lmdeploy.pytorch is an inference engine in LMDeploy that offers a developer-friendly framework to users interested in deploying their own models and developing new features.
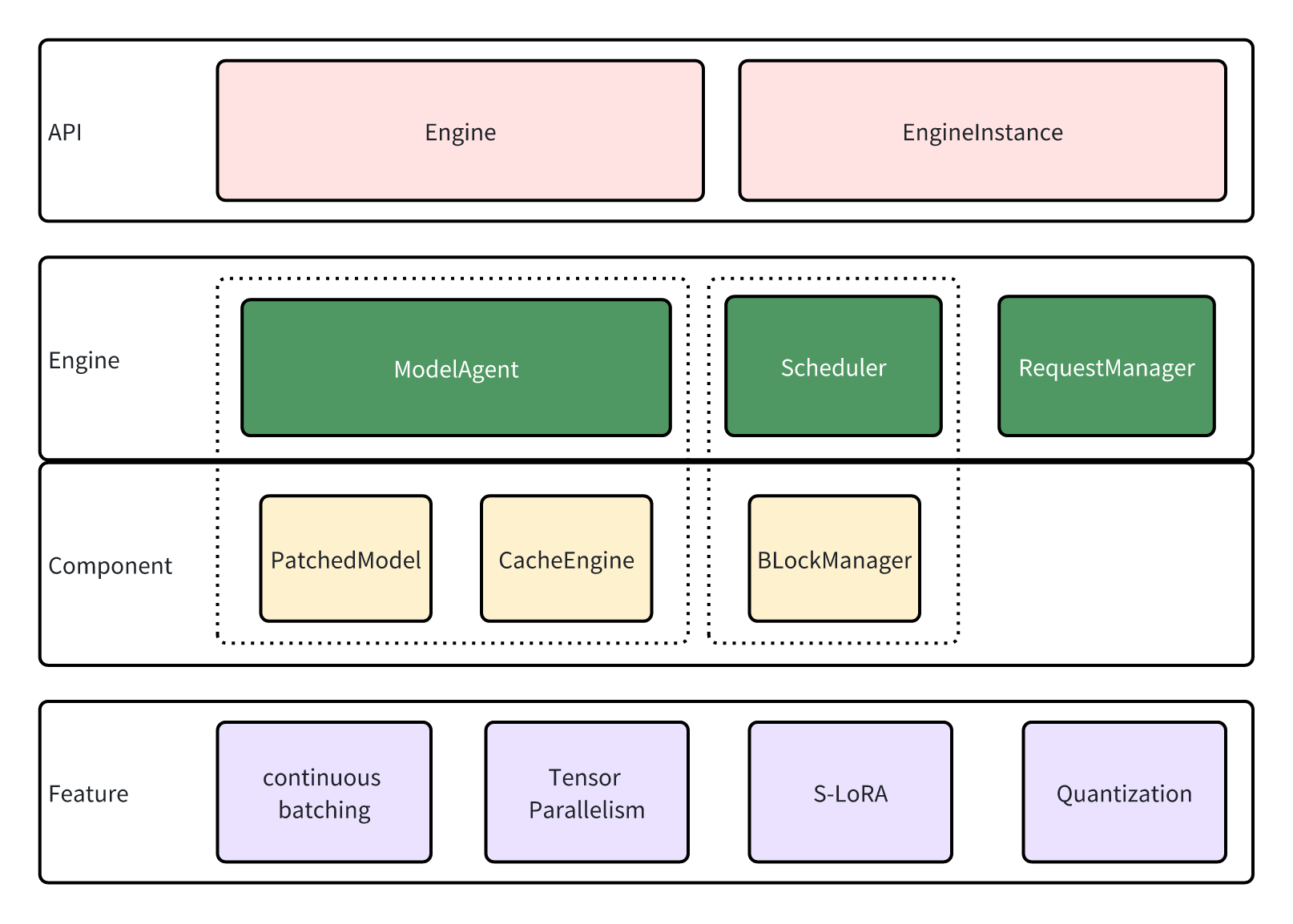
lmdeploy.pytorch shares service interfaces with Turbomind, and the inference service is implemented by Engine and EngineInstance.
EngineInstance acts as the sender of inference requests, encapsulating and sending requests to the Engine to achieve streaming inference. The inference interface of EngineInstance is thread-safe, allowing instances in different threads to initiate requests simultaneously. The Engine will automatically perform batch processing based on the current system resources.
Engine is the request receiver and executor. It contain modules:
ModelAgentserves as a wrapper for the model, handling tasks such as loading model/adapters, managing the cache, and implementing tensor parallelism.- The
Schedulerfunctions as the sequence manager, determining the sequences and adapters to participate in the current step, and subsequently allocating resources for them. RequestManageris tasked with sending and receiving requests. acting as the bridge between theEngineandEngineInstance.
The Engine responses to requests in a sub-thread, following this looping sequence:
- Get new requests through
RequestManager. These requests are cached for now. - The
Schedulerperforms scheduling, deciding which cached requests should be processed and allocating resources for them. ModelAgentswaps the caches according to the information provided by the Scheduler, then performs inference with the patched model.- The
Schedulerupdates the status of requests based to the inference results fromModelAgent. RequestManagerresponds to the sender (EngineInstance), and the process return to step 1.
Now, Let's delve deeper into the modules that participate in these steps.
In LLM inference, caching history key and value states is a common practice to prevent redundant computation. However, as history lengths vary in a batch of sequences, we need to pad the caches to enable batching inference. Unfortunately, this padding can lead to significant memory wastage, limiting the transformer's performance.
vLLM employs a paging-based strategy, allocating caches in page blocks to minimize extra memory usage. Our Scheduler module in the Engine shares a similar design, allocating resources based on sequence length in blocks and evicting unused blocks to support larger batching and longer session lengths.
Additionally, we support S-LoRA, which enables the use of multiple LoRA adapters on limited memory.
lmdeploy.pytorch supports Tensor Parallelism, which leads to complex model initialization, cache allocation, and weight partitioning. ModelAgent is designed to abstract these complexities, allowing the Engine to focus solely on maintaining the pipeline.
ModelAgent consists of two components:
- `patched_model: : This is the transformer model after patching. In comparison to the original model, the patched model incorporates additional features such as Tensor Parallelism, quantization, and high-performance kernels.
- cache_engine: This component manages the caches. It receives commands from the Scheduler and performs host-device page swaps. Only GPU blocks are utilized for caching key/value pairs and adapters.
In order to facilitate the deployment of a new model, we have developed a tool to patch the modules.
For example, if we want to reimplement the forward method of LlamaAttention:
class CustomLlamaAttention(nn.Module):
def forward(self, ...):
# custom forwardWe register the implementation above into lmdeploy.pytorch.models.module_map:
MODULE_MAP.update({
'transformers.models.llama.modeling_llama.LlamaAttention':
'qualname.to.CustomLlamaAttention'})ModelAgent would then load and patch LlamaAttention with CustomLlamaAttention while leaving everything else unchanged. You can perform inference with the new implementation. For more detail about model patching, please refer to support new model .
lmdeploy.pytorch supports new features including:
-
Continuous Batching: As the sequence length in a batch may vary, padding is often necessary for batching inference. However, large padding can lead to additional memory usage and unnecessary computation. To address this, we employ continuous batching, where all sequences are concatenated into a single long sequence to avoid padding.
-
Tensor Parallelism: The GPU memory usage of LLM might exceed the capacity of a single GPU. Tensor parallelism is utilized to accommodate such models on multiple devices. Each device handles parts of the model simultaneously, and the results are gathered to ensure correctness.
-
S-LoRA: LoRA adapters can be used to train LLM on devices with limited memory. While it's common practice to merge adapters into the model weights before deployment, loading multiple adapters in this way can consume a significant amount of memory. We support S-LoRA, where adapters are paged and swapped in when necessary. Special kernels are developed to support inference with unmerged adapters, enabling the loading of various adapters efficiently.
-
Quantization: Model quantization involves performing computations with low precision.
lmdeploy.pytorchsupports w8a8 quantization. For more details, refer to w8a8.