여러 사이트, 면접 경험, 스스로에게 질문했던 모든 내용을 총 망라합니다.
기본적으로 공유된 정보는 출처를 남기지 않습니다. 특히 개인의 의견이 들어간 블로그 글이 많으므로 신용하지 않습니다. 정보의 우선순위는 아래와 같습니다.
- Document
- 저명한 저자의 강의, 발표
- 위키, 백과사전
- 도서
- 블로그
만약 내용이 너무 같거나, 전반을 참조한다면 하단에 출처를 남깁니다.
프론트엔드 체크리스트를 개략적으로 이해하는지 확인합니다.
- DOCTYPE
- 모든 HTML 페이지의 최상단에 위치하며 사용하는 HTML을 명시하는 것으로 현재는 HTML5를 선언합니다.
- Charset & Viewport
- 둘 모두 head 태그 내부에서도 상단에 위치해야 합니다.
- Charset : 문서에 대한 문자 인코딩(문자 집합)을 나타내며 현재는 UTF-8이 선언되어야 합니다.
- Viewport : 반응형 웹 디자인을 위한 태그입니다.
- Title
- 문서의 Title을 설정합니다.
- Google은 제목에 사용된 글자들의 너비 픽셀을 계산하여 472-482px 사이의 값만을 유효하게 판단합니다. 이 때 글자 길이는 보통 55개 정도입니다.
- Description
- 페이지에 대한 설명으로 150개 이하의 문자로 구성되어야 합니다.
- favicon
- rel="icon"으로 선언하며 페이지의 상단에 추가해야 합니다. 최근에는 ico 포맷보다 png 포맷의 아이콘 사용(32px x 32px)이 권장됩니다.
- Canonical
- 컨텐츠의 중복을 피하기 위하여 link 태그에 rel="canonical" 을 사용합니다.
- lang 속성
- 현재 문서의 언어를 설정(ko, en)합니다.
- dir 속성
- 글자 방향을 설정(rtl, ltr)합니다.
- CSS Critical
- 페이지가 로딩되는 즉시(펼쳐지는 그 순간) 컨텐츠에 영향을 끼치는 CSS를 "critical CSS"라고 하며, 애플리케이션의 CSS가 로딩되기 전에
<style>태그 사이에 최소화 된 상태로 한 줄 추가되어 임베딩됩니다.
- 페이지가 로딩되는 즉시(펼쳐지는 그 순간) 컨텐츠에 영향을 끼치는 CSS를 "critical CSS"라고 하며, 애플리케이션의 CSS가 로딩되기 전에
- CSS 순서
- 모든 CSS 파일은 내에서 자바스크립트 파일보다 이전에 로딩이 완료됩니다.
- Sementic Element
- 의미론적 태그를 사용하여 영역을 나타내는 것입니다.
- 에러 페이지
- 에러 처리를 위한 404페이지, 5xx 페이지를 명시하는 것입니다. 특히 5xx 페이지는 서버 에러이므로 서버에서 전송 받는 데이터 없이 독립적으로 자체 CSS를 포함하고 있어야 합니다.
- Noopener
- tab nabbing 피싱 공격을 방지하기 위해 rel="noopener" 속성을 사용해야 합니다.
HTML testing을 통해 아래의 항목을 점검할 수 있습니다.
- W3C
- 문서의 모든 HTML이 표준에 맞게 작성되었는지 W3C validator를 이용해 테스트합니다.
- HTML Lint
- HTMl 코드 내에 발생할 수 있는 코드 문제를 분석합니다.
- Line checker
- 페이지 내에 깨진 링크나 404 에러가 존재하지 않는지 확인합니다.
현재 웹폰트는 woff, woff2, ttf는 모든 최신 브라우저에서 지원되며, 웹폰트의 용량은 총 2MB를 넘지 않아야 합니다.
- 페이지가 반응형으로 디자인 되었는지 확인해야 하며, 한 페이지 내에 같은 ID가 두 개 이상 존재하는지 점검합니다.
- reset, normalize 등을 사용하여 브라우저 별 상이한 CSS를 초기화시켜야 합니다.
- 정말 필요한 경우가 아니라면 인라인 CSS는 지양되어야 합니다.
- 베더 프리픽스가 브라우저 지원 호환성에 따라 알맞게 생성되었는지 확인합니다.
- CSS 정의는 여러 파일에 분리하여 작성하는 것이 HTTP/2.0에서 성능 상 좋습니다.
- CSS 파일은 모두 압축(최소화)되어야 합니다.
- CSS 파일은 비동기적으로 로드되어야 합니다. DOM을 로딩할 때 방해되면 안되기 떄문이죠.
- 모든 CSS 파일에 에러가 없는지 확인하고, 페이지는 설정한 지점에서 반응형으로 출력되어야 합니다.
- 모든 페이지는 모든 운영체제와 모든 데스크탑, 모바일 브라우저에서 정상적으로 동작해야 합니다.
- 다국어를 지원할 경우 글자 방향에 맞게 모든 페이지가 정상적으로 동작되어야 합니다.
- 모든 이미지가 브라우저에 렌더링 될 수 있는지 확인해야 합니다.
- img 태그에 너비와 높이가 설정되면 안되며, 이미지를 서술하는 대체 텍스트가 존재해야 합니다.
- lazy 로딩에 대해 예외처리가 되어 있어야 합니다.
- 인라인 자바스크립트는 사용하면 안 됩니다.
- 모든 자바스크립트 코드가 하나의 파일에 집중되면 안됩니다.
- 모든 자바스크립트 파일은 압축(최소화)되어야 합니다.
- 자바스크립트를 사용하지 않는다면 noscript 태그를 기입합니다. CSR이 빨라지니까요.
- 자바스크립트 파일은 async, defer 속성들을 이용하여 비동기적인 로드가 필요합니다.
- Linter와 Prettier를 적용하여 코드 포맷을 준수하세요.
- 페이지 내의 모든 외부 컨텐츠는 HTTPS가 적용되어야 합니다.
- HTTP 헤더 값으로 'Strict-Transport-Security'가 설정되었는지 확인합니다. 웹 서버는 302 상태 코드로 클라이언트를 리다이렉트 시킬 수 있는데, 이것이 보안 취약점이 될 수 있습니다. HSTS는 이러한 응답을 받은 웹 페이지에 HTTPS 접속을 강제합니다.
- CSRF(Cross Site Request Forgery), 사이트 간 요청 위조 공격을 방지하기 위해 웹 서버로 발생하는 모든 HTTP 요청이 명확하고 합법적인지 확인합니다.
- XSS(Cross Site Scripting), 사이트 간 스크립팅이 발생할 여지가 있는지 확인합니다.
- X-Content-Type-Options으로 서버에서 설정한 타입과 다른 응답이 올 경우 mime-sniffing을 하지 않도록 합니다.
- X-Frame-Options(XFO), 방문자를 클릭재킹 공격으로부터 보호합니다.
- 페이지는 사용자에게 의미 있는 컨텐츠가 그려지는 첫 순간(First Meaningful Paint)이 1초 이하여야 합니다.
- 3G 네트워크를 사용하거나, 매우 느린 전송 속도를 가진 네트워크 대기 시간 기준으로도 페이지가 활성화되까지의 응답 속도는 최대 5초 이하, 재접속 시 2초 이하여야 합니다.
- 핵심 파일들은 GZIP 압축 시 170kb 이하여야 합니다.
- HTML이 압축(최소화)되어 있습니다.
- 이미지, 스크립트, CSS 파일들이 Lazy 로딩되어 페이지의 응답시간을 향상시킵니다.
- 쿠키를 사용한다면 각 쿠키의 크기는 4096바이트, 개수는 20개 이상을 가지면 안 됩니다.
- 서드파티 iframe이나 컴포넌트의 경우 정적으로 교체하여 외부 API 호출을 제한하며 사용자의 활동을 외부로 유출하면 안 됩니다.
DNS resolution, Preconnect, Prefetching, Preloading이 있지만 이를 사용해보지는 못했습니다.
- Progressive enhancement
- 메인 네비게이션, 검색 등이 자바스크립트 없이 동작해야 합니다.
- 색상 대비 기준은 WCAG AA를 통과(모바일은 AAA)해야 합니다.
- 모든 페이지 내에 웹 페이지 타이틀과 다른 H1 태그가 존재해야 합니다.
- 헤딩은 올바른 순서(H1 ~ H6)까지 적절히 사용되어야 합니다.
- 시멘틱한 태그를 사용하여 개별적인 키패드나 위젯을 보여주는 모바일 장치들에 효율적으로 접근할 수 있습니다.
- 폼(form)에서 레이블(label)은 다른 입력 폼 요소와 관계되며 레이블이 보여지지 않는다면 aria-label을 사용합니다.
- 키보드만을 이용하여 웹 페이지를 예측 가능하도록 움직일 수 있는지 확인합니다.
- 포커스가 되지 않는다면 눈에 보이는 상태의 CSS로 대체되어야 합니다.
Google Analytics를 설치하고, 제목을 적절하게 배치합니다. sitemap.xml이 Google Search Console에 제출되었고, robots.txt 파일이 웹 페이지를 블로킹하지 않아야 합니다.
웹 페이지가 정형화 된 구조를 가지고 있다면 웹 크롤러가 페이지 내 컨텐츠를 이해하는데 도움을 줍니다.
SPA(Single Page Application)는 서버에 처음에만 페이지를 요청하고, 이후에는 동적으로 페이지를 구성하는 웹 애플리케이션을 뜻합니다.
페이지가 한번 로딩된 이후 데이터를 수정하거나 조회할 때, 페이지가 새로 고침되지 않고 다른 페이지로 넘어가지 않습니다.
다른 방식으로는 MPA(Multi Page Application)가 있는데, 이는 서버로부터 완전한 페이지를 받아오고 이후에 데이터를 수정하거나 조회할 때, 다른 완전한 페이지로 이동(URL이 변경될 수 있는)하는 형태입니다.
데이터가 없는 껍데기 HTML(그 외 정적인 파일들)만 우선 응답 받고, 데이터는 여러 정적 파일이 로드된 이후 다시 요청해서 응답 받는 방식입니다.
CSR은 SSR보다 초기 전송되는 페이지의 속도는 빠르지만 서비스에서 필요한 데이터를 클라이언트(브라우저)에서 추가로 요청하여 재구성해야 하기 때문에 전제적인 페이지 완료 시점은 SSR보다 느려집니다.
데이터까지 전부 삽입된 완성형 HTML을 응답 받습니다.
서버에서 사용자에게 보여줄 페이지를 모두 구성하여 사용자에게 페이지를 보여주는 방식이다. JSP/Servlet의 아키텍처에서 이 방식을 사용했는데, SSR을 사용하면 모든 데이터가 매핑된 서비스 페이지를 클라이언트(브라우저)에게 바로 보여줄 수 있습니다.
서버를 이용해서 페이지를 구성하기 때문에 클라이언트에서 구성하는 CSR(client-side rendering)보다 페이지를 구성하는 속도는 늦어지지만 전체적으로 사용자에게 보여주는 콘텐츠 구성이 완료되는 시점은 빨라진다는 장점이 있으며 SEO(search engine optimization) 또한 쉬워집니다.
CSR은 기본적으로 페이지 로드 이후 동적으로 콘텐츠를 생성하기 때문에 콘텐츠를 빠르게 소비하는 사용자의 요구 사항을 충족시킬 수가 없었습니다. 네트워크 상황이 좋지 않다면 CSR을 이용할 경우 사용자들은 글을 보기 전에 상당 시간 하얀 화면을 봐야 할 수도 있죠.
대부분 SSR을 채택하는 이유는 급변하는 프론트엔드 생태계에 대응하고, CSR의 한계를 극복하기 위해서입니다. 일반적으로 클라이언트에서 작성한 코드의 일부는 서버에서도 동일한 로직으로 구성되는 경우가 많으므로 개발의 난이도는 있지만 생산성 측면에서는 SSR을 구축하는 것이 장기적인 관점에서 더욱 효율적이게 돼죠.
또한 SSR을 사용하면 프론트엔드와 백엔드를 완전히 분리함으로써 생산성을 높일 수 있습니다. 해당 영역은 REST API를 통해 느슨하게 연결할 수 있죠.
기존 CSR 페이지는 프론트엔드에서 개발하고 SSR 페이지는 백엔드에서 개발을 했다면, SSR 환경을 구축하면 페이지의 소유권이 온전히 프론트엔드에 존재하므로 페이지가 변경될 때마다 불필요한 커뮤니케이션을 할 필요가 없어집니다.
다만, 인프라를 구축하고 운영하는 것이 부담스러운 부분이지만 요즘은 가상화를 통한 구성이 너무 잘 되어 있어서 조그만한 투자로 많은 이점을 얻을 수 있습니다.
더불어 백엔드에서도 API 개발과 데이터 활용에 더 집중할 수 있어서 서비스 품질을 높이는 데 기여할 수 있다는 장점이 있어요.
마지막으로 SSR 아키텍처를 구성하면 다른 여러 가지 대안을 활용할 수 있는 토대가 되므로 필요에 따라 CSR로만 구성할 수도, CSR과 prependering을 함께 사용하도록 개발할 수도 있습니다.
객체 지향 프로그래밍(Object Oriented Programming)은 여러 특징을 이용해 코드 재사용을 증가시키고, 유지보수를 감소시키는 장점을 얻기 위해서 객체들을 연결해 프로그래밍 하는 기법입니다.
- 캡슐화 : 객체의 내용 중 숨기고 싶은 부분을 외부에서 접근할 수 없게 감출 수 있습니다. 이는 정보의 은닉과 보호가 가능합니다.
- 추상화 : 객체들의 공통된 특징을 파악해 정의해 놓은 설계 기법입니다.
- 다형성 : 코드의 재사용성이 증가되고 폭 넓은 코드 구현이 가능하며, 개발속도를 향상시킬 수 있습니다.
- 상속 : Class의 멤버(데이터)와 함수를 다른 Class에 물려주거나 물려받을 수 있는 기능으로 다형성을 확보할 수 있습니다.
함수형 프로그래밍(Function Programming)은 순수 함수와 보조 함수의 조합을 통해 로직내에 존재하는 조건문과 반복문을 제거하여 복잡성을 해결하고 변수의 사용을 억제하여 상태 변경을 피하려는 프로그래밍 패러다임입니다.
순수 함수는 같은 입력이 주어지면, 같은 출력을 반환해야 합니다. 즉, 부가 효과(Side Effect)가 존재하면 안 됩니다. 부가 효과가 발생하면 순수 함수로서의 기능을 하지 못해 예측 불가능한 오류를 일으킬 수 있습니다.
객체 지향 프로그래밍은 클래스와 객체의 관계가 중심으로 구성되므로 상태, 멤버 변수, 메서드 등이 긴밀하게 의존합니다. 이는 멤버 변수가 가진 상태에 따라 결과가 변한다는 것이죠.
함수형 프로그래밍은 순수 함수와 보조 함수의 조합으로 상태를 제어하는 복잡성을 최소화하고 변수의 사용을 억제하여 상태 변경을 피해 최적화된 동작을 만들어 낼 수 있습니다.
REST API(RESTful API)란 REST 아키텍처의 제약 조건을 준수하는 애플리케이션 프로그래밍 인터페이스를 뜻합니다. REST는 Representational State Transfer의 줄임말입니다.
REST는 프로토콜이나 표준이 아닌 아키텍처 원칙 세트로, 개발자는 REST를 다양한 방식으로 구현할 수 있습니다.
RESTful API를 통해 요청이 수행될 때 RESTful API는 리소스 상태에 대한 표현을 요청자에게 전송합니다. 이 정보 또는 표현은 HTTP: JSON(Javascript Object Notation), HTML, XLT, XML 또는 일반 텍스트를 통해 몇 가지 형식으로 전송됩니다. JSON은 사용 언어와 상관이 없을 뿐 아니라 인간과 머신이 모두 읽을 수 있기 때문에 가장 널리 사용됩니다.
객체의 상태 변화를 감지해서 해당 객체를 사용하는 다른 객체의 상태를 변경하거나, 관련된 뷰(View)를 자동으로 갱신해주는 시스템입니다. 즉, 모든 상태 변경에 대해 이벤트를 발생시키고, 변경을 감지하기 위해서 해당 이벤트에 대한 리스너를 등록하던 일을 자동으로 해 주는 것이죠.
예를 들어 영상을 찍는 스트리머와 이를 송출하는 플랫폼이 있다고 가정해봅시다. 스트리머는 일정하게 영상에 대한 프레임을 송출(emit)하고, 플랫폼은 스트리머을 관찰하고 있다가 새로운 영상을 송출하면 이를 획득하는 방식입니다.
흔히들 구독/알림(Publish/Subscribe) 관계라고 하는데 여기서 스트리머의 역할이 옵저버블(observable), 플랫폼이 옵저버(Observer), 영상 프레임이 Notification이 됩니다.
- 사용자 인터페이스(UI)
- 보안(Security)
- 성능(Performance)
- 검색 엔진 최적화(SEO)
- 유지보수성(Maintainability)
기획, 디자인, 퍼블리싱, 프로그램 개발, 테스트/검수, 홍보 및 마케팅이 있습니다.
- 기획 : 만들려는 웹의 목적, 주요 타깃을 결정하고 정리된 컨텐츠(Contents)를 기본으로 전체 디자인 컨셉(Concept)을 잡는 단계입니다.
- 디자인 : 기획에서 정한 컨셉에 맞게 시각적 요소를 활용하여 사용성을 높일 수 있는 디자인 작업을 진행하는 단계입니다.
- 퍼블리싱 : HTML, CSS, 자바스크립트를 통해 여러 화면의 움직임을 구현하고 웹 표준에 맞는 반응형(또는 적응형) 작업을 진행합니다.
- 프로그램 개발 : 화면이 내포하는 실제 기능을 구현하는 단계입니다. 다양한 클라이언트 요청에 개발이 이루어집니다.
- 테스트/검수 : 기획 의도에 맞게 디자인과 프로그램 개발 작업을 테스트하고 발생하느 오류를 수정합니다.
- 홍보 및 마케팅 : 완성된 웹에 사용자/방문자를 늘리기 위해 적극 홍보합니다.
많은 테스트를 통해 말그대로 기능을 점진적으로 향상시킵니다. 기능이 제한된 브라우저의 애플리케이션을 개발할 때 주로 사용합니다.
기본 수준의 사용자 환경에 대한 응용 프로그램을 구축하지만 브라우저가 이를 지원할 경우 기능을 강화하는 방법입니다. 기초부터 천천히 발전하므로 노력과 시간이 필요하죠. 예를 들어 아래처럼 웹 페이지 구성을 간략화하면 어떨까요?
- HTML 마크업 작성
- CSS 스타일링
- 자바스크립트 기능 개발
신기술을 최신 기기에 적용하여 기능을 구현하고, 오래 된 기기에서 동작하도록 기술 버전을 점차 낮추어 유사한 기능을 구현하는 것입니다.
최신 브라우저를 위한 어플리케이션을 구축하는 동시에 구형 브라우저에서도 계속 동작하도록 하는 개발 방법입니다. 전체가 동일한 애플리케이션을 사용하는 것이 아닌 기기별로 애플리케이션 버전을 다르게 개발하는 것이죠. 예를 들어 최신 모던 브라우저에서는 동작하는 Fetch API의 경우 IE에서는 동작하지 않으니 XhrHTTPRequest를 사용하는 것과 같습니다.
표준에 의해 공통적인 기준과 상호 운용성이 명확해져 혁신이 빨라집니다.
좁은 의미에서의 표준은 협업을 원활하게 해주며, 개발에 따른 비용과 유지보수 용이성을 제공합니다. 그러나 넓은 의미로 해석하면 아래와 같습니다.
- 상호 운용성을 제공합니다.
- 호환성(compatibility), 상호 운용성(Interoperability)의 제공으로 같은 기종 또는 다른 기종 간에 정보교환 및 처리를 가능하게 해줍니다.
- 비용을 절감시켜 줍니다.
- 제조업체, 벤더 등 사업자는 단위 생산·거래 비용을 줄일 수 있으며, 대량생산을 통해 규모의 경제(economy of scale)를 실현하는 것이 가능합니다. 또한 기술의 중복투자 방지, 기술이전 촉진 등 연구·개발 비용을 절감할 수 있습니다.
- 무역 활성화를 통한 시장 진출 도구로 활용할 수 있습니다.
- 국가 간 무역은 국제표준을 따르므로 기술 무역장벽 제거 및 국제 교역 활성화가 촉진됩니다.
- 또한 소비자 및 시장의 요구가 반영되어 있기에 표준을 사용한 제품 및 서비스의 시장 진출 시 성공 가능성을 높일 수 있습니다.
- 사용자에 대한 자유도(선택의 자유)를 높일 수 있습니다.
- 통일된 형태의 결과물을 통해 제품의 이동을 편리하게 하고, 우수 경쟁체제를 통해 보다 나은 제품 및 서비스를 획득하는 것이 가능합니다.
모노레포(Monorepo)는 두 개 이상의 프로젝트 코드를 하나의 저장소에서 관리하는 기법입니다.
- 코드의 재사용
- 여러 저장소에서 프로젝트를 진행하면 비슷한 로직을 각 저장소에서 중복 구현하는 때가 많은데, 이를 공유하려면 저장소와 의존성을 추가해야 합니다. 모노레포를 적용하는 경우 하나의 저장소에서 하나의 키워드만으로 모든 프로젝트가 같은 공통 코드를 사용할 수 있습니다.
- 의존성 관리
- 멀티레포 구조에서는 각 저장소에 Linter를 따로 설치했지만 모노레포를 적용하면 그럴 필요가 없습니다.
- 작은 커밋과 PR
- 모노레포에서는 여러 패키지의 변경사항을 하나의 커밋과 PR로 제출할 수 있어 작업을 작게 쪼갤 수 있습니다. 물론 하나의 커밋에는 한 패키지의 변경사항만 기록하는 SRP(Single Responsibility Principle, 단일 책임 원칙)를 지켜야하죠.
- 대규모 리팩토링
- 모노레포로 저장소를 운영해보니 하나의 파일에 대한 컨트리뷰터가 상당히 많아지므로 해당 로직을 이해하는 여러 사람이 효율적으로 작성하는 방식에 대해서도 함께 생각할 수 있으므로 대규모 리팩토링을 유도할 수 있습니다.
- 팀 간 협업
- 모든 구성원이 모든 코드에 접근할 수 있기 때문에 팀 간 협업이 자유롭습니다.
- 트렁크 기반 개발(Trunk Based Development)
- 모노레포에서는 서버와 웹을 합쳐 하나의 버전으로 판단할 수 있으므로 Master 브랜치를 항상 배포할 수 있도록 유지하는 트렁크 기반 개발에 도움이 됩니다.
FOUC(Flash Of Unstyled Content)는 외부의 CSS가 불러오기 전에 잠시 스타일이 적용되지 않은 웹 페이지가 나타나는 현상입니다.
해당 웹 문서의 사용자 경험성을 떨어뜨리게 돼죠. IE 브라우저에 유독 자주 나타나지만 다른 브라우저도 발생할 수 있습니다.
이는 브라우저의 렌더링 방식과 연관이 있는데, 브라우저는 요청한 리소스를 응답받고 이를 파싱하여 DOM 트리를 생성합니다. 그 뒤 순서에 마크업의 순서에 따라 스타일을 적용하죠. 이때 렌더 트리가 노출된 후에 CSS나 자바스크립트로 렌더 트리가 변경되면 이 수정된 렌더 트리가 화면에 노출 될 수 있는데, 이 것이 바로 FOUC입니다.
특히 요즘은 여러 CSS 파일을 사용(IE의 경우 @import 명령어를 사용하면 화면에 노출된 상태로 스타일이 적용)하고, 웹 폰트(IE는 다른 브라우저와 다르게 기본 폰트를 불러온 뒤 다시 웹 폰트로 변경)를 적극 기용하는데 이는 DOM 구조를 변경하므로 자주 발생하게 되는 현상입니다.
<script> 태그를 <head> 태그에 위치시켜 자바스크립트로 인한 FOUC를 방지할 수 있지만, CSS는 효과가 없습니다.
가장 널리 사용하는 방식은 로드와 렌더링이 모두 완료되었을 때 사용자에게 보여주는 것입니다. 화면을 숨기거나, 프로그레스바를 보여준다거나, 프레임워크를 사용하는 방법 등이죠.
HTML5부터 제공하는 기능으로, 해당 도메인과 관련된 특정 데이터를 서버가 아니라 클라이언트 브라우저에 저장할 수 있습니다.
Web Storage의 개념은 키/값 쌍으로 데이터를 저장하고, 키를 기반으로 데이터를 조회할 수 있으며 영구저장소(LocalStorage)와 임시저장소(SessionStorage)를 분리해 데이터의 지속성을 구분할 수 있습니다.
또한 쿠키와 마찬가지로 사이트의 도메인 단위로 접근이 제한됩니다. A 도메인에서 저장한 데이터는 B 도메인에서 조회할 수 없는 것이죠.
시맨틱(Semantic)은
의미론적인이라는 의미를, 마크업(Markup)은 HTML 태그로 문서를 작성하는 것을 말하므로 시맨틱 마크업이란 의미를 잘 전달하도록 문서를 작성하는 것을 말합니다.
시맨틱 마크업은 태그를 용도에 맞게 사용하는 것입니다. 컨텐츠나 분류별로 그 뜻을 명확하게 하기 위함이죠. <header>, <footer>, <main>, <section> 등을 사용할 수 있습니다.
<b>라는 태그와 <strong>는 그 기능이 동일하지만 직관적으로 다가오는 것은 강조의 의미를 내포하는 <strong> 태그가 시멘틱 태그에 적합하죠.
검색 엔진이 이러한 시멘틱 태그를 중요하게 판단하므로 검색 엔진 최적화가 대두됨에 따라 시멘틱 태그를 사용하는 것이 권장되고 있습니다. 물론 다른 이유로는 웹 접근성 측면과 유지보수/가독성의 향상이 있습니다.
검색 엔진 최적화(영어: search engine optimization, SEO)는 검색 엔진으로부터 웹사이트나 웹페이지에 대한 웹사이트 트래픽의 품질과 양을 개선하는 과정입니다.
웹 페이지 검색엔진이 자료를 수집하고 순위를 매기는 방식에 맞게 웹 페이지를 구성해서 검색 결과의 상위에 나올 수 있게 합니다. 웹 페이지와 관련된 검색어로 검색한 검색 결과 상위에 나오게 된다면 방문 트래픽이 늘어나기 때문에 효과적인 인터넷 마케팅 방법 중의 하나이며 비용처리 없는 마케팅이라고 할 수 있습니다.
2019년도 이후로 한국 내 구글의 점유율이 30%를 넘어서고 있고, 네이버의 점유율이 점점 하락 하고 있으며, 구글은 네이버와같은 블로그 우선노출과 같은 정책이 없고 구글 애즈를 제외한 다른 검색결과에 한해서는 검색엔진 최적화 여부에 따라 웹사이트를 랭킹 시키고 있기 때문에 검색엔진 최적화(SEO)의 중요성이 점점 부각되고 있는 실정입니다.
블랙햇(Black Hat) SEO란 특정 웹사이트를 구글 상위 노출을 시키기 위해, 구글 검색엔진 서비스 이용 약관(Terms of Service)에 위배 되는 SEO(검색엔진최적화) 전략을 사용하는 것을 의미하며 화이트햇 SEO는 정상적이고 도덕적인 방법으로 구글 가이드라인 범위안에서 검색 엔진 최적화를 진행하는것을 의미합니다.
브라우저는 HTML, CSS, 자바스크립트로 작성된 텍스트 문서를 파싱(Parsing)하여 렌더링(Rendering)합니다.
- 브라우저는 HTML, CSS, 자바스크립트, 이미지, 폰트 파일 등 렌더링에 필요한 리소스를 요청하고 서버로부터 응답을 받습니다.
- 브라우저의 렌더링 엔진은 서버로부터 응답된 HTML과 CSS를 파싱하여 DOM과 CSSOM을 생성하고 이들을 결합하여 렌더 트리를 생성합니다.
- 브라우저의 자바스크립트 엔진은 서버로부터 응답된 자바스크립트를 파싱하여 AST(Abstract Syntax Tree)를 생성하고 바이트코드로 변환하여 실행합니다. 이때 자바스크립트는 DOM API를 통해 DOM이나 CSSOM을 변경할 수 있습니다. 변경된 DOM과 CSSOM은 다시 렌더 트리로 결합됩니다.
- 렌더 트리를 기반으로 HTML 요소의 레이아웃(위치와 크기)을 계산하고 브라우저 화면에 HTML 요소를 페인팅합니다.
- 브라우저 주소창에 www.kakaopay.com을 검색합니다.
- URL의 호스트 이름이 DNS를 통해 IP 주소로 변환되고, IP 주소를 갖는 서버에게 요청을 전송합니다. 루트 요청이 카카오페이 서버로 전송되면 서버는 대부분 암묵적으로 index.html을 응답하도록 되어 있습니다.
- 서버는 루트 요청에 대해 정적파일 index.html을 클라이언트로 응답하고, 브라우저는 응답 받은 index.html을 파싱합니다.
- 브라우저의 렌더링 엔진이 HTML을 파싱하는 도중 외부 리소스를 로드하는 태그인 link, img, script 태그 등을 만나면 HTML 파싱을 일시 중지하고 해당 리소스 파일을 서버로 요청합니다.
- DOM트리를 만들어나갑니다.
- 중간에 link태그를 만나 css요청이 발생하면, 요청과 응답과정을 거치고 css를 파싱합니다.
- CSS파싱이 끝나면 중단된 html을 다시읽고 DOM트리를 완성합니다.
- 완성된 DOM트리와 CSSOM트리를 합쳐 Render Tree를 만들고 그립니다.
- 중간에 HTML파서는 Script태그를 만나게 되면 javascript 코드를 실행하기 위해 파싱을 중단합니다.
- 제어권한을 자바스크립트 엔진에게 넘기고, 자바스크립트 코드 또는 파일을 로드해서 파싱하고 실행합니다.
웹에서 쓰이는 통신 규약입니다. 저희는 서버/브라우저와 통신할 때 URI를 사용하는데, 이 때 URI는 각 프로토콜 정보를 내포하고 있습니다. 기본적으로 저희가 사용하는 프로토콜에는 HTTP, HTTPS, FTP, SMTP 등이 있습니다.
HTTP(Hyper text Transfer Protocol)는 브라우저가 웹 서버와 통신하기 위해 사용하는 주요 프로토콜입니다.
WWW 에서 하이퍼텍스트(hypertext) 문서를 교환하기 위하여 사용되는 통신 규약으로, 초기에 사용했던 HTTP 프로토콜은 매우 단순하였습니다. 이를 HTTP/0.9 버전이자 단일 프로토콜(One-line)이라고 하며, 많은 개선을 거쳐 현재의 표준화 된 HTTP/1.1, 더 나아가 HTTP/2.0이 등장하게 됩니다.
HTTP는 인터넷상에서 데이터를 주고 받기 위한 클라이언트/서버 모델을 따르는 전송 프로토콜이자 애플리케이션 레벨의 프로토콜로 TCP/IP위에서 작동합니다. 이는 아래와 같은 문제가 있었습니다.
- 암호화가 되지 않은 평문 데이터를 전송하는 프로토콜로서, 제 3자가 중요한 정보를 조회할 수 있는 문제가 있었습니다.
- 통신 상대를 확인하지 않으므로 위장이 가능했으며, 완전성을 증명할 수 없어 변조까지 가능했습니다.
HTTP 통신 소켓을 SSL(Secure Socket Layer)/TLS(Transport Layer Security) 프로토콜로 대체하며 보안성이 강화되었습니다.
- HTTP는 제 3자가 중요한 정보를 조회하거나 수정할 수 있었으나 암호화가 적용된 HTTPS는 불가능합니다.
- 기본적으로 HTTP가 HTTPS보다 빠르지만 HTTP/2.0에서는 HTTPS가 빠르다고 합니다.
- session resumption이라는 기능 때문이랍니다.
- 평문 통신에 비해 암호화 통신은 CPU나 메모리가 많이 필요하여 민감한 정보를 다룰 때에만 사용하므로 민감한 정보를 자루지 않는다면 HTTP를 사용합니다.
HTTP/2.0은 HTTP/1.1의 가장 큰 문제점, 회전 지연(Latency)를 해결하기 위해 제안되었습니다.
HTTP/1.1의 요청-응답 메세지 포맷은 구현의 단순성, 접근성을 중점으로 최적화 되었습니다. 하나의 요청에 하나의 응답만을 받는(1:1) HTTP 메세지 교환 방식은 응답을 받아야만 다음 요청을 보낼 수 있으므로 심각한 회전 지연이 발생했습니다. 병렬 커넥션, 파이프라인 커넥션 등이 도입 되었지만 이를 완전히 해결하진 못했죠.
HTTP/2.0은 기존의 요청-응답과는 약간 다른 서버 푸시(Server Push)를 도입하여 요청을 명시적으로 받지 않아도 능동적으로 클라이언트에 리소스를 전송할 수 있게 되었습니다.
그 차이점은 아래와 같습니다.
- HTTP/2.0의 모든 메세지는 프레임에 담겨 전송됩니다.
- 스트림(Stream)과 멀티 플렉싱(Multi-flexing)을 지원합니다.
- 하나의 커넥션에 여러 스트림이 동시에 열리거나 우선순위를 가질 수 있습니다.
- 헤더를 압축하여 보내므로 중복된 내용을 효과적으로 처리할 수 있습니다.
- 서버 푸시가 도입되어 클라이언트가 능동적으로 리소스를 푸시합니다.
- 효율적인 페이지 로딩을 위해 URL 이미지, 스크립트 등의 리소스를 압축하여 요청을 감소시킵니다.
- 무제한 파일 업로드 : 악성 파일을 서버에 업로드 한 후 실행하여 시스템을 공격하는 공격입니다.
- 공격에는 과부하 된 파일 시스템 또는 데이터베이스, 시스템 해킹, 클라이언트 공격 등이 포함될 수 있습니다.
- 클릭 재킹 : 사용자가 사이트에 속하지 않는 웹 페이지 또는 요소를 클릭하는 속임수를 사용하는 공격입니다.
- 클릭 재킹은 사용자가 무의식적으로 자격 증명 또는 민감한 정보를 제공하거나, 바이러스를 다운로드하거나, 악성 웹 페이지를 방문하거나, 온라인으로 제품을 구매하거나, 돈을 이체하도록 만들 수 있습니다.
- XSS 공격 : 웹 페이지에 브라우저 측 스크립트 형태로 악성 스크립트를 삽입 하는 공격입니다.
- 사이트의 결함으로 인해 XSS 공격이 성공하면 사이트를 사용하는 클라이언트에게 피해가 퍼질 수 있습니다.
- SQL 주입 : 입력 필드를 통해 SQL 문에 악성 코드를 주입하여 데이터베이스를 파괴하는 공격입니다.
- 서비스 거부 공격(DoS 공격) : 트래픽으로 서버를 폭격하여 사용자가 서버 또는 해당 리소스를 사용할 수 없게 만드는 공격입니다.
- 중간자 공격(세션 하이재킹) : 클라이언트와 서버 간의 통신을 가로 채서 암호, 계정 번호 또는 개인 정보를 훔치는 공격입니다.
- 공격자는 항상 서버에 도달하여 작업을 수행하기 위해 프런트 엔드에서 허점을 찾습니다.
- 엄격한 사용자 입력 : 사용자 입력은 SQL 주입, 클릭 재킹 등과 같은 취약성을 피하기 위해 본질적으로 항상 엄격해야합니다.
- 사용자 입력을 서버로 보내기 전에 유효성을 검사하거나 삭제하는 것이 중요합니다.
- 데이터 삭제는 화이트리스트를 사용하고 입력 데이터를 이스케이프하는 것과 같이 상황에 맞는 위험한 문자를 제거하거나 대체하여 수행 할 수 있습니다.
- 숨겨진 필드 또는 브라우저 메모리에 저장된 데이터의 주의 :
type="hidden"또는 브라우저 저장소의 localStorage, sessionStorage, cookies를 다시 한 번 살펴야 합니다.- 브라우저에 추가 된 모든 것은 공격자가 쉽게 액세스 할 수 있습니다. 공격자는 개발 도구를 열고 모든 메모리 내 변수를 변경할 수 있습니다.
- 따라서
type="hidden"또는 브라우저 내 메모리 저장소에 키, 인증 토큰 등을 직접 저장하지거나 남용하면 안됩니다.
- 강력한 콘텐츠 보안 정책(CSP) 사용 : 신뢰할 수있는 특정 콘텐츠 만 브라우저에서 실행하거나 더 많은 리소스를 렌더링 할 수 있도록 항상 강력한 Content-Security-Policy HTTP 헤더를 정의하십시오.
- 서버가 보내는 모든 것을 신뢰하지 마세요. 허용 된 소스 목록 인 화이트리스트를 만드는 것이 좋습니다. 이제 공격자가 스크립트를 삽입하더라도 스크립트는 화이트리스트와 일치하지 않으면 실행되지 않습니다.
- 아래와 같은 옵션을 줄 수 있습니다.
Content-Security-Policy: default-src 'none'; script-src 'self'; img-src 'self'; style-src 'self'; connect-src 'self';- document를 로드 할때 css, script, image같은 리소스들은 HTML 문서가 제공되는 곳과 불러오는 곳이 동일해야 한다는 것입니다. Defualt CSP 지침은 default-src로 설정하면 되며 기본 동작이 URL에 대한 연결을 제한해야 하기 때문에 none으로 설정합니다.
- 그러나 CSP는 인라인 스크립트 실행 문제를 해결하지 못하므로 XSS 공격을 막을 순 없습니다.
- XSS 보호 모드 활성화
- 공격자가 사용자 입력에서 악성 코드를 삽입하는 경우
"X-XSS-Protection": "1; mode=block"헤더를 적용하여 응답을 차단하도록 브라우저에 지시 할 수 있습니다. - 대부분의 최신 브라우저에는 기본적으로 XSS 보호 모드가 활성화되어 있지만 X-XSS-Protection헤더를 포함하는 것이 좋습니다. 이는 CSP 헤더를 지원하지 않는 이전 브라우저의 보안을 강화하는 데 도움이 됩니다.
- 공격자가 사용자 입력에서 악성 코드를 삽입하는 경우
- 일반적인 XSS 실수 방지 : XSS 공격은 일반적으로 DOM API로 추적됩니다.
- innerHTML.예를 들면 다음과 같습니다.
document.querySelector('.tagline').innerHTML = nameFromQueryString
- innerHTML을 사용자 입력을 기반으로 값을 설정하지 말고 textContent를 대신 사용하세요.
- 또한 HTTP 응답 헤더 Content-Type과 X-Content-Type-Options도 적절하게 설정하세요. 예를 들어 JSON 데이터는 실수로 실행되는 것을 방지하기 위해 text/HTML로 인코딩해서는 안됩니다.
- innerHTML.예를 들면 다음과 같습니다.
- iframe 삽입 사용 중지
"X-Frame-Options": "DENY"헤더를 적용하면 iframe으로부터 클릭 재킹 공격을 방지할 수 있습니다.- 또한
frame-ancestors CSP지시문을 사용하여 iframe에 페이지를 포함 할 수있는 상위 항목을 더 많이 제어 할 수 있습니다.
- 일반적인 오류 유지
"암호가 올바르지 않습니다."와 같은 오류는 사용자뿐만 아니라 공격자에게도 도움이 될 수 있습니다. 이러한 오류에서 다음 조치를 계획하는 데 도움이되는 정보를 알아낼 수 있습니다.- 계정, 이메일 등을 처리 할 때 "잘못된 로그인 정보"와 같은 모호한 문구를 사용해야 합니다.
- Referrer-Policy 설정
- 앵커 태그 또는 웹 사이트 외부로 이동하는 링크를 사용할 때마다 헤더 정책
"Referrer-Policy": "no-referrer"를 적용하거나 앵커 태그의 경우rel = noopener or noreferrer를 설정해주세요. - 이러한 헤더 및 속성을 설정하지 않으면 대상 웹 사이트에서 세션 토큰 및 데이터베이스 ID와 같은 데이터를 얻을 수 있습니다.
- 앵커 태그 또는 웹 사이트 외부로 이동하는 링크를 사용할 때마다 헤더 정책
- 정기적으로 종속성 검사
- 취약한 패키지 목록을 점검하고 보안 문제를 방지하기 위해 업그레이드해야 합니다.
- GitHub는 이제 취약한 종속성에 플래그를 지정할 수 있으며 소스 코드를 자동으로 확인하고 bump 버전에 대한 pull 요청을 열 수도 있습니다.
- 제 3 자 서비스 피하기
- Google Analytics, Google Tag Manager, Intercom, Mixpanel 같은 타사 서비스가 손상되는 경우 웹 앱을 취약하게 만들 수 있습니다. 따라서 강력한 CSP 정책을 갖는 것이 중요합니다. 대부분의 타사 서비스에는 정의 된 CSP 지시문이 있으므로 추가하면 됩니다.
- 또한
integrity스크립트 태그를 추가하면 하위 리소스 무결성을 검사하는데, 스크립트의 암호화 해시를 검증하고 변조되지 않았는지 확인할 수 있습니다.
오픈 소스 패킷 분석 프로그램으로 네트워크의 문제, 분석, 소프트웨어 및 통신 프로토콜 개발, 교육에 쓰이고 있습니다.
와이어샤크(Wireshark)는 각기 다른 네트워크 프로토콜의 구조를 이해하는 소프트웨어입니다. 그러므로 각기 다른 네트워크 프로토콜이 규정한 각기 다른 패킷의 의미와 더불어 필드와 요약 정보를 보여줄 수 있죠. 와이어샤크는 pcap을 이용하여 캡처를 포획하므로 pcap이 지원하는 종류의 네트워크의 패킷만 포획할 수 있습니다.
와이어샤크는 실시간 네트워크 연결의 유선으로부터 데이터를 포획하고, 이미 포획한 패킷을 기록해둔 파일로부터 데이터를 읽을 수 있습니다.
실시간 데이터를 이더넷, IEEE 802.11, PPP, 루프백을 포함한 수많은 네트워크로부터 읽을 수 있으며 포획한 네트워크 데이터는 GUI나 터미널 (명령 줄) 버전의 유틸리티 TShark를 통해 탐색할 수 있습니다.
또한 포획한 파일들을 editcap 프로그램으로의 명령 줄 스위치를 통하여 프로그래밍하듯이 편집하거나 변환할 수 있습니다.
💬 간단한 데이터를 클라이언트로만 관리 할수 있는가, 이와 관련해서 브라우저에서 어떠한 것들을 지원하고 있는가, 예를 들면 소셜 로그인같은 것들에 대한 브라우저 종료시 발생하는 문제에 대응 경험이 있는가
DOCTYPE은 Document Type의 약어입니다. DOCTYPE은 항상 DTD(Document Type Definition)와 관련됩니다.
DTD는 특정 문서가 어떻게 구성되어야 하는지 정의(ex: button은 span을 포함할 수 있지만 div는 그럴 수 없습니다)하는 반면, DOCTYPE은 문서가 존중할만한 DTD를 선언합니다(ex: 이 문서는 HTML DTD를 존중합니다).
웹 페이지는 DOCTYPE 선언이 필요합니다. 유저 에이전트에게 문서가 존중하는 HTML 사양의 버전을 알리는데 사용되니까요. 유저 에이전트가 올바른 DOCTYPE을 인식하면, 문서를 읽는데에 DOCTYPE과 일치하는 no-quirks mode를 트리거합니다. 유저 에이전트가 올바른 DOCTYPE을 인식하지 못하면, quirks mode를 트리거합니다.
HTML5 표준에 대한 DOCTYPE 선언은 <!DOCTYPE html>입니다.
기본적으로 페이지 내의 내용은 하나의 일관된 언어로만 표시되어야 합니다.
HTTP 요청을 서버에 보내면, 대개 요청하는 유저 에이전트가 Accept-Language 헤더와 같은 기본 언어 설정에 대한 정보를 보냅니다. 그 다음 서버는 이 정보를 사용하여 해당 언어가 제공 가능한 경우, 해당 언어 버전의 문서를 반환할 수 있습니다. 반환된 HTML 문서는 <html lang="en">...</html>과 같이 <html> 태그에 lang 속성을 선언해야 합니다.
백엔드에서 HTML 마크업은 YML 또는 JSON 형식으로 저장된 특정 언어에 대한 i18n placeholder와 내용을 포함합니다. 그 다음 서버는 일반적으로 백엔드 프레임워크의 도움을 받아 특정 언어로 HTML 페이지를 동적 생성합니다.
- HTML에 lang 속성을 사용합니다.
- 기본적으로 그들이 접속한 지역의 언어로 안내합니다.
- 사용자가 번거롭지 않도록 쉽게 국가/언어를 변경할 수 있도록 합니다.
- 텍스트를 포함한 이미지를 사용하는 것은 확장 가능한 접근이 아닙니다.
- 이미지에 텍스트를 배치하는 것은 잘 보이고 시스템 글꼴이 아닌 글꼴을 모든 컴퓨터에 표시하는데 여전히 널리 사용되는 방법입니다. 그러나 이미지에 텍스트를 번역하려면, 텍스트 문자열에 각 언어에 대해 만들어진 별도 이미지가 필요합니다. 이 같은 대체 방식이 늘어나면 금방 통제가 어려워집니다.
- 단어/문장 길이 제한
- 일부 언어는 다른 언어로 작성될 때 더 길어질 수도 있습니다. 디자인에 레이아웃이나 오버 플로우 문제 발생에 주의하세요. 디자인에 필요한 텍스트의 양을 정하거나, 디자인이 꺠질 수 있는 디자인은 하지 않도록 하는 것이 가장 좋습니다. 문자 수 제한은 제목, 레이블, 버튼과 같은 항목에서 사용됩니다. 본문이나 댓글과 같이 자유롭게 흐르는 텍스트에 대해서는 문제가 되지 않습니다.
- 색상이 어떻게 이해될지에 대해 주의 깊게보세요.
- 색상은 언어와 문화에 따라 다르게 인식됩니다. 적절한 색상을 사용하여 디자인해야 합니다.
- 날짜와 통화 형식
- 날짜는 종종 다른 방식으로 표현됩니다.
- 번역된 문자열을 연결하지 않습니다.
"오늘의 날짜는 " + date + "입니다"와 같은 것은 하지마세요. 단어의 순서가 다른 언어에서는 문자가 망가지게됩니다. 대신 각 언어에 대한 매개변수와 함께 템플릿 스트링을 사용하세요. 예를 들면, 영어와 한국어로된 다음 두 문장을 보세요.I will travel on {% date %}, 나는 {% date %}에 여행 갈거야. 변수의 위치는 언어의 문법에 따라 달라집니다.
- 언어를 읽는 방향
- 영어는 왼쪽에서 오른쪽으로, 위에서 아래로 읽지만, 전통적인 일본어는 위에서 아래로, 오른쪽에서 왼쪽으로 읽습니다.
프론트엔드 개발자는 DOM 추가 프로퍼티 등의 조작없이 DOM 자체에 추가적인 데이터를 저장하기 위해 data-속성을 사용했었습니다. 이는 적절한 속성이나 요소가 없는 페이지나 애플리케이션에 사용자정의 데이터를 비공개로 저장하기 위한 것이었죠.
요즘에는 data-속성을 사용하는 것을 권장하지 않습니다. 그 이유 중 하나는 사용자가 브라우저의 inspect 기능를 사용하여 데이터 속성을 쉽게 수정할 수 있다는 것입니다. 데이터 모델은 자바스크립트 자체에 더 잘 저장되며, 라이브러리나 프레임워크의 데이터 바인딩을 통해 DOM을 업데이트된 상태로 유지하는 것이 더 낫습니다.
- 의미 : 콘텐츠를 보다 더 정확하게 설명할 수 있도록 허용합니다.
- 연결 : 새롭고 혁신적인 방법으로 서버와 통신할 수 있도록 허용합니다.
- 오프라인과 저장소 : 웹 페이지가 클라이언트 측에서 데이터를 로컬로 저장하여, 오프라인에서보다 효율적으로 동작하도록 허용합니다.
- 멀티미디어 : 개방형 웹에서 비디오와 오디오를 일급으로 만듭니다.
- 2D/3D 그래픽과 효과 : 훨씬 다양한 프레젠테이션 옵션을 허용합니다.
- 성능과 통합 : 컴퓨터 하드웨어의 성능 최적화와 개선으로 더 나은 사용을 제공합니다.
- 장치 접근 : 다양한 입출력 장치의 사용을 허용합니다.
- 스타일링 : 사용자가 더 세련된 테마를 사용하게 합니다.
클라이언트 측에서 값을 저장하는 key-value 저장소 매커니즘입니다. 모두 문자열로만 값을 저장할 수 있습니다.
| cookie | localStorage | sessionStorage | |
|---|---|---|---|
| 생성자 | 클라이언트나 서버. 서버는 Set-Cookie 헤더를 사용할 수 있습니다 | 클라이언트 | 클라이언트 |
| 만료 | 수동으로 설정 | 영구적 | 탭을 닫을 때 |
| 브라우저 세션 전체에서 지속 | 만료 설정 여부에 따라 다름 | O | X |
| 모든 HTTP 요청과 함께 서버로 보냄 | 쿠키는 Cookie 헤더를 통해 자동 전송됨 | X | X |
| 용량 (도메인당) | 4kb | 5MB | 5MB |
| 접근성 | 모든 윈도우 | 모든 윈도우 | 같은 탭 |
HTML 파싱이 중단되고, 스크립트를 즉시 가져오고 실행되며, 스크립트 실행 후 HTML 파싱이 다시 시작됩니다.
HTML 파싱과 병렬적으로 가져오며, 가능할 때 즉시 실행됩니다(아마 HTML 파싱이 끝나기 전).
스크립트가 페이지의 다른 스크립트들과 독립적인 경우 async를 사용하세요.
HTML 파싱과 병렬적으로 가져오지만, 페이지 파싱이 끝나면 실행됩니다.
이 스크립트 태그가 여러 개라면 각 스크립트는 페이지에 등장한 순서대로 실행됩니다. 스크립트가 완전히 파싱된 DOM에 의존되는 경우 defer 속성은 스크립트를 실행하기 전에 HTML이 완전히 파싱되도록 하는데 유용합니다. <body>의 끝부분에 일반 <script>를 두는 것과 별 차이가 없습니다. defer 스크립트는 document.write를 포함하면 안됩니다.
주의: src 속성이 없는 스크립트 태그는 async 와 defer 속성이 무시됩니다.
💬 왜 일반적으로 CSS <link> 태그를 <head>...</head> 태그 사이에 위치시키고, <script> 태그를 </body> 직전에 위치시키는 것이 좋은 방법인가요? 다른 예외적인 상황을 알고있나요?
-
<link>를<head>안에 넣는 것은 최적화된 웹사이트를 구출할 때 적절한 명세의 일부입니다. 페이지가 처음로드되면 HTML과 CSS가 동시에 파싱됩니다. HTML은 DOM(Document Object Model)을 만들고 CSS는 CSSOM (CSS Object Model)을 만듭니다. 두 가지 모두 웹사이트에서 시각적인 부분을 만드는데 필요하므로, 빠른의미있는 첫 번째 페인팅을 가능하게 합니다. 이 점진적 렌더링은 사이트의 성능 점수에서 측정되는 사이트 최적화의 범주입니다. -
문서 맨 아래에 CSS를 두는 것은 IE를 비롯한 많은 브라우저에서 점진적 렌더링을 금지시키는 것입니다. 몇몇 브라우저는 스타일이 변경되면 페이지의 요소를 다시 그리지 않아도 되도록 렌더링을 차단하므로 사용자는 빈 하얀 페이지에서 멈추게 돼죠. 다른 경우에는 스타일되지 않은 내용이 깜빡일 수 있습니다(flashes of unstyled content: FOUC).
-
그 외에도 상단에 배치하면 페이지가 점진적으로 렌더링되기 때문에 UX가 향상되며, 스타일이 없는 내용이 잠깐 보이는 것을 방지할 수 있습니다.
-
<script>는 다운로드되고 실행되는 동안 HTML 파싱을 차단합니다. 스크립트를 맨 아래에 두면 HTML을 먼저 파싱하여 사용자에게 표시할 수 있습니다. -
스크립트에
document.write()가 있을 때는<script>를 아래쪽에 두는 것이 예외적일 수 있습니다만, 요즘은document.write()를 사용하지 않는 것이 좋습니다. 또한,<script>를 맨 아래에 두면, 브라우저가 전체 문서가 파싱될 때까지 스크립트 다운로드를 시작할 수 없다는 것을 의미합니다. 이렇게하면 DOM 요소를 조작해야하는 코드가 오류를 발생시키지 않고 전체 스크립트를 중지시키지 않습니다.<head>에<script>를 넣어야하는 경우, defer 속성을 사용하세요. HTML을 파싱한 후에 스크립트를 다운로드하고 실행하는 것과 같은 효과가 있습니다.
점진적 렌더링(Progressive Rendering)이란 콘텐츠를 가능한한 빠르게 표시하기 위해 웹 페이지의 성능을 향상시키는 데 사용되는 기술입니다(특히, 인식되는 로딩 시간을 향상시킵니다).
아래 같은 관련 기술이 있습니다.
- 이미지 지연 로딩
- 페이지의 이미지를 한꺼번에 로딩하지 않습니다. 자바스크립트를 사용하여 사용자가 이미지를 표시하는 페이지 부분으로 스크롤 할 때 이미지를 로드 할 수 있습니다.
- 보이는 콘텐츠의 우선순위 설정(또는 스크롤 없이 볼 수 있는 렌더링)
- 가능한 한 빨리 표시하기 위해 사용자 브라우저에서 렌더링될 페이지에 필요한 최소한의 CSS/콘텐츠/스크립트 만 포함하면 deferred 스크립트를 사용하거나 DOMContentLoaded/load 이벤트를 사용하여 다른 리소스와 내용을 로드할 수 있습니다.
- 비동기 HTML 프래그먼트
- 페이지의 백엔드에서 HTML 페이지의 일부를 브라우저로 가져옵니다. 이 기술에 대한 자세한 내용은 여기에서 찾을 수 있습니다.
기기의 디스플레이 너비에 따라 다른 이미지를 사용자에게 제공하려는 경우 srcset 속성을 사용합니다.
레티나 디스플레이를 통해 장치에 고품질 이미지를 제공하여 사용자 경험을 향상시키고, 저해상도 이미지를 저사양 기기에 제공하여 성능을 높이고 데이터 낭비를 줄입니다(왜냐하면 더 큰 이미지를 제공하는 것은 눈에 보일 정도의 차이가 없기 때문).
예를 들어 <img srcset="small.jpg 500w, medium.jpg 1000w, large.jpg 2000w" src="..." alt="">는 클라이언트의 해상도에 따라 브라우저에 small, medium, large .jpg 그래픽을 표시하도록 지시합니다. 첫 번째 값은 이미지 이름이고 두 번째 값은 픽셀 단위의 이미지 너비입니다. 320px 너비의 경우, 다음과 같은 계산을 따릅니다
- 500 / 320 = 1.5625
- 1000 / 320 = 3.125
- 2000 / 320 = 6.25
클라이언트의 해상도가 1x 일 경우, 1.5625가 가장 가깝고 small.jpg에 해당하는 500w가 브라우저에 의해 선택됩니다.
해상도가 레티나(2x)인 경우 브라우저는 최소값에서 가장 위로 가까운 해상도를 사용합니다. 500w(1.5625)는 1보다 크고 이미지가 보기 좋지 않을 수 있기 때문에 선택하지 않는다는 것을 의미합니다. 그래서 브라우저는 계산 결과 비율값이 2에 가까운 1000w (3.125) 이미지를 선택합니다.
srcset는 데스크탑 디스플레이처럼 거대한 이미지를 필요로하지 않기 때문에 화면 장치를 좁히는 작은 이미지 파일을 제공하고자하는 문제를 해결합니다.
srcset는 화면이 작은 기기에서 데스크탑 디스플레이처럼 큰 이미지가 필요하지 않기 때문에 작은 이미지 파일을 제공하는 문제를 해결하며, 선택적으로 고해상도/저해상도 화면에 다른 해상도 이미지를 제공할 수도 있습니다.
많은 템플릿 엔진(Pug, ERB, Slim, Handlebars, Jinja, Liquid 등)이 존재하나 큰 차이는 없으며, 보여줄 데이터를 조작하는 데 유용한 필터들과 내용을 escape 하는 유사한 기능을 제공합니다. 대부분의 템플릿 엔진을 사용하면 표시하기 전에 처리가 필요한 이벤트에 자신의 필터를 삽입할 수 있습니다.
inline 속성은 text 크기만큼 공간을 차지하나 줄바꿈이 없습니다. 따라서 width, height, margin(top/bottom), padding(top/bottom), line-height를 사용할 수 없습니다. 대표적인 태그로는 span 태그가 있어요.
block 속성은 무조건 한 줄을 차지하며 다음 태그는 줄바꿈이 생기며 대표적으로는 div 태그가 있어요.
inline-block은 inline 속성과 block 속성의 특징을 전부 가지고 있습니다. inline 속성과 다르게 width, height, margin, padding과 line-height 전부 적용할 수 있습니다.
정리하자면, 아래와 같죠.
| block | inline-block | inline |
|---|---|---|
| 크기 | 부모 컨테이너의 너비를 채웁니다. | 내용에 의존합니다. |
| 위치 | 새 줄에서 시작하고, 그 옆에 HTML 요소를 허용하지 않습니다 (float을 추가 할 때 제외). | 다른 콘텐츠와 함께 흐르고, 다른 요소가 옆에 있는 것을 허용합니다. |
| width, height 지정 가능 여부 | 가능 | 가능 |
| vertical-align 정렬 가능 여부 | 불가능 | 가능 |
| margin 과 padding | 모든 방향에서 가능. | 모든 방향에서 가능. |
| float | - | - |
브라우저는 CSS 규칙의 특정성에 따라 요소에 표시할 스타일을 결정합니다. 브라우저는 이미 특정 요소와 일치하는 규칙을 결정했다고 가정합니다. 일치하는 규칙들 가운데, 네 개의 쉼표로 구분된 값 a, b, c, d는 다음을 기반으로 각 규칙에 대해 계산됩니다.
- a는 인라인 스타일이 사용되고 있는지입니다. 속성의 선언이 요소의 인라인 스타일이면 a는 1이고, 그렇지 않으면 0입니다.
- b는 ID 셀렉터의 수입니다.
- c는 클래스, 속성, 가상 클래스 선택자의 수입니다.
- d는 태그, 가상 요소 선택자의 수입니다.
결과적인 특정성은 점수가 아니라, 컬럼마다 비교할 수 있는 값들의 행렬입니다. 선택자를 비교하여 가장 높은 특정성을 갖는 항목을 결정할 때, 왼쪽에서 오른쪽 순으로 각 열의 가장 높은 값을 비교합니다. 따라서 b열의 값은 c와 d열에 있는 값을 무시합니다. 따라서 0,1,0,0의 특정성은 0,0,10,10중 하나보다 큽니다.
동등한 특정성의 경우 가장 중요합니다. 스타일 시트에 동일한 규칙을 두 번 작성한 경우(내부나 외부에 관계없이) 스타일 시트의 하위 규칙이 스타일 될 요소에 더 가까우므로 더 구체적으로 적용됩니다.
필요하다면 쉽게 재정의할 수 있도록 낮은 특정성 규칙들을 작성합니다. CSS UI 컴포넌트 라이브러리 코드를 작성할 때, 라이브러리 사용자가 !important를 사용하거나 특정성을 높이기 위해 지나치게 복잡한 CSS 규칙을 사용하지 않고도 이를 재정의할 수 있도록 특정성을 낮게 하는 것이 중요하니까요.
- Resetting은 요소의 모든 기본 브라우저 스타일을 제거합니다. 예를 들어 margin, padding, font-size는 같은 값으로 재설정돼죠.
- Normalizing은
모든 스타일을 제거하는 것이 아니라유용한 기본 스타일을 보존합니다. 또한 일반적인 브라우저 종속성에 대한 버그를 수정합니다.
보통 자신만의 스타일링이 필요한 경우 Resetting을, 아닌 경우 Normalizing을 선택합니다.
특정 요소를 흐르게 하는 속성입니다.
float 속성으로 특정 박스(div 등)를 왼쪽이나 오른쪽으로 위치시킬 수 있는 레이아웃 기법입니다.
float이 적용된 요소는 기본적인 흐름과 관계 없이 자유로운 배치가 가능하며 position: absolute 값과 양립할 수 없습니다. 또한 어떤 요소든 상관 없이 display: inline-block으로 취급됩니다.
float 을 사용해 레이아웃을 잡다보면 float을 해제할 clear 속성이 필요해지는데, 이 때 부모 요소에 clearfix를 적용하는 것이 제일 좋습니다. 자식 요소를 선택한 값에 따라 부모 요소 안에 가둘 수 있기 떄문이죠.
z-index속성은 겹치는 요소의 쌓임 순서를 제어하며position: static이 아닌 요소만 영향을 미칩니다.
z-index 값이 없으면 DOM에 나타나는 순서대로 요소가 쌓이게 됩니다. 정적이지 않은(non-static) 위치지정 요소(및 해당 하위 요소)는 HTML 레이어 구조와 상관없이 기본 정적 위치로 항상 요소 위에 나타납니다.
스택 컨텍스트(stacking context)는 레이어들을 포함하는 요소입니다. 지역 스택 컨텍스트 내에서, 자식의 z-index 값은 문서 루트가 아닌 해당 요소를 기준으로 설정됩니다. 해당 컨텍스트 외부 레이어(예: 지역 스택 컨텍스트의 형제 요소)는 그 사이의 레이어에 올 수 없습니다. 요소 B가 요소 A의 상단에 위치하는 경우, 요소 A의 하위 요소 C는, 요소 C가 요소 B보다 z-index가 더 높은 경우에도 요소 B 보다 위에 올 수 없습니다.
각각의 스택 컨텍스트는 자체적으로 포함되어 있습니다 - 요소의 내용이 쌓인 후에는 전체 요소를 스택 컨텍스트의 쌓인 순서로 고려합니다. 다음 몇몇 CSS 속성, opacity가 1보다 작거나, filter: none이 이거나, transform: none이 아닌 것들이 새로운 스택 컨텍스트를 트리거 합니다.
BFC(Block Formatting Context)는 블록 박스가 배치된 웹 페이지의 시각적 CSS 렌더링의 일부입니다.
float, position: absolute로 배치된 요소, inline-blocks, table-cells, table-caption 그리고 visible(그 값이 viewport에 전파되었을 때는 제외)이 아닌 overflow가 있는 요소들이 새로운 Block Formatting Context를 만듭니다.
BFC는 다음 조건 중 하나 이상을 충족시키는 HTML 박스입니다.
- float의 값이 none이 아님.
- position의 값이 static도 아니고 relative도 아님.
- display의 값이 table-cell, table-caption, inline-block, flex, inline-flex임.
- overflow의 값이 visible이 아님.
BFC에서 각 박스의 왼쪽 바깥 모서리는 포함하는 블록의 왼쪽 모서리에 닿습니다(right-to-left 포맷에서는, 오른쪽 모서리에 닿음).
- 빈 div 방법
<div style="clear:both;"></div>
- Clearfix 방법
overflow: auto또는overflow: hidden방법- 부모는 새로운 Block Formatting Context를 설정하고, 확장된 자식을 포함하도록 합니다.
대규모의 프로젝트에서는 유용하게 .clearfix 클래스를 만들어 필요한 곳에서 사용합니다. 자식이 부모보다 크기가 큰 경우 overflow: hidden은 자식을 모두 보여줄 수 없습니다.
CSS 스프라이트는 여러 이미지를 하나의 큰 이미지로 결합합니다. 일반적으로 아이콘에 사용되는 기술(Gmail에서 사용)입니다.
- 스프라이트 생성기를 사용하여 여러 이미지를 하나로 묶어 적절한 CSS를 생성합니다.
- 각 이미지는
background-image,background-position,background-size속성이 정의된 해당 CSS 클래스를 갖습니다. - 해당 이미지를 사용하기 위해, 요소에 해당 클래스를 추가합니다.
- 장점
- 여러 이미지에 대한 HTTP 요청 수를 줄입니다(스프라이트 시트당 하나의 단일 요청만 필요합니다). 물론 HTTP/2.0를 사용하면 여러 이미지를 로드하는 것은 문제가 되지 않죠.
:hover의 상태에서만 나타나는 이미지가 필요할 때 이미지를 미리 다운로드하여 깜박임이 보이지 않습니다.
- 문제를 식별하고 해당 브라우저가 사용 중일 때만 로드되는 별도의 스타일 시트를 사용합니다.
- 이 방식을 사용하려면 서버사이드 렌더링이 필요합니다.
- 이미 이러한 스타일링 문제를 처리하고 있는 Bootstrap 같은 라이브러리를 사용합니다.
- autoprefixer를 사용하여 벤더 프리픽스를 코드에 자동으로 추가합니다.
Reset.css또는Normalize.css를 사용합니다.
접근성(Accessibility, a11y)에 관련이 있습니다.
width: 0; height: 0- 요소가 화면의 어떤 공간도 차지하지 않도록 합니다. 결과적으로 보이지 않게 됩니다.
position: absolute; left: -99999px- 화면 외부에 배치합니다.
text-indent: -9999px- 이것은 block인 요소 내의 텍스트에서만 동작합니다.
메타데이터- Schema.org, RDF, JSON-LD 등을 사용합니다.
WAI-ARIA- 웹 페이지의 Accessibility를 높이는 방법을 정의하는 W3C 기술 사양입니다.
absolute 위치 지정 접근 방법이 대부분의 요소에 동작하며 가장 간단한 기술이므로 이를 활용하세요.
@media 속성은 screen 을 포함하여 4가지 타입이 있습니다.
| 타입 | 설명 |
|---|---|
| all | 모든 미디어 기기 장치 |
| 프린터 | |
| speech | 화면을 크게 읽는 스크린리더 |
| screen | 컴퓨터 스크린, 태블릿, 스마트폰 등 |
- 브라우저는 선택자가 맨 오른쪽(key 선택자)부터 왼쪽으로 일치하는지 확인합니다.
- 브라우저는 선택자에 따라 DOM의 요소를 필터링하고 해당 부모 요소가 일치하는지 식별합니다.
- 선택자 체인의 길이가 짧을수록 브라우저는 해당 요소가 선택자와 일치하는지 여부를 빠르게 판별할 수 있습니다.
- 따라서 태그 선택자와 보편적인 선택자 사용을 피해야 합니다.
- 이들은 많은 요소가 매치되기 때문에 부모가 일치하는지 여부를 판단하기 위해 브라우저가 많은 작업을 해야합니다.
BEM (Block Element Modifier) 방법론에서는 모두 단일 클래스를 갖고, 계층구조가 필요한 곳에서는 클래스의 이름을 확장하기를 권장합니다. 따라서 선택자를 쉽고 효율적으로 재정의할 수 있습니다.
어떤 CSS 속성이 reflow, repaint, compositing을 트리거 하는지 알아두세요. 가능하면 레이아웃(reflow 트리거)를 변경하는 스타일은 피하세요.
-
장점
- CSS의 유지보수성이 향상됩니다.
- 중첩 선택자를 작성하기 쉽습니다.
- 일관된 테마를 위한 변수사용. 여러 프로젝트에 걸쳐 테마 파일을 공유할 수 있습니다.
- 반복되는 CSS를 위한 Mixins 생성이 가능합니다.
- 코드를 여러 파일로 나눕니다.
- CSS 파일도 나눌 수 있지만, 그렇게 하기 위해서는 각 CSS 파일을 다운로드하기 위한 HTTP 요청이 필요하니까요.
-
단점
- 전처리기를 위한 도구가 필요합니다.
- 컴파일이 필요하므로 느릴 수도 있습니다.
font-face를 사용하고 font-weight가 다른 경우 font-family를 정의합니다.
이는 효율적인 CSS 작성과 관련이 있습니다.
- 브라우저는 선택자를 오른쪽(선택자)에서부터 왼쪽으로 일치시킵니다.
- 브라우저는 선택자에 따라 DOM의 요소를 필터링하고 부모 요소를 검사하여 일치를 판정합니다.
- 선택자 체인의 길이가 짧을수록, 브라우저가 해당 요소가 일치하는지 여부를 더 빠르게 판단할 수 있습니다.
예를 들어, 이 p span 선택자는 먼저 모든 <span>요소를 찾아 그 부모의 루트까지 모두 통과하여 <p>요소를 찾습니다. 특정한 <span>의 경우 <p>를 찾는 즉시 <span>이 일치하는 것을 알고있으며, 이에 따라 매칭을 중지합니다.
CSS 의사 요소(Pseudo-element)는 선택자에 추가되는 키워드로, 선택한 요소의 특정 부분을 스타일링 할 수 있습니다.
마크업을 수정하지 않고(:before, :after) 텍스트 데코레이션을 위해 사용하거나(:first-line, :first-letter) 마크업에 요소를 추가할 수 있습니다(content: ...와 결합).
-
:first-line,:first-letter: 텍스트를 데코레이션하는데 사용될 수 있습니다. -
위의 .clearfix에 사용되어
clear: both로 영역을 차지하지 않는 요소를 추가합니다. -
특정 삼각 화살표는
:before와:after를 사용합니다. 삼각형이 실제로 DOM이 아닌 스타일의 일부로 간주되기 때문에 분리하는 것이 좋습니다. 추가적인 HTML 요소를 사용하지 않고 CSS 스타일만으로 삼각형을 그릴 수는 없습니다.
CSS 박스 모델은 문서 트리의 요소에 대해 생성되고 시각적 포매팅 모델에 따라 배치된 사각형 상자를 나타냅니다. 각 박스에는 content 영역(예: 텍스트, 이미지 등)과 padding, border, margin 영역을 선택적으로 사용할 수 있습니다.
CSS 박스 모델은 다음을 계산합니다.
- 블록 요소가 공간을 얼마나 차지하는가?
- 테두리 또는 여백이 겹치거나 충돌하는가?
- 박스의 크기는 얼마인가?
박스 모델에는 다음과 같은 규칙이 있습니다.
- 블록 요소의 크기는 width, height, padding, border, margin에 의해 계산됩니다.
- height 가 지정되어있지 않으면, 블럭 요소는 포함하고있는 내용만큼의 높이를 가질 것이고, padding을 더합니다.(float가 아닌경우).
- width 가 지정되지있지 않으면, float가 아닌 블록 요소는 [부모의 너비-padding]에 맞게 확장됩니다.
- 요소의 height는 내용의 height에 의해 계산됩니다.
- 요소의 width는 내용의 width에 의해 계산됩니다.
- 기본적으로, padding과 border는 요소의 width와 height의 일부가 아닙니다.
기본적으로, 요소들에 box-sizing: content-box가 적용되면 내용의 크기만 고려됩니다. box-sizing: border-box는 요소의 width와 height가 어떻게 계산되는지를 변경하여, border와 padding도 계산에 포함됩니다.
- 요소의 height는 내용의 **[height + 수직 padding + 수직 border 폭]**으로 계산됩니다.
- 요소의 width 는 내용의 **[width + 수평 padding + 수평 border 폭]**으로 계산됩니다.
- padding과 border를 박스 모델의 일부분으로 생각하면, 디자이너가 실제로 생각하는 것과 거의 동일합니다.
위치가 정해진 요소는 계산된 position 속성이 relative, absolute, fixed, sticky 중 하나인 요소입니다.
- static : 기본 위치
- 요소가 평소와 같이 페이지에 위치합니다. top, right, bottom, left, z-index 속성은 적용되지 않습니다.
- relative : 상대 위치
- 요소의 위치가 레이아웃을 변경하지 않고, 자체에 상대적으로 조정됩니다. (따라서 배치되지 않은 요소의 간격을 남겨 둡니다.)
- absolute : 절대 위치
- 요소가 페이지의 평소 위치에서 제거되고, 가장 가까운 static이 아닌 부모 블록이 있는 경우 지정된 위치에 배치됩니다. 그렇지 않으면 최상위 블록에 의존됩니다. absolute로 배치된 박스는 margin을 가질 수 있으며 다른 margin과 충돌하지 않습니다. 이 요소는 다른 요소의 위치에 영향을 주지 않습니다.
- fixed : 고정 위치
- 요소는 페이지의 평소 위치에서 제거되고 뷰포트를 기준으로 지정된 위치에 배치되며 스크롤 할 때 이동하지 않습니다.
- sticky : sticky는 relative와 fixed의 하이브리드입니다.
- 요소는 지정된 임계값을 넘을 때까지 relative 위치로 처리되며, 특정 지점에서 fixed 위치로 처리됩니다.
displat: flex는 주로 1차원 레이아웃을,display: grid는 2차원 레이아웃을 대상으로 사용합니다.
Flexbox는 CSS에서 컨테이너 안에 있는 요소의 수직 가운데 정렬, sticky footer 등과 같은 많은 일반적인 문제들을 해결합니다. 단, flex-grow를 사용할 때 일부 브라우저에서 비호환성 문제(Safari, IE)가 발생했고, 결국 백분율로 나타낸 폭을 계산하기 위해 inline-blocks과 다시 작성해야 했습니다.
Grid는 그리드 기반의 레이아웃을 생성하기 위한 가장 직관적인 접근법이지만 현재 브라우저 지원은 넓지 않습니다.
반응형 웹사이트를 만드는 것은 일부 요소가 미디어 쿼리를 통해 장치의 화면 크기(일반적으로 뷰포트 너비)에 따라 크기나 다른 기능을 조정하도록 반응함을 의미합니다. 모바일 우선 전략 또한 반응적이지만 모바일 장치에 대한 모든 스타일을 우선 정의하고 다른 장치에 대한 특정 규칙은 나중에 추가합니다.
모바일 장치에서 적용되는 모든 규칙이 미디어 쿼리에 대해 유효성 검사를 받을 필요가 없으므로 모바일 장치에서 더 뛰어난 성능을 발휘합니다.
반응형과 적응형 디자인은 모두 서로 다른 뷰포트 사이즈, 해상도, 사용 컨텍스트, 제어 메커니즘 등을 조정하여 다양한 장치에서 사용자 경험을 최적화하려고 시도합니다.
반응형 디자인은 유연성 원칙에 따라 동작합니다. 즉, 어떤 장치에서나 보기 좋은 단일 변하기 쉬운 웹 사이트입니다. 반응형 웹 사이트는 미디어 쿼리, 유연한 그리드 및 반응 형 이미지를 사용하여 다양한 요인에 따라 유연하고 변화하는 사용자 경험을 제공합니다. 마치 하나의 공이 여러개의 서로 다른 링을 통과하기 위해 커지거나 줄어드는 것과 유사합니다.
적응형 디자인은 점진적 향상의 현대적 정의에 더 가깝습니다. 하나의 유연한 디자인 대신에, 적응형 설계는 장치 및 기타 기능을 감지 한 다음 사전 정의 된 뷰포트 크기 및 기타 특성 세트를 기반으로 적절한 기능 및 레이아웃을 제공합니다. 하나의 공이 여러개의 서로 다른 링을 통과하는 대신, 링의 크기에 따라 여러개의 공을 사용하는 것과 유사합니다.
translate()은 CSS transform의 값입니다.
transform이나 opacity를 변경해도 브라우저의 reflow나 repaint가 다시 발생하지 않고 composite만 실행되는 반면, 절대 위치를 변경하면 reflow가 발생합니다.
transform을 사용하면 브라우저에서 이 요소를 위한 GPU 레이어가 생성되지만, 절대 위치 속성을 변경하는 것은 CPU를 사용하니까요. 그러므로 translate()가 더 효율적이며, 매끄러운 애니메이션을 위한 페인트 시간이 짧아집니다.
translate()을 사용할 때는 절대 위치를 변경할 때와 달리 원래 위치(일종의 position: relative)를 그대로 사용합니다.
이진 탐색 트리(Binary Search Tree)는 이진 탐색(binary search)과 연결리스트(linked list)를 결합한 자료구조의 일종입니다.
이진 탐색의 효율적인 탐색 능력을 유지하면서 빈번한 자료 입력과 삭제를 가능하게끔 고안됐죠.
이진 탐색의 경우 탐색에 소요되는 시간복잡도는 O(logn)으로 빠르지만 자료 입력, 삭제가 불가능합니다.
연결리스트의 경우 자료 입력, 삭제에 필요한 시간복잡성은 O(1)로 효율적이지만 탐색하는 데에는 O(n)의 시간복잡성이 발생합니다. 이를 적절히 사용하여 성능을 향상시키는 것이 이진 탐색 트리의 목적입니다.
이진 탐색 트리는 다음과 같은 속성을 갖습니다.
- 각 노드에 값이 있다.
- 값들은 전순서가 있다.
- 노드의 왼쪽 서브트리에는 그 노드의 값보다 작은 값들을 지닌 노드들로 이루어져 있다.
- 노드의 오른쪽 서브트리에는 그 노드의 값보다 큰 값들을 지닌 노드들로 이루어져 있다.
- 좌우 하위 트리는 각각이 다시 이진 탐색 트리여야 한다.
자바스크립트 (JS)는 가벼운, 인터프리터 혹은 just-in-time 컴파일 프로그래밍 언어로, 일급 객체를 지원합니다.
웹 페이지를 위한 스크립트 언어로 잘 알려져 있지만, Node.js, Apache CouchDB, Adobe Acrobat처럼 많은 비 브라우저 환경에서도 사용하고 있습니다. 자바스크립트는 프로토타입 기반, 다중 패러다임, 단일 스레드, 동적 언어로, 객체지향형, 명령형, 선언형(함수형 프로그래밍 등) 스타일을 지원합니다.
객체를 반환하는 메서드를 한 문장에 여러 번 호출하는 것입니다.
코드가 짧아지므로 유지보수성은 좋아지나 어디서 어떤 결과가 끝나는지 명확히 알기 어려우므로 디버깅이 힙듭니다.
자바스크립트의 간단한 로컬 캐시(Cache) 기술 중 하나로 메모리에 특정 정보를 기록한 뒤 필요 시 참조하여 사용하는 것입니다.
이미 연산했던 결과를 저장함으로써 불필요한 반복 연산을 피할 수 있습니다. 간단한 변수에 연산 결과를 저장해두고, 새로 계산하는 값이 기존에 존재하는지 확인하면 됩니다.
addEventListner, removeEventListener를 사용하여 등록 및 해제를 진행합니다.
이 때 각 함수에 필요한 매개변수로는 이벤트 타입, 사전 정의된 콜백 함수입니다.
이벤트 버블링(event bubbling)은 자바스크립트가 기본적으로 적용되어 있으며 이벤트 위임의 동작 메커니즘입니다.
DOM 요소에서 이벤트가 트리거되면 리스너가 연결되어 있는 경우 이벤트 처리를 시도하고 해당 이벤트가 부모에게 버블링되어 부모도 같은 이벤트가 발생합니다. 이 버블링은 요소의 최상단 부모 요소인 document까지 계속적으로 발생합니다.
stopPropagation()을 사용하여 버블링을 중지시킬 수 있습니다.
이벤트 캡처링(Event Capturing)은 이벤트 버블링의 반대 개념입니다.
DOM 요소에서 이벤트가 트리거되면 리스너가 연결되어 있는 경우 이벤트 처리를 시도하고, 해당 이벤트가 자식에게 캡처링되어 자식도 같은 이벤트가 발생합니다. 이 캡처링은 자손 요소의 마지막까지 계속적으로 발생합니다.
버블링과는 다르게 addEventListner 객체에 3번째 인자로 true 또는 {capture: true} 인자를 넘겨야 합니다.
stopPropagation()을 사용하여 캡처링을 중지시킬 수 있습니다.
이벤트 위임(Event Delegation)은 이벤트 리스너를 하위 요소에 추가하는 대신 상위 요소에 추가하는 기법입니다.
리스너는 DOM의 이벤트 버블링(Event Bubbling)으로 인해 하위 요소에서 이벤트가 발생될 때마다 실행됩니다. 이 기술의 이점은 다음과 같습니다.
- 각 하위 항목에 이벤트 핸들러를 연결하지 않고, 상위 요소에 하나의 단일 핸들러만 필요하기 때문에 메모리 사용 공간이 줄어듭니다.
- 제거된 요소에서 핸들러를 해제하고 새 요소에 대해 이벤트를 바인딩할 필요가 없습니다.
this의 값은 함수가 호출되는 방식에 따라 달라집니다.
- 일반 함수 호출 시 this는 전역 객체에 바인딩됩니다.
- 메서드 호출 시 메서드를 호출한 객체에 바인딩됩니다.
- 생성자 함수 호출 시 생성자 함수가 미래에 생성할 인스턴스에 바인딩됩니다.
- Function.prototype.apply/call/bind 메서드에 의한 간접 호출 시 Function.prototype.apply/call/bind 메서드에 첫 번째 인수로 전달된 객체에 바인딩됩니다.
모든 자바스크립트 객체는 다른 객체에 대한 참조인
__proto__프로퍼티를 가지고 있습니다.
객체의 프로퍼티에 접근할 때, 해당 객체에 해당 프로퍼티가 없으면 자바스크립트 엔진은 객체의 __proto__과 __proto__의 __proto__등을 보고 프로퍼티 정의가 있을 때까지 찾고, 만약 객체의 프로퍼티에 접근할 때 해당 객체에 해당 프로퍼티가 없으면 프로토타입 체인 중 하나에 있거나 프로토타입 체인의 끝에 도달할 때까지 찾습니다. 이 동작은 고전적인 상속을 흉내내지만, 실제로 상속보다 위임에 더 가깝습니다.
두 가지 모두 ES2015가 등장하기 전까지 자바스크립트에 기본적으로 존재하지 않는 모듈 시스템을 구현하는 방법입니다. CommonJS는 동기식인 반면 AMD(Asynchronous Module Definition - 비동기식 모듈 정의)는 분명히 비동기식입니다. CommonJS는 서버사이드 개발을 염두에 두고 설계되었으며, AMD는 모듈의 비동기 로딩을 지원하므로 브라우저용으로 더 많이 사용됩니다.
AMD은 구문이 매우 장황하고, CommonJS은 다른 언어처럼 import 문을 작성하는 스타일에 더 가깝습니다. 대부분의 경우 AMD를 필요로 하지 않습니다. 모든 자바스크립트를 연결된 하나의 번들 파일로 제공하면 비동기 로딩 속성의 이점을 누릴 수 없기 때문입니다. 또한 CommonJS 구문은 모듈 작성의 노드 스타일에 가깝고 클라이언트 사이드와 서버사이드 자바스크립트 개발 사이를 전환할 때 문맥 전환 오버 헤드가 적습니다.
ES2015 모듈이 동기식 및 비동기식 로딩을 모두 지원하는 것이 반가운 것은 마침내 하나의 접근 방식만 고수할 수 있다는 점입니다. 브라우저와 노드에서 완전히 동작되지는 않지만, 언제나 트랜스파일러를 사용하여 코드를 변환할 수 있습니다.
Node가 사용하는 모듈 로드 방식이 CommonJS 규격을 따르므로 Node 환경에서만 사용가능한데, 이외 환경에 돌아가게 하려면 웹팩 등의 처리가 필요합니다.
IIFE는 즉시 함수 호출 표현식(Immediately Invoked Function Expressions)을 의미합니다.
자바스크립트 parser는 function foo(){ }();을 function foo(){ }와 ();로 읽습니다. 전자는 함수 선언이며 후자(한 쌍의 중괄호)는 함수를 호출하려고 시도했지만, 이름이 지정되지 않았기 때문에 Uncaught SyntaxError : Unexpected token )을 발생시킵니다.
괄호를 추가하여 고치는 두 가지 방법이 있습니다.
(function foo(){ })()(function foo(){ }())
function으로 시작하는 문은 함수 선언으로 간주됩니다. 이 함수를 ()로 묶으면 함수 식이 되고, 이렇게하면 다음 ()로 함수를 실행할 수 있습니다. 이러한 함수는 전역 범위에 노출되지 않으며, 본문 내에서 이 함수 자체를 참조할 필요가 없는 경우에는 해당 함수의 이름을 생략할 수도 있습니다.
void function foo(){ }();처럼 void 연산자를 사용할 수도 있습니다. 불행히도, 이러한 접근방식에는 한 가지 문제가 있습니다. 주어진 표현식의 평가는 항상 undefined이므로, IIFE 함수의 반환 값은 무시됩니다.
undeclared 변수는 이전에 var, let, const를 사용하여 생성되지 않은 식별자에 값을 할당할 때 생성됩니다.
undeclared 변수는 현재 범위 외부에 전역으로 정의됩니다. strict 모드에서는 undeclared 변수에 할당하려고 할 때, ReferenceError가 발생합니다. undeclared 변수는 전역 변수처럼 좋지 않습니다. 이를 검사하려면, 사용할 때 try/catch 블록에 감싸세요.
undefined 변수는 선언되었지만, 값이 할당되지 않은 변수입니다.
이는 undefined 타입입니다. 함수가 실행 결과에 따라 아무값도 반환하지 않으면, 변수에 할당되며, 그 변수가 undefined 값을 갖습니다. 이를 검사하기 위해, 엄격한 (===) 연산자 또는 typeof에 undefined 문자열을 사용하여 비교하세요. 확인을 위해 추상 평등 연산자(==)를 사용해서는 안되며, 이는 값이 null이면 true를 반환합니다.
null인 변수는 null 값이 명시적으로 할당된 것입니다.
null은 값을 나타내지 않으며, 명시적으로 할당됐다는 점에서 undefined와 다릅니다. null을 체크하기 위해서 단순히 완전 항등 연산자(===)를 사용하여 비교하면 됩니다. 위와 같이, 추상 평등 연산자 (==)를 사용해서는 안되며, 값이 undefined이면 true를 반환합니다.
클로저는 함수와 그 함수가 선언된 렉시컬 환경의 조합입니다.
렉시컬은 렉시컬 범위 지정이 변수가 사용 가능한 위치를 결정하기 위해 소스 코드 내에서 변수가 선언된 위치를 사용한다는 사실을 나타냅니다. 클로저는 외부 함수가 반환된 후에도 외부 함수의 변수 범위 체인에 접근할 수 있는 함수입니다.
클로저는 이와 같이 사용할 수 있습니다.
- 클로저로 private 멤버 변수와 private 메서드를 모방할 수 있으며, 일반적으로 모듈 패턴에 사용됩니다.
- currying
커링(Currying) 은 함수와 함께 사용할 수 있는 고급 기술입니다. 자바스크립트에만 존재하는 것은 아니고 다른 언어에도 존재하죠.
커링은 f(a, b, c)처럼 단일 호출로 처리하는 함수를 f(a)(b)(c)와 같이 각각의 인수가 호출 가능한 프로세스로 호출된 후 병합되도록 변환하는 것입니다. 커링은 함수를 호출하지 않습니다. 단지 변환할 뿐이죠.
먼저 예제를 통해서 커링이 무엇인지 이해하고 그다음에 실용적인 적용법을 알아보겠습니다. f의 두 개의 인수를 커링하는 헬퍼 함수 curry(f)를 생성해 보겠습니다. 다른 말로 하면, f(a, b)처럼 두 개의 인수를 요구하는 함수를 f(a)(b) 형식으로 변환하는 curry(f)라는 함수를 만드는 것입니다.
function curry(f) { // 커링 변환을 하는 curry(f) 함수
return function(a) {
return function(b) {
return f(a, b);
};
};
}
// usage
function sum(a, b) {
return a + b;
}
let curriedSum = curry(sum);
alert( curriedSum(1)(2) ); // 3실제 구현은 그저 두 개의 래퍼를 사용한 것과 같이 간단합니다.
- curry(func)의 반환값은 function(a)형태의 래퍼입니다.
- curriedSum(1)같은 함수가 호출되었을 때, 그 인수는 렉시컬 환경에 저장이 되고 새로운 래퍼 function(b)이 반환됩니다.
- 그리고 반환된 function(b)래퍼 함수가 2를 인수로 호출됩니다. 그리고 반환값이 원래의 sum으로 넘겨져서 호출됩니다.
커링은 정보를 형식화하고 출력하는 로그 함수 log(date, importance, message) 등에 사용되며, 실제 프로젝트에서 이러한 함수는 네트워크를 통해 로그를 보내는 것과 같은 많은 유용한 기능을 제공합니다.
function log(date, importance, message) {
alert(`[${date.getHours()}:${date.getMinutes()}] [${importance}] ${message}`);
}커리 함수를 직접 구현해볼까요?
function curry(func) {
return function curried(...args) {
if (args.length >= func.length) {
return func.apply(this, args);
} else {
return function(...args2) {
return curried.apply(this, args.concat(args2));
}
}
};
}function sum(a, b, c) {
return a + b + c;
}
let curriedSum = curry(sum);
alert( curriedSum(1, 2, 3) ); // 6, 보통때 처럼 단일 callable 형식으로 호출하기
alert( curriedSum(1)(2,3) ); // 6, 첫 번째 인수를 커링하기
alert( curriedSum(1)(2)(3) ); // 6, 모두 커링하기- 새로운 curry는 복잡해 보일 수도 있지만 사실 이해하기는 쉽습니다. curry(func)의 반환값은 curried라는 아래의 래퍼와 같습니다.
// func 이 변환되어야 하는 함수입니다 function curried(...args) { if (args.length >= func.length) { // (1) return func.apply(this, args); } else { return function pass(...args2) { // (2) return curried.apply(this, args.concat(args2)); } } };
- 위의 예시를 실행시키면, 두 개의 if 분기점이 있습니다.
- (1)에 해당하는 경우(함수가 호출되었을때): args 를 카운트한 갯수가 전달된 원래 함수 func (func.length)와 같거나 길다면, 그대로 func 호출에 전달함. (2)에 해당하는 경우(partial이 적용될때): 아직 func이 호출되지 않습니다. pass라는 래퍼가 대신 반환되고, pass 래퍼함수가 curried를 이전함수와 새로운 인수와 함께 다시 적용합니다. 그 다음 새로운 curried 호출에, 다시 새로운 partial (만약에 인수가 충분하지 않으면)을 반환하거나 최종적으로 func 결과를 반환합니다.
- 예를 들면, sum(a, b, c) 예시에서 어떻게 진행되었는지 살펴보세요. 인수가 세 개이므로 sum.length = 3 입니다.
- curried(1)(2)(3)이 호출되는 과정은 다음과 같습니다.
- 첫 번째 curried(1) 을 호출할때 1을 렉시컬 환경에 기억하고 curried(1) 이 pass 래퍼를 반환합니다.
- pass래퍼가 (2)와 함께 호출됩니다. 이전의 인수인 (1)을 가져서 (2)와 연결하고curried (1, 2)를 함께 호출합니다. 인수의 개수는 아직 3보다 작기때문에 curry는 pass를 반환합니다.
- pass 래퍼가 다시 (3)과 함께 호출됩니다. 다음 호출인 pass(3)가 이전의 인수들인 (1, 2)를 가져오고 3을 추가하고 curried(1, 2, 3) 호출을 합니다 – 여기에 3인수는 마지막으로, 원래의 함수에 전달됩니다.
- 위의 예시를 실행시키면, 두 개의 if 분기점이 있습니다.
오직 고정된 길이의 함수들만 사용 가능합니다. 커링은 해당 함수가 고정된 개수의 인수를 가지도록 요구합니다. f(...args)같은 나머지 매개변수를 사용하는 함수는 이러한 방법으로 커리할 수 없습니다.
커링의 정의에 따르면, 커링은 sum(a, b, c)을 sum(a)(b)(c)으로 변환해야 합니다. 그러나 커링의 구현은 자바스크립트에서 고급단계입니다. 이번 챕터에서 알아보았듯이 커링은 다중-인수를 단일 프로세스로 callable 한 함수를 다중 프로세스 형태로 변형할 수 있도록 하는 것입니다.
정리하자면, 커링은 f(a,b,c)를 f(a)(b)(c)와 같이 다중 callable 프로세스 형태로 변환하는 기술입니다. 보통 자바스크립트에서의 커링 되어진 함수는 평소처럼 호출도 하고 만약에 인수들이 충분하지 않을 때에는 partial을 반환합니다. 또한 커링은 partial을 쉽게 적용할 수 있도록 해줍니다. 로그 예시에서 보았듯이 커링을 적용하면 인수 세 개의 범용 함수 log(date, importance, message)를 log(date)같이 인수가 하나인 형태나 log(date, importance)처럼 인수가 두 개인 형태로 호출할 수 있습니다.
둘 다 대상 배열을 순회하지만 가장 큰 차이점은 map 함수가 새로운 배열을 반환한다는 것입니다. 수정된 결과가 필요하지만 원본 배열을 변경하고 싶지 않으면 map 함수를 사용하며, 가독성을 높이며 배열을 순회하고자 한다면 forEach를 사용합니다.
익명함수는 IIFE로 사용되어 지역 범위 내에서 일부 코드를 캡슐화하므로 선언된 변수가 전역 범위로 노출되지 않습니다.
보통 한 번 사용되고 다른 곳에서는 사용할 필요가 없는 콜백으로 사용됩니다. 함수 본체를 찾기 위해 다른 곳을 찾아볼 필요 없이 코드를 호출하는 코드 바로 안에 핸들러가 정의되어 있으면 코드가 보다 독립적이고 읽기 쉽게 보일 것입니다.
모듈 패턴은 여전히 훌륭하지만, 요즘에는 React/Redux 기반의 Flux 아키텍처를 사용합니다. 이 아키텍처는 단방향 프로그래밍 방식을 권장합니다. 저는 평범한 객체를 사용하여 응용 프로그램의 모델을 표현하고 이러한 객체를 조작하는 유틸리티 순수 함수를 작성합니다. 상태는 다른 Redux 응용 프로그램에서와 마찬가지로 action 및 reducer를 사용하여 조작됩니다.
내장 객체는 ECMAScript 사양에 정의된 자바스크립트 언어의 일부인 객체(String, Math, RegExp, Object, Function 등)입니다.
호스트 객체는 window, XMLHTTPRequest 등과 같이 런타임 환경(브라우저 또는 Node)에 의해 제공됩니다.
function Person(){}은 정상적인 함수 선언이며, 이 컨벤션은 생성자 함수로 사용하기 위해 함수 이름에 파스칼 케이스(PascalCase)를 사용합니다. const person = Person()은 생성자가 아니며 Person을 일반 함수로 호출합니다. 따라서 undefined가 반환되고 지정된 변수에 할당됩니다.
const person = new Person()은 Person.prototype을 상속받은 new 연산자를 사용하여 Person 객체의 인스턴스를 생성합니다.
.call과 .apply는 모두 함수를 호출하는데 사용되며, 첫 번째 매개변수는 함수 내에서 this의 값으로 사용됩니다. 그러나 .call은 쉼표로 구분된 인수를 두 번째 인수로 취하고 .apply는 인수의 배열을 두 번째 인수로 취합니다. call은 C: Comma 로 구분되며, apply는 인수 배열인 A: arguments 라고 기억하면 쉽습니다.
bind() 메서드는 호출될 때, this 키워드가 주어진 인자 값으로 설정되고, 새로운 함수가 호출될 때, 앞쪽의 매개변수도 자신의 인자를 사용해 미리 순서대로 채워놓은 새로운 함수를 반환합니다.
document.write()는 document.open()에 의해 열린 문서 스트림에 텍스트 문자열을 씁니다. 페이지가 로드된 후에 document.write()가 실행되면 document.open을 호출하여 문서 전체를 지우고 문자열로 주어진 매개 변수 값으로 대체합니다. 그러므로 일반적으로 위험하고 오용되기 쉽습니다.
document.write()가 코드분석이나 자바스크립트가 활성화된 경우에만 동작하는 스타일을 포함하고 싶을 때 사용되는 경우를 설명하는 온라인 답변이 몇 가지 있습니다. 심지어 HTML5 보일러 플레이트에서 스크립트를 병렬로 로드하고 실행 순서를 보존할 때도 사용된다고 합니다.
Ajax(Asynchronous 자바스크립트 and XML)는 비동기 웹 응용 프로그램을 만들기 위해 클라이언트 측에서 사용되는 웹 개발 기술의 집합입니다.
Ajax를 사용하면 웹 애플리케이션은 기존 페이지의 화면 및 동작을 방해하지 않으면서 백그라운드에서 비동기적으로 서버로 데이터를 보내고 서버에서 데이터를 받아올 수 있습니다. Ajax는 프리젠테이션 레이어에서 데이터 교환 레이어를 분리함으로써, 웹페이지 및 확장 웹 애플리케이션이 전체 페이지를 다시 로드 할 필요 없이 동적으로 컨텐츠를 변경할 수 있도록 합니다.
최근에는 네이티브 자바스크립트의 장점 때문에 XML대신 JSON을 사용하며, 통신 기술은 XMLHTTPRequest API와 fetch API, axios를 많이 활용합니다.
-
장점
- 상호작용성이 좋아집니다. 서버의 새로운 컨텐츠를 전체 페이지를 다시 로드할 필요 없이 동적으로 변경할 수 있습니다.
- 스크립트나 스타일 시트는 한 번만 요청하면 되므로 서버에 대한 연결을 줄여줍니다.
- 상태를 페이지에서 관리할 수 있습니다. 메인 컨테이너 페이지가 다시 로드되지 않기 때문에 자바스크립트의 변수와 DOM의 상태가 유지됩니다.
- 기본적으로 SPA의 대부분의 장점과 같습니다.
-
단점
- 동적 웹 페이지는 북마크하기 어렵습니다.
- 브라우저에서 자바스크립트가 비활성화된 경우 동작하지 않습니다.
- 일부 웹 크롤러는 자바스크립트를 실행하지 않으며 자바스크립트에 의해 로드된 콘텐츠를 볼 수 없습니다.
- SPA의 대부분의 단점과 같습니다.
호이스팅은 코드에서 변수 선언의 동작을 설명하는데 사용되는 용어입니다.
var 키워드로 선언되거나 초기화된 변수는 현재 스코프의 최상위까지 끌어 올려집니다. 이것을 호이스팅이라고 부릅니다. 그러나 선언문만 호이스팅되며 할당은 그대로 존재하죠.
사실 선언은 실제로 이동되지 않습니다. 자바스크립트 엔진은 컴파일 중에 선언을 파싱하고 선언과 해당 스코프를 인식합니다. 선언을 해당 스코프의 맨 위로 옮겨지는 것으로 생각하여 동작을 이해하는 것이 더 쉬울 뿐입니다.
함수 선언은 함수몸체가 호이스팅되는 반면, 변수 선언 형태로 작성된 함수 표현식은 변수 선언만 호이스팅됩니다.
attribute는 HTML 마크업, property는 DOM에 정의됩니다.
내장/네이티브 자바스크립트 객체를 확장한다는 것은 prototype에 속성/함수를 추가한다는 것을 의미합니다. 이것은 처음에는 좋은 생각처럼 보일 수 있지만 실제로는 위험합니다. Array.prototype을 확장하는 여러가지 라이브러리를 사용한다면 메서드를 서로 덮어쓰게 되어 메서드의 동작에서 예상치 못한 에러가 발생할 수 있습니다.
네이티브 객체를 확장할 수 있는 유일한 경우는 폴리필(polyfill)을 만들 때입니다. 자바스크립트 사양의 일부이지만, 오래된 브라우저이기 때문에 사용자 브라우저에 없을 수도 있는 메서드에 대한 고유한 구현을 제공해야할 경우 뿐입니다.
window의 document.load 이벤트는 DOM과 모든 종속 리소스와 에셋들이 로드된 후에 발생합니다.
DOMContentLoaded 이벤트는 스타일시트, 이미지, 서브프레임 로딩을 기다리지 않고 초기 HTML 문서가 완전히 로드되고 파싱되면 발생합니다.
==는 추상 동등 연산자이고 ===는 완전 동등 연산자입니다.
==연산자는 타입 변환이 필요한 경우 타입 변환을 한 후에 동등한지 비교할 것입니다. ===연산자는 타입 변환을 하지 않으므로 두 값이 같은 타입이 아닌 경우 ===는 false를 반환합니다. 편의상 null과 undefined를 비교할 때를 제외하면 == 연산자를 절대 사용하지 않아야 합니다.
동일 출처 정책(Same-origin Policy)은 자바스크립트가 도메인 경계를 넘어서 요청하는 것을 방지합니다.
어떤 출처에서 불러온 문서나 스크립트가 다른 출처에서 가져온 리소스와 상호작용하는 것을 제한하는 중요한 보안 방식입니다. 동일 출처 정책은 잠재적으로 해로울 수 있는 문서를 분리해, 공격받을 수 있는 경로를 줄입니다.
origin이란 요청을 보낸 도메인을 의미하며, 같은 도메인으로 요청을 보내지 않으면 동일 출처 정책에 의해 에러와 맞닥뜨립니다. 물론 외부 API를 사용하거나 서버-클라이언트 통신 시 많은 불편함이 존재하는데, 이를 해결하기 위해 등장한 것이 CORS(Cross-Origin Resource Sharing) 정책입니다.
"use strict";는 전체 스크립트나 개별 함수에 엄격 모드를 사용하는데 사용되는 명령문입니다.
대표적으로는 아래와 같습니다.
- 선언하지 않은 변수를 참조하면 ReferenceError가 발생합니다.
- delete 연산자로 변수/함수/매개변수를 삭제하면 SyntaxError가 발생합니다.
- 삭제할 수 없는 속성을 삭제하려고 시도합니다. (시도 효과가 없을 때까지)
- 함수의 매개변수에 중복된 이름을 사용하면 SytaxError가 발생합니다.
- 일반 함수로 호출하면 this에 undefined가 바인딩됩니다.
- 매개변수에 전달된 인수를 재할당하여 변경해도 반영되지 않습니다.
모듈 패턴(IIFE)을 사용하여 변수를 로컬 네임스페이스 내에 캡슐화 하는 것이 바람직합니다.
모든 스크립트는 전역 스코프에 접근할 수 있으며, 모든 사람이 전역 네임스페이스를 사용하여 변수를 정의하면 충돌이 발생할 수 있기 때문입니다.
load 이벤트는 문서로딩 프로세스가 끝날 때 발생됩니다. 이 시점에서 문서의 모든 객체가 DOM에 있고, 모든 이미지, 스크립트, 링크 및 하위 프레임로딩이 완료됩니다.
DOM 이벤트 DOMContentLoaded는 페이지의 DOM이 생성된 후에 발생하지만 다른 리소스가 로딩되기를 기다리지 않습니다. 이것은 초기화되기 전에 전체 페이지가 로드될 필요가 없는 경우에 선호됩니다.
웹 개발자는 요즘 웹 사이트가 아닌 웹 앱으로 제작한 제품을 언급합니다. 두 가지 용어 사이에는 엄격한 차이는 없지만, 웹 앱은 대화형, 동적인 경향이 있어 사용자가 작업을 수행하고 작업에 대한 응답을 받을 수 있습니다. 전통적으로, 브라우저는 서버에서 HTML을 받아 렌더링합니다. 사용자가 다른 URL로 이동하면, 전체페이지 새로고침이 필요하며 서버는 새페이지에 대해 새 HTML을 보냅니다. 이를 server-side rendering이라고합니다.
그러나 현대 SPA에서는 대신 client-side rendering이 사용됩니다. 브라우저는 전체 애플리케이션에 필요한 스크립트(프레임워크, 라이브러리, 앱 코드) 및 스타일시트와 함께 서버의 초기 페이지를 로드합니다. 사용자가 다른 페이지로 이동하면 페이지 새로고침이 발생하지 않습니다. 페이지의 URL은 HTML5 History API를 통해 업데이트됩니다. 일반적으로 JSON 형식의 새 페이지에 필요한 새 데이터는 브라우저에서 AJAX 요청을 통해 서버로 전송됩니다. SPA는 초기 페이지 로딩에서 미리 다운로드된 자바스크립트를 통해 페이지를 동적으로 업데이트합니다. 이 모델은 네이티브 모바일 앱의 동작 방식과 유사합니다.
-
장점
- 전체 페이지 새로고침으로 인해 페이지 탐색 사이에 하얀 화면이 보이지 않아 앱이 더 반응적으로 느껴지게 됩니다.
- 동일한 애셋을 페이지 로드마다 다시 다운로드할 필요가 없으므로 서버에 대한 HTTP 요청이 줄어듭니다.
- 클라이언트와 서버 사이의 고려해야 할 부분을 명확하게 구분합니다. 서버 코드를 수정하지 않고도 다양한 플랫폼(예: 모바일, 채팅 봇, 스마트워치)에 맞는 새로운 클라이언트를 쉽게 구축할 수 있습니다. 또한 API 규약이 깨지지 않는 한도 내에서 클라이언트와 서버에서 기술 스택을 독립적으로 수정할 수 있습니다.
-
단점
- 여러 페이지에 필요한 프레임워크, 앱 코드, 애셋로드로 인해 초기 페이지 로드가 무거워집니다.
- 모든 요청을 단일 진입점으로 라우트하고 클라이언트 측 라우팅이 그 한곳에서 인계받을 수 있도록 서버를 구성하는 추가 단계가 필요합니다.
- SPA는 콘텐츠를 렌더링하기 위해 자바스크립트에 의존하지만 모든 검색 엔진이 크롤링 중에 자바스크립트를 실행하지는 않으며 페이지에 빈 콘텐츠가 표시될 수 있습니다. 이로 인해 의도치 않게 앱의 검색 엔진 최적화(SEO)가 어려워집니다. 그러나 대부분의 경우 앱을 제작할 때 검색 엔진에서 모든 콘텐츠 색인할 필요는 없으므로 SEO가 가장 중요한 요소는 아닙니다. 이를 극복하기 위해, 앱을 서버 측 렌더링하거나 Prerender와 같은 서비스를 사용하여 "브라우저에서 자바스크립트를 렌더링하고, 정적 HTML을 저장한 다음, 크롤러에게 반환합니다".
Promise는 어느 시점에 resolve된 값 또는 resolve되지 않은 이유(예: 네트워크 오류가 발생) 중 하나의 값을 생성할 수 있는 객체입니다. promise는 fulfilled, rejected, pending 3가지 상태 중 하나일 수 있습니다. promise 사용자는 콜백을 붙여서 fulfill된 값이나 reject된 이유를 처리할 수 있습니다.
ES2015는 즉시 사용할 수 있는 Promise를 지원하며 일반적으로 요즘엔 polyfill이 필요하지 않습니다.
-
장점
- 가독성이 떨어질 수 있는 콜백 지옥을 피할 수 있습니다.
- .then()을 이용하여 가독성 좋은 연속적인 비동기 코드를 쉽게 작성할 수 있습니다.
- Promise.all()을 사용하여 병렬 비동기 코드를 쉽게 작성할 수 있습니다.
- Promise를 통해 콜백만 사용하는 코딩 방식에 있는 다음과 같은 상황이 발생하지 않습니다.
- 콜백을 너무 빨리 호출
- 콜백을 너무 늦게 호출하거나 미호출
- 콜백을 너무 적게 호출하거나 너무 많이 호출
- 필요한 환경/매개변수를 전달하는데 실패
- 발생가능한 오류/예외를 무시
-
단점
- 약간 더 복잡한 소스코드(개인적인 생각입니다).
- ES2015를 지원하지 않는 이전 브라우저에서 이를 사용하기 위해서는 polyfill을 로드해야 합니다.
-
오브젝트의 경우:
- for-in 반복 : for (var property in obj) { console.log(property); }. 그러나, 이는 상속된 속성도 반복되며, 사용하기 전에 obj.hasOwnProperty(property) 체크를 추가해야 합니다.
- Object.keys() : Object.keys(obj).forEach(function (property) { ... }). Object.keys()는 전달하는 객체의 열거 가능한 모든 속성을 나열하는 정적 메서드입니다.
- Object.getOwnPropertyNames() : Object.getOwnPropertyNames(obj).forEach(function (property) { ... }). Object.getOwnPropertyNames()는 전달하는 객체의 열거 가능한 속성과 열거불가능한 모든 속성을 나열하는 정적 메서드입니다.
-
배열의 경우:
- for 반복 : for (var i = 0; i < arr.length; i++). 여기에 있는 일반적인 함정은 var이 함수 스코프고 블록 스코프가 아니며, 대부분 블록 스코프의 반복자 변수를 원할 것이라는 점입니다. ES2015에는 블록 범위가 있는 let이 추가됐고, 이를 대신 사용할 것을 권장합니다. 그래서 다음과 같이 됩니다. for (let i = 0; i < arr.length; i++).
- forEach : arr.forEach(function (el, index) { ... }). 필요한 것이 배열의 요소라면 index를 사용할 필요가 없기 때문에 이 구문이 더 편리 할 수 있습니다. 또한 every과 some메서드를 이용하여 반복을 일찍 끝낼 수 있습니다.
- for-of 반복 : for (let elem of arr) { ... }. ES6는 String, Array, Map, Set 등과 같은 iterable protocol을 준수하는 객체를 반복 할 수 있게 해주는 새로운 for-of 루프를 도입했습니다. for 루프의 장점은 루프에서 벗어날 수 있다는 것이고, forEach()의 장점은 카운터 변수가 필요 없기 때문에 for 루프보다 간결하다는 것입니다. for-of 루프를 사용하면, 루프에서 빠져 나올 수도 있고 더 간결한 구문도 얻을 수 있습니다.
대부분의 경우에 저는 .forEach 메서드를 선호하지만, 무엇을 하느냐에 따라서 각 상황에 맞게 사용하는 것이 좋습니다. ES6 이전에는 for 루프를 사용하여 루프를 조기 종료해야 할 때 break를 사용했습니다. 그러나 이제 ES6에서는 for-of루프를 사용하여 이를 수행 할 수 있습니다. 루프 당 반복자를 두 번 이상 늘리는 것과 같이 유연성이 더 필요하다면, for 루프를 사용할 것입니다.
또한, for-of 루프를 사용할 때 각 배열 요소의 인덱스와 값에 모두 접근해야하는 경우 ES6 Array의 entries() 메서드와 destructuring을 사용하면됩니다.
- 자바스크립트에서 immutable 객체의 예는 무엇인가요?
- Immutability의 장점과 단점은 무엇인가요?
- 자신의 코드에서 어떻게 immutability를 얻을 수 있나요?
동기 함수는 블로킹(Bloking)인 반면, 비동기 함수는 논-블로킹(non-Bloking)입니다.
동기 함수에서는 다음 명령문이 실행되기 전에 앞 명령문이 완료됩니다. 이 경우, 프로그램은 명령문의 순서대로 정확하게 평가되고 명령문 중 하나가 매우 오랜 시간이 걸리면 프로그램 실행이 일시중지됩니다.
비동기 함수는 일반적으로 파라미터를 통해서 콜백을 받고, 비동기 함수가 호출된 후 즉시 다음 줄 실행이 계속됩니다. 콜백은 비동기 작업이 완료되고 호출 스택이 비어 있을 때만 호출됩니다. 웹 서버에서 데이터를 로드하거나 데이터베이스를 쿼리하는 등의 무거운 작업을 비동기식으로 수행하여, 메인 스레드가 긴 작업을 완료할 때까지 블로킹하지 않고 다른 작업을 계속할 수 있습니다(브라우저의 경우 UI가 중지됨).
이벤트 루프는 콜 스택을 모니터하고 태스크 큐에서 수행할 작업이 있는지 확인하는 단일 스레드 루프입니다. 콜 스택이 비어 있고 태스크 큐에 콜백 함수가 있는 경우, 함수는 큐에서 제거되고 실행될 콜 스택으로 푸시됩니다.
Philip Robert의 talk on the Event Loop를 아직 확인하지 않은 경우 확인하십시오. 자바스크립트 분야에서 가장 많은 조회수를 기록한 동영상 중 하나입니다.
전자는 함수 선언인 반면, 후자는 함수 표현식입니다. 주요한 차이점은 함수 선언은 함수바디가 호이스트되지만, 함수 표현식의 바디는 호이스트되지 않습니다(변수와 동일한 호이스팅 동작을 가짐). 호이스팅에 대한 자세한 설명은 질문 위의 호이스팅을 참조하십시오. 함수 표현식을 정의하기 전에 호출하려고 하면 Uncaught TypeError : XXX is not function 에러가 발생합니다.
var 키워드로 선언한 변수가 가진 문제점은 아래와 같습니다.
- 변수 중복 선언
허용 - 함수 레벨 스코프,
function() {} - 변수 호이스팅으로
변수 선언문 이전에 참조가 가능하며, 할당문 이전에 참조 시 undefined를 반환 전역 변수,전역 함수, 선언하지 않은 변수에 값을 할당한암묵적 전역은 전역 객체 window의 프로퍼티에 할당
이런 이유로 가독성, 개발자의 의도가 흐려지게 되었고 결국 let과 const가 등장하게 됩니다.
ES6에 추가된 블록 레벨 스코프의 재할당이 가능한 키워드입니다.
let 키워드로 선언한 변수는 var 키워드를 대체할 수 있으며, 아래와 같은 특징을 갖습니다.
- 변수 중복 선언
금지, 중복 선언 시 문법 에러(SyntaxError) 발생 - 함수 레벨 스코프,
function() {}, if 문, for 문, while 문, try/catch 문 등 - 변수 호이스팅이
발생하지 않는것처럼 동작 - 전역 객체 window의 프로퍼티가 아니며 let 전역 변수는
보이지 않는 개념적 블록(전역 렉시컬 환경의 선언적 환경 레코드)내에 존재
var 키워드로 선언한 변수는 런타임 이전에 자바스크립트 엔진에 의해 암묵적으로 선언 단계와 초기화 단계가 동시에 진행되는 반면 let, const 키워드로 선언한 변수는 선언 단계와 초기화 단계가 분리되어 진행됩니다.
ES6에 추가된 블록 레벨 스코프의 재할당 불가능한 상수(constant)를 선언하는 키워드입니다.
const 키워드는 기본적으로 let과 동일하게 동작합니다. 다른 점은 반드시 선언과 동시에 초기화해야 한다는 것이에요.
구문이 단순화 되었으며, 비슷한 동작을 하는 것처럼 보입니다. 이는 ES6의 클래스는 함수이며 기존 프로타입 기반 패턴에 문법적 설탕(Syntactic sugar)이기 떄문이죠.
- 클래스는 클래스 선언문 이전에 참조할 수 없습니다.
- 클래스는 클래스 내부의 캡슐화된 변수, 클래스 필드(Class Field) 를 가집니다.
- 클래스 필드에는 메서드만 선언할 수 있습니다.
- getter/setter로 클래스 필드의 값을 참조하거나, 조작할 수 있습니다.
- 정적(static) 메서드를 정의할 수 있으며, 클래스 인스턴스가 아니라 클래스 이름으로 호출할 수 있습니다.
- extends 키워드로 클래스를 상속(Class Inheritance) 할 수 있습니다.
화살표 함수의 한 가지 분명한 이점은 function 키워드를 사용하지 않고도 함수를 생성하는데 필요한 문법을 단순화하는 것입니다.
화살표 함수 내의 this는 일반 함수와 다르게 주변 스코프에 바인딩됩니다. 이는 특히 React 컴포넌트에서 콜백을 호출할 때 유용합니다. 결국 화살표 함수 도입에 영향을 준 두 요소는 보다 짧아진 함수와 및 바인딩하지 않은 this입니다.
- this나 super에 대한 바인딩이 없고, 메서드로 사용될 수 없습니다.
- new.target 키워드가 없습니다.
- 일반적으로 스코프를 지정할 때 사용하는 call, apply, bind 메서드를 이용할 수 없습니다.
- 생성자(Constructor)로 사용할 수 없습니다.
- yield를 화살표 함수 내부에서 사용할 수 없습니다.
화살표 함수는 자신의 this가 없습니다. 대신 화살표 함수를 둘러싸는 렉시컬 범위(lexical scope)의 this가 사용됩니다. 화살표 함수는 일반 변수 조회 규칙(normal variable lookup rules)을 따릅니다. 때문에 현재 범위에서 존재하지 않는 this를 찾을 때, 화살표 함수는 바로 바깥 범위에서 this를 찾는 것으로 검색을 끝내게 됩니다.
생성자 내부에서 화살표 함수를 메서드로 사용하는 주된 장점은, 함수 생성시 this의 값이 설정되고 그 이후에는 변경할 수 없다는 것입니다.
따라서, 생성자가 새로운 객체를 생성하는데 사용될 때, this는 항상 그 객체를 참조할 것입니다.
여기에서 주요 장점은 this는 일반 함수에 대해 변경될 수 있지만, 컨텍스트는 항상 화살표 함수에 대해 동일하게 유지된다는 것입니다. 따라서 화살표 함수를 앱의 다른 부분으로 전달하는 경우에도 컨텍스트 변경에 대해 걱정할 필요가 없습니다.
이는 특히 React 클래스 컴포넌트에서 유용할 수 있습니다. 일반 함수를 사용하는 클릭 핸들러와 같은 클래스 메서드를 정의한 다음, 해당 클릭 핸들러를 하위 컴포넌트의 prop으로 전달하면 상위 컴포넌트의 생성자에서 this도 바인드해야합니다.
대신 화살표 함수를 사용하면, 메서드가 this값을 주위 렉시컬 컨텍스트에서 자동으로 가져오기 때문에 this를 바인딩할 필요가 없습니다.
고차 함수(higher-order function)는 다른 함수를 매개 변수로 사용하여 어떤 데이터를 처리하거나, 결과로 함수를 반환하는 함수입니다.
고차 함수는 반복적으로 수행되는 어떤 연산을 추상화하기 위한 것입니다. 전형적인 예시는 배열과 함수를 인수로 취하는 map입니다. map은 고차 함수를 사용하여 배열의 각 항목을 변환하고, 변환된 데이터로 새로운 배열을 반환합니다. 자바스크립트에서 흔히 볼 수 있는 다른 예로 forEach, filter, reduce가 있습니다. 다른 함수에서 함수를 반환하는 많은 사용사례가 있기 때문에 고차 함수는 배열을 조작할 필요가 없습니다. Array.prototype.bind는 자바스크립트에서 그러한 예시 중 하나입니다.
디스트럭쳐링은 ES6에서 사용할 수 있는 표현식으로 객체나 배열의 값을 추출하여 다른 변수에 배치하는 간결하고 편리한 방법을 제공합니다.
템플릿 리터럴을 사용하면 문자열 보간을 하거나 문자열에 변수를 포함하는 작업을 간단하게 수행할 수 있습니다. ${} 안에 표현식을 삽입할 수 있다는 것을 나타내기 위해 따옴표(')가 아닌 백틱(`)을 사용하며, 다중행 문자열을 만든다면 템플릿 리터럴은 당신이 추가한 간격 그대로 유지됩니다. 마지막으로 템플릿 리터럴의 또 다른 사용사례는 간단한 변수 보간을 위한 템플릿 라이브러리의 대체품으로 사용하는 것입니다.
currying은 둘 이상의 매개 변수가 있는 함수가 여러 함수로 분리된 패턴으로, 직렬로 호출하면, 필요한 모든 매개 변수가 한 번에 하나씩 누적됩니다. 이 기법은 함수형 스타일로 작성된 코드를 읽고, 합성하기 더 쉬워진 경우 유용할 수 있습니다. 함수를 currying하려면 하나의 함수로 시작하여 하나의 매개 변수를 취하는 일련의 함수로 분리해야 합니다.
spread 문법의 경우 Object.create, slice나 라이브러리 함수를 사용하지 않고도 배열이나 객체의 복사본을 쉽게 만들 수 있습니다. 이 언어 기능은 Redux나 RxJS를 사용하는 프로젝트에서 많이 사용됩니다.
ES6의 rest 구문은 함수에 전달할 임의의 수의 인수를 포함하는 약식을 제공합니다. 이는 데이터의 배열을 채우기보다는 데이터를 가져와서 배열로 채우는 spread 구문의 반대와 비슷하며, 배열이나 객체 디스트럭쳐링 할당뿐만 아니라 함수 인수에서도 동작합니다.
호스트 환경에 따라 다릅니다.
클라이언트(브라우저 환경)에서는, 변수/함수가 전역 스코프(window)에 선언되어있는 한 모든 스크립트가 이를 참조할 수 있습니다. 또는, 모듈형 접근 방식을 위해 RequireJS를 통해 비동기 모듈 정의(AMD)를 이용합니다.
서버(Node.js)에서 일반적인 방법은 CommonJS를 사용하는 것입니다. 각 파일은 모듈로 취급되며, 변수와 함수를 module.exports 객체에 붙여서 내보낼 수 있습니다.
ES2015에서는 AMD 및 commonJS를 모두 대체하기 위한 모듈 문법을 정의합니다. 이 기능은 브라우저 및 노드 환경 모두에서 지원됩니다.
정적 클래스 멤버(속성/메서드)는 클래스의 특정 인스턴스와 묶이지 않으며, 어떤 인스턴스가 이를 참조하는지에 관계없이 동일한 값을 가집니다. 정적 속성은 일반적으로 설정(configuration) 변수이며 정적 메서드는 일반적으로 인스턴스의 상태에 의존하지 않는 순수 유틸리티 함수입니다.
자기 참조 변수(self-referencing variable)로 자신이 속한 객체 또는 자신이 생성할 인스턴스를 가리킵니다.
- 자바스크립트 엔진에 의해 암묵적으로 생성됩니다.
- 따라서 어디서든 참조할 수 있습니다.
- 함수를 호출하면 arguments 객체와 this가 암묵적으로 전달됩니다.
- this도 지역변수처럼 사용할 수 있습니다.
- this가 가리키는 값, this 바인딩은 함수 호출 방식에 따라 동적으로 결정됩니다.
특정 코드의 연산이 끝날 때까지 코드의 실행을 멈추지 않고 다음 코드를 먼저 실행하는 자바스크립트 특성입니다.
자바스크립트는 싱글 스레드 언어입니다. 따라서 동기식으로 코드를 처리하면 요청-응답이 필요한 항목에서 지연(Blocking)이 발생할 수 있습니다. 따라서 자바스크립트는 몇몇 비동기 처리 방식을 지원하며, 아래에 하나씩 소개합니다.
보통 화면에 표시할 이미지나 데이터를 서버에서 불러와 표시할 때 제이쿼리(jQuery)의 경우 ajax 통신으로 해당 데이터를 서버로부터 가져올 수 있습니다.
ajax 통신을 시도하면 데이터를 요청하고 받아올 때까지 기다려주지 않고 다음 코드를 실행합니다. 이렇게 특정 로직의 실행이 끝날 때까지 기다려주지 않고 나머지 코드를 먼저 실행하는 것이 비동기 처리입니다.
화면에서 서버로 데이터를 요청했다고 서버가 언제 응답을 줄 지는 확실치 않습니다. 만약 이를 마냥 기다리면(동기 처리) 다른 코드들은 그대로 멈춰지게 돼죠. 즉, 비동기 처리가 아니라면 애플리케이션 동작에 많은 지연이 생깁니다.
setTimeout()은 Web API의 하나로서 코드를 바로 실행하지 않고 지정한 시간만큼 기다렸다가 로직을 실행합니다.
ajax, setTimeout의 경우 이들이 실행되는 시점을 확인하여 코드를 작성할 수 없었습니다.
필요한 데이터를 받아와서 처리해야하는 경우, 데이터가 아니라 자꾸 undefined가 뜰 수도 있었죠. 이를 어떻게 해결했을까요? 바로 콜백(callback) 함수를 활용하는 것이었습니다.
콜백 함수를 사용하면 특정 로직이 끝났을 때 원하는 동작을 실행시킬 수 있습니다. 어떤 행위가 종료되면 이어서 무언가를 하는 걸 콜백 함수라고 생각하면 쉬워요. 그러나 이 콜백 함수는 충분히 문제를 야기할 수 있었습니다.
예를 들어 웹 서비스를 개발하다 보면 서버에서 데이터를 받아와 화면에 표시하기까지 인코딩, 사용자 인증 등을 처리해야 하는 경우가 있습니다. 만약 이 모든 과정을 비동기로 처리해야 한다고 하면 위와 같이 콜백 안에 콜백을 계속 무는 형식으로 코딩을 하게 됩니다. 이러한 코드 구조는 가독성도 떨어지고 로직을 변경하기도 어렵습니다. 이와 같은 코드 구조를 콜백 지옥이라고 합니다.
이를 개선하기 위해 등장한 것이 프로미스(Promise), async/await와 같은 문법입니다.
Promise를 더욱 쉽게 사용할 수 있도록 ES2017(ES8) 문법으로 함수의 앞부분에 async 키워드를 추가하고, 함수 내부에서 Promise의 앞부분에 await 키워드를 사용합니다. async, await를 사용할 경우 코드가 간결해지지만, 에러처리를 잡기 위해 try catch를 사용해야합니다. 동기적인 코드흐름으로 개발이 가능합니다.
다른 언어에는 int, double, float 등 다양한 숫자 타입이 존재하지만 자바스크립트는 Number 하나만 있습니다.
자바스크립트의 코드들이 실행되기 위한 환경 전역 컨텍스트, 함수 컨텍스트 2가지 존재 전역 컨텍스트 하나 생성 후에 함수 호출할 때마다 함수 컨텍스트가 생성 컨텍스트를 생성시에 변수객체, 스코프 체인, this가 생성된다. 컨텍스트 생성 후 함수가 실행되는데 사용되는 변수들은 변수 객체 안에서 값을 찾고 없다면 스코프체인을 따라 올라가며 찾음. 함수 실행이 마무리되면 해당 컨텍스트는 사라짐. 페이지가 종료되면 전역 컨텍스트가 사라짐 즉, 자바스크립트의 코드가 실행되기 위해서는 변수객체, 스코프체인, this 정보들을 담고 있는 곳을 실행컨텍스트라고 부른다.
변수를 선언하고 초기화 했을때 선언부분이 최상단으로 끌어올려지는 현상 예를들어, 코드 상단에서 console.log(a)를 찍고 하단에서 var a=1; 이라고 하였을때 a는 undefined라고 나온다. 이런 현상을 호이스팅이라고한다. 함수의 경우 함수표현식은 호이스팅이 적용되지 않으나 일반 함수선언문은 함수 호이스팅이 적용된다.
내부 함수가 외부 함수보다 오래 유지되는 경우, 내부 함수는 종료된 외부 함수의 변수를 참조할 수 있게 되고 이를 클로저(Closure)라 부릅니다.
상태(State)를 안전하게 은닉하고 특정 함수에게만 상태 변경을 허용하기 위해 사용합니다. 클로저는 자신만의 독립된 렉시컬 환경을 갖으므로 상태(State)가 의도치 않게 변경되지 않도록 안전하게 정보를 은닉하고 특정 함수에게만 상태 변경을 허용할 수 있습니다.
동적 할당된 메모리 영역 가운데 더 이상 사용할 수 없게 된 영역을 탐지하여 자동으로 해제합니다. 더 이상 사용할 수 없게 된 영역은 어떤 변수도 가리키지 않게 된 영역을 의미하죠.
메모리 할당을 추적하고 할당된 메모리 영역이 필요하지 않은 영역일 경우를 판단해서 회수하는 것. 자바스크립트에서 변수는 직접적으로 참조 값(문자열, 객체, 배열 등)을 담고 있지 않고, 해당 값을 메모리 상에 저장 된다. 그래서 참조 값을 생성하고나서 더이상 참조할 것이 없거나 비어졌을 때 가비지 컬렉터가 동작해서 메모리가 반환됨.(메모리를 다시 재사용할 수 있는 상태가 된다) 자바스크립트의 순환참조란? 어떤게 문제이고 해결방법은?
위와 같이 서로 순환되어서 참조되어져서 가비지컬렉터가 동작하지 않고 메모리 누수가 발생된다. null을 할당해서 연결을 끊는 방법을 사용한다. 대부분의 브라우저에서는 Mark and sweep알고리즘을 사용. 그래서 가비지컬렉터가 참조되지 않는 객체가 있을 때 동작하는 것이 아니라 접근 할 수 없는(닿을 수 없는) 객체 일 때 동작한다.
자바스크립트의 배열은 실제 자료구조의 배열과 다르게 HashMap으로 구현되어있다. 이 HashMap을 구현하기 위해서는 연결리스트로 구현하게 되는데 연결리스트에서 값을 찾기 위해서는 탐색해나가면서 값을 찾는 불상사가 발생한다. 이를 해결하기 위해서 타이핑된배열(Int8Array,Float32Array 등) 이 추가되고 있다.
자바스크립트는 싱글 스레드 기반 언어이다. 함수를 실행하면 함수 호출이 스택에 순차적으로 쌓이고 스택의 맨위에서부터 아래로 한번에 하나의 함수만 처리 할 수 있다.
하지만, 자바스크립트에는 이벤트 루프라는것을 통해 동시성을 지원한다. (동시에 일어나는 것이 아니라 동시에 일어나는 것처럼 보이게 하는것이다!)
이벤트 루프는 콜 스택에서 실행 중인 게 있는지 확인하고, Event queue에 작업이 있는지 확인해서 콜스택이 비어있다면 이벤트큐 내의 작업이 콜스택으로 이동되어서 실행된다.
자바스크립트는 프로토타입을 기반으로 상속을 구현하여 불필요한 중복을 제거(중복 제거 방법은 기존의 코드를 재사용하는것!!) 즉, 생성자 함수가 생성할 모든 인스턴스가 공통적으로 사용할 프로퍼티나 메서드를 프로토타입에 미리 구현해 놓음으로써 또 구현하는것이 아니라 상위(부모) 객체인 프로토타입의 자산을 공유하여 사용할 수 있다. proto 접근자 프로퍼티로 자신의 프로토타입, 즉 Prototype 내부슬롯에 접근 할 수 있음. 프로토타입체인이란? 객체의 프로퍼티에 접근하려고 할때 객체에 접근하려는 프로퍼티가 없으면, __proto__접근자 프로퍼티가 가리키는 링크를 따라 자신의 부모역할을 하는 프로토타입의 프로퍼티를 순차적으로 검색한다. 프로로타입체인의 최상위 객체는 Object.prototype이다. 이 객체의 프로퍼티와 메서드는 모든 객체에게 상속된다. prototype 프로퍼티 는 생성자함수가 생성할 인스턴스의 프로토타입을 가르킨다.
자바스크립트의 내부함수는 일반 함수, 메서드, 콜백함수 어디에서 선언되었든지 this는 전역객체를 가르킴 일반함수의 this는 window(전역)을 가르키며, 화살표 함수의 this는 언제나 상위스코프의 this를 가르킴
3가지 방법은 this를 바인딩하기 위한 방법이다. Call은 this를 바인딩하면서 함수를 호출하는 것, 두번째 인자를 apply와 다르게 하나씩 넘기는 것 Apply는 this를 바인딩하면서 함수를 호출하는 것, 두번째인자가 배열 Bind는 함수를 호출하는 것이 아닌 this가 바인딩 된 새로운 함수를 리턴함.
일반함수에서의 this는 undefined가 바인딩 됨.
트랜스파일러를 적극 도입합니다. 바벨로 문법을 변환하고, 폴리필로 부족한 함수를 내포시킵니다.
this 바인딩의 불편함이 해소되었고 순수 함수의 구현이 쉬워졌습니다.
동일한 식별자명으로 프로퍼티를 선언할 경우 value를 생략하는 단축 표기법이 도입되었고, 메서드를 간소화하여 추가할 수 있습니다.
그에 따라 객체 리터럴 및 클래스 선언이 더 밀접되어져, 객체 기반 설계가 더 편리해졌습니다.
문자열로 식별자와 연산을 표현하기 쉬워졌습니다.
인젝션 공격 방어 혹은 문자열로 부터 상위 데이터 구조체 재조립 등을 위해 string 생성을 커스터마이징이 가능하게끔 해줍니다.
객체와 배열에서 필요한 값을 선택하는 것이 편해졌습니다.
구조 분해 할당(Destructuring)은 배열과 객체에 패턴 매칭을 통한 데이터 바인딩을 제공합니다. 할당 실패 시 undefined 값이 자동적으로 할당됩니다.
클래스(Class)로 포로토타입 기반 객체 지향 패턴을 더 쉽게 사용할 수 있습니다.
클래스 패턴 생성을 더 쉽고 단순하게 생성할 수 있어서 사용하기도 편하고 상호운용성도 증가됩니다.
파라미터에 기본 값을 설정할 수 있으며, 가변 인자를 사용하여 배열로 치환 가능하고 배열의 인자를 나누어 주입합니다.
새로운 스코프를 갖는 let, const를 도입하여 var의 문제점을 해소합니다.
반복자(Iterator)는
for ... of문을 사용할 수 있게 해주며, 이는for ... in문과는 다르게 동작합니다.
제네레이터(Generators)는
function*과yield 키워드를 이용하여 반복자(Iterator) 선언을 단순하게 작성할 수 있게 도와줍니다.function*으로 선언한 함수는 제네레이터 객체를 반환합니다. 제네레이터는 반복자의 하위 타입이며 next와 throw 메서드를 가지고 있습니다. 이 메서드들로 인해 yield 키워드로 반환된 값은 다시 제네레이터에 주입하거나 예외 처리를 할 수 있게 되었습니다. 해당 키워드는 비동기 프로그래밍의async/await같은 기능이 가능합니다.
컴포넌트 정의를 위한 모듈을 지원하며 유명한 자바스크립트 모듈 로더들(AMD, CommonJS)의 패턴을 적용시켰습니다.
런타임 동작은 호스트에 정의된 기본 로더에 의해 정의됩니다. 묵시적 비동기 형태로 요구되는 모듈들이 정상적으로 로드되기 전까지 코드가 실행되지 않습니다.
기본적으로 사용할 모듈 로더를 설정할 수 있으며, 로더를 새로 생성하여 격리되거나 제한된 맥락에서 코드를 로드할 수 있습니다.
아래와 같은 행위가 가능합니다.
- 동적 로딩(Dynamic loading)
- 상태 격리(State isolation)
- 전역 네임스페이스 격리(Global namespace isolation)
- 컴플레케이션 훅(Compilation hooks)
- 중첩 가상화(Nested virtualization)
일반 알고리즘을 위한 효율적인 데이터 구조를 제공합니다.
WeakMap과 WeakSet는 메모리 누수로 부터 자유롭게 해줍니다. 이들 내 저장된 객체에 다른 참조가 없는 경우, 가비지 콜렉션(Garbage Collection)의 대상이 될 수 있습니다.
프록시(Proxy)를 사용하여 호스트 객체에 다양한 기능을 추가한 체를 생성할 수 있습니다. interception, 객체 추상화, 로깅/수집, 값 검증 등에 사용될 수 있습니다.
심볼(Symbol)은 객체 상태의 접근 제어를 가능하게 합니다.
심볼은 새로운 원시 타입으로 이름 충돌의 위험 없이 속성(property)의 키(key)로 사용할 수 있습니다. 옵션 파라미터인 description는 디버깅 용도로 사용되며 식별 용도는 아닙니다. 또한 심볼은 고유(unique)하며, Object.getOwnPropertySymbols과 같은 리플렉션(Reflection) 기능들로 접근할 수 있기 때문에 private 하진 않습니다(단, for ... in문이나 Object.keys()로는 접근할 수 없어요).
ES6에서 Array, Date, DOM Element 같이 내장 객체들은 상속이 가능합니다.
객체 생성 시 호출되는 Ctor 함수는 다음의 2단계를 가집니다(둘 다 가상적으로 실행).
- 객체 할당을 위해
Ctor[@@create]호출하여 새로운 인스턴스의 생성자를 호출해 초기화 진행 @@create심볼은Symbol.create를 통해 만들어졌습니다.
core Math 라이브러리, Array 생성 helper, String helper, 복사를 위한 Object.assign 등이 있습니다.
// Number
Number.EPSILON
Number.isInteger(Infinity) // false
Number.isNaN("NaN") // false
// Math
Math.acosh(3) // 1.762747174039086
Math.hypot(3, 4) // 5
Math.imul(Math.pow(2, 32) - 1, Math.pow(2, 32) - 2) // 2
// String
"abcde".includes("cd") // true
"abc".repeat(3) // "abcabcabc"
// Array
Array.from(document.querySelectorAll('*')) // Returns a real Array
Array.of(1, 2, 3) // Similar to new Array(...), but without special one-arg behavior
[0, 0, 0].fill(7, 1) // [0,7,7]
[1, 2, 3].find(x => x == 3) // 3
[1, 2, 3].findIndex(x => x == 2) // 1
[1, 2, 3, 4, 5].copyWithin(3, 0) // [1, 2, 3, 1, 2]
["a", "b", "c"].entries() // iterator [0, "a"], [1,"b"], [2,"c"]
["a", "b", "c"].keys() // iterator 0, 1, 2
["a", "b", "c"].values() // iterator "a", "b", "c"
// Object
Object.assign(Point, { origin: new Point(0,0) })프로미스(Promise)는 비동기 프로그래밍을 위한 라이브러리로 미래에 생성되는 값을 나타내는 일급 객체입니다.
리플렉션(Reflection) API는 런타임 시 객체에 대해 작업을 수행할 수 있습니다.
프록시 트랩(Proxy traps)와 같은 메타 함수들을 가지고 있으며 프록시를 구현하는데 유용합니다.
마지막에 호출되는 함수가 호출 스택이 초과되게 하지 않습니다.
이는 재귀 알고리즘이 매우 큰 입력 값에서도 안전하게 합니다.
가상 돔(virtual DOM)은 실제 DOM을 추상화한 개념입니다.
먼저 브라우저는 HTML 파일을 스크린에 보여주기 위해 DOM 노드 트리 생성, 렌더 트리 생성, 레이아웃, 페인팅 과정을 거칩니다. DOM 노드는 HTML의 각 엘리먼트와 연관되어 있기 때문에 HTML 파일에 20개의 변화가 생기면 DOM 노드에도 20회의 변경이 이루어 집니다. 작은 변화에도 매우 복잡한 과정들이 다시 실행되기 때문에 DOM 변화가 잦을 경우 성능이 저하됩니다.
가상 돔은 뷰에 변화가 있다면 그 변화가 실제 DOM에 적용되기 전에 가상 돔에 적용시키고 최종 결과만 실제 DOM에 전달합니다. 따라서 20개의 변화가 있다면 가상 돔은 변화된 부분만 가려내어 실제 DOM에 전달하고 실제 DOM은 그 변화를 1회로 인식하여 단 한번의 렌더링 과정만 거치게 됩니다.
React와 D3.js를 함께 사용할 때의 문제점은 두 라이브러리 모두 DOM의 렌더링을 장악/통제하려 한다는 것이다. D3.js 는 선택과 하위 항목의 첨부 + 업데이트를 통해 DOM을 수정하고, React는 요소의 성질이나 상태가 변할 때마다 렌더 함수의 렌더링 요소를 통해 DOM을 수정한다. 이 접근법들을 보고 그 방법들을 결합시킬 방법도 살펴 보자.
-
React를 사용하여 렌더링하기 React는 JSX에서 직접 svg 요소 렌더링을 처리할 수 있어서 우리는 D3의 렌더링 능력을 전혀 이용할 필요가 없다. 차라리 D3를 데이터의 쉬운 로딩, 활용, 포맷팅을 가능하게 하는 d3-scale, d3-request, d3-path 등과 같은 D3 도움 함수로 사용할 것이다. 그 후에 우리는 렌더링을 처리하는 React 컴포넌트를 만들 수 있다.
- 장점 : 더 나은 차트 구조, 더 읽기 쉬움
- 단점 : DOM을 직접 수정할 수 있는 d3.transition과 기타 D3 함수를 사용하지 않음, 요소의 소품과 재 렌더링에 애니메이션 효과를 주는 것이 D3의 애니메이션을 사용하는 것보다 느림
-
D3사용하여 렌더링하기 또 다른 옵션은 React의 렌더링을 다음과 같이 사용하지 못하게 한다. shouldComponentUpdate() { return false }
그리고 D3가 svg elements를 만들도록 하는 것이다. 우리는 단일 svg 컨테이너를 렌더링하는 하나의 React 컴포넌트를 만들고, constructor (props)와 componentWillReceiveProps (nextProps) 함수에서 주어진 데이터 변화에 따라 D3가 DOM을 만드는 것을 처리하도록 한다. 애니메이션은 주로 외부 이벤트에 의해 동작된다. 예를 들어, 버튼 클릭은 React 컴포넌트 트리를 통해 전파되고, D3 요소의 componentWillReceiveProps를 불러내고, 그것은 D3의 업데이트 선택을 사용하여 트렌지션 효과를 동작시킨다.
- 장점 : d3.transition 애니메이션처럼 D3의 모든 함수를 사용할 수 있음
- 단점 : 하나의 컴포넌트에 전체 차트를 넣음으로써 구조화가 약함, 개별 파트간 Tight-coupling 발생, 읽기 힘듦
- 하이브리드 접근법 나는 하이브리드 접근법을 선호한다. React 컴포넌트를 사용하면서 얻게되는 구조와 가독성을 선호하지만, DOM 요소에서 직접 전환 효과를 사용하는 것 또한 좋아한다. 그래서 필자는 두 가지 접근법을 결합한다. React가 대부분의 모든 고정 요소 (컨테이너, 타이틀, 축, 범례) 를 렌더링 하도록하고 D3가 애니메이션화 해야하는 모든 것들을 (데이터 시리즈) 렌더링 하도록 한다. 예를 들어, 이 방법의 실행을 내 Bubble Chart on GitHub 에서 볼 수 있다 ( 또는 여기에서 실행할 수 있다.) 버블 요소를 제외한 모든 요소는 고정 요소이며, 변화하지 않으므로 필자는 이 요소들을 React 내에서 렌더링한다. 버블 요소는 D3에서 force layout을 사용하여 원형들을 렌더링하고 애니메이션화한다. 그렇게 하면 App.js 는 다음과 같이 보인다.
좋은 독립적 차트 구조 적절한 곳(애니메이션)에 D3를 직접적으로 사용할 수 있음
싱글 페이지 애플리케이션은 검색 엔진 최적화에 적합하지 않습니다.
그 이유는 SPA는 하나의 페이지에 여러 페이지를 클라이언트 사이드에서 자바스크립트로 구현하는 방식이기 때문이죠. 자바스크립트를 읽지 못하는 검색엔진에 대해서는 크롤링이 안되어 색인이 되지 않는 문제가 발생할 수 있습니다.
메타 데이터(Meta Data) 또한 하나의 페이지라는 SPA의 본질적인 특성에서 발생하는 문제입니다. MPA와 같이 <head>에 메타 태그를 삽입한 뒤 사이트 내의 다른 페이지로 이동하더라도 HTML은 변동되지 않기 때문에 모든 페이지(단일 페이지이지만)에 동일한 메타 데이터를 삽입하는 상황이 발생합니다.
마지막으로, 크롤러에게는 하나의 페이지이기 때문입니다. 크롤러는 기본적으로 이미 알려진 페이지를 크롤링합니다. 하나의 페이지에 들어갔을 때 발견되는 URL을 대기열에 저장하고 저장된 URL을 기반으로 다시 크롤링하는 작업을 반복하죠. 그러나 SPA 방식의 웹 사이트의 경우 기본적으로 사이트 내의 페이지로 향하는 href속성을 html에서 사용하지 않고 자바스크립트로 페이지 이동을 구현하기 때문에 크롤러가 사이트에 있는 모든 페이지(단일 페이지이지만)의 내용을 크롤링하지 못하는 경우가 발생할 수 있습니다.
위의 문제를 해결하기 위해 아래와 같이 SSR(Server Side Rendering), 그리고 History API를 이용하여 검색 엔진 최적화를 할 수 있습니다.
사이트를 만들기 전에 SEO가 필요한 상황이라면 SSR을 적용해야 합니다.
SPA는 기본적으로 CSR(Client-Side Rendering)로 구현됩니다. 서버에서는 HTML, CSS, JS 등의 리소스를 응답 받은 후 클라이언트가 렌더링을 하는 방식이죠. 그러나 크롤링에 더 친화적인 SSR 방식으로 사이트를 구축하는 것이 SEO의 관점에서 적합합니다.
사이트가 이미 SPA-CSR 방식으로 구현되어있거나 SSR로 개발이 불가한 경우 사전 렌더링(Pre-rendering)을 통해 검색 엔진 최적화를 할 수 있습니다.
사전 렌더링은 서버에서 요청하는 자가 사람인지 크롤러인지 판단하여 사람에게는 HTML과 js 등을 제공하고 크롤러에게는 사전에 렌더링된 HTML 버전의 페이지를 보여주는 방식입니다. 즉, 크롤러는 서버에서 이미 렌더링된 HTML 버전의 소스를 손쉽게 읽을 수 있게 됩니다.
History API는 SPA 방식의 단일 페이지에도 주소를 부여할 수 있습니다.
과거 SPA환경에서 #또는 #!을 통해 주소를 구분하였지만 현재는 History API와 pushState() 메서드를 통해 특수 문자로 된 주소가 아닌 정적인 URL과 같은 주소를 설정할 수 있게 되었습니다. SEO의 관점에서 이는 크롤링뿐만 아니라 백링크를 얻기 용이하게 되었다고 볼 수 있습니다.
자바스크립트는 싱글 스레드 프로그래밍 언어입니다.
싱글 스레드 런타임이라는 의미는 싱글 콜 스택이라는 의미고, 하나의 프로그램은 하나의 코드만 실행하는 것입니다. 콜 스택은 자료구조로서 실행되는 순서를 기억합니다. 함수에서 리턴이 일어나면 스택의 가장 위쪽에서 해당 함수를 꺼내죠.
느려진다는 것은 어떤 것일까요? 블로킹에 대해 설명해보자면 블로킹은 느리게 동작하는 코드일 뿐입니다. 네트워크 요청, 이미지 프로세싱은 느립니다. 느린 동작이 스택에 남아있는 것을 블로킹이라고 하죠. 실행되고 기다리고, 실행되고 기다리고. 싱글 스레드라 함은 요청을 하면 끝날 때까지 기다립니다. 웹 브라우저에서 코드가 실행되는 것이 문제입니다.
브라우저가 멈춥니다. 모든 요청이 완료될 때까지요. 렌더링, 이벤트 발생 등 그 아무것도 실행할 수 없죠. 네트워크 요청이 콜 스택을 블로킹하며 일어나는 현상입니다. 이를 해결할 제일 좋은 방법은 비동기 콜백입니다. 브라우저와 노드에는 블로킹 함수가 거의 없는데, 이는 비동기로 만들어졌기 때문입니다.
이벤트 루프와 동시성이 비동기 콜백의 역할을 합니다. 자바스크립트는 한 번에 하나밖에 할 수 없죠. ajax 요청이나 setTimeout 등이요. 그러나 브라우저는 단순 런타임 이상을 의미합니다. 브라우저는 Web API등을 제공하죠. 자바스크립트에서 호출할 수 있는 스레드를 효과적으로 지원합니다. 여기서 동시성이 들어오죠. Node 또한 C++ API를 사용하죠. 콜백 함수와 setTimeout은 자바스크립트 런타임에 존재하는 별도의 API입니다. 이는 브라우저에서 실행시키죠. 콜 스택에서의 호출은 종료되어 콜 스택에서 바로 지워집니다. 그럼 Web API에서 타이머가 남아있죠. 이는 갑자기 작성된 코드에 끼어들 수 없기 떄문입니다. 이때 테스크 큐와 콜백 큐가 활약합니다.
모든 Web API는 작동이 완료되면 콜백을 태스크 큐에 밀어 넣었습니다. 이벤트 루프는 이 전체 시스템에서 아주 단순한 일을 합니다. 콜 스택과 태스크 큐를 주시하는 것이죠. 스택이 비어있으면 첫 콜백을 스택에 쌓아 실행시키죠.
setTimeout 0의 의미는 무엇일까요? 이는 스택이 비어있을때까지 기다리게 합니다. Web API는 바로 태스크 큐에 콜백을 집어넣고, 이벤트 루프는 스택이 비어있을 때까지 태스크 큐의 콜백을 스택에 넣지 않죠. 이것이 setTimeout 0가 스택의 마지막까지 지연시키는 원리입니다. 모든 Web API는 동일한 방식으로 작동합니다. Ajax요청도 Web API구요. 이러한 의미로 setTimeout에 지정하는 시간은 반드시 보장되지 않습니다. 최소의 지연 시간이죠.
브라우저는 자바스크립트로 하는 무언가로 인해 제약을 받습니다. 브라우저는 기본적으로 화면을 16.6ms, 1초에 60프레임을 repaint하는게 이상적입니다. 그래서 스택에 코드가 있으면 렌더링을 못합니다. 스택이 비워질 때까지 기다려야 하죠. 렌더도 하나의 콜백처럼 행동하니까요. 다른 점이라면 렌더는 일반적인 콜백보다 우선순위가 높습니다. 지속적으로 렌더 콜백을 호출하여 화면을 그리죠. 동기실행 코드가 존재하면 이 렌더 콜백은 실행할 수 없는 것입니다.
우리는 콜 스택, 이벤트 루프, 렌더 스텝을 전부 생각해야 합니다.
requestAnimationFrame은 브라우저가 디스플레이를 업데이트하기로 하면 그때 렌더링 단계를 진행합니다. 즉, 업데이트할 게 있어야만 렌더링을 진행해요. 브라우저 탭이 백그라운드 상태면 절대 렌더링을 하지 않습니다. 대부분의 스크린은 렌더링 빈도가 잦아 1초에 60번입니다. 즉, 60프레임이라는 거죠. 페이지에 천 번의 변경이 되어도 60번 바뀐다는 것입니다.
setTimeout은 디스플레이가 표현할 수 있는 속도보다 많이 움직입니다. 이를 콜백이 작동하는 횟수로 생각한다고 해보세요. setTimeout은 4.7 ms로 움직입니다. 작업을 큐하는 방법은 메세지 채널도 쓸 수 있습니다. 렌더링 작업 사이에는 수십, 수천 작업이 존재할 수 있다는 것입니다.
사용자에게 보여질 각 프레임의 경우 처음에 스타일 계산 레이아웃 같은 렌더링이 실행되는데, 대부분 일정합니다. 그러나 태스크는 이벤트 루프로 인해 프레임 내에 무작위로 위치하게 됩니다. setTimeout의 경우 프레임마다 작업이 4개까지 존재합니다. 콜백의 3/4은 렌더링으로 낭비된거죠. 1000 /60으로 지연시간을 적용해도 부정확하여 드리프트가 발생할 수 있습니다. 한 프레임에서 렌더링이 두번 발생할 수 있는 것이죠. 즉 루틴이 깨져버립니다.
그러나 requestAnimationFrame은 프레임 타이밍 내에서 이루어지게 제어합니다. 이러한 프레임은 사용자 경험이 뛰어나다는 것이죠.
edge, safari는 스타일 계산, 레이아웃 렌더링, 페인팅 작업 뒤에 두므로 문제가 생깁니다. 다른 모던 브라우저는 스타일 계산 전에 requestAnimationFrame이 위치하여 아주 깔끔하죠.
이벤트 루프의 알려지지 않은 부분입니다.
간단한 DOM 작업조차조 생각지 못하게 겹쳐지면서 이벤트 버블링이 발생하고... 수천개의 이벤트가 일어났죠. 따라서 변경 사항 전체를 대표할 이벤트, Mutation Observer, Micro Task가 생겨났습니다.
이는 이벤트 루프 한 번마다 혹은 작업 한 번마다 실행한다고 되어 있습니다. 이벤트 루프 어딘가 의외의 곳에서요. 자바스크립트가 실행을 마쳤을 때 실행됩니다. 자바스크립트 콜 스택이 비어지는 순간에요. 콜 스택이 완료되면 뮤테이션 옵저버에 의해 Microtask를 큐에 넣습니다. 그리고 실행하죠. Promise도 동일합니다. 프로미스 콜백은 스택 밑이라 마이크로 태스크를 씁니다.
세가지 큐가 있습니다. 태스크 큐, 애니메이션 콜백 큐, 마이크로태스크 큐. 셋은 미묘한 차이가 있습니다. 작업 큐에서는 한 항목을 빼면 그것만 빠지고, 더하면 큐 끝에 하나만 추가돼요. 애니메이션 콜백은 완료될 때까지 실행되고, 처리 도중 추가된 건 다음 프레임으로 넘어갑니다. 마이크로 태스크는 완료될 때까지 실행돼요. 새 항목이 큐에 추가되면 되는 대로 계속 실행하죠. 이벤트 루프는 큐가 비워질 때까지 진행되지 않아서 렌더링이 막혀요. 이를 잘 이해하시면 좋습니다.
-
속도 (Speed) : 자바스크립트는 인터프리터 언어이기 때문에, 자바와 같이 컴파일이 필요한 다른 프로그래밍 언어에 비해 시간이 적게 소요됩니다. 또한 자바스크립트는 클라이언트 스크립트이기 때문에 서버 연결에 드는 시간을 절약할 수 있어서 프로그램 실행 속도를 높일 수 있죠.
자바스크립트는 인터프리터 언어?
자바스크립트는 기본적으로 인터프리터 언어이다. 인터프리터 언어는 프로그래밍 언어를 컴파일하여 기계 언어로 바꾸지 않고, 프로그래밍 언어로 되어 있는 코드를 한줄씩 읽으며 실행한다.
그러나, 인터프리터 방식은 한가지 단점이 있다. 가령 매번 똑같은 결과를 반환하느 함수를 5번 호출한다고 치자. 인터프리터 방식은 해당 함수 호출을 만날 때마다 함수를 매번 하여 총 5번 함수를 실행한다. 반면, 컴파일 언어에서는 처음 함수를 만났을 때 그 결과를 기억하고 있다가, 다음 함수 호출을 만나면 함수를 다시 실행하지 않고, 기억하고 있는 결과값을 반환한다. 따라서 함수를 5번 호출해도 실행은 처음 호출한 1번만 한다.
이러한 인터프리터 언어의 한계를 극복하기 위해 V8은 인터프리터에 컴파일을 결합하였다. 일단 기본적으로는 인터프리터가 코드를 읽으며 실행한다. 그리고 이 과정에서 프로파일러(Profiler)가 코드 수행을 지켜보다가, 최적화 할 수 있는 코드는 컴파일러에게 전달해준다. (여기서 최적화 할 수 있는 코드란 여러번 호출되는 함수 등을 의미한다.) 그리고 원래 코드와 최적화된 코드를 바꿔준다.
이렇게 인터프리터 방식으로 실행하다가 필요할 때 컴파일 하는 방식을 JIT(Just-In-Time) 컴파일러라고 한다. V8 외에도 Rhino, SpiderMonkey 등도 JIT 컴파일러를 채택하였다.
-
단순함 (Simplicity) : 자바스크립트는 배우기 쉬운 언어이다. 개발자 뿐만 아니라 개인도 쉽게 이해할 수 있는 구조를 가지고 있다. 또한 프로그램 개발이 매우 쉬워서, 개발자들이 웹을 위한 동적 컨텐츠를 개발하는데 드는 비용을 절약하게 해준다.
-
인기 (Popularity) : 현대의 모든 브라우저들은 자바스크립트를 지원하기 때문에, 사실상 우리는 자바스크립트를 거의 모든 곳에서 발견할 수 있다. 구글, 아마존, 페이팔 등의 유명한 기업들도 자바스크립트를 도구로 사용한다.
-
정보에 대한 상호운용성(Interoperability) : 자바스크립트는 다른 프로그래밍 언어와 완벽하게 호환되기 때문에 많은 개발자들이 다양한 애플리케이션을 만들 때 자바스크립트를 선호한다. 다른 웹페이지나 다른 프로그래밍 언어의 스크립트 안에 자바스크립트 코드를 임베드할 수 있다.
-
서버 로딩 (Server Load) : (클라이언트에서 동작하는 자바스크립트의 경우) 서버로 데이터를 주고 받지 않아도 브라우저 자체에서 데이터 유효성 검사를 할 수 있다. 만약 데이터가 불일치 하는 경우, 전체 페이지를 새로고침하지 않고, 브라우저가 페이지의 일부만 업데이트한다.
-
풍부한 인터페이스 (Rich Interfaces) : 자바스크립트는 매력적인 웹 페이지를 만들기 위한 다양한 인터페이스를 제공한다. 드래그 앤 드롭이나 슬라이더는 웹 페이지에 풍부한 인터페이스를 제공한다. 이로 인해 웹 페이지에서의 사용자 상호작용(user interactivity)이 향상된다.
-
확장된 기능성 (Extended Functionality) : npm 등을 통해 라이브리러리를 추가할 수 있다. 이러한 풍부하고 잘 관리된 써드파티 라이브러리는 개발자로 하여금 빠르고 쉽게 자바스크립트 애플리케이션을 구축할 수 있도록 한다.
-
다재다능 (Versatility) : 자바스크립트는 이제 프론트엔드 뿐만 아니라 백엔드에서도 개발할 수 있다. 백엔드 개발에는 NodeJS를 사용하며, 프론트엔드 개발에는 AngularJS, ReactJS 등을 사용할 수 있다.
-
오버헤드 감소 (Less Overhead) : 자바스크립트는 코드 길이를 줄임으로써 웹 어플리케이션의 성능을 향상시킨다. 이 코드에는 루프, DOM 접근 등 다양한 내장 기능을 사용함으로써 오버헤드가 적다.
자바스크립트는 코드의 길이를 줄인다?
Parser는 소스코드를 AST(Abstract Syntax Tree, 추상 구문 트리)로 바꾸고, Ignition은 이 AST를 바이트코드(Bytecode)로 바꾼다. 원본 소스 코드보다 컴퓨터가 해석하기 쉬운 바이트 코드로 변환함으로써 원본 코드를 다시 파싱하는 수고를 덜어주고, 코드의 양도 줄이면서 코드 실행 때 차지하는 메모리 공간을 아껴준다.
앞서 봤던 JIT 컴파일러(여기서는 TurboFan이라는 이름이다)도 원본 소스 코드를 컴파일하는게 아니라, 이 Ignition이 변환시킨 바이트코드를 컴파일하는 것이다. 어떤 바이트코드가 자주 쓰이면 TurboFan으로 보내져서 Optimized Machine Code로 컴파일되고, 덜 쓰이면 다시 Deoptimizing되어 다시 바이트 코드가 된다.
-
클라이언트 보안 (Client-side Security) : 자바스크립트 코드는 유저에게 보이기 때문에, 누군가가 악의적인 의도로 자바스크립트 코드를 사용할 수도 있다. 인증(authentification) 없이 소스 코드를 사용하는 것이 이에 해당한다. 또한 데이터 보안을 손상시킬 수 있는 악성 코드를 웹사이트에 삽입하는 것은 매우 쉽다.
-
브라우저 지원 (Browser Support) : 브라우저마다 자바스크립트를 해석(interpret)하는 방법은 제각기 다르다. 따라서, 코드를 배포하기 전에 다양한 플랫폼에서 잘 돌아가는지 시험해봐야 한다. 또한 구형 브라우저는 새로운 기능을 지원하지 않는 경우가 있기 때문에 그 부분도 늘 확인해야 한다.
-
디버깅 기능의 부족 (Lack of Debugging Facility) : 몇몇 HTML 에디터가 디버깅 기능을 제공하긴 하지만, C/C++ 에디터와 같은 다른 에디터에 있는 것처럼 유용하지는 않다. 또한, 브라우저는 에러를 보여주지 않기 때문에 개발자가 문제를 찾아내는 것 자체도 어렵다.
-
단일 상속 (Single Inheritance) : 자바스크립트는 단일 상속만 지원하고 다중 상속은 지원하지 않는다.
-
느린 비트 함수 (Sluggish Bitwise Function) : 자바스크립트는 64비트 부동소수점 숫자(64-bit floating-point number)로 숫자를 저장하고, 연산자는 32비트 연산자(32-bit bitwise operands)에서 동작한다. 따라서, 자바스크립트는 숫자(64-bit floating-point number)를 32-bit signed integer로 변환하고, 그걸 기반으로 연산을 수행하고, 그 결과를 다시 자바스크립트 숫자(64-bit floating-point number)로 변환한다. 이러한 연속적인 변환은 시간을 많이 소요하기 때문에 스크립트를 실행하는 데 드는 시간을 늘리고, 스피드는 줄이게 된다.
-
렌더링 중지 (Rendering Stopped) : 코드에 에러가 딱 하나만 있어도 웹 사이트에서 동작하는 자바스크립트 코드가 완전히 렌더링을 중지해버린다. 사용자에게는 자바스크립트가 아예 없는 것처럼 보일 것이다. 그러나 브라우저는 이러한 에러에 매우 관대하다.
-
다른 OOP 언어와의 차이점 1 - 은닉화의 한계 : Java나 TypeScript에는 클래스 내부에서만 쓰이는 속성과 메서드를 구별하는 private이라는 키워드가 존재한다. 따라서 클래스에 정의된 속성이나 메서드에 private 딱지가 붙어있으면, 클래스 외부에서는 접근할 수 없다. JavaScript에서는 private 이 있긴 하지만, 지원하는 브라우저가 별로 없다.
-
다른 OOP 언어와의 차이점 2 - 추상화 기능 부재 : OOP의 추상화는 속성과 메서드의 이름만 노출시켜 사용을 단순화함을 의미한다. 다시 말해, 인터페이스를 단순화함을 의미한다. Java나 TypeScript에서는 인터페이스 기능이 구현되어 있다. 인터페이스를 명시적으로 작성해놓음으로써, 이 클래스가 메서드 이름이 의도한 대로 작동할 것임을 드러낸다. 또한 실질적인 구현은 공개하지 않고 사용법만 노출시킬 수 있다. 특히 이러한 인터페이스 기능은 스크립트가 외부에 공개되는 모듈(ex. API)일 때 유리하다.
- 스로틀
- 디바운스
- html 태그에 적용되면 전체 페이지 배경 이미지가 좋아지지만 앞서 언급한 것처럼 스크롤이 매우 느립니다. 정확히 말하자면 초당 6프레임에 불과합니다.
- 다음의 스타일을 html 태그에 적용하면 프레임률이 600% 향상되는 것을 볼 수 있습니다.
html { -webkit-transform: translate3d(0,0,0); }
- 또한, 스크롤에 아래 옵션을 넣어서 iOS 에서 스크롤 속도를 높일 수 있습니다.
html { -webkit-overflow-scrolling: touch; }
- 단 translate3d or translateZ는 CPU가 아닌 GPU에 엘리먼트를 합성하여 동작하는데, 데스크탑에서는 상관 없으나 처리 능력이 부족한 모바일의 경우 대량의 데이터가 이동 되면 성능을 많이 저하시킵니다.
- 다음의 스타일을 html 태그에 적용하면 프레임률이 600% 향상되는 것을 볼 수 있습니다.
일반적으로 자바스크립트는 데이터 집합 정렬 또는 페이지에 DOM 요소 추가 등 시각적 변화를 일으키는 작업을 처리하는 데 사용됩니다. 하지만 반드시 자바스크립트로 시각적 변화를 트리거할 필요는 없습니다. CSS Animations, Transitions 및 Web Animations API도 널리 사용됩니다.
이는 .headline 또는 .nav > .nav__item 등의 매칭 선택기에 따라 어떤 CSS 규칙을 어떤 요소에 적용할지 계산하는 프로세스입니다. 여기에서 규칙이 알려지면 적용되고 각 요소의 마지막 스타일이 계산됩니다.
브라우저가 요소에 어떤 규칙을 적용할지 알게 되면 화면에서 얼마의 공간을 차지하고 어디에 배치되는지 계산하기 시작할 수 있습니다. 웹의 레이아웃 모델은 한 요소가 다른 요소에 영향을 줄 수 있음을 의미합니다. 예를 들어, 요소의 너비는 일반적으로 하위 요소의 너비 등 트리의 위아래 모든 곳에 영향을 주며, 따라서 이 프로세스는 브라우저에 상당한 영향을 줄 수 있습니다.
페인트는 픽셀을 채우는 프로세스입니다. 이는 텍스트, 색, 이미지, 경계 및 그림자 등 요소의 모든 시각적 부분을 그리는 작업을 포함합니다. 그리기는 일반적으로 레이어라고 하는 다수의 표면에서 수행됩니다.
페이지의 여러 부분이 잠재적으로 여러 레이어로 그려졌기 때문에 페이지가 정확히 렌더링되려면 정확한 순서로 화면에 그려야 합니다. 실수로 한 요소가 다른 요소 위에 잘못 나타날 수 있기 때문에 이는 다른 요소와 겹치는 요소가 있는 경우에 특히 중요합니다.
TypeScript라는 이름답게 정적 타입을 명시할 수 있다는 것이 순수한 자바스크립트와의 가장 큰 차이점입니다.
개발 도구(IDE나 컴파일러 등)에게 개발자가 의도한 변수나 함수 등의 목적을 더욱 명확하게 전달할 수 있고, 그렇게 전달된 정보를 기반으로 코드 자동 완성이나 잘못된 변수/함수 사용에 대한 에러 알림 같은 풍부한 피드백을 받을 수 있게 되므로 순수 자바스크립트에 비해 어마어마한 생산성 향상을 꾀할 수 있죠. 즉, 자바스크립트를 실제로 사용하기 전에 있을만한 타입 에러들을 미리 잡는 것 이 타입스크립트의 사용 목적인 만큼 자바스크립트와의 가장 큰 차이점을 다시 한 번 상기할 수 있습니다.
Typescript는 동적타입언어인 Javascript의 약점을 보완하기 위해서 타입을 지정해주는 것이다. 타입이 필요한 이유는 결론은 메모리를 절약하기 위해서이다. 메모리에 저장된 것을 읽어들일때, 값을 메모리에 저장할때, 값이저장되어있는 것을 참조할때의 크기들을 알아야 하기 때문이다. 또한, 에러를 잡기가 쉬워지고, 다른 동료와 협업 할때 코드의 예측도 가능해지고, 코드에디터의 도움을 더 받을 수 있다. 리액트의 경우 (브라우저는 javascript밖에 모르기떄문에) tsx파일을 javascript로 변환하는 트랜스파일링이 필요하다. 이때 변환하는 과정에서 에러를 잡을 수 가있다. 런타임에 오류를 잡는 것보다 훨~~좋다! 또한, Babel을 안써도 된다.
자바스크립트의 V8 엔진으로 빌드 된 자바스크립트 런타임 환경입니다.
자바스크립트를 브라우저가 아니어도 사용할 수 있게 해줍니다. 다양한 환경에서 자바스크립트로 프로그래밍할 수 있게 만들어주죠. 내부 모듈인 http 등으로 웹 서버를 구동시킬 수 있습니다.
노드를 사용하게 되면 최신 스펙으로 개발할 수 있는데, ECMA 스펙에서 편의성 높은 기능이 제안되어도 브라우저는 이를 금방 지원해주지 않습니다. 웹팩, 바벨 등의 도구 없이는 이러한 기술을 사용해서 개발하기란 쉽지 않죠. 따라서 최신 스펙으로 쾌적한 개발을 위해 노드를 사용해야 합니다. 또한 자바스크립트를 배포하기 위해서는 많은 단계를 거치는데 이러한 번거로움을 줄여주는 빌드 자동화와, 많은 프레임워크나 cli 라이브러리가 제공하는 도구를 확장하거나 수정하는 커스터마이징 기능을 제공합니다.
구글이 만든 오픈 소스 자바스크립트﹒웹어셈블리 엔진으로, 자바스크립트 코드를 실행 전에 최적화된 머신 코드로 컴파일하는 엔진이다. (즉, V8은 자바스크립트 코드를 받아 컴파일하고 실행하는 C++ 프로그램이다.) 크롬 브라우저와 노드 js에서 사용된다.
V8 엔진이 어떻게 동작하는지 알아보기 전에, 애초에 왜 머신 코드로 컴파일하는지 간략히 짚고 넘어가자. 우리가 사용하는 컴퓨터 안에는 마이크로프로세서라는 작은 기계가 있는데, 이것은 CPU의 핵심 기능을 통합한 집적 회로(IC)다. 프로그래머가 어떤 코드를 짜서 컴퓨터에게 일을 시키려면 결국 이 마이크로프로세서가 해석할 수 있는 언어로 전달해야 한다. 마이크로프로세서는 이것을 만든 회사나 버전에 따라 각자 다른 언어를 사용하는데, 가장 많이 쓰이는 것들은 IA-32, x86-64, MIPS, ARM 등이다. 이 언어들은 하드웨어와 직접적으로 소통할 수 있는 코드들이고 그래서 기계어, 머신 코드라 불린다. 그러니까 결국 프로그래머들은 프로그래밍 효율을 위해 추상화 수준이 높은 high level 언어를 사용해서 코딩을 하지만 이는 결국 머신 코드로 컴파일되어야만 CPU가 이해하고 처리를 할 수 있다는 말이다.
- C++로 쓰여졌고 크롬과 Nodejs에서 쓰인다.
- ECMAScript를 따른다. (ECMA-262)
- V8 엔진은 혼자 동작할 수 있고 프로그래머가 C++ 프로그램을 만들어서 돌릴 수도 있다. 예를 들어 원래 Node.js에서 print 함수는 유효하지 않지만, C++의 print 함수를 V8 엔진 위에 얹으면 노드에서 print 함수를 native하게 돌아가게 할 수 있다. C++은 자바스크립트에 비해 하드드라이브의 파일이나 폴더를 다루는 기능이 뛰어난데, 이런 기능들을 V8 엔진을 이용하면 자바스크립트에 심을 수도 있다는 것이다.
- 자바스크립트 코드를 컴파일하고 실행한다
- 콜스택을 핸들링해서 자바스크립트 함수를 특정 순서에 따라 실행한다
- 메모리 힙에 객체들의 메모리 할당을 관리한다
- 더 이상 쓰이지 않는 객체들을 가비지 콜렉팅한다
- 모든 데이터 타입, 연산자, 객체, 함수를 제공한다
- 이벤트 루프를 제공한다(가끔 브라우저에 의해 제공되기도 한다)
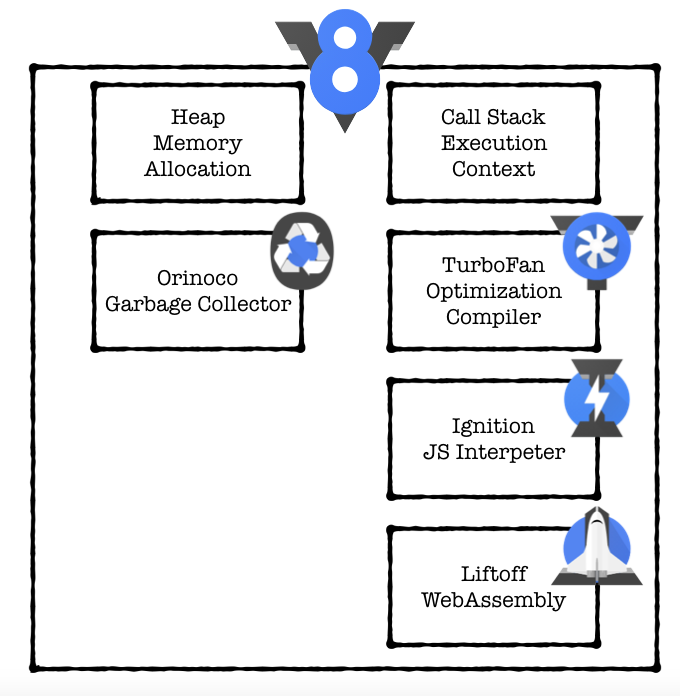
5.9v 이전까지 쓰이던 컴파일러인 Crankshaft와 Full-codegen은 이제 더 이상 쓰이지 않고, Ignition이라는 js 인터프리터와 TurboFan이라는 컴파일러로 대체되었다. (https://v8.dev/blog/launching-ignition-and-turbofan) 이전까지는 JIT(Just-in-time) 컴파일레이션 과정을 거칠 때 아래의 과정을 거쳤었다.
- 코드 실행 전에 Full-codegen(
baseline compiler)이 자바스크립트 코드를 빠르게 non-optimized 머신 코드로 컴파일 - 한 번 컴파일된 코드를 런타임 동안 분석하여 Crankshaft가 optimized 머신 코드로 재컴파일
이 과정의 문제점은 코드가 한 번만 실행되더라도 JIT로 컴파일된 머신 코드가 메모리를 많이 소비한다는 점이다. Full-codegen이 생성하는 코드는 크롬에서 자바스크립트 힙의 거의 삼분의 일을 차지했기 때문에 어플리케이션 데이터를 위한 공간이 적었다. 이 오버헤드를 줄이기 위해 Ignition이라는 인터프리터가 나왔고, 이제는 1번 과정에서 베이스라인 컴파일러가 하는 일을 대체한다.
Ignition은 자바스크립트 코드를 바이트 코드로 컴파일하는데, 이 코드의 사이즈는 베이스라인 머신 코드 크기의 25%~50% 정도이다. 또한 Full-codegen이 베이스라인 코드를 생성하는 데 걸리는 시간보다 바이트코드를 생성하는 것이 더 빠르기 때문에 일반적으로 Ignition은 웹페이지가 로드되는 시간을 줄인다.
이제는 1번을 Ignition이 대체하여 바이트코드를 생성하고, 2번을 TurboFan이 대체하여 최적화 컴파일하는 과정을 거친다.
TurboFan이 Crankshaft를 대체한 이유는 Crankshaft가 자바스크립트의 일부만 최적화 했고(예를 들어 try catch 에러 핸들링 구문을 최적화하도록 디자인되지 않았다) 새로운 자바스크립트 피처를 최적화하기에 한계가 있었기 때문이다. 반면 TurboFan은 ES5뿐만 아니라 ES6 이상을 다룰 수 있도록 설계되었다.
하나의 종속성: 빌드 종속성이 하나만 있습니다. 웹팩, Babel, ESLint 및 기타 놀라운 프로젝트를 사용하지만, 그 위에 응집력 있는 큐레이티드 경험을 제공합니다.
구성이 필요 없음: 아무것도 구성할 필요가 없습니다. 코드 작성에 집중할 수 있도록 개발 및 프로덕션 빌드의 구성이 적절하게 처리됩니다.
No Lock-In: 언제든지 사용자 지정 설정으로 "제거"할 수 있습니다. 단일 명령을 실행하면 모든 구성 및 빌드 종속성이 프로젝트로 직접 이동되므로 중단했던 부분을 바로 선택할 수 있습니다.
사용자 환경에는 최신 단일 페이지 React 앱을 구축하는 데 필요한 모든 것이 있습니다.
React, JSX, ES6, TypeScript 및 Flow 구문 지원. 객체 스프레드 연산자와 같은 ES6 이후의 언어 추가. -webkit- 또는 다른 접두사가 필요 없도록 자동 리믹스된 CSS입니다. 커버리지 보고를 기본적으로 지원하는 빠른 대화형 장치 테스트 실행자. 일반적인 실수에 대해 경고하는 실시간 개발 서버입니다. 프로덕션용 JS, CSS 및 이미지를 해시 및 소스 맵과 번들로 제공하는 빌드 스크립트입니다. 모든 Progressive Web App 기준을 충족하는 오프라인 우선 서비스 작업자 및 웹 앱 매니페스트입니다. (참고: 리액트-스크립트@2.0.0 이상에서는 서비스 작업자 사용이 옵트인됨) 단일 종속성을 가진 위의 도구를 쉽게 업데이트할 수 있습니다. 이 안내서에서 이러한 도구들이 서로 어떻게 결합되는지에 대한 개요를 확인하십시오.
단점은 이러한 툴이 특정 방식으로 동작하도록 사전 구성된다는 것입니다. 프로젝트에 더 많은 사용자 지정이 필요한 경우 "제거"하고 사용자 지정할 수 있지만, 이 구성을 유지해야 합니다.
리액트에서 전역의 상태를 관리하기 위해서 사용하는 방법이다. 컴포넌트간의 상태들을 한군데다가 모아놓고 공유해서 사용하는 방식. 리액트의 상태관리는 Context API, Redux, MobX 등의 상태관리가 있으며, Context API보다 Redux를 사용하는 이유는 대규모 개발에서 유지보수성이나 작업효율을 높이기에는 Redux를 사용하는것이 좋기 때문에 많은 사람들이 Redux를 사용한다. 리액트 16.3이후 버전에서는 그래도 Context API가 개선되어 사용하기 좋아졌다. Redux는 사실 다른 곳에서도 많이 쓰이는 기술이었지만, react-redux라는 것이 있어서 react에서 사용하기 좋아졌다. react-redux에서는 3가지 규칙을 지켜야하는데
- 단일 스토어야 할것
- 읽기전용상태여야 한다. 즉 기존의 객체는 건드리지 않고 새로운 객체를 생성해서 사용하여야한다.
- 리듀서는 순수한 함수여야한다. 즉, 파라미터 외의 값에는 의존하지 않아야한다.
만드는 순서는 액션 타입을 정하고, 액션 생성 함수를 만들고, 이 액션들을 사용하는 리듀서 함수(초기상태 포함)를 만들고, index.js에서 스토어를 만들어 provider로 스토어를 props로 전달해준다. 프레젠테이셔널 컴포넌트와 컨테이너 컴포넌트를 분리하여, 컨테이너 컴포넌트에서 connect함수를 사용해서 mapStateToProps(스토어 안의 상태를 컴포넌트의 props로 넘겨주기 위해 설정하는 함수), mapDispatchToProps(액션 생성 함수를 컴포넌트의 Props로 넘겨주기 위해 사용하는 함수) 이 2가지를 다음과 같이 사용 connect(mapStateToProps, mapDispatchToProps)(타깃컴포넌트)
클래스형은 라이프사이클 메서드를 사용하고, 함수형에서는 useEffect등 Hook을 사용한다. 클래스형은 render함수가 반드시 필요, 함수형이 선언하기 더 간편하다.
클래스형에 라이프사이클 메서드에는 크게 mount, update, unmount 3가지 과정으로 나뉜다. 자세하게는 constructor -> getDerivedStateFromProps -> render -> componentDidMount -> getDerivedStateFromProps -> shouldComponentUpdate -> render -> getSnapshotBeforeUpdate -> componentDidupdate
mount에서 컴포넌트가 만들어질때 componetDidMount에서 비동기처리 같은것을 주로하고, shouldComponentUpdate에서 업데이트 직전에 랜더링시(상태가변경)에 조건으로 재랜더링을 하냐마냐 결정을 할 수 있고, componentDidUpdate 업데이트 직후에 호출되는 메서드이고 unmount에서 컴포넌트가 소멸된 시점에 타이머나 비동기 API를제거 하는 곳이다.
우선 Angular는 프레임워크이고, React는 라이브러리이다. Angular는 양방향 바인딩개념으로 Model과 view가 연결되어있어 데이터 값이 한쪽에서 변화하면 다른쪽에서도 바로 업데이트가 진행된다. 서비스라는 개념은 컴포넌트간의 의존성관리를 용이하게 해준다. Directive를 이용하여 커스텀 HTML태그를 작성할 수 있다. React는 Virtual DOM을 가지고 있다. 가상 DOM이 있기때문에 상태를 비교하여 부분적으로 랜더링 할 수 있어 속도가 빠르다. 오직 UI컴포넌트를 만들기 위한 라이브러리이다. Angular는 HTML스크립팅이 templete 기반, React는 JSX 이용 / Angular는 기본이 Typesciprt
공통점으로 컴포넌트 기반이다. Virtual DOM 방식이다. 가볍고 빠르다. vue는 단일 파일 컴포넌트이다. html, css, javascript코드가 하나의 파일에 모두 정의하는 방식이 기본이지만, 컴포넌트화 해서 사용할 수 있음!! HTML 기반 템플릿 구문을 가진다. -> 배우기 쉬움
https://kr.vuejs.org/v2/guide/comparison.html https://github.com/snabbdom/snabbdom https://ahnheejong.name/articles/why-i-prefer-react-over-vuejs/
- beforeCreate: beforeCreate 훅은 컴포넌트 초기화 단계 중 가장 처음으로 실행됩니다. 이 훅에서는 컴포넌트의 data를 관찰하고, 이벤트를 초기화합니다. 이 단계에서 data는 아직까지 반응적이지 않으며, 컴포넌트의 라이프사이클에서 발생하는 이벤트 역시 설정되지 않은 상태입니다.
- created: created 훅은 Vue 인스턴스가 이벤트를 설정하고 data를 관찰할 때 발생합니다. 이 단계에서 템플릿은 아직 마운트되거나 렌더링되지 않았지만, 이벤트들이 활성화되며 data에 반응적으로 접근하는 것이 가능합니다. 주의: Create 훅에서는 DOM에 직접 접근하거나 마운트할 엘리먼트(this.$el)에 직접 접근할 수 없다는 점을 기억하세요.
- Mounting(DOM 추가): Mount 훅은 가장 많이 사용되는 단계로, 컴포넌트가 렌더링되기 직전이나 직후에 컴포넌트에 접근할 수 있는 단계입니다.
- beforeMount: beforeMount 훅은 컴포넌트가 DOM에 추가되기 직전에 실행되는 훅입니다.
- mounted: mounted 훅은 반응적인 data, 템플릿, 렌더링된 DOM(this.$el) 모두에 접근할 수 있어서 가장 많이 사용되는 훅입니다. 흔히 컴포넌트에서 필요한 데이터를 외부에서 가져오는(fetch) 용도로 많이 사용됩니다.
- Updating (재 렌더링): Update 훅은 컴포넌트 내부의 반응적인 속성이 변했거나, 그 외의 것들이 재 렌더링을 일으킬 때 실행되는 단계입니다.
- beforeUpdate: beforeUpdate 훅은 컴포넌트의 data가 변경되어 업데이트 사이클이 시작될 때 실행됩니다.
- updated: updated 훅은 컴포넌트의 data가 변하여 재 렌더링이 일어난 후에 실행됩니다.
- Destruction(해체): Destruction 훅은 컴포넌트를 더 이상 사용하지 않을 때 사용하는 단계입니다.
- beforeDestroy: beforeDestroy 훅은 컴포넌트가 해체되기 직전에 실행됩니다. 이 훅은 반응적인 이벤트들이나 data들을 해체하는 훅으로 적합합니다. 이 단계에서 컴포넌트는 여전히 문제없이 잘 동작합니다.
- destroyed: destroyed 훅은 컴포넌트가 해체되고 난 직후에 호출됩니다. 모든 지시자들의 바인딩이 해제되었으며, 이벤트 리스너가 제거된 상태입니다.
11버전.
perfomance 최적화 이런건 물론이고(?), Conformance랑, Image 최적화 관련, Webpack5 관련 요소들이 새롭게 업데이트 됐다..🙌
Next.js가 갈수록 SEO 전용 프레임워크로 거듭나는 것 같다. 웹 바이탈(Web vital) 개선 요소들을 계속해서 공략해 나아가는 느낌이다.
Conformance: 최적의 UX를 제공할 수 있는 최적화된 솔루션을 제공하는 시스템
Improved Performance: Cold Start up Time(Next.js 빌드 및 실행할 때 걸리는 시간?) 최적화.
next/script: 성능 향상을 위한 third-party 우선순위 로딩 자동화.
next/image: 이미지 사이즈를 미리 탐지하고 blur-up placeholder 처리를 통해서, layout shift를 줄이고 스무스하게 이미지를 보여주는 사용자 경험 추가.
Webpack 5: 이제 Next.js application 자체에서, 모든 Next.js 개발자들에게 webpack5 관련 요소들을 기본적으로 제공.
Create React App Migration (Experimental): Create React App에서 Next.js가 지원되도록 변환 자동화
Next.js Live (Preview Release): 브라우저를 통해 실시간 협업 코딩 가능
‘Next.js’는 하이브리드 정적 및 서버 렌더링(hybrid static and server rendering), 스마트 번들링(smart bundling), 타입스크립트(TypeScript) 지원, 라우트 프리페칭(route pre-fetching) 등의 기능을 제공한다. 이번에 발표된 버전 10의 새로운 기능은 다음과 같다.
• 자동 이미지 최적화(Automatic image optimization): 기존 HTML 및 브라우저 이미지를 대체한다. 개발자는 점진적 로딩(progressive loading)을 통해 페이지 응답 속도를 향상시키는 리액트 기반 이미지 구성요소로 기존 HTML 태그를 자동 교체할 수 있다.
• 다국어 라우팅(Internationalized routing) 및 자동 언어 감지(automatic language detection): 사용자 선호 언어에 따라 제공할 콘텐츠를 결정하는 동시에 즉각적인 언어 네고시에이션 및 메모라이제이션을 지원해 개발팀에 번역 경로를 제공하고 DIY 접근방식을 제거한다.
• Next.js 애널리틱스(Next.js Analytics): 개발자가 웹 사이트 성능을 개선하는 데 필요한 사용자 인사이트를 지속적으로 제공한다. 지속적인 피드백은 사이트나 애플리케이션이 어떻게 작동하는지 이해하고 웹 바이탈(Web Vitals) 점수를 올리는 데 도움을 준다.
• Next.js 커머스(Next.js Commerce): 이는 성능, 개인화, 몰입적인 사용자 경험을 지원하는 전자상거래 사이트용 올인원 스타터 키트다. 이 오픈소스 플랫폼은 빅커머스(BigCommerce)에서 제공하는 데이터 레이어 및 재사용할 수 있는 데이터 프리미티브를 통해 일반적인 전자상거래 사이트 구성요소 구축을 자동화한다.
• 이제 서드파티 리액트 구성요소에서 CSS를 가져올 수 있다.
이 밖에 Next.js 버전 10은 최근 공개된 ‘리액트 17(React 17)’을 지원한다. 리액트 17에는 Next.js에 관한 주요 변경사항은 없었지만 피어 종속성 업데이트와 같은 일부 유지관리 변경이 필요했다. 새로운 JSX 변환은 리액트 17을 사용할 때 자동 활성화
💬 Nextjs는 ssr을 처리할 수 있음과 동시에 csr영역도 담당하므로 여러 문제 또는 현상이 발생할 슈 있다. 예를 들어 현재 환경이 브라우저인지 서버인지 판단하기 어렵다. 어떻게 판단하면 될까?
💬 클라이언트는 react 서버사이드 프레임워크는 next 서버는 nodejs를 사용한다고 했을때 ssr과정이 어떻게 일어나는지 코드 관점에서 구체적으로 설명해달라 (브라우저에 렌더링이 되기까지)
Next 9 버전
새로고침
브라우저 => 프론트엔드 서버 => 브라우저 => 프론트엔드 서버 => 백엔드 서버 => 프론트엔드 서버 => 브라우저 : CSR 브라우저 => 프론트엔드 서버 => 백엔드 서버 => 프론트엔드 서버 => 브라우저 : SSR 초기 로딩 속도가 조금 빠른 느낌을 줄 수 있다. 사전 작업으로, SSR 구현 전 적용되었던 라이브러리 들은 가급적 제거하는게 좋다. 가볍게할 것. 버전 업데이트 할 때 좋다. next에서 SSR용 메서드 네 개를 제공하는데, redux랑 사용하려면 문제가 좀 있다. 그래서 next-redux-wrapper를 사용하는게 좋다.
원리는, 메인부터 보자면 화면이 로딩된 후에 useEffect를 통해 사용자, 게시글 정보를 받아 오는데 화면이 처음 로딩될 때는 사용자, 게시글 정보가 존재하지 않다가 불러오면서 데이터의 공백이 발생된다. 그러면 화면을 받아올때부터 데이터를 불러올 수 있다면? 그러면 데이터가 채워친 채로 화면이 그려질 수있다. 즉, 홈 컴포넌트보다 먼저 실행될 게 필요한데 종류가 여러가지 있다.
getInitialProps는 next 8버전이다. next 9버전부터 3개가 추가 되었다. getStaticprops, getstaticpath, getserversideprops.
export const getServerSideProps = wrapper.getServerSideProps( context =>
async ({ req }) => {
context.store.dispatch({
type: LOAD_MY_INFO_REQUEST,
});
// 몇 개 불러왔는지 데이터를 가지고 있어야 함
context.store.dispatch({
type: LOAD_POSTS_REQUEST,
});
}
);useEffect로 가져오는 dispatch를 먼저 실행하는 것이다. 물론, 여기서 바로 실행하면 어떤 데이터 정보도 담기지 않지만 HYDRATE라는 개념이 등장한다. NEXTREDUXWRAPPERHYDRATE. getServerSideProps에서 dispatch를 하면 store에 변화가 생기므로 NEXTREDUXWRAPPERHYDRATE로 액션이 실행되면서 데이터를 받는다.
state에 정보를 덮어씌워야 하는데 HYDRATE가 이상하게 실행되어 다른 곳에 데이터를 넣어주고 있다면 reducer의 구조를 다시 한 번 점검해야 한다.
getStaticProps getServerSideProps의 차이?
언제 접속해도 데이터가 변경되지 않을거라면 getStaticProps 접속하는 상황에 따라 화면이 바뀌어야 되면 getServerSideProps를 사용해야 한다. getStaticProps는 블로그 게시글처럼 정말 거의 안바뀌는 것들에 사용하는데, 사용하기가 매우 까다롭다.
빌드할때 아예 정적인 HTML타입으로 변환시켜준다. getStaticProps를 사용할 수 있다면 getStaticProps쓰는게 서버에는 무리가 덜 간다. 정적인 HTML이므로 생각보다 쓰기 어려운 이유는.. 어떤 페이지든 계속 변경되어야 하기 때문이다.
- css-prop, 이모션과 스타일드 컴포넌트의 가장 큰 차이점 // https://emotion.sh/docs/css-prop 기존 정의한 컴포넌트 스타일을 쉽고 안전하게 확장할 수 있음 @emotion/styled는 styled-components와 거의 동일한 기능을 제공하고 있고, 추가로 @emotion/core를 통해 확장성까지 갖추었습니다.
바벨(Babel)이란 자바스크립트 ES6 문법을 기존의 브라우저에서도 실행할 수 있게 ES5로 변환하는 자바스크립트 트랜스 파일러입니다.
트랜스파일러는 프로그래밍 언어로 작성된 소스 코드를 읽어 동일한 수준의 다른 언어로 동등한 코드를 생성하는 도구입니다. 예를 들어 타입스크립트를 자바스크립트로 변환하고 sass를 CSS로 변환하는 것처럼 말이죠. 즉, 컴파일러는 자바나 C와 같이 낮은 추상화 단계로 언어를 변환하지만 트랜스파일러는 같은 추상화 단계에서 변환합니다.
.babelrc 파일로 바벨의 사전 설정을 할 수 있으며, 이는 json 구조로 되어 있습니다. 여기에는 presets, plugins 두 속성을 설정할 수 있는데 ES6에는 화살표 문법이나 class처럼 다양한 기능이 많습니다. 이를 plugins에 정의하려면 많은 양이 차지하므로, 사전 정의된 presets을 사용하면 훨씬 효과적으로 이를 적용할 수 있습니다.
메서드은 웹 개발에서 기능을 지원하지 않는 웹 브라우저 상의 기능을 구현하는 코드를 뜻합니다.
기능을 지원하지 않는 웹 브라우저에서 원하는 기능을 구현할 수 있으나, 폴리필 플러그인 로드 때문에 시간과 트래픽이 늘어나고 브라우저별 기능을 추가하므로 코드가 매우 장황하고 성능이 저하되는 단점이 있습니다.
바벨은 문법을 변환시켜 줄 뿐, 호환되지 않는 기능에 대해 이를 처리하진 않습니다. 그러나 폴리필을 적용하면 현재 브라우저에서 지원하지 않는 기능을 검사한 뒤 각 객체의 프로토타입에 선언해주죠. 즉 바벨은 런타임 이전, 폴리필은 런타임에 실행됩니다.
💬 모듈, 모듈 로더, 모듈 번들러를 설명해주세요.
구현 세부사항을 캡슐화하고, 공개 API를 노출해 다른 코드에서 쉽게 로드하고 사용할 수 있도록 재사용가능한 코드조각입니다.
ES5 모듈 패턴
런타임(실행시간)에 스크립트를 로드해서 html에 부착합니다. 모듈로더는 위에서 언급했던 주요 모듈 포맷으로 작성된 모듈을 해석하고 로드합니다.
모듈로더는 런타임에 실행되는데요.
즉, 클라이언트 사이드에서 불러오는 것입니다.
브라우저에서 모듈로더를 로드합니다. 모듈로더에게 어떤 메인 어플리케이션파일을 로드할 것인지 알려줘야합니다. 모듈로더는 메인 어플리케이션 파일을 다운로드하고 해석합니다. 필요한 경우, 모듈로더가 파일을 다운로드합니다. 예를 들어, 우리가 모듈 10개를 불러온다면, 스크립트태그 10개가 추가된다고 보면 됩니다.
지금도 많이 쓰이는 방식이지만, 한가지 아쉬운 점은 스크립트를 이렇게 나눠서 로딩하게 되면 로딩하는데 시간이 매우 많이 걸리게 된다는 것입니다.
하나의 js파일에 쓸 수 있는것을, 나눠서 30개의 js로 코딩해서 모듈로더를 통해 불러오게된다면, 30번 불러오게 됩니다.
브라우저 개발자콘솔에서 네트워크 탭을 열면, 모듈 로더에 의해 30개의 파일들이 로드된 것을 볼 수 있습니다..
http는 비용이 큰 프로토콜이라 매우 큰 부하를 주게된다고 합니다.
그래서 나온 발상이 “빌드시간에 합치면 되지 않을까?”였습니다.
이게 모듈 번들러입니다.
모듈 번들러는 모듈 로더를 대체합니다.
모듈 로더와는 반대로 모듈 번들러는 빌드타임에 실행됩니다.
빌드 타임에 번들 파일을 생성하기위해 모듈 번들러를 실행합니다.(ex: bundle.js) 브라우저에서 번들 파일을 로드합니다. 기본적으로 js에는 빌드라는 것이 없다고 합니다.
그렇기에 차라리 빌드타임(컴파일 타임)을 만들어내서 한개의 js파일로 보내자는 시도를 하게 된 것입니다.
모듈 번들러는 정말 심플한 역할입니다.
“묶어주는 역할” 이게 끝입니다.
브라우저 개발자 콘솔에서 네트워크탭을 열면, 1개 파일만 로드된 것을 볼 수 있습니다.
모듈: 구현 세부사항을 캡슐화하고 공개API를 노출하여 다른 코드에서 쉽게 로드하고 사용할 수 있는 재사용가능한 코드 조각
모듈 포맷: 모듈을 정의하기위해 사용하는 문법. AMD, CommonJS, UMD, System.register같은 여러 모듈포맷이 등장했으며, ES6부터는 내장된 모듈 포맷을 사용할 수 있다.
모듈 로더: 주요 모듈 포맷으로 작성된 모듈을 런타임때 로드하고 해석. 대표적으로 RequireJS와 SystemJS가 있음.
모듈 번들러: 모듈 로더를 대체하고 빌드타임에 모든 코드의 번들을 생성. 대표적으로 Browerify와 Webpack이 있음.
웹팩(Webpack)은 오픈 소스 자바스크립트 모듈 번들러입니다.
자바스크립트를 위한 모듈 번들러이지만 호환 플러그인을 포함하는 경우 HTML, CSS, 심지어는 이미지와 같은 프론트엔드 리소스를 변환할 수 있죠. 웹팩은 의존성이 있는 모듈을 취하여 해당 모듈을 대표하는 정적 리소스를 생성합니다.
웹팩은 의존성을 취한 다음 의존성 그래프를 만듦으로써 웹 개발자들이 웹 애플리케이션 개발 목적을 위해 모듈 방식의 접근을 사용할 수 있게 도와줍니다. CLI를 통해서 사용할 수 있으며, webpack.config.js이라는 이름의 구성 파일을 사용하여 구성할 수 있습니다. 이 파일을 사용하면 프로젝트를 위해 로더, 플러그인 등을 정의할 수 있죠(웹팩은 로더를 통해 상당한 확장이 가능하므로 개발자들이 파일을 함께 번들링할 때 수행하기 원하는 사용자 지정 작업을 작성할 수 있어요).
단, 웹팩 설치에는 Node.js가 요구됩니다. 또한 moniker 코드 스플리팅을 사용한 코드 온 디맨드를 제공하고 있습니다.
웹팩은 다른 모듈 번들러에 비해 성능이 우수합니다. Grunt, Gulp는 오로지 리소스들에 대한 툴로 사용되며 dependency graph에 대한 개념이 없고, Browsify는 비슷한 도구이나 속도 측면에서 웹팩이 더 좋습니다.
따라서 다양한 리소스들이 들어있는 프로젝트에는 웹팩을 사용하는 것이 좋습니다.
번들(Bundle)은 소프트웨어 및 일부 하드웨어와 함께 작동하는 데 필요한 모든 것을 포함하는 Package입니다.
각 모듈들의 의존성을 파악하여 하나 또는 여러 개로 그룹핑합니다.
ESLint는 ES 와 Lint의 합성어입니다.
ES는 Ecma Script, 표준 Javascript를 의미하며 Lint는 에러가 있는 코드에 표시를 달아놓는 것이죠. ESLint는 자바스크립트 문법의 에러를 표시해줍니다.
ESLint를 설정함으로서 특정 부분만을 제한하거나 전반적인 코딩 스타일을 지정할 수 있습니다.
정해진 규칙대로 코드를 정리해주는 도구입니다.
소스 코드를 스캔하여 문법적 오류나 잠재적 오류까지 찾아내고 오류의 이유를 볼 수 있게 해주는 도구입니다.
- 구문 오류로 인한 코드의 버그를 알려줍니다.
- 코드가 직관적이지 않을 때 경고합니다.
- 일반적인 모범 사례를 제안합니다.
- TODO 및 FIXME를 추적합니다.
- 일관된 코드 스타일을 유지할 수 있습니다.
이는 여러 프로젝트에서 동일한 코드 표준을 적용하고, 협업 간 의사소통이 원활하게 되며 가독성과 유지보수가 좋아지는 장점이 있습니다.
-
package 병렬 설치 npm 은 여러 package를 설치할 때, 각각의 package가 완전히 설치되고 나서 다음이 설치됩니다. (순차적). Yarn은 병렬로 처리되서 performance와 speed가 증가 됩니다.
-
자동 Lock file 생성 npm, yarn 둘 다 package.json에 버전을 명시하고 의존성은 추적 관리하고 있습니다. 버전에 ^를 붙이게 되면 package manaager는 새로운 버전이 배포 되었는지 체크합니다. 새로운 버전이 있으면 명시된 버전이 아닌 최신 버전이 설치 됩니다. 자동으로 설치되는 것을 원치 않는다면 2가지 방법이 있습니다. 하나는 lock file을 생성하는 것입니다. 그래서 특정 버전만 설치되는 것입니다. 다른 하나는 ^를 제거하는 것입니다. yarn은 자동은 yarn.lock 파일을 생성합니다. npm은 nmp shrinkwrap커맨드로 생성 합니다. 차이점이라면 yarn 은 항상 파일을 생성하고, npm은 그렇지 않다는 것입니다. npm-shrinkwrap.jon 이 존재해야 update 됩니다. npm 5버전에서는 lock.json 파일이 새로운 package 이름으로 나옵니다. 그리고 완전히 npm-shrinkwrap 시스템을 버립니다. 이는 설치 프로세스와 성능을 올렸지만, 여전히 yarn에는 못 미칩니다.
-
보안 npm은 다른 package를 즉시 포함 시킬 수 있는 코드를 자동으로 실행하므로 보안에 취약합니다. 반면에 Yarn은 yarn.lock 또는 package.json에 있는 파일만 설치합니다. 이는 npm 보다 더 안전하다고 여겨집니다.
-
결론 둘 다 이점이 있고 사용자에 필요한 기능들을 가지고 있습니다. yarn 은 효율적이면서도 공간을 많이 차지 합니다. yarn 은 더 최신에 등장 했지만 보안과 안정성을 업데이트 하면서 많은 인기를 끌고 있습니다. npm 역시도 다른 manager들을 따라가기 위해 노력중입니다.
프로젝트의 메타 데이터를 담습니다. npm의 핵심 요소죠.
노드로 확장 모듈을 작성하면 npm(node package manager)을 통해 중앙 저장소로 배포할 수 있습니다. package.json 파일은 배포한 모듈 정보를 담고자 만들어졌지만 노드로 작성하는 애플리케이션도 package.json 파일을 사용하여 관리할 수 있습니다. 꼭 확장 모듈 형태로 배포하기 위한 것이 아니더라도 애플리케이션을 개발할 때 package.json 파일을 이용하면 사용하는 확장 모듈에 대한 의존성 관리가 가능하기 때문에 편리합니다.
pacakge.json 파일은 기본적으로 CommonJS의 명세를 따르며, JSON 형식입니다. 직접 작성하거나 npm init 명령어로 자동 생성할 수도 있습니다. 해당 애플리케이션을 위해 사용한 확장 모듈에 대한 정보는 npm install -save를 통해 모듈에 대한 정보를 추가할 수 있습니다. 즉, 프로젝트에 대한 명세라고 할 수 있습니다.
주요 속성으로는 아래와 같습니다.
- name, version : 필수 속성
- description, keywords, private : 각각 설명과 키워드 및 비공개 여부
- bugs : 버그가 발생할 시 제보할 곳
- author : 제작자의 정보
- repository : 코드가 저장된 장소에 대한 정보
- engines, os, cpu : 이 패키지가 특정한 환경에만 동작하도록 하는 속성
- main : 이 패키지의 메인 파일
- scripts : 여러가지 npm 명령어
- dependencies : 일반적으로 의존하는 패키지
- devDependencies : 개발 모드일 때만 의존하는 패키지
- peerDependencies : 직접 require은 하지 않지만 호환되는 패키지의 목록으로 어떤 패키지의 플러그인 같은 개발할 때 사용
버전은
[메이저].[마이너].[패치]3단계로 구성됩니다.
메이저는 대규모 업데이트(이전 버전과 호환 안 됨), 마이너는 소규모 업데이트(이전 버전과 호환은 됨), 패치는 버그 수정 시에 버전을 증가시킵니다.
숫자만으로 기입된 패키지는 해당 버전만을, 부등호(>, >=, <=, <)는 각 연산자에 해당하는 버전을, x 표시는 어떤 버전이든 수용하는 것이며 latest는 가장 최신 버전을 설치하는 것을 의미합니다. ~는 패치 버전까지 변경 허용, ^는 마이너 버전까지 변경을 허용합니다. npm은 ^을 기본값으로 두고 있습니다.
프로젝트 의존성 관리를 위한 부분입니다. 이 프로젝트가 어떤 확장 모듈을 요구하는지 정리할 수 있습니다.
일반적으로 package.json에서 가장 많은 정보가 입력되는 곳입니다. 애플리케이션을 설치할 때 이 내용을 참조하여 필요한 확장 모듈을 자동으로 설치합니다.
따라서 개발한 애플리케이션이 특정한 확장 모듈을 사용한다면 여기에 꼭 명시를 해주어야 합니다.
개발할 때만 의존하는 확장 모듈을 관리합니다.
npm install 명령은 여기에 포함된 모든 확장 모듈들을 설치합니다.
package.json 에서는 버전정보를 저장할 때 version range를 사용합니다. 그러나 종종 같은 package.json이라도 다른 node_modules를 생성하는 경우가 발생합니다. npm 버전이 다르다던가, version range에 해당하는 버전이 다르다던가 말이죠. 이럴때 필요한 것이 packaga-lock.json입니다.
package-lock.json 은 node_modules 구조나 package.json 이 수정되고 생성될 때 당시 의존성에 대한 정확하고 구체적인 정보를 품고 자동으로 생성됩니다. npm install 명령어의 실행과 동시에 생성되는 것이죠. package-lock.json 이 존재할 때에는 npm install이 package-lock.json을 사용하여 node_modules를 생성합니다.
즉, 개발자들이 동일한 node_module 트리를 생성해서 같은 의존성을 설치할 수 있도록 보장하는 것이 package-lock.json 입니다.
일반적으로 실무에서 테스트 코드를 작성한다고 하면 거의 단위 테스트를 의미한다. 통합 테스트는 실제 여러 컴포넌트들 간의 상호작용을 테스트하기 때문에 모든 컴포넌트들이 구동된 상태에서 테스트를 하게 된다. 그렇기에 통합 테스트를 위해서는 캐시나 데이터베이스 등 다른 컴포넌트들과 실제 연결을 해야 하고, 시스템을 구성하는 컴포넌트들이 많아질수록 테스트를 위한 비용(시간)이 상당히 커진다. 반면에 단위 테스트는 해당 부분만 독립적으로 테스트하기 때문에 어떤 코드를 리팩토링하여도 빠르게 문제 여부를 확인할 수 있다.
- 테스팅에 대한 시간과 비용을 절감할 수 있다.
- 새로운 기능 추가 시에 수시로 빠르게 테스트 할 수 있다.
- 리팩토링 시에 안정성을 확보할 수 있다.
- 코드에 대한 문서가 될 수 있다.
그렇기 때문에 실무에서는 단위 테스트를 선호하며, 요즘 많이 사용되는 TDD(Test-Driven Development, 테스트 주도 개발) 에서 얘기하는 테스트도 단위 테스트를 의미한다. 우리는 우리가 작성한 테스트 코드를 수시로 빠르게 돌리면서 문제를 파악할 수 있다.
어떤 객체가 자체적으로 모든 일을 처리한다면 문제가 없겠지만, 일반적인 애플리케이션에서는 1개의 기능을 처리하기 위해 다른 객체들과 메세지를 주고 받아야 한다. 하지만 앞서 설명하였듯 단위 테스트는 해당 모듈에 대한 독립적인 테스트이기 때문에 다른 객체와 메세지를 주고 받는 경우에 문제가 발생한다. 그렇기 때문에 다른 객체 대신에 가짜 객체(Mock Object)를 주입하여 어떤 결과를 반환하라고 정해진 답변을 준비시켜야 하는데, 이를 stub이라고 한다.
예를 들어 데이터베이스에 새로운 데이터를 추가하는 코드를 테스트한다고 하면, 가짜 데이터베이스(Mock Database)를 주입하여 insert 처리 시에 반드시에 1을 반환하도록 해주는 것이 stub이다.
일반적으로 요구 사항은 계속해서 변하고, 그에 맞춰 우리의 코드 역시 변경되어야 한다. 하지만 실제 코드를 변경한다는 것은 잠재적인 버그가 발생할 수 있음을 내포하는데, 좋은 테스트 코드가 있다면 변경된 코드를 검증함으로써 이를 해결할 수 있다. 또한 실제 코드가 변경되면 테스트 코드 역시 변경이 필요할 수 있는데, 이러한 이유로 우리는 테스트 코드 역시 가독성있게 작성할 필요가 있다.
그렇기에 테스트를 작성하는 경우에는 다음을 준수하는 것이 좋다.
- 1개의 테스트 함수에 대해 assert를 최소화하라
- 1개의 테스트 함수는 1가지 개념 만을 테스트하라
또한 좋고 깨끗한 테스트 코드는 FIRST라는 5가지 규칙을 따라야 한다.
- Fast: 테스트는 빠르게 동작하여 자주 돌릴 수 있어야 한다.
- Independent: 각각의 테스트는 독립적이며 서로 의존해서는 안된다.
- Repeatable: 어느 환경에서도 반복 가능해야 한다.
- Self-Validating: 테스트는 성공 또는 실패로 bool 값으로 결과를 내어 자체적으로 검증되어야 한다.
- Timely: 테스트는 적시에 즉, 테스트하려는 실제 코드를 구현하기 직전에 구현해야 한다.
단위 테스트(Unit Test)는 하나의 모듈을 기준으로 독립적으로 진행되는 가장 작은 단위의 테스트이다. 여기서 모듈은 애플리케이션에서 동작하는 하나의 기능 또는 메서드로 이해할 수 있다. 예를 들어 웹 애플리케이션에서 로그인 메서드에 대한 독립적인 테스트가 1개의 단위테스트가 될 수 있다.
즉, 단위 테스트는 애플리케이션을 구성하는 하나의 기능이 올바르게 동작하는지를 독립적으로 테스트하는 것으로, "어떤 기능이 실행되면 어떤 결과가 나온다" 정도로 테스트를 진행한다.
통합 테스트(Integration Test)는 모듈을 통합하는 과정에서 모듈 간의 호환성을 확인하기 위해 수행되는 테스트이다.
일반적으로 애플리케이션은 여러 개의 모듈들로 구성이 되고, 모듈들끼리 메세지를 주고 받으면서(함수 호출) 기능을 수행한다. 그렇기에 통합된 모듈들이 올바르게 연계되어 동작하는지 검증이 필요한데, 이러한 목적으로 진행되는 테스트가 통합 테스트이다. 그렇기에 통합 테스트는 독립적인 기능에 대한 테스트가 아니라 웹 페이지로부터 API를 호출하여 올바르게 동작하는 지를 확인하는 것이다.
일반적으로 기획자의 의도에 따라 디자인 된 화면을 개발하게 됩니다. 스크롤이 움직이거나 마우스가 클릭되고, 키보드 입력이 있을 경우에 어떤 기능이 작동하고 화면이 변경되는 지 등의 변화를 내포한 일련의 작업들을 말이죠.
이렇게 시각적인 요소만을 담당하는 것은 아닙니다. 마크업 개발이 어느 정도 규모가 있는 회사에서는 구분이 되어 있는 것을 예외로 하더라도, 사용자가 보기 위한 데이터를 가져와서 정제하는 것도 필요하죠. 이때 백엔드-서버 개발자들과 긴밀하게 협의하여 명확한 표준을 작성한 뒤 개발에 착수해야 합니다.
즉, UI/UX를 알고 동작과 최적화를 이해한 상태에서, 백엔드에서의 데이터 통신을 적절히 처리하여 사용자에게 친화적이고 좋은 경험성을 제공하는 것이 프론트엔드 개발자의 역할입니다.
💬 CORS란? CORS를 해결하기 위한 방법을 아는 대로 모두 설명해 주시고 보통 어떤 방식으로 해결하는지 자주 사용하는 방법 1가지와 함께 실제 해결하신 경험을 공유해 주세요.
Cross-Origin Resource Sharing(CORS) 은 추가 HTTP 헤더를 사용하여 브라우저가 한 출처에서 실행중인 웹 애플리케이션에 선택된 액세스 권한을 부여하도록하는 메커니즘입니다.
다른 출처의 자원 또는 웹 응용 프로그램과 다른 출처(도메인, 프로토콜 또는 포트)를 가진 리소스를 요청할 때 cross-origin HTTP 요청을 실행합니다. Same-Origin Policy의 문제점을 해결하기 위한 정책으로 CORS란 cross-Origin, 출처가 다른 도메인에서의 Ajax 요청도 서버에서 데이터 접근 권한을 허용하는 정책입니다.
CORS를 해결하는 방법으로는 Access-Control-Allow-Origin response header를 사용하는 방법과 서버에서 CORS를 설정하는 방법, 또한 proxy를 설정하는 방법이 있습니다.
이 중 Access-Control-Allow-Origin 응답 헤더는 이 응답이 주어진 origin으로부터의 요청 코드와 공유될 수 있는지를 나타냅니다. 즉 서버측 응답에서 접근 권한을 주는 헤더를 추가해 cors 에러를 해결하는 방법이죠. "*"를 기입하면 모든 도메인을 허용합니다.
코드 레벨(CSS, JS)로 나누거나, 클라이언트-서버 환경, 브라우저 호환성 등을 생각해야 합니다.
저는 대부분 코드 레벨로 프론트엔드 성능을 끌어올렸습니다. 그 부분을 중심으로 설명 드립니다.
배열에서 무언가를 찾으려면 find, indexOf, filter 같은 메소드를 사용하여 배열의 처음부터 끝까지 탐색하므로 O(n)의 복잡성을 지닌 선형 검색이 됩니다. 최악의 경우, 배열의 요소 갯수만큼의 많은 비교를 수행해야함을 의미합니다. 작은 배열에서는 이것이 눈에 띄지 않지만, 배열의 크기가 크다면 성능에 엄청난 영향을 끼치게됩니다.
이런 경우 배열을 객체나 맵으로 변환하고 key 로 검색을 하는 것이 좋습니다. 객체와 맵은 해시 테이블 이라는 자료구조를 사용하기 때문에 O(1)의 복잡성으로 요소에 접근할 수 있어 자료의 크기에 관계없이 항상 메모리를 한 번만 호출하게 됩니다.
맵과 객체는 초당 수백만 개의 작업을 수행하지만, 배열은 최상의 결과에서조차 고작 100여개의 작업만 수행할 수 있습니다. 물론 지금은 데이터 변환을 고려하지않았지만, 데이터 변환을 고려한다고 해도 여전히 맵과 객체가 빠릅니다.
if문, try-catch, short-circuit 평가 중, null 을 체크하는 것이 항상 더 낫다는 것은 굉장히 중요한 사실입니다. if문과 short-circuit 평가 는 성능 차이가 거의 없기때문에 더 마음에 드는 것을 사용하면 됩니다.
map, filter, reduce는 훌륭하지만 성능을 저하시키는 요소가 될 수 있습니다. 원본 배열을 변경하거나, 사본 배열을 반환하는 등의 효과가 있기 때문이죠. 메서드 체이닝 등을 활용해도 동일합니다.
반복문에는 forEach, for...of, for...in 등이 있습니다. 이러한 반복문은 전통적으로 사용되던 기본 반복문 과 비교하면 성능이 떨어집니다. for...in 반복문은 다른 방법이 정녕 없는 경우를 제외하고는 사용하지 않는 것이 좋을 정도로 느립니다. 또한 for...in 반복문은 모든 객체의 프로퍼티(배열의 경우 인덱스)에 접근하기때문에, 예상치못한 결과가 발생할 수 있습니다.
DOM을 다룰 때 라이브러리를 사용하는 것은 나쁜 방법이 아니지만, 가장 기본적인 메소드인 getElementById와 getElementsByClassName이 DOM을 순회할 때 가장 뛰어난 성능을 보여줍니다.
querySelector by id와 Advanced selector in querySelector 또한 jQuery보다 빠른 성능을 보여주었죠. 오직 클래스 명으로 엘리먼트 여러개를 가져올 때 사용하는 querySelectorAll의 경우에만 jQuery보다 느렸습니다.
이 외의 방법으로 Webpack 등의 모듈 번들러로 진행하는 자바스크립트 번들링을 통해 최적화할 수 있습니다.
브라우저의 URL 요청을 받아서 서버의 데이터를 화면에 다시 뿌려주기까지의 백엔드 쪽의 플로우를 알고 있는지 확인하는 차원.
대기업/공기업 등의 프로젝트를 진행하면서 jenkins를 사용하거나 ant-builder, 혹은 file-zilla를 통해 직접 배포하기도 했습니다.
애플리케이션 개발단계를 자동화 하여 애플리케이션을 보다 짧은 주기로 고객에게 제공하는 방법입니다.
기본 개념으로는 지속적인 통합, 지속적인 서비스 제공, 지속적인 배포입니다.
애플리케이션의 통합 및 테스트 단계에서부터 제공 및 배포에 이르는 애플리케이션의 라이프사이클 전체에 걸쳐 지속적인 자동화와 지속적인 모니터링을 제공하죠. 이런 구축 사례를 일반적으로 CI/CD 파이프라인이라 부르며 개발 및 운영팀의 애자일방식을 통해 지원 됩니다.
개발자를 위한 자동화 프로세스인 지속적인 통합을 의미합니다.
성공적으로 구현할 경우 애플리케이션에 대한 새로운 코드 변경사항이 정기적으로 빌드 및 테스트되어 공유 리포지토리에 통합되어 서로 충돌할 수 있는 문제를 해결합니다.
CI가 필요한 환경으로는 다음과 같습니다.
- 다수의 개발자가 형상관리 툴을 공유하여 사용하는 환경
- MSA(Micro Service Archietecture)환경
- 최근에 많이 사용하는 아키텍쳐 모델
- 작은 기능별로 서비스를 잘게 쪼개어 개발하는 형태.
- 대부분 Agile(소규모 기능 단위로 빠르게 개발 & 적용을 반복)방법론이 적용됨.
CI를 통한 목표는 버그를 신속하게 찾아 해결하고, 소프트웨어의 품질을 개선하여 새로운 업데이트의 검증 및 릴리즈의 시간을 단축시키는 것입니다.
지속적인 배포를 의미합니다.
개발자들이 애플리케이션에 적용한 변경 사항이 버그 테스트를 거쳐 리포지토리에 자동으로 업로드 되는 것을 뜻하며, 운영 팀은 이 리포지토리에서 애플리케이션을 실시간으로 배포할 수 있습니다.
개발팀과 비즈니스팀 간의 가시성과 커뮤니케이션 부족 문제를 해결해줍니다.
혼자 진행했던 프로젝트나 시스템 업무를 맡으면서 스스로 짰던 경험은 있습니다. API 서버를 추구하면서 python으로 Selenium을 사용하여 웹에 뿌려지는 데이터를 체크했고, 그 외의 단위 테스트는 jest를 사용했었습니다.
안정성, 투명성 관점이 제일 중요했습니다.
- 사전에 문제를 빠르게 인지하고 검증할 수 있을까?
- 문제 발생 시 어떻게 하면 쉽고 효과적으로 해결할 수 있을까?
- 다양한 상황에 대해 충분한 검증이 이루어질까?
git repository를 하나파서 다른 동료가 fork를 해서 사용하는 방식. PM과 팀원의 구조를 가질 수도있고 동시에 Pull request를 가능하게끔 권한을 줄 수 도 있다. 각자의 팀장의 레포가 origin이라하고, 팀원의 포크딴 레포를 rmorigin이라고 한다면 각자의 origin에서 develop브랜치에서 작업을 한뒤 최종 작업이 완료되면 팀장의 origin의 마스터로 push한다.