pdf文档 from http://www.deeplearningbook.org/contents/intro.html
######首先给出 Deep learning在AI领域的地位(Figure 1.4)
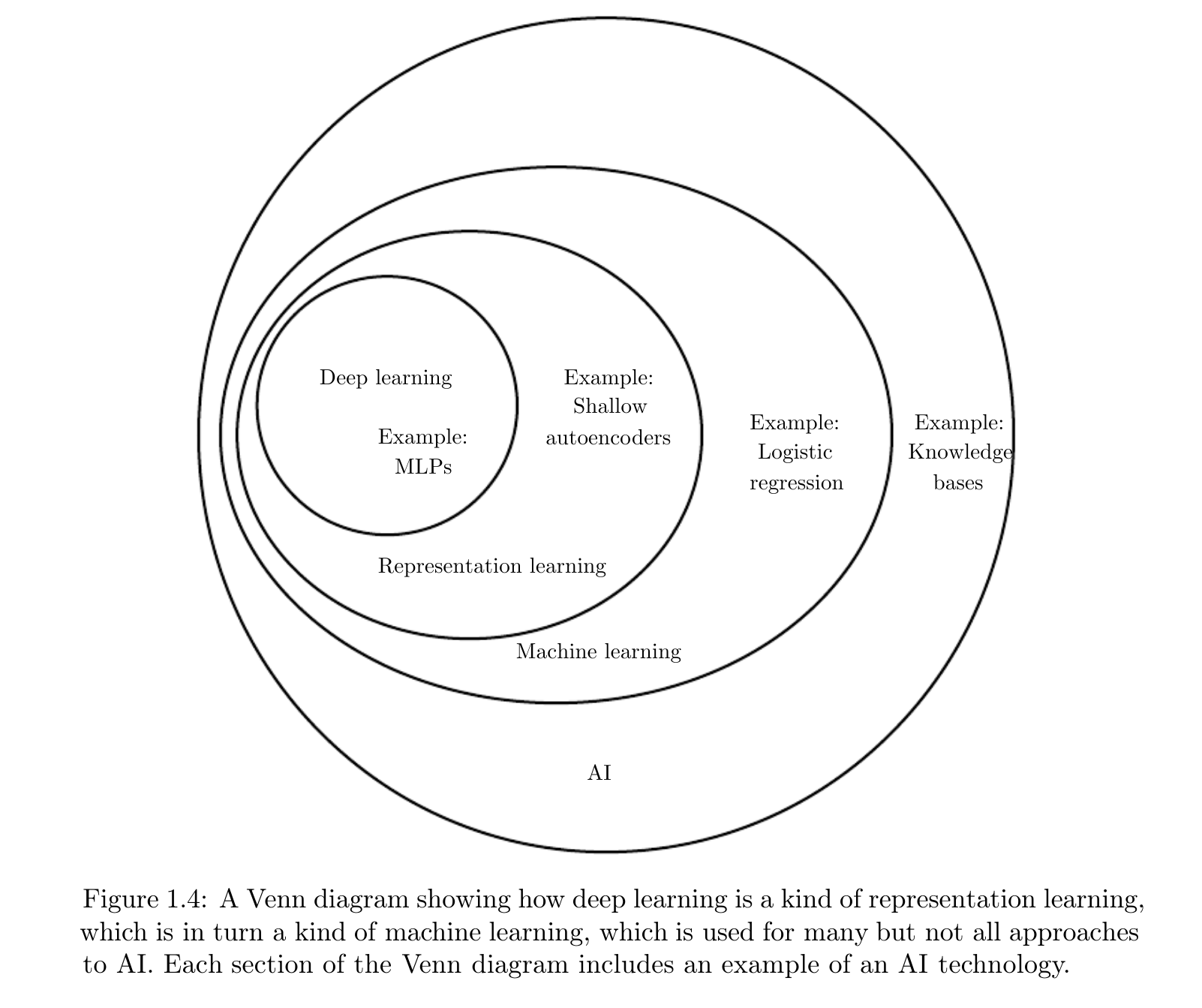
######Let's go!
- 我们一直在梦想着创造一个可以思考的机器。
- 人工智能真正的挑战是如何去解决那些人可以很直观解决,但是很难正式描述的事情(如果人类可以很容易正式描述出来的话,就不是难点了,直接一系列规则即可),比如口语理解、人脸识别等。The true challenge to artificial intelligence proved to be solving the tasks that are easy for people to perform but hard for people to describe formally—problems that we solve intuitively, that feel automatic, like recognizing spoken words or faces in images.
P1-bottom:本书就是关于这些直观问题的解决方案,即允许机器从经验中学习,并以一系列层次性的概念来理解这个世界(learn from experience and understand the world in terms of a hierarchy of concepts),每个概念都是基于更简单的概念或其关系来定义的(with each concept defined in terms of its relation to simpler concepts)。而这层次性的概念也使得计算机可以不断的从 world 中收集知识(人也是这样子学习的),并从更简单的(概念)层次,进而学习更复杂(complicated)的概念.(The hierarchy of concepts allows the computer to learn complicated concepts by building them out of simpler ones.)。如果我们要画一个图来描述这个过程的话,那么可想这个图的深度是非常 deep 的,所以我们把这种方法(solution,解决方案)称作 deep learning,即层次性学习。- 计算机擅长规则或者正式的事情,而不擅长学习不正式或主观的事情: 我们人类每天获取的知识绝多数是来自于人客观或主观的感知,而这是很难以一个正式的方式表达的(Much of this knowledge is subjective and intuitive, and therefore difficult to articulate in a formal way.)。所以计算机若想实现人工智能,一个关键挑战就在于如何将这些非正式的信息传递给计算机(One of the key challenges in artificial intelligence is how to get this informal knowledge into a computer)。有两种方式:
- hard-code,或者叫做 knowledge base: 即 使用正式语言来对world进行描述(hard-code knowledge about the world in formal languages),这需要人类设计足够复杂的规则去准确的描述world。但这个太难了,以这种方式构建的系统基本上没有获得巨大成功的。
P2-left举了个FredWhileShaving的例子,即Cyc系统(knwoledge base system)无法理解 在早上剃胡须的Fred(人名)这是个什么东西,因为它认为人不是不应该包含电子器件的,但是FredWhileShaving又包含了电子器件,所以它会检测到不一致性。 - machine learning(ML): hard-code面临的困难也意味着,机器应该拥有取获取自己知识的能力,即从原始数据(底层)到规则/模式(高层)的获取知识的能力,这个能力就叫做机器学习(ML)。简单的机器学习算法比如有:逻辑回归模型(LR)、朴素bayes(NB)。
- **这些简单机器模型的基本流程是输入数据的某种表示形式(data reprezation,or feature ,特征,经常需要人工提取),接着去学习这些输入和输出的关系。**也就是这些简单机器学习算法严重依赖数据的表示形式,特征造得好和坏,对结果影响特别大(It is not surprising that the choice of representation has an enormous effect on the performance of machine learning algorithms)。
- 对于简单的任务,我们可以很容易的提取出有价值的特征,然后丢给一个简单机器学习算法去学习即可完美解决该任务的问题。但是对于很多任务,是很难去知道要提取哪些特征的。比如,假设我们想取写一个程序取检测图像中的cars,因为我们知道cars有轮子(wheels),那么我们就可以以是否有轮子来作为特征。但是非常unfortunately,机器并不知道轮子是怎样子(it is difficult to describe exactly what a wheel looks like in terms of pixel values),甚至轮子还可能出现光照、阴暗等的影响等等。
- representation learning:
P4-top. 那么数据表示(特征)这个问题的一个解决方法就是机器学习不仅去发现从数据表示(特征)到输出之间的关系,同时也去学习数据表示形式自身(原始输入到特征的mapping),这就叫做表示学习或特征学习。同时学习到的数据表示(特征)也比人造的特征表现要好。- 特征学习和映射学习两者同时学的好处在于实现了end-to-end的学习,这使得AI系统可以快速的迁移到一个新任务,而不需要人工造任何的特征(减少人工干预,更智能)。一个好的representation learning算法甚至可以在几分钟学习到一个简单任务的良好特征集合。大大减少了人造特征的工作量。
- algorithm example:
- autoencoder(自编码):
P4-bottom.由一个encoder函数和一个decoder函数构成。An autoencoder is the combination of an encoder function that converts the input data into a different representation, and a decoder function that converts the new representation back into the original format.可以用encoder的输出作为数据的表示形式。
- autoencoder(自编码):
