How to calculate the vertical distance from a D455 to the surface represented by each pixel value in a depth image? #11657
Comments
|
Hi @MartyG-RealSense, thank you for the recommendation. I have looked at the post and have implemented some things to test. From what I understand from these posts, I can treat the depth image such that each pixel has (in the v dimension) an equal share of the camera's vertical field of view. Is this correct? In this case, the change in angle for each pixel is constant, and I can simply add the pitch of the camera to the pitch offset of the pixel to get the pitch of the pixel. (I am assuming that the orientation of the camera should go through the center of the image (or maybe at the principal points?)
Here, the pitch angle of a particular pixel should be
Then, I should be able to use simple trigonometry to calculate
with I've implemented the following function to test this but I get very similar results to before:
It is unable to identify the whole floor, or even the whole top of the Turtle Bot because there is still a false gradient on the image which has not been removed. This gradient is visible in the Hoping someone has some ideas on how to proceed. |




|
I have just found a small error in my code that seems to have fixed things a good bit: Now I get the correct behavior: This is still sensitive to roll because I have only handled pitch so far. You can see below the effect that the roll has on it: Once I figure out the roll I'll post it here. |


|
It's great to hear that you have made significant progress! The depth pixel value is a measurement from the parallel plane of the imagers and not the absolute range.
A RealSense team member offers advice about obtaining roll and pitch from the IMU with Python at #4391 (comment) |

|
For the roll and pitch, I am using the following class: And the This seems to be working pretty well for me so far, but maybe there's a better way to do it. |
|
I do not have a better solution to suggest than the one that you have implemented. Thanks so much for sharing your solution for the benefit of the RealSense community! |
|
I have made a bit more progress on this. Lots of credit and thanks to @l0e42! :) If we augment the solution above (which handles only the pitch), we can pretty easily handle the roll as well. The following are just notes and are meant as a sketch of the idea, not as something rigorous, and it may not be perfect. The image below shows the effect of rotating the camera by an angle In the previous solution, I considered only If we consider roll, we should use
All of this leads to the following solution: And this solution gives the following output:
It is a bit noisy and sensitive to quick changes in the orientation of the camera, but it is able to correctly identify most of the floor while avoiding other non-contiguous surfaces. The performance will likely improve if the camera is stabilized (instead of handheld like it is here), and also if the orientation is filtered in a better way than this exponential decay method. I also had to make |


|
Thanks again for sharing your progress in such deep detail :) |
|
After some post-processing and essentially using a different kind of flood fill technique, the results are smoother (see below). Ultimately, it seems like the data from the D455 is less reliable when it is viewing the ground at extreme angles, which is understandable. There is probably also some loss in precision in the data as it is being transformed, especially at these extreme angles. I'll close this issue now but thanks for the suggestions @MartyG-RealSense and if anyone has any ideas or more suggestions, please let me know!
|

Issue Description
I am working on a project where I need to identify contiguous flat/level regions using a depth image. When the camera is pointed in the direction of the gravity vector, this is easy because the vertical distance is exactly the distance represented by the depth frame. For example, in the image below, I can simply flood fill (with a small tolerance) from the center of the image and easily identify the top of the Turtle Bot as a contiguous, level region (highlighted in green). The red regions are identified as particularly "un-level" because their gradients do not align well enough with the gravity vector.
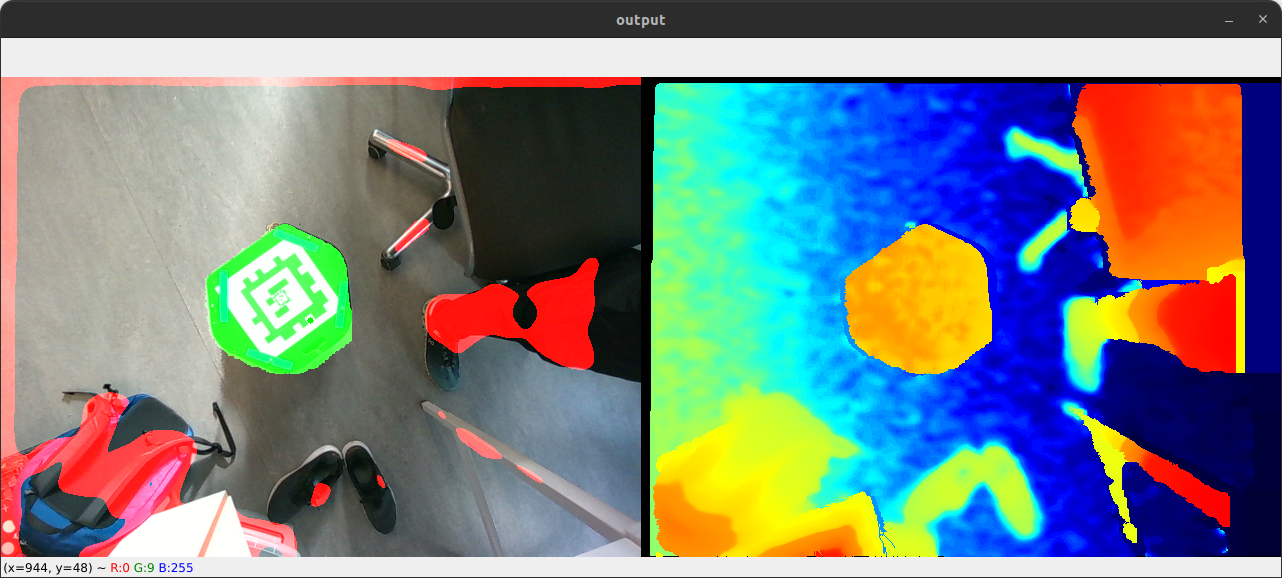
And here it can identify the floor:
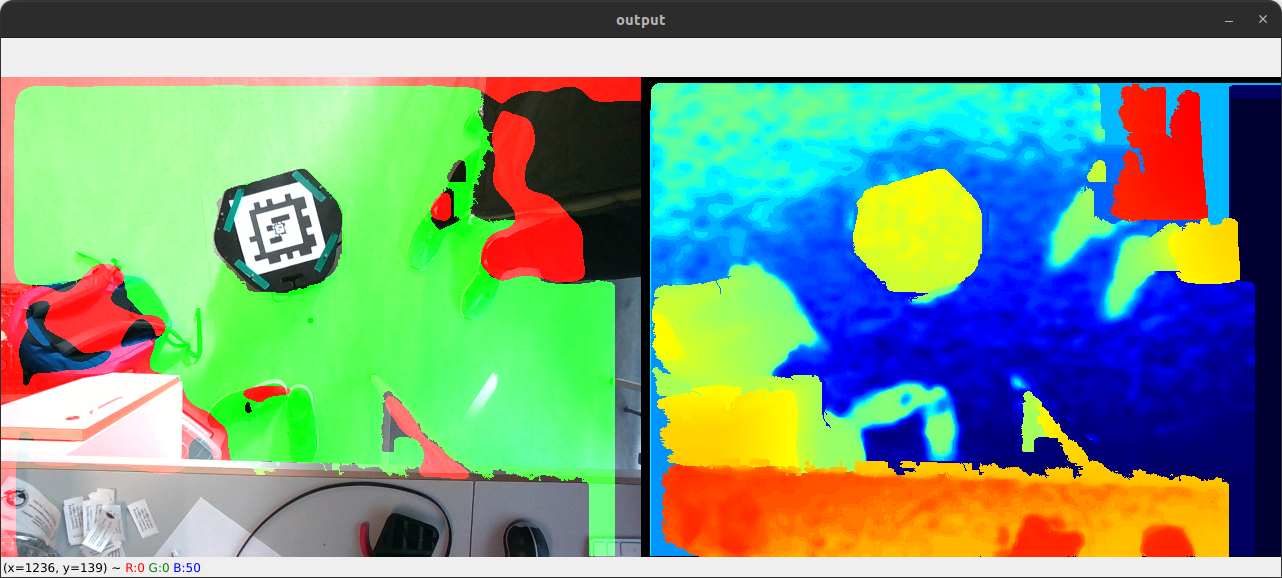
The problem becomes harder when the camera is not pointing straight down, mostly because I don't know how to correctly transform the depth image. The flood fill just floods until it reaches its tolerance and then stops, so I get results like below:
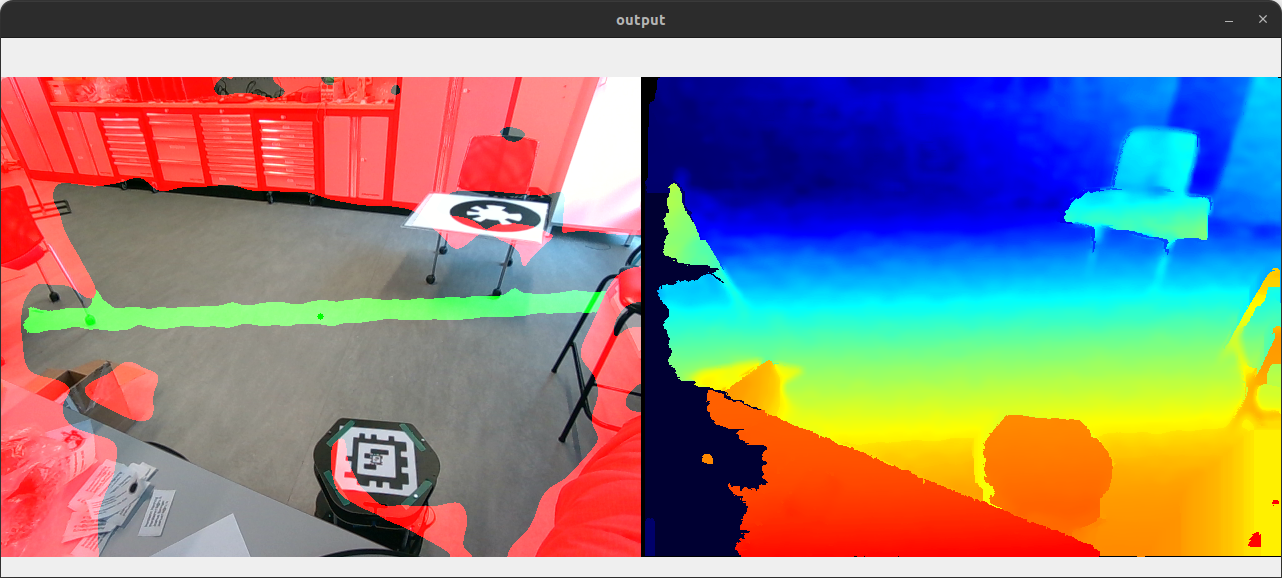
The non-zero orientation (in pitch/roll) of the camera is causing an apparent gradient over surfaces that are really level. I cannot assume the orientation of the camera will be straight down, so I need to transform the depth data. I have the gravity vector using a Python implementation of rs-motion's RotationEstimator class. I don't need the yaw because it does not bias the appearance of level surfaces (and anyway it drifts significantly over time).
Problem
How do I transform the depth data correctly? I would like to create a 2D image in the same dimensions as the depth image, where the value at each pixel corresponds to the vertical distance (with respect to the gravity vector) from the camera to the detected surface/object. I have tried using the
rs2_deproject_pixel_to_pointfunction to get the (x,y,z) coordinates represented by each pixel, and then rotate them by the inverse of the apparent gravity vector detected by the camera as below:However, I get similar results to above, and if I visualize the
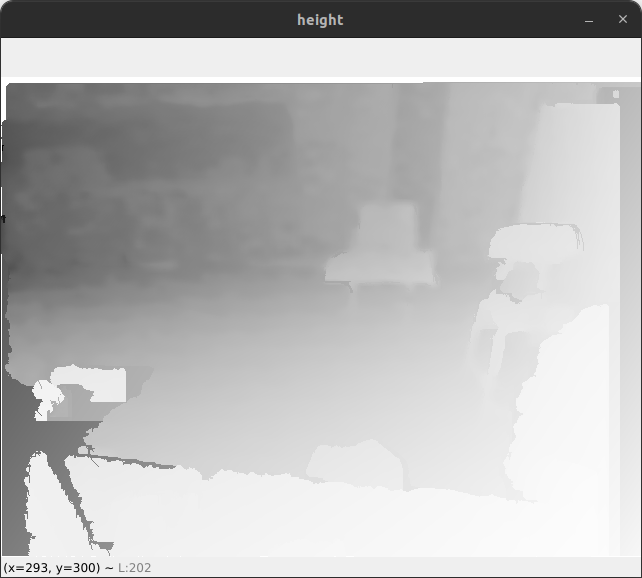
heightmatrix, the gradient is still visible:Any insight on how to calculate the vertical distance from the D455 to the surface at each pixel would be greatly appreciated!
The text was updated successfully, but these errors were encountered: