- Introductie
- (Algemene beschrijving)
- Doel
- Doelgroep
- Gebruik
- Definities en afkortingen
- Standaard
- Architectuur
- Uitgangspunten
- Systeemkenmerken en -vereisten
- Functionele vereisten
- Systeemkenmerken
- Niet-functionele vereisten
De VNG heeft een standaard ontwikkelt voor de vastlegging van verwerkingen. Door VNG-Realisatie is de Verwerkingenlogging API-standaard als onderdeel van de uitwerking van de informatiekundige visie Common Ground [LINK?] ontwikkeld en opgenomen in de GEMMA [LINK?] referentiearchitectuur. Deze API-standaard biedt leveranciers van informatiesystemen gestandaardiseerde API-specificaties voor het vastleggen en ontsluiten van metagegevens behorend bij vastgelegde (gelogde) verwerkingen.
Organisaties die persoonsgegevens verwerken zijn conform de Algemene Verordening Gegevensbescherming (AVG) en de Uitvoeringswet AVG verplicht om aan te kunnen tonen dat een verwerking van persoonsgegevens aan de belangrijkste beginselen van verwerking voldoet, zoals rechtmatigheid, transparantie, doelbinding en juistheid. Om aan deze verantwoordingsplicht te kunnen voldoen is het van belang dat per verwerking de belangrijkste metagegevens van de verwerkingen worden vastgelegd.
Aan de hand van de standaard wordt een API ontwikkeld door de Gemeente Nijmegen. Het product (API) wordt in het [restant] van dit document ['verwerkingenlogging API'] genoemd.
Gemeenten gebruiken binnen de uitvoering van de gemeentelijke taken grote hoeveelheden gegevens. Een deel van deze gegevens betreft persoonsgegevens. Vanuit de privacywetgeving zijn gemeenten verplicht dit gebruik van persoonsgegevens vast te leggen, en inzichtelijk te maken voor burgers. Door deze transparantie over het gebruik van persoonsgegevens heeft de burger de mogelijkheid om na te gaan of de gemeente zijn of haar gegevens rechtmatig gebruikt. Naast de gegevens van personen worden door gemeenten ook gegevens van andere ‘objecten’, zoals kadastrale percelen, verwerkt. Hoewel er geen wettelijke verplichting bestaat om van deze objecten verwerkingen vast te leggen kan het wel een toegevoegde waarde hebben.
Het doel van het product dat Gemeente Nijmegen gaat ontwikkelen is de implementatie van de standaard zoals beschreven door het VNG. Daarmee bied de gemeente de mogelijkhied aan [applicaties/organisatie] verwerkingen te loggen en burgers om verwerkte gegevens in te zien.
Het verwerkingenlogging product is beschikbaar voor alle applicaties die persoons(gegevens) verwerken [binnen de scope van de gemeente].
De applicaties hebben de mogelijkheid om verschillende API verzoeken te maken richting de verwerkingenlogging. Deze verzoeken zijn opgedeeld in het aanmaken, wijzigen of ophalen van [records] uit de achterliggende database. Zo wordt er [e.g.] per nieuwe verwerking een verzoek verstuurd naar de verwerkingenlogging API. In hoofdstuk ['...'] wordt dieper ingegaan op de verschillende verzoeken en technische implementatie.
-...
In onderstaande schets is weergegeven welke informatiesystemen een rol spelen bij de implementatie van de verschillende aspecten van de Verantwoordingsplicht. De onderdelen die door de Verwerkingenlogging API-standaard worden afgedekt zijn hierbij rood omkaderd aangegeven.
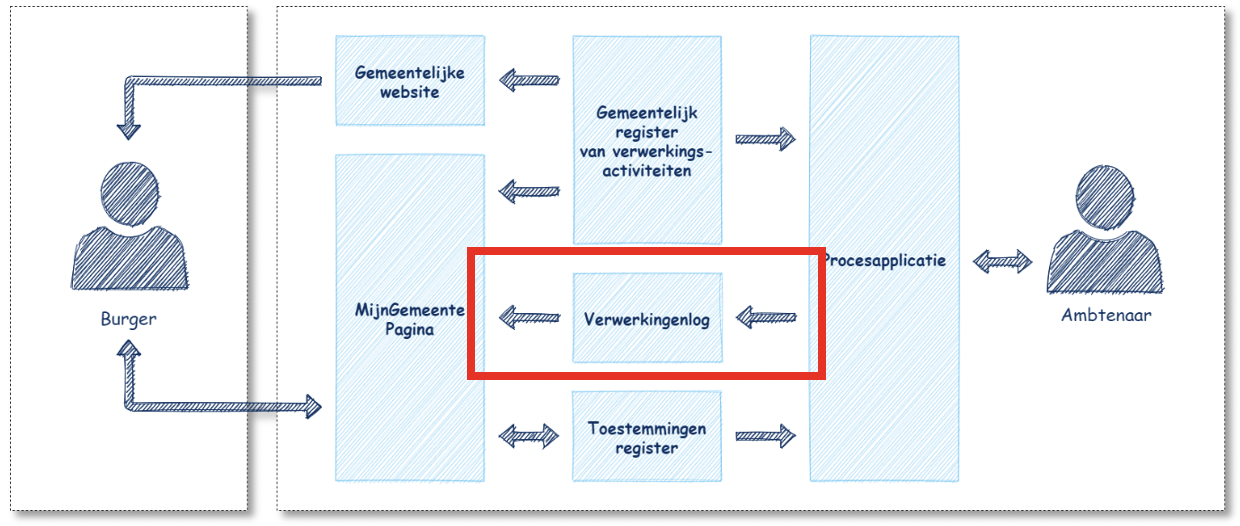
Als gemeenten hebben we de keuze om één (centraal) verwerkingenlog of meerdere (federatief) verwerkingslogs te hanteren. [in hoofdstuk ...] wordt dieper ingegaan op de technische implementatie.
Gemeenten moeten een eigen Register van verwerkingsactiviteiten (VAR) hebben. In het VAR staan verschillende verwerkingsactiviteiten zoals BRP Registratie of Geslachtswijziging. Dit kunnen dus sterk uiteenlopende activiteiten zijn, juist generiek of heel specifiek.
Het gegevensmodel is opgebouwed uit verschillende begrippen:
- Verwerkingsactiviteit
- Verwerking
- Handeling
- Actie
Het hoogste niveau is de verwerkingsactiviteit, het laagste niveau de actie. Logging vindt plaats op het niveau van de actie.
VNG heeft deze begrippen als volgt beschreven:
Een verwerkingsactiviteit is of een categorie van verwerkingen of een concreet soort verwerking.
Een verwerking is een concrete taak die een gemeente uitvoert. De taak vormt vanuit het perspectief van de burger of medewerker een logisch geheel.
Een handeling is één stap in de uitvoering van een verwerking. Deze stap kan bij een zogenaamde ‘happy flow’ zonder onderbrekingen uitgevoerd worden.
Een actie is een operatie die wordt uitgevoerd door een geautomatiseerd systeem waarbij er (persoons)gegevens verwerkt worden. Een actie wordt uitgevoerd als onderdeel van (een handeling van) een verwerking.
Op basis van de verschillende begrippen uit het gegevens model onstaat het volgende semantische informatiemodel en uitwisselingsgegevensmodel:

Hierbij worden de volgende waarden gebruikt:
- O = Optioneel
- V = Verplicht
- F = Functioneel verplicht (‘Should have’), maar technisch niet.
Binnen VNG Realisatie wordt ook gebruik gemaakt van Enterprise Architect (EA) voor de vastlegging van de semantische informatiemodellen. In hoofdstuk [...] wordt dit EA figuur benoemd en gerelateerd aan de techinsche implemenatie.
...
...
...
Situatie
Er is binnen de Nederlandse overheid op het moment van schrijven geen gestandaardiseerde oplossing om BSN’s te pseudonimiseren. Vanuit het eID-stelsel is een manier bedacht. Deze is geïmplementeerd in het BSN-koppelpunt. Er is open source software beschikbaar voor de ontsleuteling. Er is echter geen software of service beschikbaar voor de versleuteling.
Het pseudonimiseren is dus alleen mogelijk op basis van niet binnen de overheid gestandaardiseerde implementaties.
De AVG spreekt expliciet over pseudonimisering. Zonder pseudonimisering zijn verwerkingenlogs een potentiële privacy hotspot. Via het BSN is dan te achterhalen welke verwerkingen zijn uitgevoerd op de gegevens van een persoon. Verwerkingen over gezondheidsorganisaties, justitie of fraudeonderzoeken kunnen afhankelijk van de situatie afzonderlijk of gezamenlijk beschouwd worden als gevoelige informatie. Besluit
- Het ontbreken van een standaard oplossing voor pseudonimisering ontslaan de gemeenten en haar leveranciers niet van de verplichting BSN’s bij opname in het verwerkingenlog te pseudonimiseren.
- Deze pseudonimisering moet volledig achter de API van het koppelvlak plaatsvinden. Er wordt aan de API dus een gewoon BSN meegegeven. De implementatie van de API versleutelt vervolgens het BSN en kan dit vervolgens opnemen in het verwerkingenlog of vergelijken met gegevens in het verwerkingenlog
- Omdat er geen gestandaardiseerde implementatie is voor de versleuteling moet het mogelijk zijn om een pseudoniem te kunnen herleiden naar een BSN. Deze functionaliteit is o.a. noodzakelijk om de inhoud van verwerkingenlogs te kunnen migreren. Bijvoorbeeld bij een gemeentelijke herindeling of bij een wisseling van leverancier.
Besluit
Bij een verwerking kunnen meerdere personen of objecten opgenomen worden.
Toelichting
Vanuit technisch perspectief kan het wenselijk zijn deze structuur ‘platgeslagen’ (gedenormaliseerd) op te slaan. In het logisch gegevensmodel en de API is er echter sprake van een 1:n relatie tussen de verwerking en de bijbehorende objecten/personen.
Besluit
Het verwerkingenlog is fysiek onwijzigbaar (immutable)
Er mogen geen record gewist of gemuteerd worden .
Er mogen wel records toegevoegd worden.
Het verwerkingenlog is logisch muteerbaar
Wijzigingen moeten traceerbaar zijn
Van verwerkingenlogentries moet formele historie bijgehouden worden
Op basis van een verwerkingenlog waarin alleen nieuwe records toegevoegd mogen worden zou dit op onderstaande wijze geïmplementeerd kunnen worden:
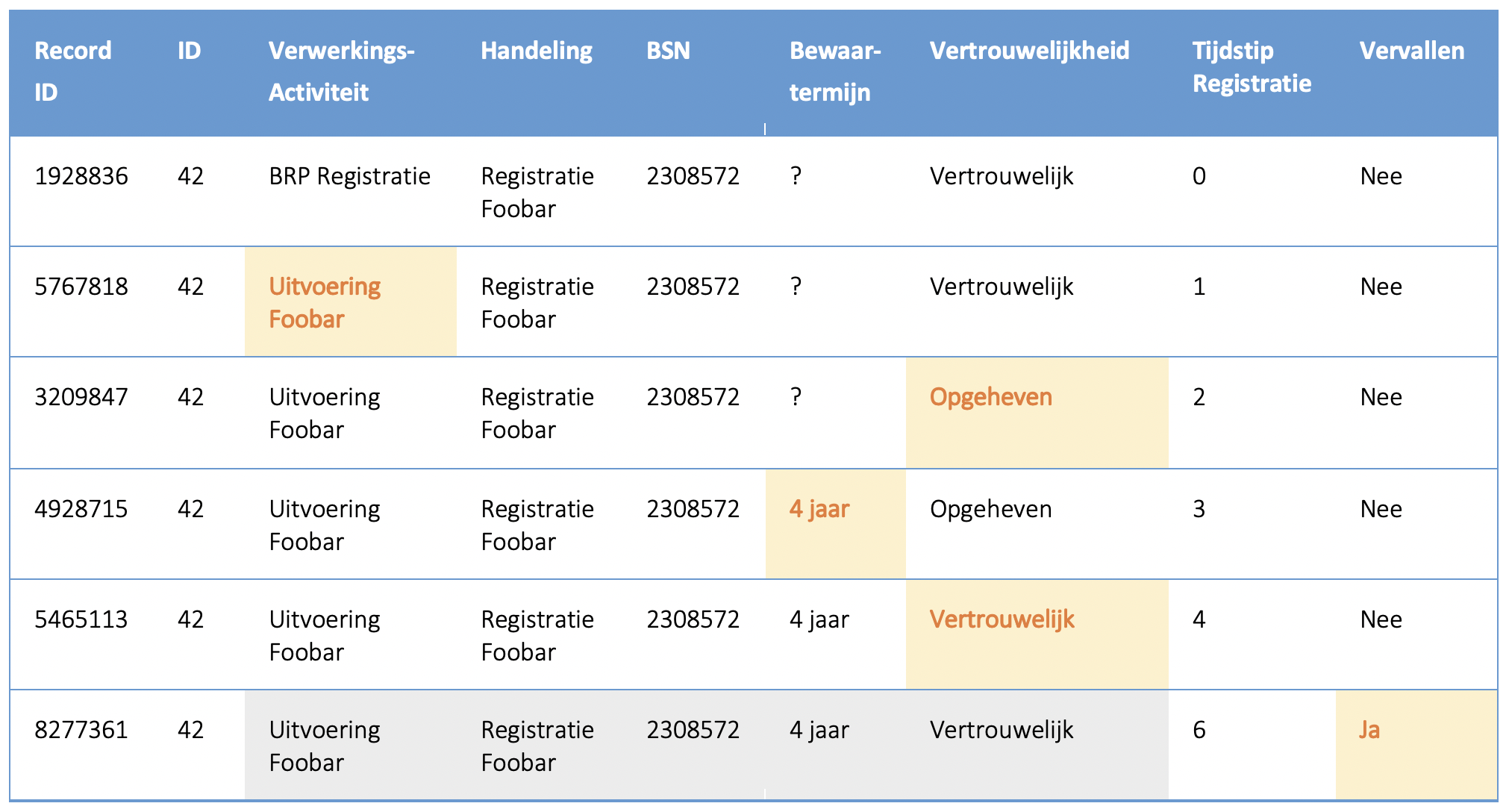
De term 'vervallen' komt echter niet voor in de technische uitwerking van de API. Zie: https://petstore.swagger.io/?url=https://raw.githubusercontent.com/VNG-Realisatie/gemma-verwerkingenlogging/master/docs/api-write/oas-specification/logging-verwerkingen-api/openapi.yaml
Toelichting is hier te vinden: https://vng-realisatie.github.io/gemma-verwerkingenlogging/achtergronddocumentatie/ontwerp/artefacten/3891.html
De autorisatie-scopes zijn hier beschreven. Als de API call niet voldoet aan de scope dan zal een HTTP 403 (Forbidden) foutmelding worden teruggegeven.
De standaar defninieert twee API's. De 'Bewerking API' en de 'Inzage API'.
De functionele vereisten kunnene we het beste beschrijven aan de hand van de functionele view van de Bewerking API. Het volgende tabel toont per categorie de verschillende functies van de API.
[TABEL]
Technisch resulteert dit in de volgende API-calls:
- POST/verwerkingsacties
- GET/verwerkingsacties
- PUT/verwerkingsacties/{actieId}
- DELETE/verwerkingsacties/{actieId}
- PATCH/verwerkingsacties
Details per API-call zijn hier te vinden: https://petstore.swagger.io/?url=https://raw.githubusercontent.com/VNG-Realisatie/gemma-verwerkingenlogging/master/docs/api-write/oas-specification/logging-verwerkingen-api/openapi.yaml#/
-
Bij alle acties die persoonsgegevens verwerken wordt er gelogd (B7952). Hierbij gelden de volgende regels:
- Alle verwerkingen hebben een eigen ID (B8157).
- Als de verwerking overeenkomt met een proces uit de bedrijfsvoering (zoals een verzoek of zaak) en dit proces heeft een eigen UUID dan kan dit UUID gebruikt worden.
- In alle andere gevallen moet een nieuw UUID toegewezen worden.
- Het ID van de verwerking wordt gelogd en kan later gebruikt worden om acties die over deze verwerking gelogd zijn aan elkaar te relateren, eventuele vertrouwelijkheid te laten vervallen, een bewaartermijn op te geven of de acties in bijzondere situaties aan te passen of logisch te verwijderen.
- Verwerkingsacties worden zodanig omschreven dat deze duidelijk zijn voor de burger. Hiertoe worden waar mogelijk en zinvol alle attributen van de actie ingezet (A5924).
- Alle verwerkingen hebben een eigen ID (B8157).
-
Roept de applicatie/service een API aan waarbij die API persoonsgegevens verwerkt? Dan moet bij deze aanroep in de header de volgende informatie meegegeven worden (B7259, B9177):
OIN, Verwerkingsactiviteit ID, Verwerkingsactiviteit URL, Verwerking ID, Vertrouwelijkheid en Bewaartermijn. Zie ‘Toevoeging aan de header van alle persoonsgegevens-verwerkende API’s’ hieronder voor meer informatie. -
Wordt een service geboden waarbij persoonsgegevens verwerkt worden? Dan moet bij de uitvoering daarvan gekeken worden of in de header van de aanroep de volgende gegevens aanwezig zijn:
OIN, Verwerkingsactiviteit ID, Verwerkingsactiviteit URL, Verwerking ID, Vertrouwelijkheid en Bewaartermijn. Deze gegevens dienen overgenomen te worden bij het loggen van de verwerking. Zie ‘Toevoeging aan de header van alle persoonsgegevens-verwerkende API’s’ hieronder voor meer informatie.
- DynamoDB
- Database oplossing
- S3
- Storage oplossing (Simple Storage Service)
- SQS
- Queueing systeem
- API Gateway
- API gateway implementatie
- Lambda's
- Microservices waar custom logic (code) draait
- Bestaat uit 3 verschillende lambda's:
- GEN - verwerkt het binnenkomend bericht, en genereerd de nodige ID's. Stuurt bericht door naar de Queue
- PROC - Haalt bericht(en) op van de queue en plaatst het in de DB.
- REC - Haalt berichten direct uit de DB.
Verzoeken komen vanuit de appliatie binnen op via de API Gateway. Achter de gateway hangt een integratie per route. Voor de POST, PUT en PATCH verzoeken wordt de GEN lambda getriggered. Voor de GET en DELETE verzoeken wordt de REC lambda getriggered. De verzoeken die op de GEN lambda komen worden doorgestuurd naar zowel een S3 Backup Bucket als de SQS queue. In de backup bucket wordt het bericht opgeslagen als backup. De PROC lamdba haalt vervolgens de berichten uit de queue en plaats het bericht als een nieuwe record in de DynamoDB database. De verzoeken die op de REC lamdba komen worden gebruikt om records uit de database te halen. De DELETE route is momenteel niet geimplementeerd zoals de standaard voorschrijft.
[Afbeelding AWS architectuur huidige versie]
- Performance: zoals binnen 1ms response.
- Staat dit ergens beschreven?
- Misschien (nog) niet relevant, zeker niet in eerste versie.
REST STAAT IN WORD DOC