P4-bottom:不管人工设计特征还是设计学习特征的算法,我们的目标都是希望能够分离(separate)或者找出可以解释现有可观察数据的变异/分叉/多样性因素(factors of variation that explain the observed data),这里的factors of variation 可以理解为导致任意两份数据/个体不一样的因素,即变异的原因。本文使用“factors”去表示导致各个来源(source)分离的影响因素,这些factors通常不是不能通过乘法运算结合的(not combined by multiplication);这些因素通常很难可观的量化;而且,他们可能存在于未观察到物体或力量中,却影响着可观察到的量化。可以认为是事物的概念或者抽象。比如当我们分析一个语音识别的时候,the factors of variation 包括讲话者的年龄、性别、口音等等。具体看原文英文,P4-bottom解释。- 在现实应用场景中,很多factors of variation 会影响 一系列的数据,即这个factors还不够本质/判别力(discriminative),比如red car的像素点在晚上就跟黑色一样,所以就不能用一个像素点来做判断。同时如果以一个轮廓来判断一个car的话,也会因为角度、光线的原因,影响判断。所以通常应用中都会对fators进行分解(disentangle),并去除(discard)无用的。
- 当然,从原始数据中提取出这样高层、抽象的特征是非常困难的。
- hard-code,或者叫做 knowledge base: 即 使用正式语言来对world进行描述(hard-code knowledge about the world in formal languages),这需要人类设计足够复杂的规则去准确的描述world。但这个太难了,以这种方式构建的系统基本上没有获得巨大成功的。
--
-
Deep learning(DL):是ML的一个分支, Deep learning 的提出就是解决representation learning的一个方法,通过引入层次的概念,即从更简单的表示/概念中来构建更复杂高层的表示/概念。比如Figure1.2 就展示了人如果从原始像素到一些简单概念(比如角度、轮廓等),再到物体识别的过程。
- quintessential example:
- multilayer perceptron(MLP): feedforward deep network。可以将MLP看作一个函数,即将输入映射到输出,当然这个函数是由需要简单的函数够成的( is formed by composing many simpler functions)
- 可以有两个角度(perspective)来理解DL。一,就是原本定义,即一层层的不断的学习数据的representation; 二,DL也可以看作是一个分步骤的程序(multi-step program),每一层的表示可以当作并行执行了一系列指令后计算机的内存(memory,记忆)。构建更深的网络,也就意味着可以执行更复杂的指令。这种序列化类型的指令有种好处,就是回溯回更早指令的结果(refer back to earlier instructions)
- Depth:
P7-bottom to P8-top: 关于DL网络的 depth ,有两种measure方法:- 一、the depth of the computational graph,计算图方法(computational graph):整个网络基于执行多少个序列指令,但有个缺点,就是使用不同函数构成的网络(但完成同样功能),会造成depth不同,如 Figure 1.3;
- 二、the depth of the probabilistic modeling graph,或者叫概念图方法(conceptual graph):这种观点 ragard the depth as being not the depth of the computational graph but the depth of the graph describing how concepts are related to each other. 以多少层概念(数据表示)来作为depth。第一种方法要比第二种方法计算出来的deeper,原因是系统对底层的理解,可以通过高层的理解反过来继续refine系统对底层的理解(This is because the system’s understanding of the simpler concepts can be refined given information about the more complex concepts)。所以当网络是一个递归网络的时候,使用方法1计算出来的depth会更深,因为会对网络的每个概念层计算多次**(备注:这里是读者的理解,可能不准确,之后会再重读下)**。
- 其实具体 Depth of network 是没有唯一答案,对于多深的网络算“deep”也没有一致的(consensus)意见。但是还是可以很保守的认为DL比传统机器学习算法不仅有更多的可学习(训练)函数(learned fuctions)及其组合,也有更多的可学习概念(表示,representation)(learned concepts)。
- quintessential example:
-
Summary:小总结下,DL,本book的主题,是一种AI方法,也是一种ML类型,是一个允许计算机从经验和数据中改善自我的技术。
- machine learning is the only viable approach to building AI systems that can operate in complicated, real-world environments.
- Deep learning is a particular kind of machine learning that achieves great power and flexibility by learning to represent the world as a nested hierarchy of concepts, with each concept defined in relation to simpler concepts, and more abstract representations computed in terms of less abstract ones.
####最后可以再看回开头的图1.4,会对整个DL和AI有更清晰的了解,下面给出了各种AI方法的过程(Figure 1.5),以及该书的组织架构(Figure 1.6):

