1024x1024 model question #12
Comments
|
|
ok. |
|
I did not understand it, which means to upscale a 512x512 images to higher resolution one? |
|
I already cropped faces with onother project(GFPGAN) to 512Pix. Now, what I want is to try your code on those images without changing resolution. I want enhance faces to be in same resolution (512x512pixels). Then I will pasteback those faces directly from GFPGAN. If it is not possible, please tell me ways I can do it. If output face photo must be upscaled, no problem, I will downscale it with photoshop. |
|
I see. You can directly execute tasks in 512Pixels images, since the model get a super-resolution result from 512Pixels" low-resolution" image. You should change the config to |
|
when I commented that line everything goes OK until Do you have solution for this? Thank you |
|
|
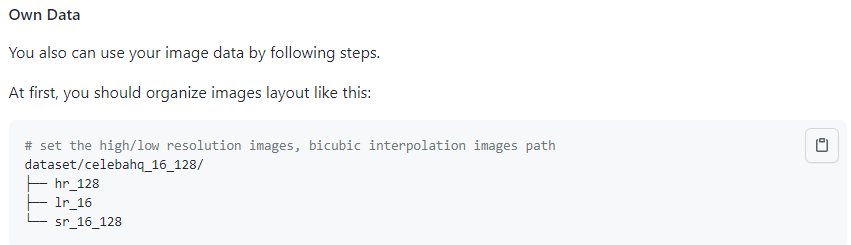
|
I successed it. But with model that correspond 64x512 results are too sharp and not much better from original. |
|
I think this has something to do with the unstable pre-trained model. I have some suggestion about it:
|
|
Hi, |
|
So sorry, I didn't know much about other models. |
|
thank you very much for your reply, Janspiry! |
Hello, I have some questions about training your implementation of the model on my own dataset and I would be very grateful if you could please help me. Thank you very much! |
|
Hi, thanks for your attention.
|


|
Hello, thank you so much for your helpful reply! |
Hi |
|
Hi |
Hi. Do you plan to release 1024x1024 model?
Or it can be done modifying code to cascade all models?
Cause, I think it is better to not downscale images to 128Pixels.
Thank you very much in advance
The text was updated successfully, but these errors were encountered: