React源码阅读系列 #1
Comments
React源码之初次渲染(本段提及代码详见ReactElement.js,这里就不为了好看而贴图了) ReactCompositeComponent是自定义组件(复合组件),ReactDOMComponent指的是浏览器自带标签,ReactDOMTextComponent是针对文本节点的。三者面向的类型不同,但它们的挂载方法都叫做mountComponent(React做了很多的抽象封装,使各个函数功能能够处理各种结点等而不需要处处修改)。此外,我们通常所说的Virtual DOM 是ReactElement,并通过ReactDOM的render方法渲染到真实DOM上。 那么为了实现渲染,究竟需要那些核心功能呢? 首先一定需要一个component类,用来表示组件在渲染、更新、删除时应该做些什么事情;然后需要一个component工厂方法,用来返回一个component实例(这样就可以使返回实例可以屏蔽底层对具体类型的判断和处理);另外需要mountComponent方法,用来在component渲染时生成DOM结构;最后还需要render方法作为渲染的入口方法,内部通过事务来触发挂载,将内容写入对应的container中去。 那么具体来说,初次渲染是怎么一个流程呢?又是怎么利用这些核心功能的呢? 我们知道React的虚拟DOM的概念,事实上,React.createElement就会创建一个这样的虚拟DOM。在React.createElement方法中,会首先检测config参数,而它包含着我们在使用React组件时可能会传入的ref、key(优化效率)、onClick等,此时ReactElement会将其保存为内部属性留与后用,然后,将其中的属性传入props保存,并且子元素children也会被保存到props。之后会调用ReactElement来返回虚拟DOM,而ReactElement貌似是个构造函数,实际上就是个工厂函数了,并且通过 $$typeof: REACT_ELEMENT_TYPE 来将其标记为ReactElement。当然,如果打debugger调试的话,也会并不意外的发现这些方法会recursive的调用,下面将要提到的instantiateReactComponent 也是一样,没办法,DOM树就这样嘛。(本段提及代码详见ReactElement.js) 因为有了ReactElement,就需要将其渲染出来,也就来到了instantiateReactComponent方法。这个方法本质上也是工厂函数,并且在内部会对需要render的node类型进行判断,调用不同的方法来区别渲染。这样对于render而言,就不需要关心具体类型了。当然一个有意思的点是,ReactCompositeComponentWrapper作为ReactCompositeComponent的Wrapper,实际上就是assign了instantiateReactComponent方法,也就是说,对于不同的node,各自调用instantiateReactComponent就可以渲染各自的component实例了。当然啦,像我此时试验所用的根组件就是返回的ReactCompositeComponentWrapper实例。 这里继续看ReactCompositeComponent。不妨看看performInitialMount方法,它会在内部会调用componentWillMount钩子和_processPendingState,然后先将子ReactElement用_instantiateReactComponent渲染成child(ReactCompositeComponentWrapper),接着再将其用ReactReconciler.mountComponent渲染成一个Markup。事实上,这个调和器也是类似前面的工厂函数一样,屏蔽了想要mount的component的类型,在内部仍旧统一调用了mountComponent,换句话说,Markup就是child.mountComponent。而Markup就是ReactDOMComponent,如果将其打印的话可以看到,它就是那个准备被insertBefore到真实DOM树的,哈哈。主要流程如下(其实还是蛮简化的,不过应该算是很重要的部分了吧)。
在一篇文章上看到这样的图,相较而言更体现出instantiateReactComponent对不同元素类型的屏蔽,但是我画的完整一点吧。可留作参考。
最后,既然上面已经出现了componentWillMount,可知,在我们终于要完成初次渲染的旅程时,一定会有componentDidMount,至于具体在哪,就不具体指出了。总之,现在想想过去面试常被问的生命周期,真不是什么上档次的问题…也难怪要是连这个都不懂,就得被pass啊。 后续会对更完整的更新机制进一步做探究。 |


React源码之setState在我们对组件的状态进行修改时几乎一定会用到的就是setState方法,而较为常见的使用方式就是传入一个对象。从官网的文档中可以看到:这种形式的setState()是异步的,在同一个循环(cycle)中调用多次会被batch到一起,并且在一个cycle中调用多次increment最终却只会进行一次。那么,setState方法究竟在框架内部做了哪些工作导致了文档中所描述的情况,我们又可从中学习到哪些更好的实践呢? 代码调试这里先通过打debugger和阅读源码,给出在一个handleClick里调用setState后代码的流动情况来理解这个过程。
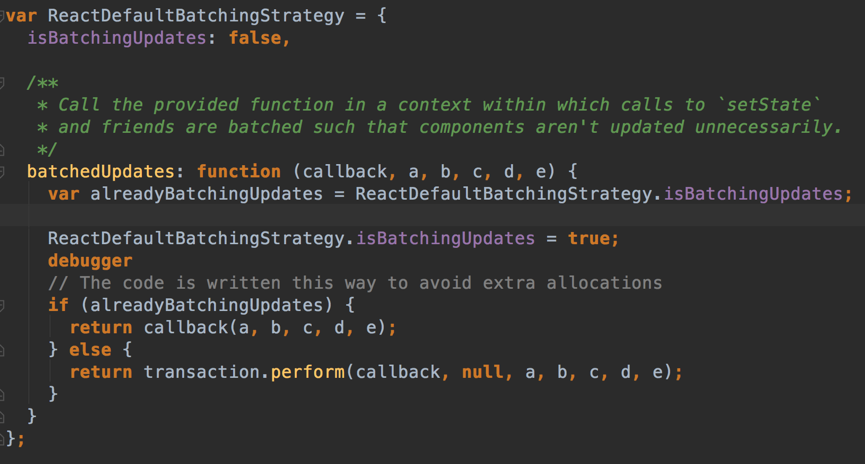
可以看到,React在事件派发的时候调用了ReacUpdates.batchedUpdates方法,而这一方法来自ReactDefaultBatchingStrategy. batchedUpdates,
这一方法算是比较核心的一个方法,甚至在通常所说的“生命周期”的钩子方法执行前也会先执行batchedUpdates(这里在后面的例子分析)。对于当前的情形,因为尚未处于批量更新的状态,alreadyBatchingUpdates这一bool变量为false,于是会走向事务transaction.perform。因此,在经历一系列事件处理后,调用栈进入到ReactComponent.prototype.setState进行状态的改变。 但是有一点非常重要的是,尽管alreadyBatchingUpdates为false,但isBatchingUpdates却被修改为true,而这会影响到后续的执行流程(作为dirtyComponents处理)。 setState接受了一个partialState参数,代表了部分发生改变的状态。在setState内部则是会调用enqueueSetState方法:
其中,updater是被注入进来的,先不去深究,而enqueueSetState方法在ReactUpdateQueue.js文件中,内部调用ReactUpdates.enqueueUpdate,再次进入函数阅读,就可以看到核心的一段代码:
若isBatchingUpdates为 true,则把当前状态等待更新的组件(即调用setState的组件,类型其实是ReactCompositeComponentWrapper,是自定义组件类的一个包装,其实就是通过_assign方法在原型上添加了一个方法)放入 dirtyComponents 数组中;否则会调用batchUpdates处理所有队列中的更新,甚至我们可以看到,该方法会在内部继续调用enqueueUpdate。也就是说,尽管使用时就是用一个setState,但实际更新的情况却会根据是否处于“批量更新”的状态来决定是先“批量更新”还是push进dirtyComponents等待后续的处理。 如果batchedUpdates,那么就是直接开始去更新了,这里会push到dirtyComponents,然后事务触发close(本例中是closeAll,但其实也是close…)才取更新视图。
上面红框的两个事务非常多见,在进入closeAll之后会进入到flushBatchedUpdates,可以从下图看到,函数在循环中将dirtyComponents中的自定义组件wrapper挨个取出,并执行了关键一步,是的又是事务,并在这一步完成了视图的更新。之后就是一些释放工作了。
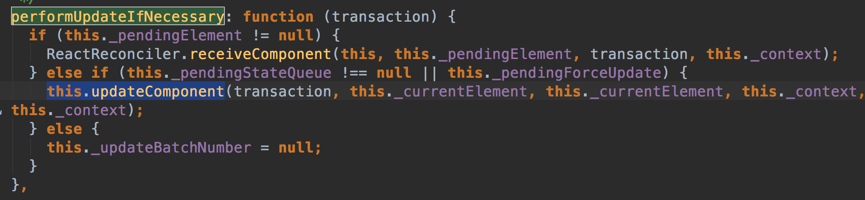
然而,还需要继续进入runBatchedUpdates,这一函数我就不截图了,它首先对要更新的dirtyComponent进行了排序,比如说有时更新了外层组件也会影响到内部组件因而需要先更新内部组件;然后继续调用ReactReconciler.performUpdateIfNecessary,但其实内部是这样的:
internalInstance,看到现在应该猜得到是ReactCompositeComponent(Wrapper),果然,ReactCompositeComponent早就定义了performUpdateIfNecessary方法,此处会由updateComponent方法来进行组件更新。可以看到,从onClick事件开始到现在,已经终于来到ReactCompositeComponent这一自定义组件的地盘。
updateComponent函数还挺长的,这里介绍其主要思想(但其实是最终更新的核心)。首先提供了componentWillReceiveProps钩子,并通过this._processPendingState计算了新的状态,然后提供了shouldComponentUpdate钩子,并且会在未提供的情况下做shallowEqual比较。最终由_performComponentUpdate执行更新。 在函数内部出现的几个变量需要说明的是,_renderedComponent是ReactDOMComponent类型的,什么意思呢?可以说,这是React加工出来的“伪”DOM元素,它拥有变成真实DOM所需的标签、子元素、设置的事件回调等等。 继续调用ReactReconciler.receiveComponent之后,又会跳到ReactDOMComponent. receiveComponent(发现这个套路没……)然后跳到ReactDOMComponent. updateComponent,可以看到下图中,先更新了属性,然后更新子DOM,也就是说更新本身是个递归过程,
然后执行进去后,在这一句发生了变化:
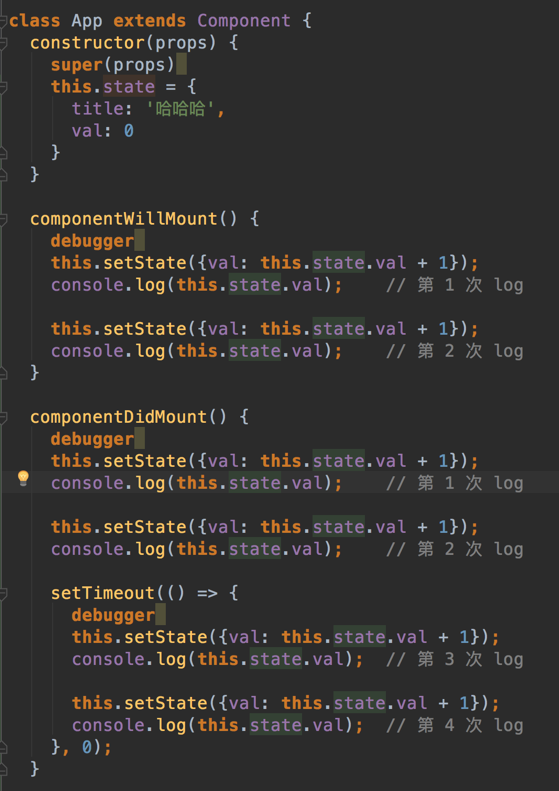
而实现的过程就是由调和器ReactChildReconciler.unmountChildren去掉子元素后重新挂载新元素导致的。 事实上,底层涉及到的操作都和这几个事务有关,在下一个例子中会看到它们是如何影响setState的行为的。 实例分析这个例子是从别人的分析中看来的,以此为基础也加深了我的理解和思考。这里分析如下(图片有点长。。。):
上面代码的结果是0 0 1 1 3 4。总的来说这个意思就是: 在ComponentWillMount、ComponentDidMount里,会先触发事务进入batchedUpdates执行状态,状态的更新都会被push进dirtyComponent并且只执行一次。这里划掉是因为这个理解不准确。正如前面所提到的文档描述,所谓的只执行一次,是因为每一个setState都没有立即更新,所以在同一个cycle里,this.state.val都是一样的,而this.state.val+1也是如此。这样一来,连续几个setState只是在反复令val等于同一个值而已,并且push到dirtyComponents里没有立即执行。所以,每一个setState都执行了,而并非文档中所说的“只执行一次increment”。而在setTimeout里,调用栈则简单得多,最终会立即更新,而打印出的值也是正常的。 结合平时的使用,我们可以尽量避免在同一个cycle中多次使用setState,同时,对于需要使用前一个状态的情形,使用setState的updater function form,如下所示:
最后尽管在对源码的理解上缺乏深度,还停留在发现是这样而不能理解这样设计的道理的层次上,但是我仍会坚持下去,希望在以后的学习中会有更深刻的体会和更显著的提升。 |










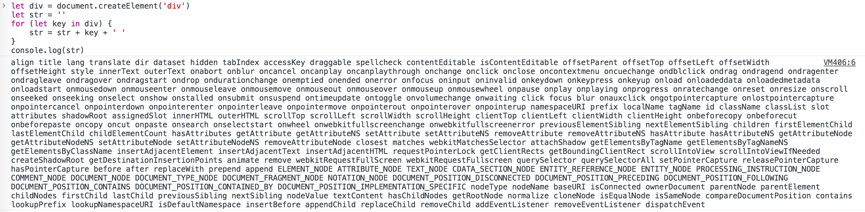
React源码之Diff算法React框架使用的目的,就是为了维护状态,更新视图。 为什么会说传统DOM操作效率低呢?当使用document.createElement()创建了一个空的Element时,会需要按照标准实现一大堆的东西,如下图所示。此外,在对DOM进行操作时,如果一不留神导致回流,性能可能就很难保证了。
相比之下,JS对象的操作却有着很高的效率,通过操作JS对象,根据这个用 JavaScript 对象表示的树结构来构建一棵真正的DOM树,正是React对上述问题的解决思路。之前的文章中可以看出,使用React进行开发时, DOM树是通过Virtual DOM构造的,并且,React在Virtual DOM上实现了DOM diff算法,当数据更新时,会通过diff算法计算出相应的更新策略,尽量只对变化的部分进行实际的浏览器的DOM更新,而不是直接重新渲染整个DOM树,从而达到提高性能的目的。在保证性能的同时,使用React的开发人员就不必再关心如何更新具体的DOM元素,而只需要数据状态和渲染结果的关系。 传统的diff算法通过循环递归来对节点进行依次比较还计算一棵树到另一棵树的最少操作,算法复杂度为O(n^3),其中n是树中节点的个数。尽管这个复杂度并不好看,但是确实一个好的算法,只是在实际前端渲染的场景中,随着DOM节点的增多,性能开销也会非常大。而React在此基础之上,针对前端渲染的具体情况进行了具体分析,做出了相应的优化,从而实现了一个稳定高效的diff算法。 diff算法有如下三个策略:
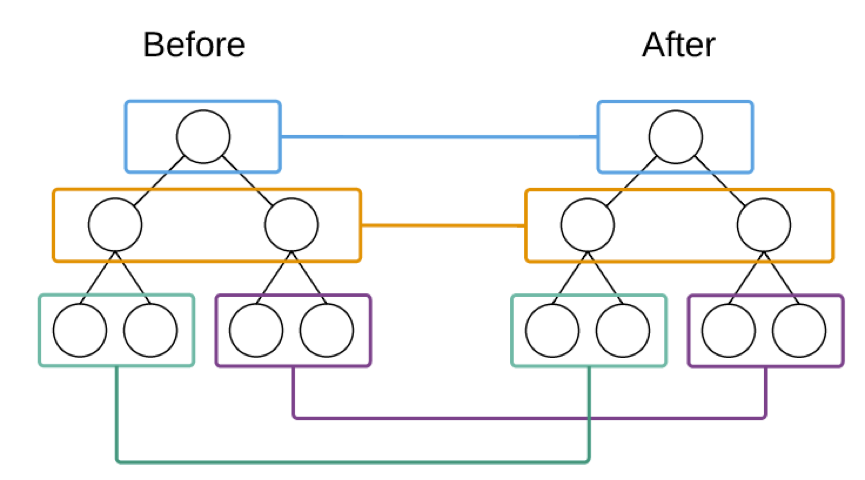
虚拟DOM树分层比较两棵树只会对同一层次的节点进行比较,忽略DOM节点跨层级的移动操作。React只会对相同颜色方框内的DOM节点进行比较,即同一个父节点下的所有子节点。当发现节点已经不存在,则该节点及其子节点会被完全删除掉,不会用于进一步的比较。这样只需要对树进行一次遍历,便能完成整个DOM树的比较。由此一来,最直接的提升就是复杂度变为线型增长而不是原先的指数增长。
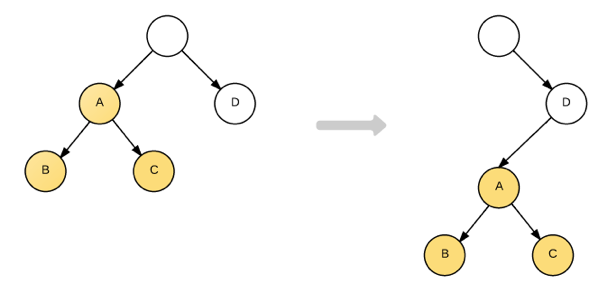
值得一提的是,如果真的发生跨层级移动(如下图),例如某个DOM及其子节点进行移动挂到另一个DOM下时,React是不会机智的判断出子树仅仅是发生了移动,而是会直接销毁,并重新创建这个子树,然后再挂在到目标DOM上。从这里可以看出,在实现自己的组件时,保持稳定的DOM结构会有助于性能的提升。事实上,React官方也是建议不要做跨层级的操作。因此在实际使用中,比方说,我们会通过CSS隐藏或显示某些节点,而不是真的移除或添加DOM节点。其实一旦接受了React的写法,就会发现前面所说的那种移动的写法几乎不会被考虑,这里可以说是React限制了某些写法,不过遵守这些实践确实会使得React有更好的渲染性能。如果真的需要有移动某个DOM的情况,或许考虑考虑尽量用CSS3来替代会比较好吧。
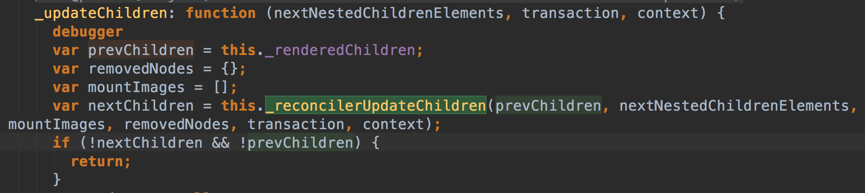
关于这一部分的源码,首先需要提到的是,React是如何控制“层”的。在许多源码阅读的文章里(搜到的讲的比较细的一般都是两三年前啦),都是说用一个updateDepth或者某种控制树深的变量来记录跟踪。事实上就目前版本来看,已经不是这样了(如果我没看错…)。ReactDOMComponent .updateComponent方法用来更新已经分配并挂载到DOM上的DOM组件,并在内部调用ReactDOMComponent._updateDOMChildren。而ReactDOMComponent通过_assign将ReactMultiChild.Mixin挂到原型上,获得ReactMultiChild中定义的方法updateChildren(事实上还有updateTextContent等方法也会在不同的分支里被使用,React目前已经对这些情形做了很多细化了)。ReactMultiChild包含着diff算法的核心部分,接下来会慢慢进行梳理。到这里我们暂时不必再继续往下看,可以注意prevChildren和nextChildren这两个变量,当然removedNodes、mountImages也是意义比较明显且很重要的变量:
prevChildren和nextChildren都是ReactElement,也就是virtual DOM,从它们的$$typeof: Symbol(react.element)就可看出;removedNodes保存删除的节点,mountImages则是保存对真实DOM的映射,或者可以理解为要挂载的真实节点,这些变量会随着调用栈一层层往下作为参数传下去并被修改和包装。 而控制树的深度的方法就是靠传入nextNestedChildrenElements,把整个树的索引一层层递归的传下去,同时传入prevChildren这个虚拟DOM,进入_reconcilerUpdateChildren方法,会在里面通过flattenChildren方法(当然里面还有个traverse方法)来访问我们的子树指针nextNestedChildrenElements,得到与prevChildren同层的nextChildren。然后ReactChildReconciler.updateChildren就会将prevChildren、nextChildren封装成ReactDOMComponent类型,并进行后续比较和操作。 至此,同层比较叙述结束,后面会继续讨论针对组件的diff和对元素本身的diff。 组件间的比较参考官方文档及其他资料,可以讲组件间的比较策略总结如下:
这里可以看出React再次抓了主要矛盾,对于不同组件但结构相似的情形不再去关注,而是对相同组件、相似结构的情形进行diff算法,并提供钩子来进一步优化。可以说,对于页面结构基本没有变化的情况,确实是有着很大的优势。 元素间的比较这一节算是diff算法最核心的部分,我会尝试着对算法的思想进行分析,并结合自己的demo来增进理解。 例子很简单,是一个涉及到新集合中有新加入的节点且老集合存在需要删除的节点的情形。如下图所示。
也就是说,通过点击来控制文字和数字的显示与消失。这种JSX可以说是太常用了。正好借学习diff算法的机会,来看看就这种最基本的结构,React是怎么做的。 首先先在ReactMultiChild中的_updateChildren中打上第一个debugger。
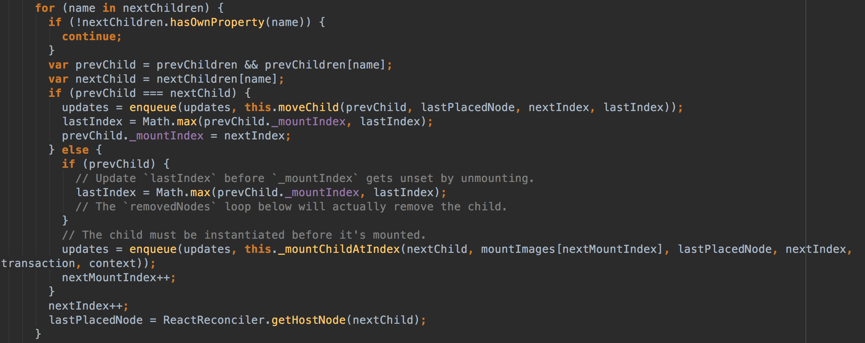
断点之前的代码会得到prevChildren和nextChildren,他们经过处理会从ReactElement数组变成一个奇怪的对象,key为“.0”、“.1”这样的带点序号(这里不妨先多说一句,这是React为一个个组件们默认分配的key,如果这里我强行设置一个key给h2h3标签,那么它就会拥有如’$123’这样的key),值为ReactDOMComponent 组件,前面写初次渲染的文章中提到过ReactDOMComponent就是最终渲染到DOM之前的那一环。而在本demo中,prevChildren存放着“哈哈哈的h1标签”和“142567的h3标签”,而nextChildren存放着“哈哈哈的h1标签”和“你好啊的h2标签”。 先不看若干index变量,看到for循环的in写法,即可明白是在遍历存放了新的ReactDOMComponent的对象,并且通过hasOwnProperty来过滤掉原型上的属性和方法。接着各自拿到同层节点的第一个,并对二者进行比较。如果相同,则enqueue一个moveChild方法返回的type为MOVE_EXISTING的对象到updates里,即把更新放入一个队列,moveChild也就是移动已有节点,但是是否真的移动会根据整体diff算法的结果来决定(本例当然是没移动了),然后修改若干index量;否则,就会计算一堆index(这里其实是算法的核心,此处先不细说),然后再次enqueue一个update,事实上是一个type属性为INSERT_MARKUP的对象。对于本例而言,h1标签不变,则会先来一个MOVE_EXISTING对象,然后h3变h2,再来一个INSERT_MARKUP,然后通过ReactReconciler.getHostNode根据nextChild得到真实DOM。
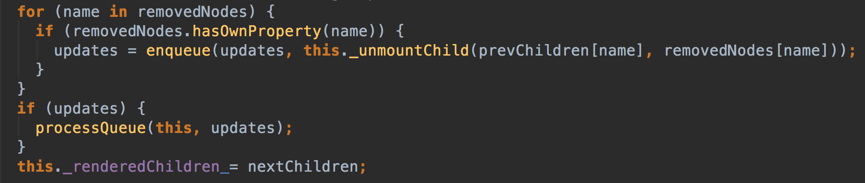
这个for-in结束后,则是会把需要删除的节点用enqueue的方法继续入队unmount操作,这里this._unmountChild返回的是REMOVE_NODE对象,至此,整个更新的diff流程就走完了,而updates保存了全部的更新队列,最终由processQueue来挨个执行更新。 那么细节在哪里?慢慢来。
首先,React为同层节点比较提供了若干操作。早期版本有INSERT_MARKUP、MOVE_EXISTING、REMOVE_NODE这三个增、移、删操作,现在又加入了SET_MARKUP和TEXT_CONTENT这俩操作。 INSERT_MARKUP,新的component类型(nextChildren里的)不在老集合(prevChildren)里,即是全新的节点,需要对新节点执行插入操作; MOVE_EXISTING,在老集合有新component类型,且element是可更新的类型,这种情况下prevChild===nextChild,就需要做移动操作,可以复用以前的DOM节点。 REMOVE_NODE,老component类型在新集合里也有,但对应的element不同则不能直接复用和更新,需要执行删除操作;或者老component不在新集合里的,也需要执行删除操作。 所有的操作都会通过enqueue来入队,把更新细节隐藏,而如何判断做出何种更新操作,则是diff算法之所在。我们回到前面的代码重新再看,并分情况讨论其中的原理。 代码分析
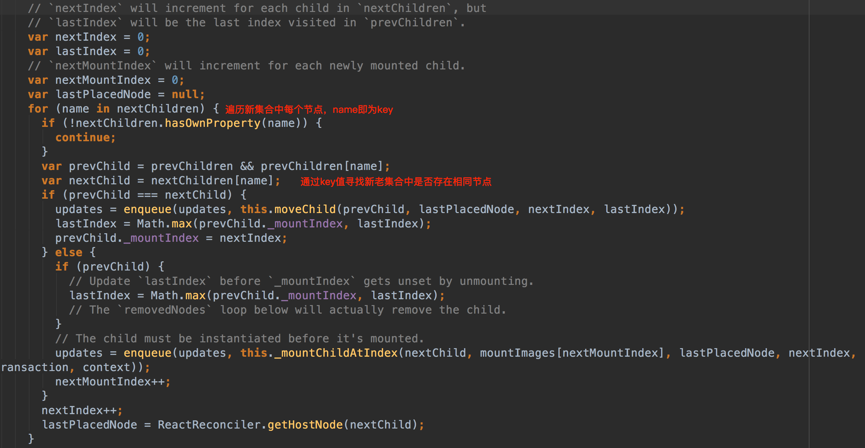
首先对新集合的节点(nextChildren)进行in循环遍历,通过唯一的key(这里是变量name,前面提到过nextChildren和prevChildren是以对象的形式存储ReactDOMComponent的)可以取得新老集合中相同的节点,如果不存在,prevChildren即为undefined。根据图中代码,如果存在相同节点,也即prevChild === nextChild,则进行移动操作,但在移动前需要将当前节点在老集合中的位置与 lastIndex 进行比较,见moveChild函数,如下图:
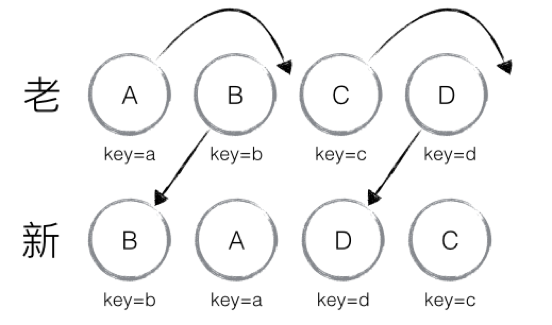
if (child._mountIndex < lastIndex),则进行节点移动操作,否则不执行该操作。这是一种顺序优化手段,lastIndex一直在更新,表示访问过的节点在老集合中最右的位置(即最大的位置),如果新集合中当前访问的节点比lastIndex大,说明当前访问节点在老集合中就比上一个节点位置靠后,则该节点不会影响其他节点的位置,因此不用添加到差异队列中,即不执行移动操作,只有当访问的节点比lastIndex小时,才需要进行移动操作。 新老集合节点相同、只需要移动的情形
图是直接拷来的…画那么好我就不重复画轮子了。还是源码,就按上面的图来讲。 源码中会开始对nextChildren(即新的节点状态 对象形式)进行遍历,并且对象本身是以键值对的形式存储这些节点的状态。首先,key=’b’时,通过prevChildren[name]的方式(name即为key)取老集合节点中是否存在key为b的节点,显然,如果存在,则取得,不存在,则为undefined。然后,判断是否相等。当我们两个key值相同的B节点被判定相等时,enqueue一个’ MOVE_EXISTING’操作。这一操作内部会作如下判断:
child即为prevChild,也就是判断B._mountIndex < lastIndex,lastIndex是prevChildren最近访问的最新index,初始为0(其实因为这些个children都是对象,所以index更多的是计数而非下标)。这里,B._mountIndex=1,lastIndex为0,所以不做移动操作更新。然后更新lastIndex,如下图所示:
我们知道prevChild就是B,则prevChild._mountIndex如前所示为1,所以lastIndex更新为1,这样lastIndex就可以记录着prevChildren中最后访问的那个的序号。再然后,更新B的位置为信集合中的位置:
nextIndex随着nextChildren中遍历的子元素递增,此时为1,也就是说,把B的挂载位置设置为0,就相当于告诉B你的位置从1移动到了0。
最后更新nextIndex,准备为下一个放在位置1的元素准备序号。这里getHostNode方法会返回一个真正的DOM,它主要是给enqueue使用,可以理解为开始执行更新队列时能让React知道这些更新的节点要放到的DOM的位置。 第二轮,从新集合取到A,判断到老集合中存在相同节点,同样是对比位置来判断是否进行移动操作。只不过,这一次A._mountIndex=0,lastIndex在上一轮更新为1,满足child._mountIndex<lastIndex的条件,于是enqueue移动操作。
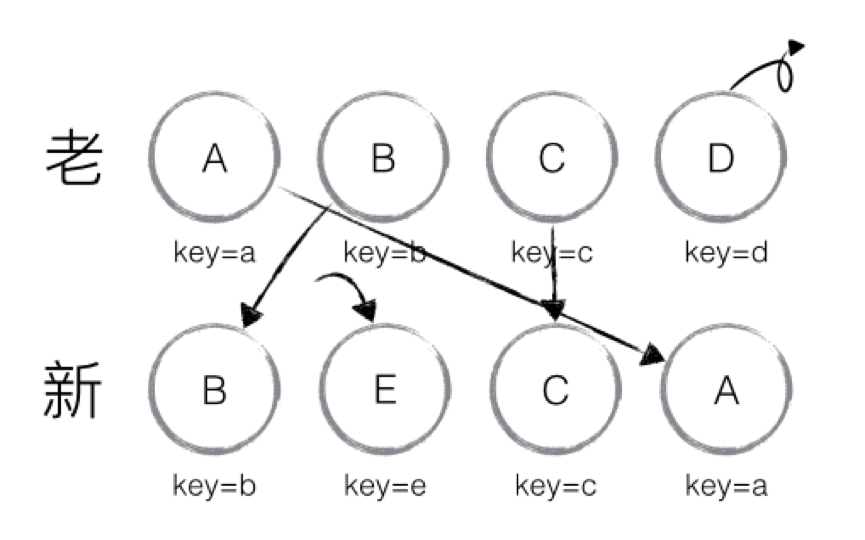
其中toIndex就是nextIndex,目前为1,很正确嘛。然后继续更新lastIndex为1,并更新A._mountIndex=1,然后后续基本一致。 存在需要插入、删除节点的情形
还是拿了大佬的图,哈哈。这里其实就是更完整的情形,也就会涉及到整个代码流程,当然也并不复杂。
讲白了,就是enqueue来创建节点到指定位置,然后更新E的位置,并nextIndex++来进入下一个节点的执行。 第三轮,从新集合取到C,C在老集合中有,但是判断之后并不进行移动操作,继续各种更新然后进入下一个节点的判断。 第四轮,从新集合中取到A,A也存在,所以enqueue移动操作。 至此,diff已经完成,这之后会对removedNodes进行循环遍历,这个对象是在this._reconcilerUpdateChildren就对比新老集合得到的。
这样一来,新集合中不存在的D也就被清除了。整体上看,是先创建,后删除的方式。 Ok,差不多啦,diff算法的核心就是这么回事啦。 总结
补充官方文档 |










不push自己一把真的是不知道何年会看啊
The text was updated successfully, but these errors were encountered: