Proof of Concept for Knitr/Bookdown pythonic alternative #12
Conversation
|
Finally, finally, I'f note that you may be able to implement all of this, directly as a Sphinx Parser (also writing any requisite directives and roles), a bit like jupinx. Obviously, this would mean that you are directly tethering yourself to a dependency on Sphinx, and I'm not sure how developer friendly this is. From experience docutils is nowhere near as clean an API as pandoc/panflute. Also, I always find it weird that, given it underpins a system as well-used as Sphinx, that it is only up to version |
|
@chrisjsewell , thanks, it looks very promising! Regarding the nested metadata like RISE metadata, they are supported in Jupytext - see for instance this Sure we could consider using YAML for representing the cell metadata in Jupytext Markdown (I guess your point is that YAML is simpler to write than JSON?), and I have even seen some users using YAML metadata in Jupytext to control how the notebook should be rendered by Sphinx, see here. Maybe I'd have a preference for hiding that YAML paragraph on GitHub - what would you think of enclosing it in HTML comments, rather than in pandoc divs? |
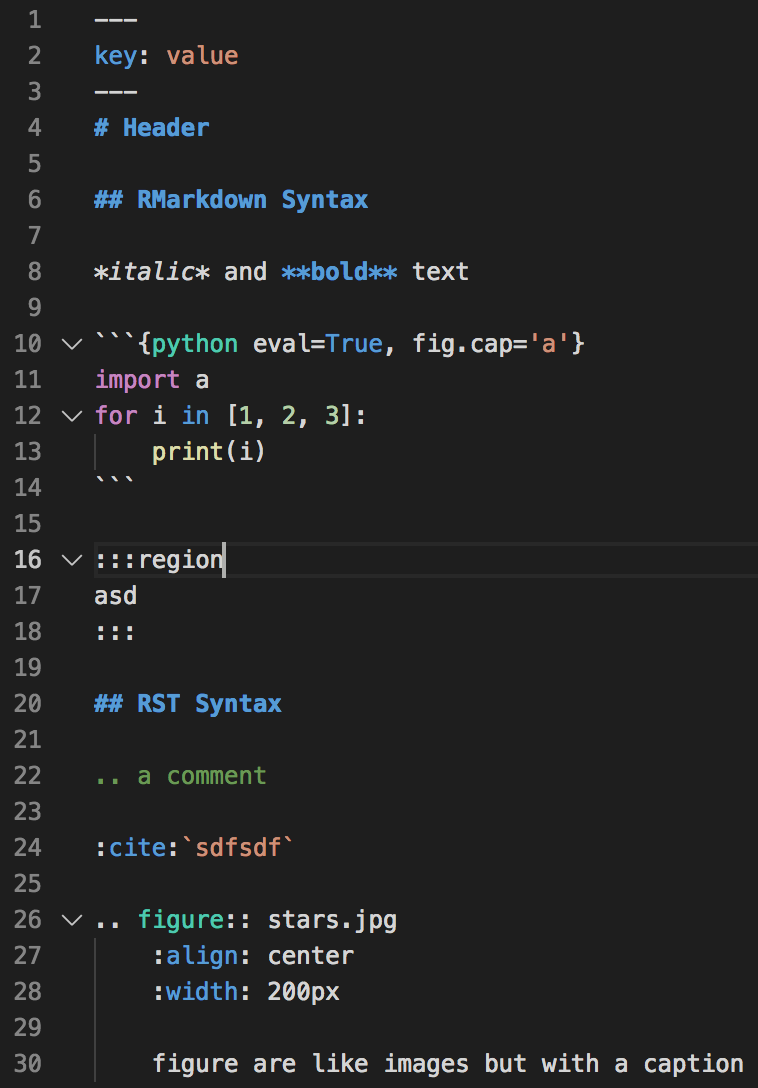
Well it looks like we are moving away from YAML for the RMarkdown/IMarkdown format, because it is too verbose for general users :(. By the same logic, I would say that, this: Is more verbose (and not in keeping with the pandoc/knitr syntax) than this: (note how I have also flattened the dictionary with dot delimitation) |
|
Its interesting though that |
Chunks are now reformatted, to play nicely with pandoc. Then chunk processing occurs after pandoc conversion. This allows concurrent processing of other pandoc elements.
The chunks now also may return metadata. This is utilised by ``PandocChunk`` to poll the kernel for current variables and return them as part of the metadata.
Both of these improvements are then utilised to walk through the document and concurrently process chunks and replace ``pf.Str`` placeholders, of the form ``{{<chunk name>:<variable name>}}``, with current variables from the kernel.
|
One last thing, to show the power of this approach (I promise!).
@choldgraf this is now implemented 😃 The method is detailed in dbfd827, but basically if you look in the input file at |
That was the reason for choosing that delimiter. But I agree that they are uneasy to type. In Jupytext 1.3 we now allow
Very nice! I'll think about implementing that in Jupytext, see mwouts/jupytext#389. But I think you'll also want the One last detail: note that if you use |
Well these already don't actually understand RMarkdown, they just treat it as regular markdown, e.g. they will only syntax highlight the shorthand code block specifiers like: import abc
a = 123But won't work for chunks like: For VS Code, this is an easy fix. If you install the IMarkdown extension I just created, it extends their own Markdown TextMate grammar, to include highlighting chunks properly, and making
For GitHub, maybe if you ask nicely they would implement this. For PyCharm, who cares, since I moved to VS Code, its dead to me 😂 (but since its just a standard TexMate grammar, there should actually be a way of making it work with PyCharm, or any other editor) |
|
All sounds spectacular to me. I put some thought into whether using a jmd style format with bookdown style extensions could have a bijective transformation to ipynb (and enable a roundtrip). It occured to me that with a few principles it might be possible. Maybe this was immediately obvious to everyone else, but if not, here is an idea and example:
Could become {
"cell_type": "code",
"execution_count": null,
"metadata": {
"jmd_chunk_options": {
"results": "hide"
}
},
"outputs": [],
"source": [
"3 + 4"
]Note that if writing an ipynb, no chunk-options are needed. So a basic ipynb would work fine. And you could have advanced features such as theorem type environments work as well (including persisting other cell metadata) becomes {
"cell_type": "code",
"execution_count": null,
"metadata": {
"jmd_chunk_options": {
"id": "pyth",
"name": "Pythagorean Theorem",
"type": "theorem"
},
"some_other_metadata" : "stuff"
},
"outputs": [],
"source": [
"For a right triangle, if $c$ denotes the length of the hypotenuse\n",
"and $a$ and $b$ denote the lengths of the other two sides, we have\n",
"\n",
"\\begin{equation}\n",
"a^2 + b^2 = c^2$$ (\\#eq:eq1)\n",
"\\end{equation}"
]
}I threw an example in https://gist.github.com/jlperla/d4972c5dc1cef2e2936d8a33e7a9ab34 to think about. |
|
I wanted to point out #11 (comment) which gives a great overview of the Rmd caching. It sounds like it can either automatically (or manually) create a DAG of cells to run when things are modified, which can mean a huge speedup. Even if the features aren't that fancy, it sure would be nice to have the option of specifying caching. Given that many datascience lectures take a long time to run, this is a big advantage. My guess is that with linting support it might be possible to add that sort of thing on the tools side (as long as the Rmd format allows it). |
Ok, last bit of code from me!
If we are to go down the route discussed in #9, of using RMarkdown (or something very similar) but with a 'pythonic' alternative to Knitr/Bookdown, this is a rough hack of how I would envisage implementing it. It addresses a decent amount of the features outlined in #11 by @jlperla, as I will explain below.
test.imd is an example RMarkdown file, and is output to markdown, tex, rst and html
The chunk system
This is a bit like the
directivesystem in Sphinx.In the setup.py, you will see that I provide an
imd.chunksentry-points group. Each of these entry points relates to sub-class of BaseChunk, which must implement three methods (and one optional):declare_formats; specifying which output formats the chunk is compatible withdeclare_options: specifying a JSON schema for the options it can be parsed.process_chunk: That is called (sequentially) for each chunk of that type in the document, is parsed the text contained in the chunk, and its dict of options (validated againstdeclare_options), and returns a pandoc document element.clean_up: Which is called after all chunks have been processed, or an error has been raised. For example, in PythonChunk this allows any running execution kernels to be closed.In process_doc, you can see how these are utilized by; (1) iterating through each chunk, (2) extracting the chunk type and options, (3) loading the entry-point related to that chunk type (if not already loaded) and parsing it the relevant data, (4) calling the
clean_upmethod for each loaded chunk handler.Note that:
BaseChunkand adding entry points to theirsetup.py. If you wanted to allow for overriding an existing chunk type, you could do something like add aliases to the document metadata:The system is self-documenting. For example, in document_chunks, I iterate through all
imd.chunksentry points and extract documentation of all available chunk types to: test_document_chunks.txt. You could use this in generating Sphinx user documentation, and also use it to provide dynamic auto-completion/validation of chunks and chunk options in a language-server.There is no inherent requirement for a single execution kernel. If you really wanted to go crazy, you could have multiple python, julia, etc kernels running to process their relevant chunk types.
@mmcky you may also note that the chunks are instantiated with the document level metadata, allowing for defaults to be set. In NoteChunk, for example, I use a default color set in the document metadata
@jlperla In the PythonChunk, I have implemented
eval,includeandecho. I would say then, so far I have roughly addressed these points from #11:With careful consideration to not introducing too much complexity, I would also envisage chunks returning (after processing of all chunks) information on what document level resources they require. For example, CSS for HTML, or the packages/commands required for the LaTeX preamble.
For 'Chunk caching' I think this could be done (at least for python output) via pairing with a Jupyter Notebook. @mwouts, perhaps in an updated/alternative RMarkdown/IMarkdown round trip conversion, the cell index could be directly specified, e.g.
Making it easy to quickly access stored outputs, without specifically keeping track of what cell you up to, e.g.
cached_output = notebook.cells[cache_index].outputs.A further abstraction would be a
Cacheclass interface which you instantiate at the start of parsing, and 'knows' how to deal with obtaining thecache_index. Then, for example, you could have sub-classes likeNotebookCache,FileSystemCache, or evenSshCache.On the topic of jupytext integration, I'm still not sure how you best handle markdown cell metadata? A good example of this is the slides metadata. Do you want to be able to create slide-shows using RMarkdown and, if so, what is the best way to do this? For example how would you handle the markdown metadata:
{ "slideshow": { "slide_type": "subslide" } }Do you stick with my original notion of
metadatablocks (which I don't think would really work with the encapsulated nature of chunks):Or, if you converted to something like:
(a) You now need your system to handle nested chunks, and (b) @mwouts I don't think the jupytext system can inherently deal with the forward-lookup you'd require to create the chunk closures?
You could maybe add an additional RMarkdown feature of layout blocks. Something like:
:::{slideshow, slide_type="subslide"} ```{python} print("hello") ``` :::But obviously this is adding in extra complexity.
The Reference System
I have implemented parsing of the Bookdown
\@ref(label)but, as with chunks (and similar to Sphinx roles), I have made this extensible (via entry points) to different types of references. In LaTeX for example I like to use\crefand\Cref.I also love using the Glossaries package (
\gls, '\Gls`, etc), and I have already implemented this as a sphinx extension in ipypublish.sphinx.gls.This system would also ideally return the document level resources it required, and I could additionally envisage it being extended to allow for options, in the form:
\@myref(id1,id2;plural=True,alt-text="something")