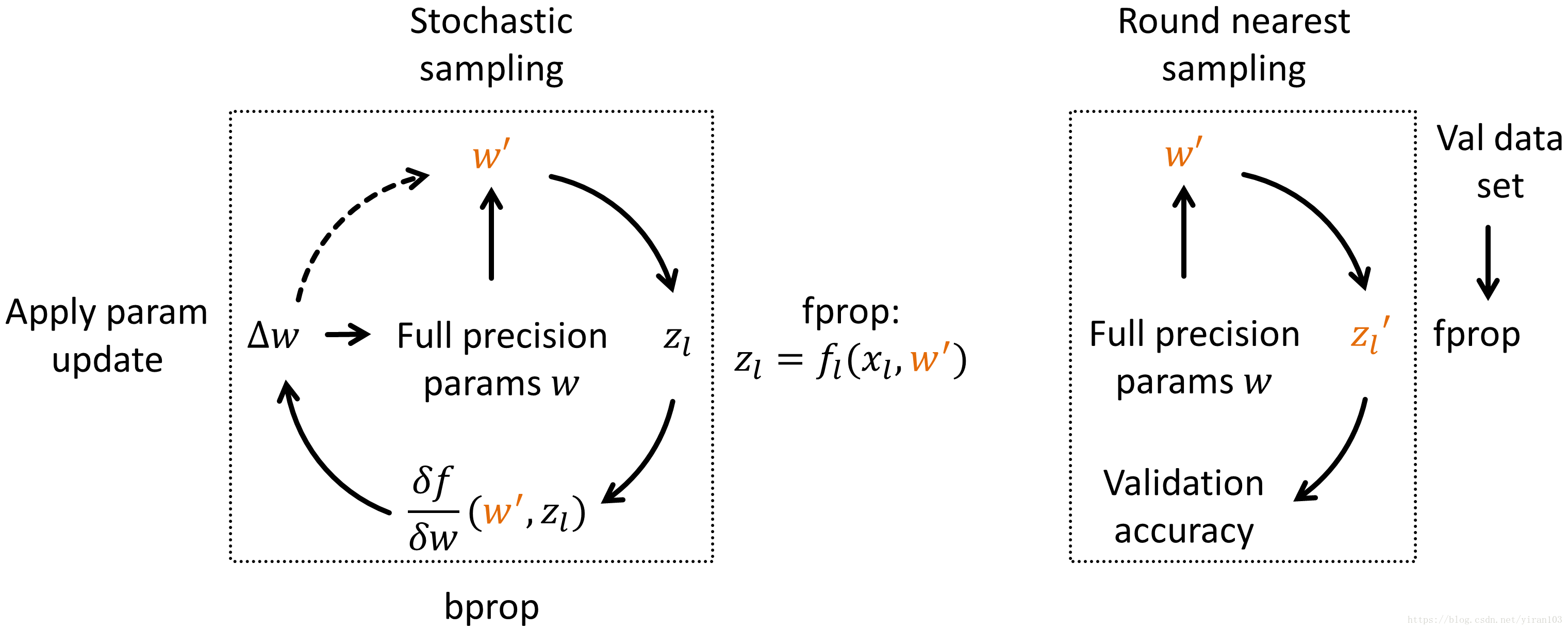
对32位FP权重w应用小权重更新,从中进行采样得到离散权重w'。
微调中的采样采用 随机舍入方法(Round nearest sampling) 进行,Gupta等2人成功地使用了这种方法,
以16位固定点来训练网络。
输入特征图input feature maps( IFM) : 通道数量 N
卷积核尺寸kernel:M*N*K*K 大小K*K 数量:M 每个卷积核的深度: N
输出特征图output feature map( OFM ): 通道数量 M尺寸大小(R,C, 与输入尺寸和步长、填充有关)
for(m =0; m<M; m++) // 每个卷积核
for(n =0; n<N; n++) // 每个输入通道
for(r =0; r<R; r++) // 输出尺寸的每一行
for(c =0; c<C; c++) // 输出尺寸的每一列
for(i =0; i<K; i++) // 方框卷积运算的每一行
for(j =0; j<K; j++)// 方框卷积运算的每一列
OFM[m][r][c] += IFM[n][r*S + i][c*S + j] * kernel[m][n][i][j]; // S为卷积步长时间复杂度: O(R*C*M*N*K^2)
卷积核参数数量:O(M*N*K^2) 内存复杂度
浮点数的二进制表示:
3.14159 我们直接对它进行转换,则为11.0010010000111111001…
1*2^1 + 1*2^0 + 1*2(-3)+....
用这种方法我们无法把3.14159精确表示,绝大多数是无法精确表示.
对十进制表示的数的每一位,使用一个4位的二进制来表达(2^3<9, 3位不够,需要4位)
例如 3.14159 对其每一位上的数字使用 4位的二进制数来表达。
0011 0001 0100 0001 0101 1001
3 1 4 1 5 9
a. 最简单的 8421BCD码:对应多大的数就用多大的二进制来表示,比如上面的。
0001 0010 0100 1000 4位上分别一位上位1对应 1 2 4 8 所以称为8421码。
b. 余三码
把8421BCD码的每个编码加上3就得到了余三码。
c. 循环码
把8421BCD码的每个编码,
最高位照旧,后面每一位与前一位取异或(不同为1,相同为0),就得到了循环码。
这种思想来源于数学中的指数表示形式(科学计数法形式);
10进制科学计数法 34.1 = 3.41 * 10^1
2进制科学计数法 11.11 = 1.111 * 2^1
一个二进制数 B 可以写成 B = 2^E * M
一个十进制数 D 可以写成 D = 10^E * M
一个R进制数 X 可以写成 X = R^E * M
其中 E为指数,M为尾数, R为基数 。
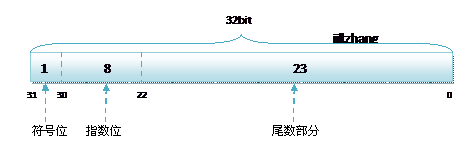
32位浮点数在计算机中的实际存储方式:
分为三个部分:
符号位(Sign) : 0代表正,1代表为负, 1位就可以表示
指数位(Exponent): 用于存储科学计数法中的指数数据(整数),并且采用移位存储,8位表示
原数绝对值小于1的话,指数位小于0
袁术绝对值大于1的话,指数位大于0
所以需要 8位来表示正负范围的整数,
最高位为指数位的符号位,剩下7位为整数部分的二进制表示
-2^7 ~2^7-1,也就是 -128 ~ 127
127 + 2 = -127;-127 - 2 = 127
所以指数部分的存储采用移位存储,
存储的数据为 原数据+127 基数 bais = 2^(8-1) - 1 =127
尾数部分(Mantissa):尾数部分, 23位表示,
而2进制的科学表示的尾数部分第一位都是1,可以省略,
所以在还原时要先在第一位加上1。
所以23位,实际上可以表示24位的精度。
1/2^23次方 可以达到 10^(-6)次方,能精确到小数点后6位。
float的内存结构,我用一个带位域的结构体描述如下:
struct MYFLOAT
{
bool bSign : 1; // S 符号,表示正负,1位
char cExponent : 8; // E 指数,8位
unsigned long ulMantissa : 23; // M 尾数,23位
};
// B = (-1)^S * 2^E * M
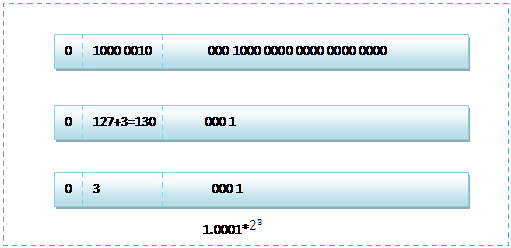
8.5,用二进制的科学计数法表示为: 1.0001*2^3
按照上面的存储方式,符号位为:0,表示为正,指数位为:3+127=130 ,尾数部分为1.0001,省略最前面的1,为 0001
定点数:
所谓定点格式,即约定机器中所有数据的小数点位置是固定不变的。
通常将定点数据表示成纯小数或纯整数。
为了将数表示成纯小数,通常把小数点固定在数值部分的最高位之前;
而为了把数表示成纯整数,则把小数点固定在数值部分的最后面。

所谓定点数和浮点数,
是指在计算机中一个数的小数点的位置是固定的还是浮动的:
如果一个数中小数点的位置是固定的,则为定点数;
如果一个数中小数点的位置是浮动的,则为浮点数。
一般来说,定点格式可表示的数值的范围有限,但要求的处理硬件比较简单。
而浮点格式可表示的数值的范围很大,但要求的处理硬件比较复杂。
IL.FL
固定整数位二进制长度和小数位二进制长度。
最大表示数:
Xmax = 2^(IL-1) - 2^(-FL)
32浮点数----->8位定点(Q4.4)
----->16位定点 ( Q8.8 Q9.7)
例如 0 1 1 0 1 1 0 1 , FL = 2
符号位: 0
尾数部分全部作为整数位: 1 1 0 1 1 0 1 B = 109D
小数部分最后两位,所以整体需要除以2^(2)
则表示的数为: R = (-1)^0 * 109 * 2^(-2) = 27.25
浮点数 ff 得到量化的数:
放大/缩小: sff = ff * 2^(fl)
取整: round(sff)
CNN的不同部分具有显着的动态范围,
在大的层中,输出是数以千计的积累的结果,因此网络参数比层输出小得多。
定点只具有有限的能力来覆盖宽动态范围。
使用B位来表示,其中一位符号位s, fl是分数长度(小数长度),其余为整数位,
除去符号位s,后面的都是尾数,每个尾数位数字为xi
n = (-1)^s * 2^(-fl)*sum(2^i * xi) , 0 =< i <= B-2
第一项确定符号,
第二项确定分数比例,
第三项确定总值大小(所有尾数对应的十进制的值)。
由于网络中的中间值具有不同的范围,所以希望将定点数值分组为具有常数f1(不同小数长度)的组中。
所以分配给小数部分的比特数在 同一组内是恒定的,但与其他组相比是不同的。
这里每个网络层分为三组:
一个用于层输入,
一个用于权重,
一个用于层输出。
这可以更好地覆盖层激活和权重的动态范围,因为权重通常特别小,层的输入输出通常比较大(上一层各个神经元累计)。
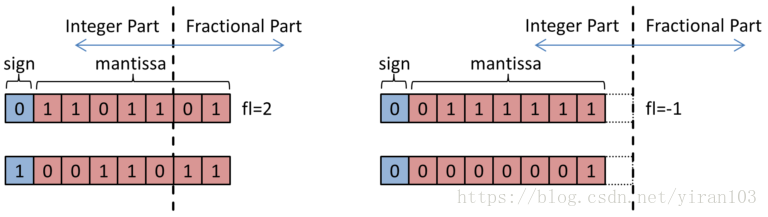
上图为4个数 属于 两个不同组 的 动态定点数的例子。
注意第二组的 分数长度 是负数。
所以第二组的分数长度是-1,整数长度是9,位宽是8。
第一组的分数长度为2,整数长度为6,位宽为8.
IEEE-754 32位浮点数:
struct MYFLOAT
{
bool bSign : 1; // S 符号,表示正负,1位
char cExponent : 8; // E 指数,8位,存储的时候,比实际的多 127
unsigned long ulMantissa : 23; // M 尾数,23位
};
// B = (-1)^S * 2^E * M
// 不过指数部分在存储的时候回 加上127(使用移位存储, 正负表达的范围较平均)
// 所以 指数部分按二进制数转到10进制数后需要减去 127, E = E' - 127
bSign --- cExponent --- ulMantissa
符号位 --- 指数位 --- 尾数位
迷你浮点数 16bit 5位指数部分 10位位数部分(精度, 1/(2^(10)) = 0.0009765, 精确到小数点后3位 )

由于神经网络的训练是以浮点的方式完成的,
所以将这些模型压缩成比特宽度减少的浮点数是一种直观的方法。
为了压缩网络并减少计算和存储需求,Ristretto可以用比IEEE-754标准少得多的位表示浮点数。
我们在16bit、8bit甚至更小的数字上都遵循这个标准,但是我们的格式在一些细节上有所不同。
也就是说,根据分配给指数的比特数降低指数偏差:
bias = 2^(exp_bits−1) − 1, 这里exp_bits提供分配给指数的位数。
例如8位指数,为了表示正负,使用移位存储,
存储的数据为 原数据+127 , 基数 bais = 2^(8-1) - 1 =127
与IEEE标准的另一个区别是我们不支持非规范化的数字,I
NF和NaN。INF由饱和数字代替,
非规格化数字NaN 由0代替。
最后,分配给指数和尾数部分的位数不遵循特定的规则。
更确切地说,Ristretto选择指数位,以避免发生饱和。
直接量化成 二进制位的形式,最高位位符号位S,后面的二进制指数部分
例如4bits
1100
第一个1为符号位,后面3个表示指数部分(-1~-8)
n=(−1)^s * 2^exp
动态固定点: 1、首先Ristretto分析层参数和输出。该工具选择在整数部分使用足够的位来避免最大值溢出。 Ristretto对如下层搜索可能的最低位宽 卷积层参数 全连接层参数 卷积层和完全连接层的激活输出 2、Minifloat: 首先Ristretto分析层激活。 该工具选择使用足够的指数位来避免最大值溢出。 Ristretto对如下层搜索可能的最低位宽 卷积和全连接层的参数和激活 3、整数幂参数: Ristretto以4-bit参数网络为基准,分别选择-8和-1作为最低和最高指数。 激活是在8位动态固定点。
1、下载原始 32bit FP 浮点数 网络权重
并将它们放入models/SqueezeNet/文件夹中。这些是由DeepScale提供的预训练好的32位FP权重。
2、微调再训练一个低精度 网络权重
我们已经为您fine-tuned了一个8位动态定点SqueezeNet。
从models/SqueezeNet/RistrettoDemo/ristrettomodel-url提供的链接下载它,并将其放入该文件夹。
3、对SqueezeNet prototxt(models/SqueezeNet/train_val.prototxt)做两个修改
a. imagenet 数据集下载 较大 train 100G+
http://www.image-net.org/challenges/LSVRC/2012/nnoupb/ILSVRC2012_img_val.tar
http://www.image-net.org/challenges/LSVRC/2012/nnoupb/ILSVRC2012_img_train.tar
解压:
tar -zxvf
b. 标签文件下载
http://dl.caffe.berkeleyvision.org/caffe_ilsvrc12.tar.gz
解压:
tar -xf caffe_ilsvrc12.tar.gz
放在 data/ilsvrc12 下面
c. 生成 lmdb数据库文件
./examples/imagenet/create_imagenet.sh 里面需要修改 上面下载的数据集的路径
得到两个数据库文件目录:
examples/imagenet/ilsvrc12_train_leveldb
examples/imagenet/ilsvrc12_val_leveldb
d. 生成数据库图片的均值文件
./examples/imagenet/make_imagenet_mean.sh
得到:
data/ilsvrc12/imagenet_mean.binaryproto
e. 修改 models/SqueezeNet/train_val.prototxt
网络配置文件中 训练和测试数据集数据库格式文件地址
source: "examples/imagenet/ilsvrc12_train_lmdb"
source: "examples/imagenet/ilsvrc12_val_lmdb"
首先安装Ristretto(make all -j 见最上面的代码 ),并且在Caffe的根路径下运行所有命令。
SqueezeNet在32位和16位动态定点上表现良好,但是我们可以进一步缩小位宽。
参数压缩和网络准确性之间有一个折衷。
Ristretto工具可以自动为网络的每个部分找到合适的位宽:
运行量化网络:
./examples/ristretto/00_quantize_squeezenet.sh
./build/tools/ristretto quantize \ # 工具
--model=models/SqueezeNet/train_val.prototxt \ # 全精度网络模型
--weights=models/SqueezeNet/squeezenet_v1.0.caffemodel \ #全精度网络权重
--model_quantized=models/SqueezeNet/RistrettoDemo/quantized.prototxt \ # 自动生成的量化网络模型文件
--trimming_mode=dynamic_fixed_point \ # 量化类型 动态定点
--gpu=0 \
--iterations=2000 \
--error_margin=3这个脚本将量化SqueezeNet模型。
你会看到飞现的信息,Ristretto以不同字宽测试量化模型。
最后的总结将如下所示:
I0626 16:56:25.035650 14319 quantization.cpp:260] Network accuracy analysis for
I0626 16:56:25.035667 14319 quantization.cpp:261] Convolutional (CONV) and fully
I0626 16:56:25.035681 14319 quantization.cpp:262] connected (FC) layers.
I0626 16:56:25.035693 14319 quantization.cpp:263] Baseline 32bit float: 0.5768
I0626 16:56:25.035715 14319 quantization.cpp:264] Dynamic fixed point CONV
I0626 16:56:25.035728 14319 quantization.cpp:265] weights:
I0626 16:56:25.035740 14319 quantization.cpp:267] 16bit: 0.557159
I0626 16:56:25.035761 14319 quantization.cpp:267] 8bit: 0.555959
I0626 16:56:25.035781 14319 quantization.cpp:267] 4bit: 0.00568
I0626 16:56:25.035802 14319 quantization.cpp:270] Dynamic fixed point FC
I0626 16:56:25.035815 14319 quantization.cpp:271] weights:
I0626 16:56:25.035828 14319 quantization.cpp:273] 16bit: 0.5768
I0626 16:56:25.035848 14319 quantization.cpp:273] 8bit: 0.5768
I0626 16:56:25.035868 14319 quantization.cpp:273] 4bit: 0.5768
I0626 16:56:25.035888 14319 quantization.cpp:273] 2bit: 0.5768
I0626 16:56:25.035909 14319 quantization.cpp:273] 1bit: 0.5768
I0626 16:56:25.035938 14319 quantization.cpp:275] Dynamic fixed point layer
I0626 16:56:25.035959 14319 quantization.cpp:276] activations:
I0626 16:56:25.035979 14319 quantization.cpp:278] 16bit: 0.57578
I0626 16:56:25.036012 14319 quantization.cpp:278] 8bit: 0.57058
I0626 16:56:25.036051 14319 quantization.cpp:278] 4bit: 0.0405805
I0626 16:56:25.036073 14319 quantization.cpp:281] Dynamic fixed point net:
I0626 16:56:25.036087 14319 quantization.cpp:282] 8bit CONV weights,
I0626 16:56:25.036100 14319 quantization.cpp:283] 1bit FC weights,
I0626 16:56:25.036113 14319 quantization.cpp:284] 8bit layer activations:
I0626 16:56:25.036126 14319 quantization.cpp:285] Accuracy: 0.5516
I0626 16:56:25.036141 14319 quantization.cpp:286] Please fine-tune.分析表明,卷积层的激活和参数都可以降低到8位,top-1精度下降小于3%。
由于SqueezeNet不包含全连接层,因此可以忽略该层类型的量化结果。
最后,该工具同时量化所有考虑的网络部分。
结果表明,8位SqueezeNet具有55.16%的top-1精度(与57.68%的基准相比)。
为了改善这些结果,我们将在下一步中对网络进行微调。
上一步将 32位浮点 SqueezeNet 量化为 8位固定点,
并生成相应的量化网络描述文件(models/SqueezeNet/RistrettoDemo/quantized.prototxt)。
现在我们可以微调浓缩的网络,尽可能多地恢复原始的准确度。
在微调期间,Ristretto会保持一组高精度的 权重。
对于每个训练batch,这些32位浮点权重 随机 四舍五入为 8位固定点。
然后将8位参数 用于前向 和 后向传播,最后将 权重更新 应用于 高精度权重。
微调程序可以用传统的caffe工具 ./build/tools/caffe train 来完成。
只需启动以下脚本:
./examples/ristretto/01_finetune_squeezenet.sh
//////////内容
#!/usr/bin/env sh
# finetune 微调
SOLVER="../../models/SqueezeNet/RistrettoDemo/solver_finetune.prototxt" # 微调求解器
WEIGHTS="../../models/SqueezeNet/squeezenet_v1.0.caffemodel" # 原始 全精度权重
./build/tools/caffe train \
--solver=$SOLVER \
--weights=$WEIGHTS
经过1200次微调迭代(Tesla K-40 GPU〜5小时), batch大小为32 * 32,
压缩后的SqueezeNet将具有57%左右的top-1验证精度。
微调参数位于models/SqueezeNet/RistrettoDemo/squeezenet_iter_1200.caffemodel。
总而言之,您成功地将SqueezeNet缩减为8位动态定点,精度损失低于1%。
请注意,通过改进数字格式(即对网络的不同部分 选择整数 和 分数长度),可以获得稍好的最终结果。
在这一步中,您将对现有的动态定点SqueezeNet进行基准测试,我们将为您进行微调。
即使跳过上一个微调步骤,也可以进行评分。
该模型可以用传统的caffe-tool进行基准测试。
所有的工具需求都是一个网络描述文件以及网络参数。
./examples/ristretto/02_benchmark_fixedpoint_squeezenet.sh
//////////内容
./build/tools/caffe test \ # 测试模式
--model=models/SqueezeNet/RistrettoDemo/quantized.prototxt \ # 量化网络文件
--weights=models/SqueezeNet/RistrettoDemo/squeezenet_finetuned.caffemodel \ # 量化网络权重
--gpu=0 \
--iterations=2000./examples/ristretto/benchmark_floatingpoint_squeezenet.sh
//////////内容
./build/tools/caffe test \
--model=models/SqueezeNet/train_val.prototxt \
--weights=models/SqueezeNet/squeezenet_v1.0.caffemodel \
--gpu=0 --iterations=2000// 具体量化方式
#include <math.h>
#include <algorithm>
#include <stdlib.h>
#include <time.h>
#include "ristretto/base_ristretto_layer.hpp"
namespace caffe {
template <typename Dtype>
BaseRistrettoLayer<Dtype>::BaseRistrettoLayer() {
// Initialize random number generator
srand(time(NULL));// 随机数种子=================
}
// 量化卷积参数==========================
// f(n) = relu(w*a + b )
template <typename Dtype>
void BaseRistrettoLayer<Dtype>::QuantizeWeights_cpu(
vector<shared_ptr<Blob<Dtype> > > weights_quantized,// [w b]
const int rounding,
const bool bias_term)
{
// 量化的卷积层参数 w
Dtype* weight = weights_quantized[0]->mutable_cpu_data();
// count() 总数
const int cnt_weight = weights_quantized[0]->count();
// 量化的卷积层参数 b
Dtype* bias = weights_quantized[1]->mutable_cpu_data();
// count() 总数
const int cnt_bias = weights_quantized[1]->count();
switch (precision_) // 不同量化策略
{
// 迷你浮点=======
case QuantizationParameter_Precision_MINIFLOAT:
Trim2MiniFloat_cpu(weight, cnt_weight, fp_mant_, fp_exp_, rounding);
if (bias_term)
{
Trim2MiniFloat_cpu(bias, cnt_bias, fp_mant_, fp_exp_, rounding);
}
break;
// 动态固定点========
case QuantizationParameter_Precision_DYNAMIC_FIXED_POINT:
Trim2FixedPoint_cpu(weight, cnt_weight, bw_params_, rounding, fl_params_);
if (bias_term)// 量化偏置 b w*a + b
{// 起始指针 数量 总位宽 取整策略 小数位宽
Trim2FixedPoint_cpu(bias, cnt_bias, bw_params_, rounding, fl_params_);
}
break;
// 2幂次===========
case QuantizationParameter_Precision_INTEGER_POWER_OF_2_WEIGHTS:
Trim2IntegerPowerOf2_cpu(weight, cnt_weight, pow_2_min_exp_, pow_2_max_exp_,
rounding);
// Don't trim bias
break;
default:
LOG(FATAL) << "Unknown trimming mode: " << precision_;
break;
}
}
// 量化层输入=============================
template <typename Dtype>
void BaseRistrettoLayer<Dtype>::QuantizeLayerInputs_cpu(
Dtype* data,
const int count)
{
switch (precision_)
{
// 2幂次===========
case QuantizationParameter_Precision_INTEGER_POWER_OF_2_WEIGHTS:
break;
// 动态固定点========
case QuantizationParameter_Precision_DYNAMIC_FIXED_POINT:
// 起始指针 数量 总位宽 取整策略 小数位宽
Trim2FixedPoint_cpu(data, count, bw_layer_in_, rounding_, fl_layer_in_);
break;
// 迷你浮点=======
case QuantizationParameter_Precision_MINIFLOAT:
Trim2MiniFloat_cpu(data, count, fp_mant_, fp_exp_, rounding_);
break;
default:
LOG(FATAL) << "Unknown trimming mode: " << precision_;
break;
}
}
// 量化层输出================================
template <typename Dtype>
void BaseRistrettoLayer<Dtype>::QuantizeLayerOutputs_cpu(
Dtype* data,
const int count)
{
switch (precision_)
{
// 2幂次===========
case QuantizationParameter_Precision_INTEGER_POWER_OF_2_WEIGHTS:
break;
// 动态固定点========
case QuantizationParameter_Precision_DYNAMIC_FIXED_POINT:
// 起始指针 数量 总位宽 取整策略 小数位宽
Trim2FixedPoint_cpu(data, count, bw_layer_out_, rounding_, fl_layer_out_);
break;
// 迷你浮点=======
case QuantizationParameter_Precision_MINIFLOAT:
Trim2MiniFloat_cpu(data, count, fp_mant_, fp_exp_, rounding_);
break;
default:
LOG(FATAL) << "Unknown trimming mode: " << precision_;
break;
}
}
// 动态固定点方式量化数据============================
template <typename Dtype>
void BaseRistrettoLayer<Dtype>::Trim2FixedPoint_cpu(
Dtype* data, // 数据 起始指针
const int cnt, // 数量
const int bit_width, // 量化总位宽
const int rounding, // 取整策略
int fl) // 小数位位宽
{
for (int index = 0; index < cnt; ++index)
{
// Saturate data 饱和数处理
// 例如 0 1 1 0 1 1 0 1 , bit_width= 8, fl = 2
// 最高位符号位,所以余下的数为 1 1 0 1 1 0 1 = 109D (假设全部作为整数位)
// 实际小时位有2位,所以小数点需要向前移动 2位
// 所以实际表示的数为 2^0 * 109 * 2(-2) = 27.25
// 所以 总位宽 bit_width 小数位长度 fl
// 表示的最大数为 (2^(bit_width-1) - 1)/(2^fl) = (2^(bit_width - 1) - 1)*(2^(-fl))
// 最小的数为 -1 * (2^(bit_width - 1) - 1)*(2^(-fl))
Dtype max_data = (pow(2, bit_width - 1) - 1) * pow(2, -fl);// 最大数
Dtype min_data = -pow(2, bit_width - 1) * pow(2, -fl);// 最小数
// 首先数据包和处理,比最大值小,比最小值大
data[index] = std::max(std::min(data[index], max_data), min_data);
// Round data
data[index] *= pow(2, fl);// 按小数位乘方系数 放大或者缩小
//data[index] /= pow(2, -fl);// 27.25125 * 2^2----> 109.005
// 放大后再取整================== 109.005 ----> 109/110
switch (rounding)
{
// 最近偶数(NEAREST)
case QuantizationParameter_Rounding_NEAREST:
data[index] = round(data[index]);
break;
// 随机舍入(STOCHASTIC)
case QuantizationParameter_Rounding_STOCHASTIC:
data[index] = floor(data[index] + RandUniform_cpu());
break;
default:
break;
}
// 取整后再缩小 109/110 ----> 109 / 2^2 = 27.25
//data[index] *= pow(2, -fl);
data[index] /= pow(2, fl);// 相当于去除了超过小数位的部分============
}
}
/* 部分调整 借鉴inq,逐步量化,先从最大的部分开始量化
// float quant_percent = 0.3; // 需要在前面 定义
//////////////////// 固定点量化
template <typename Dtype>
void BaseRistrettoLayer<Dtype>::Trim2FixedPoint_cpu(
Dtype* data, const int cnt,
const int bit_width,
const int rounding,
int fl)
{
// 上下限计算
Dtype max_data = (pow(2, bit_width - 1) - 1) * pow(2, -fl);
Dtype min_data = -pow(2, bit_width - 1) * pow(2, -fl);
// 获取 有序 数列
Dtype* data_copy=(Dtype*) malloc(cnt*sizeof(Dtype));
caffe_copy(cnt,data,data_copy);
caffe_abs(cnt,data_copy,data_copy);
std::sort(data_copy,data_copy+cnt); //data_copy order from small to large
int partition=int(cnt*(1-quant_percent))-1;
for (int index = 0; index < cnt; ++index)
{
if(std::abs(data[index]) >= data_copy[partition])
{
// Saturate data
data[index] = std::max(std::min(data[index], max_data), min_data);
// Round data
data[index] /= pow(2, -fl);
switch (rounding)
{
case QuantizationParameter_Rounding_NEAREST:
data[index] = round(data[index]);
break;
case QuantizationParameter_Rounding_STOCHASTIC:
data[index] = floor(data[index] + RandUniform_cpu());
break;
default:
break;
}
data[index] *= pow(2, -fl);
// mask_vec[i]=0; // 标记量化标志
}
}
free(data_copy);// 释放空间
}
*/
// 迷你浮点量化======================================
typedef union {
float d;
struct {
unsigned int mantisa : 23; // 尾数位
unsigned int exponent : 8; // 指数位
unsigned int sign : 1; // 符号位
} parts;
} float_cast;
template <typename Dtype>
void BaseRistrettoLayer<Dtype>::Trim2MiniFloat_cpu(Dtype* data, const int cnt,
const int bw_mant, const int bw_exp, const int rounding) {
for (int index = 0; index < cnt; ++index) {
int bias_out = pow(2, bw_exp - 1) - 1;
float_cast d2;
// This casts the input to single precision
d2.d = (float)data[index];
int exponent=d2.parts.exponent - 127 + bias_out;
double mantisa = d2.parts.mantisa;
// Special case: input is zero or denormalized number
if (d2.parts.exponent == 0)
{
data[index] = 0;
return;
}
// Special case: denormalized number as output
if (exponent < 0)
{
data[index] = 0;
return;
}
// Saturation: input float is larger than maximum output float
int max_exp = pow(2, bw_exp) - 1;
int max_mant = pow(2, bw_mant) - 1;
if (exponent > max_exp)
{
exponent = max_exp;
mantisa = max_mant;
}
else
{
// Convert mantissa from long format to short one. Cut off LSBs.
double tmp = mantisa / pow(2, 23 - bw_mant);
switch (rounding)
{
case QuantizationParameter_Rounding_NEAREST:
mantisa = round(tmp);
break;
case QuantizationParameter_Rounding_STOCHASTIC:
mantisa = floor(tmp + RandUniform_cpu());
break;
default:
break;
}
}
// Assemble result
data[index] = pow(-1, d2.parts.sign) * ((mantisa + pow(2, bw_mant)) /
pow(2, bw_mant)) * pow(2, exponent - bias_out);
}
}
// 2幂次===========
template <typename Dtype>
void BaseRistrettoLayer<Dtype>::Trim2IntegerPowerOf2_cpu(Dtype* data,
const int cnt, const int min_exp, const int max_exp, const int rounding) {
for (int index = 0; index < cnt; ++index) {
float exponent = log2f((float)fabs(data[index]));
int sign = data[index] >= 0 ? 1 : -1;
switch (rounding) {
case QuantizationParameter_Rounding_NEAREST:
exponent = round(exponent);
break;
case QuantizationParameter_Rounding_STOCHASTIC:
exponent = floorf(exponent + RandUniform_cpu());
break;
default:
break;
}
exponent = std::max(std::min(exponent, (float)max_exp), (float)min_exp);
data[index] = sign * pow(2, exponent);
}
}
// 返回0~1之间的一个小数=====================
template <typename Dtype>
double BaseRistrettoLayer<Dtype>::RandUniform_cpu(){
return rand() / (RAND_MAX+1.0);
}
template BaseRistrettoLayer<double>::BaseRistrettoLayer();
template BaseRistrettoLayer<float>::BaseRistrettoLayer();
template void BaseRistrettoLayer<double>::QuantizeWeights_cpu(
vector<shared_ptr<Blob<double> > > weights_quantized, const int rounding,
const bool bias_term);
template void BaseRistrettoLayer<float>::QuantizeWeights_cpu(
vector<shared_ptr<Blob<float> > > weights_quantized, const int rounding,
const bool bias_term);
template void BaseRistrettoLayer<double>::QuantizeLayerInputs_cpu(double* data,
const int count);
template void BaseRistrettoLayer<float>::QuantizeLayerInputs_cpu(float* data,
const int count);
template void BaseRistrettoLayer<double>::QuantizeLayerOutputs_cpu(double* data,
const int count);
template void BaseRistrettoLayer<float>::QuantizeLayerOutputs_cpu(float* data,
const int count);
template void BaseRistrettoLayer<double>::Trim2FixedPoint_cpu(double* data,
const int cnt, const int bit_width, const int rounding, int fl);
template void BaseRistrettoLayer<float>::Trim2FixedPoint_cpu(float* data,
const int cnt, const int bit_width, const int rounding, int fl);
template void BaseRistrettoLayer<double>::Trim2MiniFloat_cpu(double* data,
const int cnt, const int bw_mant, const int bw_exp, const int rounding);
template void BaseRistrettoLayer<float>::Trim2MiniFloat_cpu(float* data,
const int cnt, const int bw_mant, const int bw_exp, const int rounding);
template void BaseRistrettoLayer<double>::Trim2IntegerPowerOf2_cpu(double* data,
const int cnt, const int min_exp, const int max_exp, const int rounding);
template void BaseRistrettoLayer<float>::Trim2IntegerPowerOf2_cpu(float* data,
const int cnt, const int min_exp, const int max_exp, const int rounding);
template double BaseRistrettoLayer<double>::RandUniform_cpu();
template double BaseRistrettoLayer<float>::RandUniform_cpu();
} // namespace caffe
// 绝对最大值
template <typename Dtype>
Dtype Net<Dtype>::findMax(Blob<Dtype>* blob) {
const Dtype* data = blob->cpu_data();
int cnt = blob->count();
Dtype max_val = (Dtype)-10;
for (int i = 0; i < cnt; ++i) {
max_val = std::max(max_val, (Dtype)fabs(data[i]));
}
return max_val;
}
// 最小值==================================
template <typename Dtype>
Dtype Net<Dtype>::findMin(Blob<Dtype>* blob) {
const Dtype* data = blob->cpu_data();
int cnt = blob->count();
Dtype min_val = (Dtype)+10;// 初始化+10
for (int i = 0; i < cnt; ++i)
{
// min=====
min_val = std::min(min_val, (Dtype)(data[i]));
}
return min_val;
}
// 最大值===================================
template <typename Dtype>
Dtype Net<Dtype>::findMaxNoAbs(Blob<Dtype>* blob) {
const Dtype* data = blob->cpu_data();
int cnt = blob->count();
Dtype max_val = (Dtype)-10;// 初始化 -10
for (int i = 0; i < cnt; ++i)
{
//max=======
max_val = std::max(max_val, (Dtype)(data[i]));
}
return max_val;
}
// 排序 选择数量 百分比处的值
template <typename Dtype>
Dtype Net<Dtype>::findMax_percent(Blob<Dtype>* blob, float percent)
{
const Dtype* data = blob->cpu_data();
int cnt = blob->count();
Dtype* data_copy_sort = (Dtype*) malloc(cnt*sizeof(Dtype));
caffe_copy(cnt, data,data_copy_sort); // 复制原始数据
caffe_abs(cnt, data_copy_sort,data_copy_sort);// 绝对值
// 对权重进行排序,获取权重的有序序列 升序排列
std::sort(data_copy_sort,data_copy_sort + cnt);
// 计算分组间隔点
int partition=int(cnt*(1.0-percent))-1;// 量化最后面的30%(值大的部分)
Dtype max_val = data_copy_sort[partition];// 指定百分比处的值
free(data_copy_sort);
return max_val;
}
template <typename Dtype>
void Net<Dtype>::RangeInLayers(vector<string>* layer_name,
vector<Dtype>* max_in, vector<Dtype>* max_out, vector<Dtype>* max_param) {
// Initialize vector elements, if needed.
if(layer_name->size()==0) {
for (int layer_id = 0; layer_id < layers_.size(); ++layer_id) {
if (strcmp(layers_[layer_id]->type(), "Convolution") == 0 ||
strcmp(layers_[layer_id]->type(), "InnerProduct") == 0) {
layer_name->push_back(this->layer_names()[layer_id]);
max_in->push_back(0);// 首次统计
max_out->push_back(0);
max_param->push_back(0);
}
}
}
// Find maximal values.
int index = 0;
Dtype max_val;
for (int layer_id = 0; layer_id < layers_.size(); ++layer_id) {
if (strcmp(layers_[layer_id]->type(), "Convolution") == 0 ||
strcmp(layers_[layer_id]->type(), "InnerProduct") == 0) {
max_val = findMax(bottom_vecs_[layer_id][0]);
//max_val = findMax_percent(bottom_vecs_[layer_id][0], 0.00);// 输入激活值 1%处的以外的值 直接 clip
max_in->at(index) = std::max(max_in->at(index), max_val);
max_val = findMax(top_vecs_[layer_id][0]);
//max_val = findMax_percent(top_vecs_[layer_id][0], 0.00);// 输入激活值 1%处的以外的值 直接 clip
max_out->at(index) = std::max(max_out->at(index), max_val);
// Consider the weights only, ignore the bias
max_val = findMax(&(*layers_[layer_id]->blobs()[0]));
//max_val = findMax_percent(&(*layers_[layer_id]->blobs()[0]), 0);// 参数权重 w 可以选择最大值
max_param->at(index) = std::max(max_param->at(index), max_val);
index++;
}
}
}// 计算最大值整数位需要的量纲长度
for (int i = 0; i < layer_names_.size(); ++i) {
il_in_.push_back((int)ceil(log2(max_in_[i])));
il_out_.push_back((int)ceil(log2(max_out_[i])));
il_params_.push_back((int)ceil(log2(max_params_[i])+1));
}
// Debug
for (int k = 0; k < layer_names_.size(); ++k) {
LOG(INFO) << "Layer " << layer_names_[k] <<
", integer length input=" << il_in_[k] <<
", integer length output=" << il_out_[k] <<
", integer length parameters=" << il_params_[k];
}
// 总量纲长度 bw_conv 减去整数位量纲长度 得到 小数位量纲长度
param_layer->set_type("ConvolutionRistretto");
param_layer->mutable_quantization_param()->set_fl_params(bw_conv -
GetIntegerLengthParams(param->layer(i).name()));
param_layer->mutable_quantization_param()->set_bw_params(bw_conv);
param_layer->mutable_quantization_param()->set_fl_layer_in(bw_in -
GetIntegerLengthIn(param->layer(i).name()));
param_layer->mutable_quantization_param()->set_bw_layer_in(bw_in);
param_layer->mutable_quantization_param()->set_fl_layer_out(bw_out -
GetIntegerLengthOut(param->layer(i).name()));
param_layer->mutable_quantization_param()->set_bw_layer_out(bw_out);template <typename Dtype>
vector<Dtype> Net<Dtype>::FindMax(Blob<Dtype>* blob, bool is_single) {
const Dtype* data = blob->cpu_data(); // 当前层 数据起始指针
int cnt = blob->count(); // 当前层 数据数量
vector<Dtype> max_vals; // 当前层每个卷积核(通道的最大值)
Dtype max_val = (Dtype)(-10); // 初始化 最大值
int index = 0;
// 4维 卷积核==================================================================
if(blob->shape().size() == 4) // output_channel * input_channel * kernel_height * kernel_width
{
// 值记录当前层 中所有卷积核 参数中的最大值==============
if(is_single)
{
max_vals = vector<Dtype>(1, Dtype(-10));
for (int i = 0; i < cnt; ++i) // 遍历
{
max_val = std::max(max_val, (Dtype)fabs(data[i]));// 最大值
}
max_vals.at(0) = max_val;// 层最大值放在第一个位置
}
// 记录当前层中每一个 卷积核中的最大值==================
else
{ // 卷积核维度 :output_channel * input_channel * kernel_height * kernel_width
int height = blob->shape(2); // 卷积核高度==
int width = blob->shape(3); // 卷积核宽度==
int channel = blob->shape(0); // 卷积核数量 输出通道数==
int deep = blob->shape(1); // 卷积核深度(厚度) 相当于立方体体积==
max_vals = vector<Dtype>(channel, Dtype(-10));// 初始化每个卷积核的最大值
int step = deep * height * width;// 每个卷积核的参数数量 = 深度*宽*高
for (int i = 0; i < cnt; ++i)
{// 总的排布顺序 是 按 每个卷积核进行循序 存放=====
if((i + 1) % step == 0) // 出现下一个卷积核的领域=====
{
max_vals.at(index) = std::max(max_val, (Dtype)fabs(data[i]));// 当前卷积核的最大值
++index;// 迭代下一个卷积核
}
else
{
max_val = std::max(max_val, (Dtype)fabs(data[i]));// 记录当前区域中的最大值
}
}
}
}
// blob 不是4维============= 输入输出================================
// 处理 CHW 格式的数据
else
{
if(is_single) // 真个输入输出参数中的最大值============
{
max_vals = vector<Dtype>(1, Dtype(-10));
for (int i = 0; i < cnt; ++i)
{
max_val = std::max(max_val, (Dtype)fabs(data[i]));//最大值====
}
max_vals.at(0) = max_val;// 宏观最大值,放在第一个地方
}
else // 求取每一个 输出通道中输入值的最大值=============
{ // output_channel * input_channel
int channel = blob->shape(0); // 总输出通道数量 === 本层卷积核的数量===本层输出通道数量==
max_vals = vector<Dtype>(channel, Dtype(-10));// 初始化每个通道的输入最大值
int step = blob->shape(1);// 每个通道的长度
for (int i = 0; i < cnt; ++i)
{
if((i + 1) % step == 0) // 出现下一个通道
{
max_vals.at(index) = std::max(max_val, (Dtype)fabs(data[i]));
++index; // 迭代 下一个通道
}
else
{
max_val = std::max(max_val, (Dtype)fabs(data[i]));// 本通道中领域元素中 的最大值
}
}
}
}
return max_vals;
}
template <typename Dtype>
void Net<Dtype>::RangeInLayers(vector<string>* layer_name,
vector<Dtype>* max_in, vector<Dtype>* max_out, vector<vector<Dtype>>* max_param, string scaling) {
// Initialize vector elements, if needed.
if(layer_name->size()==0) // 第一次循环需要初始化=======
{
for (int layer_id = 0; layer_id < layers_.size(); ++layer_id) // 遍历所有层======
{
if (strcmp(layers_[layer_id]->type(), "Convolution") == 0) // 是卷积层的,才进行统计====
{
layer_name->push_back(this->layer_names()[layer_id]);// 卷积层名字===
max_in->push_back(0); // 层输入最大值===
max_out->push_back(0); // 层输出最大值===
if (scaling == "single")
{
max_param->push_back(vector<Dtype>(1, 0));// 本层卷积核 的最大值====
}
else {
// 卷积核维度 :output_channel * input_channel * kernel_height * kernel_width
int param_shape = (&(*layers_[layer_id]->blobs()[0]))->shape(0);// 每一层的 卷积核数量:输出通道数
max_param->push_back(vector<Dtype>(param_shape, 0));// 每一层的每一个卷积核都需要统计最大值
}
}
}
}
// Find maximal values.
int index = 0;
vector<Dtype> max_vals;// 最大值
for (int layer_id = 0; layer_id < layers_.size(); ++layer_id) // 遍历所有层======
{
if (strcmp(layers_[layer_id]->type(), "Convolution") == 0) // 是卷积层的,才进行统计====
{
max_vals = FindMax(bottom_vecs_[layer_id][0]);
max_in->at(index) = std::max(max_in->at(index), max_vals.at(0)); // 输入最大值===
max_vals = FindMax(top_vecs_[layer_id][0]);
max_out->at(index) = std::max(max_out->at(index), max_vals.at(0));// 输出最大值====
// Consider the weights only, ignore the bias
if (scaling == "single") // 每一层 卷积weight的最大值===
{
max_vals = FindMax(&(*layers_[layer_id]->blobs()[0]));
max_param->at(index).at(0) = std::max(max_param->at(index).at(0), max_vals.at(0));
}
else
{
max_vals = FindMax(&(*layers_[layer_id]->blobs()[0]), false);// 当前训练中,每层 每个卷积核的最大值
for(int i = 0; i < max_vals.size(); ++i)
// 获取所有训练中每一卷积层index 的 每个 卷积核i 的最大值=======
max_param->at(index).at(i) = std::max(max_param->at(index).at(i), max_vals.at(i));
}
index++;// 卷积 层 id
}
}
}