Is there any data augmentation strategy used during training? #19
Comments
|
Hi, no we don't do any augmentation besides random cropping the data to patches of size 256x256. We used the vimeo dataset from here. How large is the performance gap? Another learning rate strategy would be to set the lr to 1e-5 after ~100-150 epochs (depending on your dataset/batch size). We have observed similar performances. |
|
Thanks for quick reply. I will try to train on the dataset provide above. Is all data used in training/validating or just part of them? |

|
I have checked the example/train.py and found that gradients were clipped by hyper_param --clip_max_norm(default:0.1). Does it influence train result? I wonder if gradient clip operation is involved in your training process? If it is, what the value of hyper_param --clip_max_norm? After declare network, I explicitly call the update func like below, is that ok? |
|
Yes ok, this gap should not happen. We use gradient norm clipping, but usually the value is set 1. not 0.1, I'll fix the example. Thanks for reporting! You only need to call |
|
Thanks. Finally I get similar results. |
|
Great, thanks for the update! |
Hi, Here is a gap with the homepage shows. 1、I wonder where is the exact position of the |

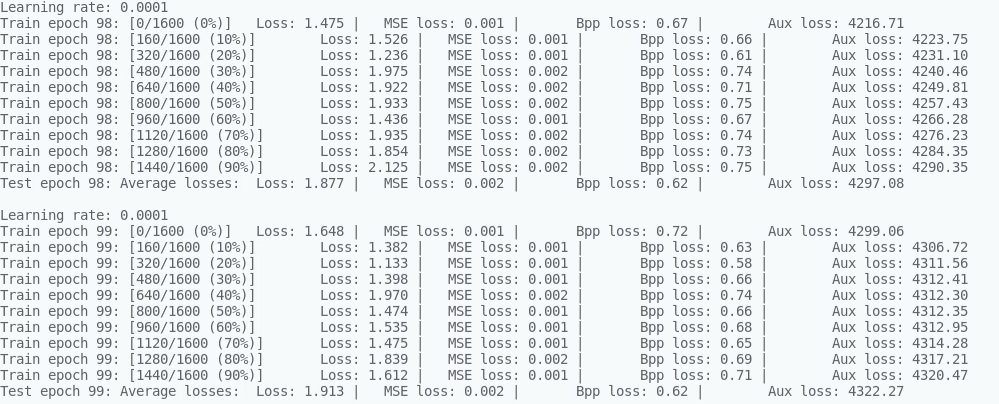
|
@jbegaint sorry, i found the update command. While I try to update the trained model as |
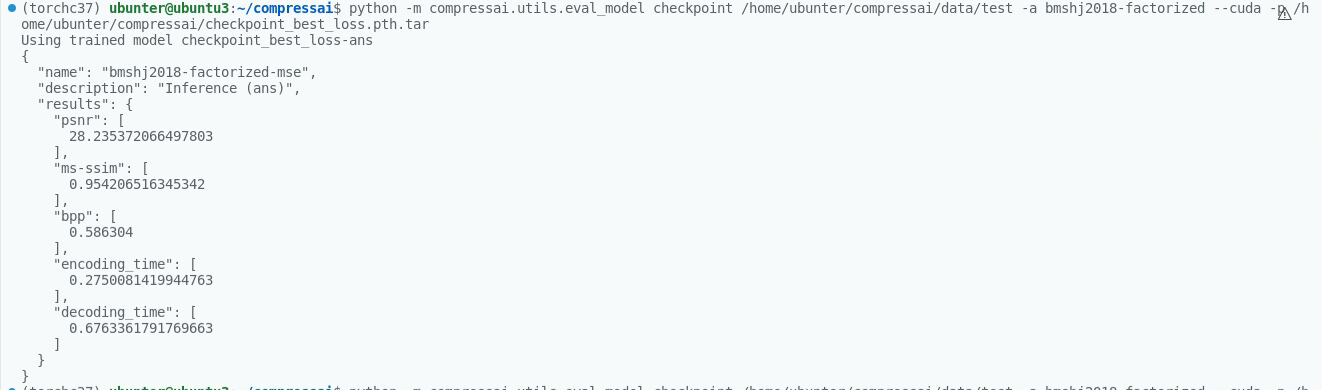
I try to train ScaleHyperprior model using code provide in example/train.py with Imagenet2012/DIV2K dataset. The learning rate for main optimizer and aux_optimizer both set to 1e-4. The learning rate of the main optimizer is then divided by 2 when the evaluation loss reaches a plateau as it described in https://interdigitalinc.github.io/CompressAI/zoo.html. However, atfer nearly 1 week's training, the rate-distortion performance on Kadok-24 still has a gap compared to the result provided.
I am also training model on vimeo_test_clean from Vimeo90K after 2 days, it seems will not to converge to the result provided.
Have I missed something? Is there any data augmentation strategy used during training?
The text was updated successfully, but these errors were encountered: