基于 python 脚本语言开发的数字图片处理包,比如 PIL、Pillow、opencv、scikit-image 等。
-
PIL 和 Pillow 只提供最基础的数字图像处理,功能有限;
-
opencv 实际上是一个 c++ 库,只是提供了 python 接口,更新速度非常慢。
-
scikit-image 是基于 scipy 的一款图像处理包,它将图片作为 numpy 数组进行处理,正好与 matlab 一样,因此,我们最终选择 scikit-image 进行数字图像处理。
写在前面的:
注:opencv 读取以及 numpy 创建图像多维数组都是先高度 height、再宽度 width,但在电脑上显示的是
width x height的格式。
总结下主流 Python 图像库的一些基本使用方法和需要注意的地方:
- opencv
- PIL(pillow)
- matplotlib.image
- scipy.misc
- skimage
图片读取操作:
import cv2
import numpy as np
#读入图片:默认彩色图,cv2.IMREAD_GRAYSCALE灰度图,cv2.IMREAD_UNCHANGED包含alpha通道
img = cv2.imread('1.jpg')
cv2.imshow('src',img)
print(img.shape) # (h,w,c)
print(img.size) # 像素总数目
print(img.dtype)
print(img)
cv2.waitKey()
值得注意的是,opencv 读进来的图片已经是一个 numpy 矩阵了,彩色图片维度是(高度,宽度,通道数)。数据类型是 uint8。
#gray = cv2.imread('1.jpg',cv2.IMREAD_GRAYSCALE) #灰度图
#cv2.imshow('gray',gray)
#也可以这么写,先读入彩色图,再转灰度图
src = cv2.imread('1.jpg')
gray = cv2.cvtColor(src,cv2.COLOR_BGR2GRAY)
cv2.imshow('gray',gray)
print(gray.shape)
print(gray.size)
print(gray)
cv2.waitKey()上面提到了两种获取灰度图的方式,读进来的灰度图的矩阵格式是(高度,宽度)。
#注意,计算图片路径是错的,Opencv也不会提醒你,但print img时得到的结果是None
img2 = cv2.imread('2.jpg')
print(img2)结果:None
#如何解决“读到的图片不存在的问题”? #加入判断语句,如果为空,做异常处理
img2 = cv2.imread('2.jpg')
if img2 == None:
print('fail to load image!')
结果:fail to load image!
opencv读入图片的矩阵格式是:(height,width,channels)。而在深度学习中,因为要对不同通道应用卷积,所以会采取另一种方式:(channels,height,width)。为了应对该要求,我们可以这么做
#注意到,opencv读入的图片的彩色图是一个channel last的三维矩阵(h,w,c),即(高度,宽度,通道)
#有时候在深度学习中用到的的图片矩阵形式可能是channel first,那我们可以这样转一下
print(img.shape)
img = img.transpose(2,0,1)
print(img.shape)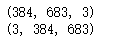
在深度学习搭建CNN时,往往要做相应的图像数据处理,比如图像要扩展维度,比如扩展成(batch_size,channels,height,width)。对于这种要求,我们可以这么做。
#有时候还要扩展维度,比如有时候我们需要预测单张图片,要在要加一列做图片的个数,可以这么做
img = np.expand_dims(img, axis=0)
print(img.shape)

上面提到的是预测阶段时预测单张图片的扩展维度的操作,如果是训练阶段,构建batch,即得到这种形式:(batch_size,channels,height,width)。我一般喜欢这么做
data_list = []
loop:
im = cv2.imread('xxx.png')
data_list.append(im)
data_arr = np.array(data_list)这样子就能构造成我们想要的形式了。
#因为opencv读入的图片矩阵数值是0到255,有时我们需要对其进行归一化为0~1
img3 = cv2.imread('1.jpg')
img3 = img3.astype("float") / 255.0 #注意需要先转化数据类型为float
print(img3.dtype)
print(img3)
#存储图片
cv2.imwrite('test1.jpg',img3) #得到的是全黑的图片,因为我们把它归一化了
#所以要得到可视化的图,需要先*255还原
img3 = img3 * 255
cv2.imwrite('test2.jpg',img3) #这样就可以看到彩色原图了opencv对于读进来的图片的通道排列是BGR,而不是主流的RGB!谨记!
#opencv读入的矩阵是BGR,如果想转为RGB,可以这么转
img4 = cv2.imread('1.jpg')
img4 = cv2.cvtColor(img4,cv2.COLOR_BGR2RGB)#访问像素
print(img4[10,10]) #3channels
print(gray[10,10]) #1channel
img4[10,10] = [255,255,255]
gray[10,10] = 255
print(img4[10,10]) #3channels
print(gray[10,10]) #1channel
#roi操作
roi = img4[200:550,100:450,:]
cv2.imshow('roi',roi)
cv2.waitKey()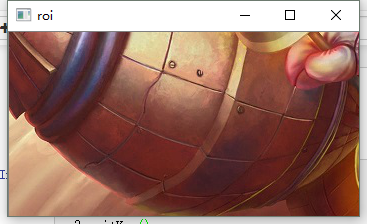
#分离通道
img5 = cv2.imread('1.jpg')
b,g,r = cv2.split(img5)
#合并通道
img5 = cv2.merge((b,g,r))
#也可以不拆分
img5[:,:,2] = 0 #将红色通道值全部设0补充:——from:https://www.jianshu.com/p/9fd339f806a7

在 cv2.split 分离出的图像基础上,扩展另外两个通道,但另外两个通道值为 0,而得到上面的这样的图像。代码如下:
# 生成一个值为0的单通道数组
zeros = np.zeros(image.shape[:2], dtype = "uint8")
# 分别扩展B、G、R成为三通道。另外两个通道用上面的值为0的数组填充
cv2.imshow("Blue", cv2.merge([B, zeros, zeros]))
cv2.imshow("Green", cv2.merge([zeros, G, zeros]))
cv2.imshow("Red", cv2.merge([zeros, zeros, R]))
cv2.waitKey(0)PIL 即 Python Imaging Library,也即为我们所称的 Pillow,是一个很流行的图像库,它比 opencv 更为轻巧,正因如此,它深受大众的喜爱。
(略。。。请阅读参考原文)
(略。。。请阅读参考原文)
(略。。。请阅读参考原文)
(略。。。请阅读参考原文)
- 除了 opencv 读入的彩色图片以 BGR 顺序存储外,其他所有图像库读入彩色图片都以 RGB 存储。
- 除了 PIL 读入的图片是img类之外,其他库读进来的图片都是以 numpy 矩阵。
- 各大图像库的性能,老大哥当属opencv,无论是速度还是图片操作的全面性,都属于碾压的存在,毕竟他是一个巨大的 cv 专用库。下面那张图就是我从知乎盗来的一张关于各个主流图像库的一些性能比较图,从测试结果看来,opencv 确实胜出太多了。

——更多内容请阅读原文:Python各类图像库的图片读写方式总结 【荐】
1 matplotlib.pylab:
import pylab as plt
import numpy as np
img = plt.imread('examples.png')
print(type(img), img.dtype, np.min(img), np.max(img))
[out]
(<type 'numpy.ndarray'>, dtype('float32'), 0.0, 1.0) # matplotlib读取进来的图片是float,0-12 PIL.image.open
from PIL import Image
import numpy as np
img = Image.open('examples.png')
print(type(img), np.min(img), np.max(img))
img = np.array(img) # 将PIL格式图片转为numpy格式
print(type(img), img.dtype, np.min(img), np.max(img))
[out]
(<class 'PIL.PngImagePlugin.PngImageFile'>, 0, 255) # 注意,PIL是有自己的数据结构的,但是可以转换成numpy数组
(<type 'numpy.ndarray'>, dtype('uint8'), 0, 255) # 和用matplotlib读取不同,PIL和matlab相同,读进来图片和其存储在硬盘的样子是一样的,uint8,0-2553 cv2.imread
import cv2
import numpy as np
img = cv2.imread('examples.png') # 默认是读入为彩色图,即使原图是灰度图也会复制成三个相同的通道变成彩色图
img_gray = cv2.imread('examples.png', 0) # 第二个参数为0的时候读入为灰度图,即使原图是彩色图也会转成灰度图
print(type(img), img.dtype, np.min(img), np.max(img))
print(img.shape)
print(img_gray.shape)
[out]
(<type 'numpy.ndarray'>, dtype('uint8'), 0, 255) # opencv读进来的是numpy数组,类型是uint8,0-255
(824, 987, 3) # 彩色图3通道
(824, 987) # 灰度图单通道注意,pylab.imread 和 PIL.Image.open读入的都是 RBG顺序,而 cv2.imread读入的是 BGR顺序,混合使用的时候要特备注意
import cv2
import pylab as plt
from PIL import Image
import numpy as np
img_plt = plt.imread('examples.png')
img_pil = Image.open('examples.png')
img_cv = cv2.imread('examples.png')
print(img_plt[125, 555, :])
print(np.array(img_pil)[125, 555, :] / 255.0)
print(img_cv[125, 555, :] / 255.0)
[out]
[ 0.61176473 0.3764706 0.29019609]
[ 0.61176471 0.37647059 0.29019608]
[ 0.29019608 0.37647059 0.61176471] # opencv的是BGR顺序1 matplotlib.pylab - plt.imshow,这个函数的实际上就是将一个 numpy 数组格式的 RGB 图像显示出来
import pylab as plt
import numpy as np
img = plt.imread('examples.png')
plt.imshow(img)
plt.show()import pylab as plt
from PIL import Image
import numpy as np
img = Image.open('examples.png')
img_gray = img.convert('L') #转换成灰度图像
img = np.array(img)
img_gray = np.array(img_gray)
plt.imshow(img) # or plt.imshow(img / 255.0),matplotlib和matlab一样,如果是float类型的图像,范围是0-1才能正常imshow,如果是uint8图像,范围则需要是0-255
plt.show()
plt.imshow(img_gray, cmap=plt.gray()) # 显示灰度图要设置cmap参数
plt.show()
plt.imshow(Image.open('examples.png')) # 实际上plt.imshow可以直接显示PIL格式图像
plt.show() import pylab as plt
import cv2
import numpy as np
img = cv2.imread('examples.png')
plt.imshow(img[..., -1::-1]) # 因为opencv读取进来的是bgr顺序呢的,而imshow需要的是rgb顺序,因此需要先反过来
plt.show()2 cv2 - 不用考虑了,pylab.imshow方便多了
1 PIL.Image
from PIL import Image
img = Image.open('examples.png')
img_gray = img.convert('L') # RGB转换成灰度图像
img_rgb = img_gray.convert('RGB') # 灰度转RGB
print(img)
print(img_gray)
print(img_rgb)
[out]
<PIL.PngImagePlugin.PngImageFile image mode=RGB size=987x824 at 0x7FC2CCAE04D0>
<PIL.Image.Image image mode=L size=987x824 at 0x7FC2CCAE0990>
<PIL.Image.Image image mode=RGB size=987x824 at 0x7FC2CCAE0250>2 cv2(注意,opencv 在读入图片的时候就可以通过参数实现颜色通道的转换,下面是用别的方式实现)
import cv2
import pylab as plt
img = cv2.imread('examples.png')
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # BGR转灰度
img_bgr = cv2.cvtColor(img_gray, cv2.COLOR_GRAY2BGR) # 灰度转BRG
img_rgb = cv2.cvtColor(img_gray, cv2.COLOR_GRAY2RGB) # 也可以灰度转RGB1 PIL.image - 保存PIL格式的图片
from PIL import Image
img = Image.open('examples.png')
img.save('examples2.png')
img_gray = img.convert('L')
img_gray.save('examples_gray.png') # 不管是灰度还是彩色,直接用save函数保存就可以,但注意,只有PIL格式的图片能够用save函数2 cv2.imwrite - 保存numpy格式的图片
import cv2
img = cv2.imread('examples.png') # 这是BGR图片
cv2.imwrite('examples2.png', img) # 这里也应该用BGR图片保存,这里要非常注意,因为用pylab或PIL读入的图片都是RGB的,如果要用opencv存图片就必须做一个转换
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imwrite('examples_gray.png', img_gray)(1)Windows 下的安装
opencv 依赖 numpy,先安装好 numpy。
方法一:直接命令法
试试 pip 或 conda 命令安装 pip install opencv-python
方法二:下载 whl 文件安装
到官网 https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv,下载相应 Python 版本的 OpenCV 的 whl 文件。比如下载的是 opencv_python‑3.4.1‑cp36‑cp36m‑win_amd64.whl,则打开该 whl 文件所在目录,CMD 进入到该目录,使用命令安装即可:
pip install opencv_python‑3.4.1‑cp36‑cp36m‑win_amd64.whl
测试是否安装成功:
import cv2运行是否报错。
注意:本人在安装 opencv-python 出现了问题,后来换了其他版本的 opencv 解决了,所以怀疑 Python 版本和 opencv-python 版本需要对应。
本人 Python 版本:3.6.4 opencv-python 版本:3.4.1.15
- GitHub:https://github.com/1zlab/1ZLAB_OpenCV_Tutorial - OpenCV基础入门。
(1)
imread 的函数原型是:Mat imread( const string& filename, int flags=1 );
Mat是OpenCV里的一个数据结构,在这里我们定义一个Mat类型的变量img,用于保存读入的图像,在本文开始有写到,我们用imread函数来读取图像,第一个字段标识图像的文件名(包括扩展名),第二个字段用于指定读入图像的颜色和深度,它的取值可以有以下几种:
-
CV_LOAD_IMAGE_UNCHANGED (<0),以原始图像读取(包括alpha通道),
-
CV_LOAD_IMAGE_GRAYSCALE ( 0),以灰度图像读取
-
CV_LOAD_IMAGE_COLOR (>0),以RGB格式读取
——from:https://blog.csdn.net/zhangpinghao/article/details/8144829
文档中是这么写的:
Flags specifying the color type of a loaded image:
CV_LOAD_IMAGE_ANYDEPTH - If set, return 16-bit/32-bit image when the input has the corresponding depth, otherwise convert it to 8-bit.
CV_LOAD_IMAGE_COLOR - If set, always convert image to the color one
CV_LOAD_IMAGE_GRAYSCALE - If set, always convert image to the grayscale one
>0 Return a 3-channel color image.
Note
In the current implementation the alpha channel, if any, is stripped from the output image. Use negative value if you need the alpha channel.
=0 Return a grayscale image.
<0 Return the loaded image as is (with alpha channel).大致翻译一下:
Flags指定了所读取图片的颜色类型
-
CV_LOAD_IMAGE_ANYDEPTH 返回图像的深度不变。
-
CV_LOAD_IMAGE_COLOR 总是返回一个彩色图。
-
CV_LOAD_IMAGE_GRAYSCALE 总是返回一个灰度图。
0 返回3通道彩色图,注意:alpha 通道将被忽略,如果需要alpha 通道,请使用负值
=0 返回灰度图
<0 返回原图(带 alpha 通道)
我觉得这里最大的问题就是一会说深度,一会说通道数,两个问题都没有说明白。
实测,当读取一副黑白图时,如果使用Flags=2(CV_LOAD_IMAGE_ANYDEPTH),此时Flags>0,得到的仍是黑白图而不是彩色图。其它的值,如 1,3,4 等均是彩色。
所以我觉得第一句话应该改为 CV_LOAD_IMAGE_ANYDEPTH 返回图像原有的深度,但是通道数变为 1,这是 Flags>0 中的特例
自己测了一下,然后总结如下:
- flag=-1 时,8位深度,原通道
- flag=0,8位深度,1通道
- flag=1, 8位深度 ,3通道
- flag=2,原深度,1通道
- flag=3, 原深度,3通道
- flag=4,8位深度 ,3通道
在源码中可以看到。默认是 1。
——from:opencv中imread第二个参数的含义
!!!注意: cv2.imread() 和cv2.imwrite() 函数,其中第一个参数 finename,一定是在已存在的目录,若指定的是不存在的目录,就不会写入和读取到图像文件了。
(2)
注1:本人使用 labelme 进行进行标注得到 json 文件,然后使用 labelme_json_to_dataset 转换的时候,得到的 label.png 为彩色,而非黑色图像,看评论有人说是版本问题…
注2:然后我安装了 labelme 旧版 2.9.0,pip install labelme==2.9.0,发现这个版本 labelme_json_to_dataset 命令生成的 label.png 文件确实是全黑色,并且是 16 位深度的。
然后我使用 cv2.imread(“label.png”) 读取发现得到的数值最小最大都是0;使用 cv2.imread(label.png”, 2) 读取发现得到的数值最小是0,最大是1,为什么呢?后来知道了。先看 opencv imread()方法第二个参数介绍 | opencv中imread第二个参数的含义,可以说,imread(const string& filename, int flag=1),filename 指图像名称,flag 指读取图像颜色类型。
- flag=-1时,8位深度,原通道
- flag=0,8位深度,1通道
- flag=1, 8位深度 ,3通道
- flag=2,原深度,1通道
- flag=3, 原深度,3通道
- flag=4,8位深度 ,3通道
我解释下:因为 label.png 是 16 位的,默认 flag=1,按上可以看到只读取到了图像的 8 位,得到 3 通道,得到的全是 0;若 flag=2,按原深度即读取了图像位深度 16 位,得到了数值 1。
我的理解:本质原因在于 imread 读取了图像的多少位。另外注意,如果本来是 1 个通道的图像,imread 第二个参数选择了返回 3 个通道的,那么第一个通道读取的数值,在相同像素的位置另外两个通道也会有同样数值。
按我自己理解我总结下,不做参考用,仅供自己看:
- 如果打开电脑上图像的属性,看到深度 8 位,你用「8位深度,1通道」读取,得到单通道图,你用「8位深度,3通道」,得到3通道图像数值(在另外两通道数值是相同的);
- 如果图像属性是 16 位的,你用「8位深度,1通道」读取,只能读取8位长度的数据,单通道,你用「原深度,1通道」你能读取16位长度,单通道,你用「原深度,3通道」你能读取16位长度数据,得到三通道(在另外两个通道数值是相同的)
- 如果图像属性是 32 位的,你用「8位深度,3通道」,得到是原图,你用「8位深度,1通道」读取,转灰度图,有个彩色图RGB数值转灰度图数值的计算公式:Grey = 0.299*R + 0.587*G + 0.114*B,按计算公式得到灰度图数值,你用「原深度,1通道」读取,得到和以「8位深度,1通道」读取一样的图像。
另外,建议可以使用 matlab 软件 imread(imagepath) 读取图像,点击打开工作区的 ans,可以看到图像数值以及是通道数量。
(暂时理解到这个进步。。。以后在探究。。。
API:cv2.addWeighted(src1, alpha, src2, beta, gamma[, dst[, dtype]]) → dst.
其中,alpha 为 src1 透明度,beta 为 src2 透明度。
# coding=utf-8
# 底板图案
bottom_pic = 'elegent.jpg'
# 上层图案
top_pic = 'lena.jpg'
import cv2
bottom = cv2.imread(bottom_pic)
top = cv2.imread(top_pic)
# 权重越大,透明度越低
overlapping = cv2.addWeighted(bottom, 0.8, top, 0.2, 0)
# 保存叠加后的图片
cv2.imwrite('overlap(8:2).jpg', overlapping)——from:https://blog.csdn.net/JNingWei/article/details/78241973
(1)设置 500x500x3 图像 的 100x100 区域为蓝色:
import cv2
import numpy as np
ann_img = np.ones((500,500,3)).astype('uint8')
print(ann_img.shape)
ann_img[:100, :100, 0] = 255 # this would set the label of pixel 3,4 as 1
cv2.imwrite( "ann_1.png" ,ann_img )
# print(ann_img)
cv2.imshow("Image", ann_img)
cv2.waitKey(0)
cv2.destroyAllWindows()ann_img[:100, :100, 0] 表示:第一维度的 099 索引位置、第二维度的 099 索引位置,第三维度的索引为 1 的位置,这些位置的值改为 255,可以看出,分别对应高、宽、通道,高和宽的 0~99 位置的 100 个像素,以及通道中的第一个通道的值都改了为 255,所以变为了蓝色。
(2)
import cv2
import numpy as np
img = cv2.imread("./haha.jpg", cv2.IMREAD_COLOR)
print(img.shape)
print(img)
emptyImage = np.zeros(img.shape, np.uint8)
print(emptyImage)
emptyImage2 = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imshow("EmptyImage", emptyImage)
cv2.imshow("Image", img)
cv2.imshow("EmptyImage2", emptyImage2)
cv2.waitKey(0)
cv2.destroyAllWindows()RGB 彩色图像中,一种彩色由R(红色),G(绿色),B(蓝色)三原色按比例混合而成。
图像的基本单元是一个像素,就像一个巨幅电子广告屏上远处看是衣服图像,走近你会看到一个一个的方格,这个方格的颜色是一种,从远处看,觉察不到这个方格的存在。
一个像素需要 3 块表示,分别代表 R,G,B,如果 8 为表示一个颜色,就由 0-255 区分不同亮度的某种原色。
实际中数都是二进制形式的,并且未必按照 R,G,B 顺序,比如OpenCV是按照 B,G,R 顺序将三个色值保存在 3 个连续的字节里。
灰度图像是用不同饱和度的黑色来表示每个图像点,比如用8位 0-255数字表示“灰色”程度,每个像素点只需要一个灰度值,8 位即可,这样一个 3X3 的灰度图,只需要9个byte就能保存
RGB 值和灰度的转换,实际上是人眼对于彩色的感觉到亮度感觉的转换,这是一个心理学问题,有一个公式:
Grey = 0.299*R + 0.587*G + 0.114*B
根据这个公式,依次读取每个像素点的 R,G,B 值,进行计算灰度值(转换为整型数),将灰度值赋值给新图像的相应位置,所有像素点遍历一遍后完成转换。
——from:RGB图像转为灰度图
先看这样的代码:
import cv2
import numpy as np
ann_img = np.ones((4,3,3)).astype('uint8')
print(ann_img.shape)
ann_img[:2, :2, 0] = 255
print(ann_img)结果:
(4, 3, 3)
[[[255 1 1]
[255 1 1]
[ 1 1 1]]
[[255 1 1]
[255 1 1]
[ 1 1 1]]
[[ 1 1 1]
[ 1 1 1]
[ 1 1 1]]
[[ 1 1 1]
[ 1 1 1]
[ 1 1 1]]]我们来这样理解下,图像高宽的像素个数分别为 4 和 3,3 个通道。我们可以把其想象成三个矩阵叠加(我暂且称它为「叠加矩阵」)。
我们再来看打印的数据值,那么这个表示叠加矩阵的第一行的像素值,
[[255 1 1]
[255 1 1]
[ 1 1 1]]下面这个表示叠加矩阵的第二行的像素值,
[[255 1 1]
[255 1 1]
[ 1 1 1]]依次内推。总共 4 行(正好对应高度 4)。然后再回来看叠加矩阵的第一个 [ ] 的像素值,其中的这个
[255 1 1]255 表示第一行第一列的第一通道的像素值,中间的 1 表示第一行第一列的第二通道的像素值,最后的 1 表示第一行第一列的第三通道的像素值。
接下来可以来看叠加矩阵的第二行像素值,第三行像素值。。。依次内推。理解起来是一样的。
这里提一下,我发现经过 cv.imread() 读取的图像,打印出来的三个维度的数值,是按照 BGR 顺序打印的。在使用 cv.imwrite() 写入输出图像的时候,第二个参数也得按照 BGR 顺序存储,所以如果label上色,记得按照 BGR 顺序赋值。
label_img = cv2.imread("./aaa.png") label_img = cv2.cvtColor(label_img, cv2.COLOR_BGR2RGB) # cv2默认为bgr顺序注:可以使用颜色空间转换函数 cv2.cvtColor 设置 cv2 的默认读取和写入通道顺序。关于该函数讲解见:opencv中颜色空间转换函数 cv2.cvtColor()
先看代码:
import cv2
import numpy as np
ann_img = np.ones((4,3)).astype('uint8')
print(ann_img.shape)
ann_img[:2, :2] = 255
print(ann_img)
print('\n---------------\n')
print(ann_img[:2, :2])
print('\n---------------\n')
cv2.imwrite("label.png", ann_img[:2, :2])
img = cv2.imread("label.png")
print(img.shape)
print(img)运行结果:
(4, 3)
[[255 255 1]
[255 255 1]
[ 1 1 1]
[ 1 1 1]]
---------------
[[255 255]
[255 255]]
---------------
(2, 2, 3)
[[[255 255 255]
[255 255 255]]
[[255 255 255]
[255 255 255]]]可以看到本地保存下来的 label.png 信息,是 8bit 的:
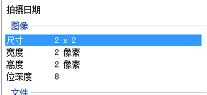
我们来分析下,先看 print(ann_img[:2, :2]) 这行代码打印出来:
[[255 255]
[255 255]]可以看出是两个维度的,且像素值是赋值的 255,没啥问题。然后 cv2.imwrite("label.png", ann_img[:2, :2]) 磁盘写入并保存 label.png 到本地,然后我们再 cv2.imread("label.png") 读取和打印该图像 shape 和像素值,结果:
(2, 2, 3)
[[[255 255 255]
[255 255 255]]
[[255 255 255]
[255 255 255]]]可以看到维度由原来的 2 个维度变为 3 维的了,并且第三个维度的值和前面维度的值是一样的。
解释:本质是因 img = cv2.imread("label.png") 默认以第二个参数为 flags=1 方式读取的(关于第二个参数的详解参考前面的内容)。改为 img = cv2.imread("label.png", 0) 读取,可以看到结果如下:
(2, 2) [[[255 255] [255 255]]
代码:
import numpy as np
import cv2
# 给标签图上色
def color_annotation(label_path, output_path):
'''
给class图上色
'''
img = cv2.imread(label_path,cv2.CAP_MODE_GRAY)
color = np.ones([img.shape[0], img.shape[1], 3])
color[img==0] = [255, 255, 255] #其他,白色,0
color[img==1] = [0, 255, 0] #植被,绿色,1
color[img==2] = [0, 0, 0] #道路,黑色,2
color[img==3] = [131, 139, 139] #建筑,黄色,3
color[img==4] = [139, 69, 19] #水体,蓝色,4
cv2.imwrite(output_path,color)**注意:**这里赋值顺序是先 BGR 顺序,即 [139, 69, 19] 赋值的分别是 B 通道、G 通道、R 通道。具体原因网上查找下资料。
在代码中看到图像的2种处理方式:
- img/255.0
- img/127.5 - 1
第一种是对图像进行归一化,范围为[0, 1],第二种也是对图像进行归一化,范围为[-1, 1],这两种只是归一化范围不同,为了直观的看出2种区别,分别对图像进行两种处理:

从图中可以看出, 第二种方式图像显示的更黑,其直方图如下:
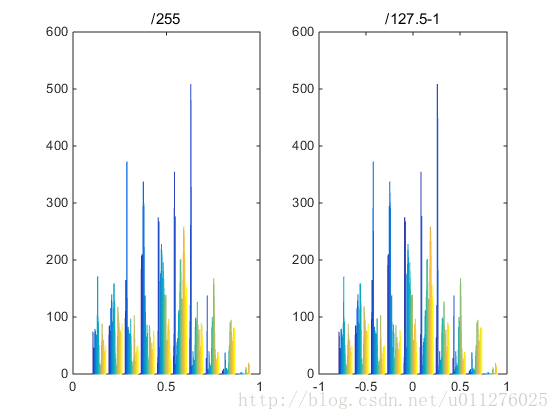
同样,其直方图的分布规律相同,第二种分布相对稀疏。——from:图像处理/255.0 和/127.5 -1
在 skimage 中,一张图片就是一个简单的 numpy 数组,数组的数据类型有很多种,相互之间也可以转换。这些数据类型及取值范围如下表所示:
| Data type | Range |
|---|---|
| uint8 | 0 to 255 |
| uint16 | 0 to 65535 |
| uint32 | 0 to 232 |
| float | -1 to 1 or 0 to 1 |
| int8 | -128 to 127 |
| int16 | -32768 to 32767 |
| int32 | -231 to 231 - 1 |
一张图片的像素值范围是 [0, 255],因此默认类型是 unit8。可用如下代码查看数据类型:
from skimage import io,data
img=data.chelsea()
print(img.dtype.name)在上面的表中,特别注意的是 float 类型,它的范围是 [-1,1] 或 [0,1] 之间。一张彩色图片转换为灰度图后,它的类型就由 unit8 变成了 float。
——from:python数字图像处理(4):图像数据类型及颜色空间转换
tiff 文件是一种常用的图像文件格式,支持将多幅图像保存到一个文件中,极大得方便了图像的保存和处理。
python 中支持 tiff 文件处理的是 libtiff 模块中的 TIFF 类(libtiff 下载链接https://pypi.python.org/pypi/libtiff/)。
1、方法一
使用 pip 安装: pip install libtiff,但是在使用的时候可能会报如下类似错误:
Failed to find TIFF library. Make sure that libtiff is installed and its location is listed in PATH|LD_LIBRARY_PATH|2、方法二
而后,我使用下载 whl 文件,离线本地安装方式,成功了,使用未报错。(参考:RivuletStudio/rivuletpy#8)
-
先使用 pip 卸载前面已安装的 libtiff:
pip uninstall libtiff; -
先在这里 https://www.lfd.uci.edu/~gohlke/pythonlibs/#pylibtiff 选择好相应的 whl 文件下载,我根据我本地的 Python 版本,选择的为
libtiff‑0.4.2‑cp36‑cp36m‑win_amd64.whl; -
下载完毕,切换到 whl 文件所在目录,执行
pip install libtiff‑0.4.2‑cp36‑cp36m‑win_amd64.whl进行安装即可。(注意,请清楚你使用的 pip 是哪个环境下的,避免安装到自己不想安装的 Python 环境下)
3、方法三
我看到还有一种安装方式,也可以试试,来源:http://landcareweb.com/questions/8084/shi-yong-numpyzai-pythonzhong-shi-yong-tiff-dao-ru-dao-chu
如果你在 python3 上,你不能
pip3 install libtiff。而是手动安装:git clone git@github.com:pearu/pylibtiff.git python3 setup.py install
使用:
from libtiff import TIFF
tif = TIFF.open('filename.tif', mode='r')
# read an image in the currect TIFF directory as a numpy array
image = tif.read_image()
# read all images in a TIFF file:
for image in tif.iter_images():
pass
tif = TIFF.open('filename.tif', mode='w')
tif.write_image(image)——from:http://landcareweb.com/questions/8084/shi-yong-numpyzai-pythonzhong-shi-yong-tiff-dao-ru-dao-chu 的 libtiff 部分。
常见函数的使用,个人小结:
tif = TIFF.open() 打开图像,返回类型 TIFF
image = tif.read_image() 读取图像,返回类型 ndarray
image.shape 形状,如(7200, 6800, 3)
image[:, :, 0] 查看第一通道的矩阵数值
TIFF.write() 写入图像【python图像处理】tiff文件的保存与解析:(——from:https://unordered.org/timelines/5a232a93f1800000)
from libtiff import TIFF
from scipy import misc
##tiff文件解析成图像序列
##tiff_image_name: tiff文件名;
##out_folder:保存图像序列的文件夹
##out_type:保存图像的类型,如.jpg、.png、.bmp等
def tiff_to_image_array(tiff_image_name, out_folder, out_type):
tif = TIFF.open(tiff_image_name, mode = "r")
idx = 0
for im in list(tif.iter_images()):
#
im_name = out_folder + str(idx) + out_type
misc.imsave(im_name, im)
print im_name, 'successfully saved!!!'
idx = idx + 1
return
##图像序列保存成tiff文件
##image_dir:图像序列所在文件夹
##file_name:要保存的tiff文件名
##image_type:图像序列的类型
##image_num:要保存的图像数目
def image_array_to_tiff(image_dir, file_name, image_type, image_num):
out_tiff = TIFF.open(file_name, mode = 'w')
#这里假定图像名按序号排列
for i in range(0, image_num):
image_name = image_dir + str(i) + image_type
image_array = Image.open(image_name)
#缩放成统一尺寸
img = image_array.resize((480, 480), Image.ANTIALIAS)
out_tiff.write_image(img, compression = None, write_rgb = True)
out_tiff.close()
return 对比测试 scipy.misc 和 PIL.Image 和 libtiff.TIFF 三个库
测试两类输入矩阵:
- (读取图像) 读入uint8、uint16、float32的lena.tif
- (生成矩阵) 使用numpy产生随机矩阵,float64的mat
import numpy as np
from scipy import misc
from PIL import Image
from libtiff import TIFF
#
# 读入已有图像,数据类型和原图像一致
tif32 = misc.imread('.\test\lena32.tif') #<class 'numpy.float32'>
tif16 = misc.imread('.\test\lena16.tif') #<class 'numpy.uint16'>
tif8 = misc.imread('.\test\lena8.tif') #<class 'numpy.uint8'>
# 产生随机矩阵,数据类型float64
np.random.seed(12345)
flt = np.random.randn(512, 512) #<class 'numpy.float64'>
# 转换float64矩阵type,为后面作测试
z8 = (flt.astype(np.uint8)) #<class 'numpy.uint8'>
z16 = (flt.astype(np.uint16)) #<class 'numpy.uint16'>
z32 = (flt.astype(np.float32)) #<class 'numpy.float32'> ①对图像和随机矩阵的存储
# scipy.misc『不论输入数据是何类型,输出图像均为uint8』
misc.imsave('.\test\lena32_scipy.tif', tif32) #--> 8bit(tif16和tif8同)
misc.imsave('.\test\\randmat64_scipy.tif', flt) #--> 8bit
misc.imsave('.\test\\randmat8_scipy.tif', z8) #--> 8bit(z16和z32同)
# PIL.Image『8位16位输出图像与输入数据类型保持一致,64位会存成32位』
Image.fromarray(tif32).save('.\test\lena32_Image.tif') #--> 32bit
Image.fromarray(tif16).save('.\test\lena16_Image.tif') #--> 16bit
Image.fromarray(tif8).save('.\test\lena8_Image.tif') #--> 8bit
Image.fromarray(flt).save('.\test\\randmat_Image.tif') #--> 32bit(flt.min~flt.max)
im = Image.fromarray(flt.astype(np.float32))
im.save('.\test\\randmat32_Image.tif') #--> 32bit(灰度值范围同上)
#『uint8和uint16类型转换,会使输出图像灰度变换到255和65535』
im = Image.frombytes('I;16', (512, 512), flt.tostring())
im.save('.\test\\randmat16_Image1.tif') #--> 16bit(0~65535)
im = Image.fromarray(flt.astype(np.uint16))
im.save('.\test\\randmat16_Image2.tif') #--> 16bit(0~65535)
im = Image.fromarray(flt.astype(np.uint8))
im.save('.\test\\randmat8_Image.tif') #--> 8bit(0~255)
# libtiff.TIFF『输出图像与输入数据类型保持一致』
tif = TIFF.open('.\test\\randmat_TIFF.tif', mode='w')
tif.write_image(flt, compression=None)
tif.close() #float64可以存储,但因BitsPerSample=64,一些图像软件不识别
tif = TIFF.open('.\test\\randmat32_TIFF.tif', mode='w')
tif.write_image(flt.astype(np.float32), compression=None)
tif.close() #--> 32bit(flt.min~flt.max)
#『uint8和uint16类型转换,会使输出图像灰度变换到255和65535』
tif = TIFF.open('.\test\\randmat16_TIFF.tif', mode='w')
tif.write_image(flt.astype(np.uint16), compression=None)
tif.close() #--> 16bit(0~65535,8位则0~255)②图像或矩阵归一化对存储的影响
# 『使用scipy,只能存成uint8』
z16Norm = (z16-np.min(z16))/(np.max(z16)-np.min(z16)) #<class 'numpy.float64'>
z32Norm = (z32-np.min(z32))/(np.max(z32)-np.min(z32))
scipy.misc.imsave('.\test\\randmat16_norm_scipy.tif', z16Norm) #--> 8bit(0~255)
# 『使用Image,归一化后变成np.float64 直接转8bit或16bit都会超出阈值,要*255或*65535』
# 『如果没有astype的位数设置,float64会直接存成32bit』
im = Image.fromarray(z16Norm)
im.save('.\test\\randmat16_norm_Image.tif') #--> 32bit(0~1)
im = Image.fromarray(z16Norm.astype(np.float32))
im.save('.\test\\randmat16_norm_to32_Image.tif') #--> 32bit(灰度范围值同上)
im = Image.fromarray(z16Norm.astype(np.uint16))
im.save('.\test\\randmat16_norm_to16_Image.tif') #--> 16bit(0~1)超出阈值
im = Image.fromarray(z16Norm.astype(np.uint8))
im.save('.\test\\randmat16_norm_to8_Image.tif') #--> 8bit(0~1)超出阈值
im = Image.fromarray((z16Norm*65535).astype(np.uint16))
im.save('.\test\\randmat16_norm_to16_Image1.tif') #--> 16bit(0~65535)
im = Image.fromarray((z16Norm*255).astype(np.uint16))
im.save('.\test\\randmat16_norm_to16_Image2.tif') #--> 16bit(0~255)
im = Image.fromarray((z16Norm*255).astype(np.uint8))
im.save('.\test\\randmat16_norm_to8_Image2.tif') #--> 8bit(0~255)
# 『使用TIFF结果同Image』③TIFF读取和存储多帧 tiff 图像
#tiff文件解析成图像序列:读取tiff图像
def tiff_to_read(tiff_image_name):
tif = TIFF.open(tiff_image_name, mode = "r")
im_stack = list()
for im in list(tif.iter_images()):
im_stack.append(im)
return
#根据文档,应该是这样实现,但测试中不管是tif.read_image还是tif.iter_images读入的矩阵数值都有问题
#图像序列保存成tiff文件:保存tiff图像
def write_to_tiff(tiff_image_name, im_array, image_num):
tif = TIFF.open(tiff_image_name, mode = 'w')
for i in range(0, image_num):
im = Image.fromarray(im_array[i])
#缩放成统一尺寸
im = im.resize((480, 480), Image.ANTIALIAS)
tif.write_image(im, compression = None)
out_tiff.close()
return 补充:libtiff 读取多帧 tiff 图像
因为(单帧)TIFF.open().read_image()和(多帧)TIFF.open().iter_images() 有问题,故换一种方式读
from libtiff import TIFFfile
tif = TIFFfile('.\test\lena32-3.tif')
samples, _ = tif.get_samples()——from:python下tiff图像的读取和保存方法
tiff 文件是一种常用的图像文件格式,支持将多幅图像保存到一个文件中,极大得方便了图像的保存和处理。
python 中支持 tiff 文件处理的是 libtiff 模块中的 TIFF 类(libtiff 下载链接https://pypi.python.org/pypi/libtiff/)。
这里主要介绍 tiff 文件的解析和保存,具体见如下代码:
from libtiff import TIFF
from scipy import misc
##tiff文件解析成图像序列
##tiff_image_name: tiff文件名;
##out_folder:保存图像序列的文件夹
##out_type:保存图像的类型,如.jpg、.png、.bmp等
def tiff_to_image_array(tiff_image_name, out_folder, out_type):
tif = TIFF.open(tiff_image_name, mode = "r")
idx = 0
for im in list(tif.iter_images()):
#
im_name = out_folder + str(idx) + out_type
misc.imsave(im_name, im)
print im_name, 'successfully saved!!!'
idx = idx + 1
return
##图像序列保存成tiff文件
##image_dir:图像序列所在文件夹
##file_name:要保存的tiff文件名
##image_type:图像序列的类型
##image_num:要保存的图像数目
def image_array_to_tiff(image_dir, file_name, image_type, image_num):
out_tiff = TIFF.open(file_name, mode = 'w')
#这里假定图像名按序号排列
for i in range(0, image_num):
image_name = image_dir + str(i) + image_type
image_array = Image.open(image_name)
#缩放成统一尺寸
img = image_array.resize((480, 480), Image.ANTIALIAS)
out_tiff.write_image(img, compression = None, write_rgb = True)
out_tiff.close()
return ——from:【python图像处理】tiff文件的保存与解析
很多医学文件采用格式TIFF格式存储,并且一个TIFF文件由多帧序列组合而成,使用libtiff可以将TIFF文件中的多帧提取出来。
from libtiff import TIFF
def tiff2Stack(filePath):
tif = TIFF.open(filePath,mode='r')
stack = []
for img in list(tif.iter_images()):
stack.append(img)
return stack——from:Python进行TIFF文件处理
GDAL(Geospatial Data Abstraction Library)是一个的开源栅格空间数据读取/转换库。其中还有一系列命令行工具来进行数据转换和处理。
而 ORG 项目是 GDAL 的一个分支,功能与 GDAL 类似,只不过它提供对矢量数据的支持。 也就是说,可以用 ORG 的库来读取、处理 shapefile 等矢量数据(如果想显示 shapefile,还需要用其他工具)。
有很多著名的 GIS 类产品都使用了 GDAL/OGR 库,包括 ESRI 的 ARCGIS 9.3,Google Earth 和跨平台的 GRASS GIS 系统。利用 GDAL/OGR 库,可以使基于 Linux 的地理空间数据管理系统提供对矢量和栅格文件数据的支持。
外文名:Geospatial Data Abstraction Library
简 称:GDAL
性 质:开源栅格空间数据转换库
用 途:进行数据转换和处理
这里引用一篇博主的博文,提到使用 GDAL 的缘由:
之所以想在 Python 下使用 GDAL,其实源自一个很实际的需求。虽然 OpenCV 处理图像能力很强, 但是有个短板就是无法加载真正的遥感影像进行处理。因为遥感影像原图一般都 1G 多, 利用 OpenCV 直接打开会提示内存不足。 于是自然地在网上找 OpenCV 打开大图像的相关内容,发现并没有这方面的资料可以参考。 但我们又有读取原始遥感影像的需求。所以必须要解决这个问题。 于是自然想到了两个办法,一是利用 Python 读取大文件的方法。但是看了相关内容后发现, 主要是针对文本文件的读取,并不适合影像。于是放弃。第二种方法是使用 GDAL 来读取遥感影像。 这种方法就是传统也是最有效的办法。
源文请阅读:Python下GDAL安装与使用 - 含 GDAL 的安装和使用。写的很详细。【荐】
以下内容为对原文的主要要点摘入,和自己的理解以及实操,实际按照步骤来是可行的。
在 Python下安装 GDAL 其实可以分两大部分,一部分是”Core”的安装,另一部分是”Binding”的安装。 可以理解为 Core 是 GDAL 的公有 DLL 库,所有语言都会调用这些 DLL 实现功能,而 Binding 则相当于是这些库的 Python 打包接口,以便 Python 可以调用。 虽然也可以使用 pip 安装”pip install gdal”,但是经过测试会有各种编译的错误,所以不推荐用这种方式安装。 在【这篇博客】中对不同环境下安装 GDAL 进行了简单的总结,以下为其内容的摘入:
不过这里有个问题需要注意。就是 GDAL 的库并不太好安装,直接使用
pip install gdal很有可能会失败。 因为安装的是源码包,所以在安装前会编译,而编译又需要用到其它依赖,所以失败的可能性很大。如果你是 Windows 用户,那么你可以在【这个网站】搜索下载对应的 GDAL 预先编译好的 wheel 包,然后本地安装即可,一般不会出现问题。或者,如果你使用 Anaconda 环境,那么你可以直接
conda install gdal,Anaconda 会自动帮你编译、安装好 GDAL。 (2018-8-7补充:有时可能会出现安装成功,但使用时报找不到 DLL 的错误。这主要是因为虽然 Conda 把 GDAL 包给装了,但是并没有安装完全依赖的DLL。 所以解决办法就是按照【这篇博客】中提到的,安装一下 GDAL Core,基本就能解决问题了。)
我自己来复述下上面引用表达的意思吧,简单说,想要在 Python 环境安装好 GDAL:
-
使用
pip install gdal很有可能会失败。 因为安装的是源码包,所以在安装前会编译,而编译又需要用到其它依赖,所以失败的可能性很大。 -
如果使用的 Anconada 环境,可以考虑直接使用
pip install gdal进行安装,可以安装成功,但是在编写 python 代码使用过程中,可能会报找不到 DLL 的错误。(注:在我后面运行某代码,确实有出现了找不到 DLL 的问题)- 主要原因是 conda 把 GDAL 包安装了,但并没有安装完全依赖的 DLL。所以解决办法就是按照【这篇博客】提到的,先安装好 GDAL Core,就可以解决问题。
所以我们先安装好 GDAL Core 吧。按照如下方式分别安装好:gdal-300-1911-x64-core.msi 、GDAL-3.0.0.win-amd64-py3.6.msi(即 GDAL for Python)。
1、下载安装包
打开这个网站如下图,选择对应的安装包。
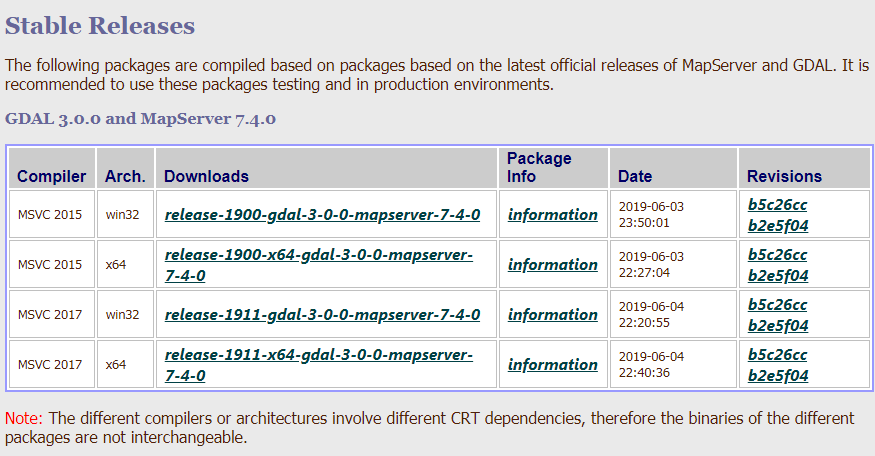
选择时有几个需要注意的地方。首先是 Compiler,这个版本要和你电脑上的VS版本对应。 其次是 Arch.,注意这里并不是与你系统的位数保持一致,而是要和 Python 位数保持一致。 假设某电脑上有 VS2010,系统是 64 位但安装了 32 位的 Python, 所以最终选择的版本是 release-1911-gdal-3-0-0-mapserver-7-4-0。 点击便会进入下一个界面,可以看到有很的可供选择。
怎么选择?首先根据电脑安装的 Python 版本选择对应的安装包,例如我的电脑上 Python 是 3.6 版本,Python 是 64 位的。我如下选择安装包(红色框)。
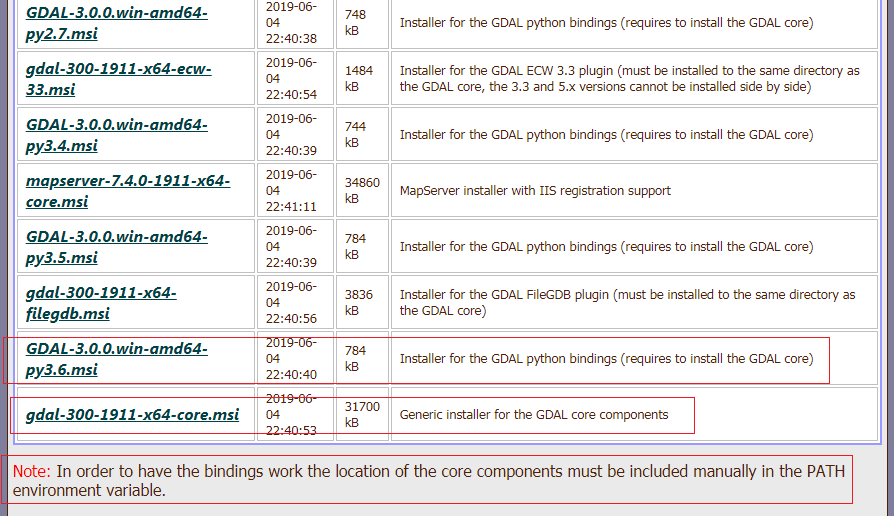
选择好后点击相应的安装包下载即可。 要注意底下的提示,告诉我们在安装好 Core 后,需要手动将路径添加到系统变量中,否则可能找不到。
2、安装
1)首先安装 gdal-300-1911-x64-core.msi
下一步下一步这样的操作,略。注意:安装完毕,添加 C:\Program Files\GDAL\ 到 Path 中。
检测是否添加成功,可以打开系统的“运行”,然后输入 gdalinfo –-version,如果出现如下提示说明安装成功。
2)安装 GDAL-3.0.0.win-amd64-py3.6.msi(即 GDAL for Python)
点击下一步下一步的操作。注意:其中某一步的页面,第二项选择”Entire feature…“,同时在下面的路径中填写本地的 Python 安装路径,这样程序会自动把文件放到 Lib\site-packages\ 下面,很方便。
3、测试
最后我们可以打开 PyCharm 测试一下,可以看到导入包没有问题,程序正常退出。这样 GDAL 的 Python 环境就配置安装完了。
from osgeo import gdal
from osgeo.gadlconst import *1、方法一:本地安装
先进入网址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#gdal,根据 Python 版本选择相应的 GDAL 下载。本人根据自己 Python 版本 3.6、64位,选择的为:GDAL‑3.0.0‑cp36‑cp36m‑win_amd64.whl。
然后使用你想要的安装 GDAL 到哪个 Python 环境,选择那个环境的 pip 进行安装即可:pip install GDAL‑3.0.0‑cp36‑cp36m‑win_amd64.whl
2、方法二:使用 pip 或 conda 安装
- 使用
pip install gdal安装,最前面也提到,使用 pip 安装,“经过测试会有各种编译的错误“,所以不推荐该方式。 - 如果有 Anconda 环境,可以考虑使用
conda install gdal安装试试。
利用GDAL读取遥感原始影像非常简单,代码如下:
from osgeo import gdal
from gdalconst import *
dataset = gdal.Open(r"E:\GF2_PMS1__20150212_L1A0000647768-MSS1 (2).tif", GA_ReadOnly)
if dataset is None:
print("None")
else:
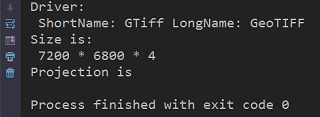
print ('Driver:\n', 'ShortName:', dataset.GetDriver().ShortName, 'LongName:', dataset.GetDriver().LongName)
print ('Size is:\n', dataset.RasterXSize, '*', dataset.RasterYSize, '*', dataset.RasterCount)
print ('Projection is ', dataset.GetProjection())结果如下,在控制台中输出了文件的相关信息:
影像读取实例:下面代码展示了读取一幅遥感印象其中一个波段某一区域的影像,并显示出来。
# coding=utf-8
from osgeo import gdal
from gdalconst import *
from matplotlib import pyplot as plt
# 以只读方式打开遥感影像
dataset = gdal.Open(r"E:\GF2_PMS1__20150212_L1A0000647768-MSS1 (2).tif", GA_ReadOnly)
# 输出影像信息
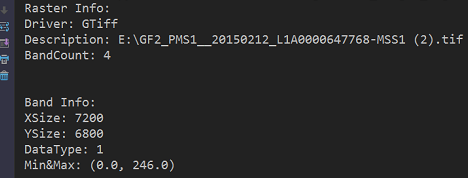
print('Raster Info:')
print('Driver:', dataset.GetDriver().ShortName)
print('Description:', dataset.GetDescription())
print('BandCount:', dataset.RasterCount)
print('\n')
# 获取影像的第一个波段
band_b = dataset.GetRasterBand(1)
# 输出波段信息
print('Band Info:')
print('XSize:', band_b.XSize)
print('YSize:', band_b.YSize)
print('DataType:', band_b.DataType)
print('Min&Max:', band_b.ComputeRasterMinMax())
# 读取第一个波段中从(4000,7300)开始,x、y方向各400像素的范围
data = band_b.ReadAsArray(4000, 4300, 400, 400)
# 调用Matplotlib以灰度形式显示图像
plt.imshow(data, cmap='gray')
plt.show()控制台打印结果如下:
显示的图像信息:
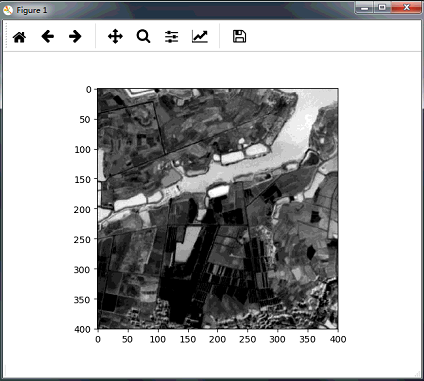
若要获取某个波段数值,可以使用 ReadAsArray 函数:
dataset = gdal.Open(r"E:\aa.tif", GA_ReadOnly)
band_b = img3.GetRasterBand(4) #获取第4通道
print(band_b.ReadAsArray())具体用法参考:https://www.osgeo.cn/pygis/gdal-gdalreadata.html 或下面的函数详解。
相关函数见原文:
- dir(dataset)、help(dataset)
- dataset.GetDescription()
- dataset.RasterCount
- dataset.GetRasterBand(BandNumber)
- dataset.RasterXSize
- dataset.RasterYSize
- dataset.ReadRaster()、dataset.ReadAsArray()
- dir(band)、help(band)
- band.XSize
- band.YSize
- band.DataType
- band.GetNoDataValue()
- band.GetMaximum()
- band.GetMinimum()
- band.ComputeRasterMinMax()
基于上面的知识,这里进行一个简单的练习,即利用 GDAL 为遥感影像制作小尺寸的缩略图。
# coding=utf-8
from osgeo import gdal
from gdalconst import *
from matplotlib import pyplot as plt
# 用户输入影像路径
image_path = input("Input image path:\n")
# 以只读方式打开遥感影像
dataset = gdal.Open(image_path, GA_ReadOnly)
# 获取影像波段数
bandNumber = dataset.RasterCount
# 用户输入生成缩略图的波段
selected_band = input(
bandNumber.__str__() + " band(s) in total.Input the number of band(1-" + bandNumber.__str__() + "):\n")
# 获取波段内容
band = dataset.GetRasterBand(selected_band)
# 设置缩放比例因子
scale = 0.1
scale = input("Input scale factor(0-1):\n")
# 原始影像大小
oriX = band.XSize
oriY = band.YSize
# 缩放后影像大小
newX = int(scale * oriX)
newY = int(scale * oriY)
# 输出信息
print('Output Info:')
print("Original Size is ", oriX, " * ", oriY)
print("New Size is ", newX, " * ", newY)
print("Selected band is ", selected_band)
# 用户交互,是否确定
result = input("Are you sure?(Y/N)")
# 如果确定就继续,否则退出
if result.__eq__('Y') or result.__eq__('y'):
print("Processing...")
# 读取影像,这里最后两个参数即使在前面说过的最终需要的大小
data = band.ReadAsArray(0, 0, band.XSize, band.YSize, newX, newY)
print("OK.")
# 调用Matplotlib以灰度形式显示图像
plt.imshow(data, cmap='gray')
plt.show()
else:
print("Exit.")根据提示输入相关参数。
注意,输入哪个通道 band 的时候,继续运行会报错。原因是:
在 Python3.x 中 raw_input( ) 和 input( ) 进行了整合,去除了 raw_input( ),仅保留了 input( ) 函数,其接收任意任性输入,将所有输入默认为字符串处理,并返回字符串类型。详细:Python2.x 和 Python3.x 中 raw_input( ) 和 input( ) 区别 | 菜鸟教程
所以代码需要改下,在需要用户输入的两处加上,如下:
# 用户输入生成缩略图的波段 selected_band = input( bandNumber.__str__() + " band(s) in total.Input the number of band(1-" + bandNumber.__str__() + "):\n") selected_band = int(selected_band) # 加上的 # 获取波段内容 band = dataset.GetRasterBand(selected_band) # 设置缩放比例因子 scale = 0.1 scale = input("Input scale factor(0-1):\n") scale = float(scale) # 加上的
之前在【这篇博客】中简单介绍了 GDAL 的使用,但并不是很完整。本文给出一个相对规范、比较完整,具有一定通用性的 GDAL 读写 tif 影像的代码,以便以后使用。代码以图像裁剪和波段融合/分离两个小功能为例进行介绍。