Optimization #24
Comments
|
how did you do this: |
I did this to understand how much faster the algorithm works with the changes I made. The standard algorithm completes on average in 5 hours |
|
Interesting...do you have to manually load each new key and then run Kang or do you have this automated somehow? |
|
I have automated this. Everything is very simple there, I added a loop and deleted the command line arguments |
|
Simple for someone who knows their way away programming :) |
|
Hi, Please be more precise: You can speed up the search by spreading the wild to -N/8,N/8, even -N/16,N/16 |
|
Jean Luc, Using the Div8 in CreateHerd? |
|
Yes, replace the code between in Kangaroo.cpp:574,579 by You win a lot for key around the center but keys on the border will longer to solve , in average you still win. |
|
Can it be put in lines 581:586? Lines 574:579 are grayed out; that's the symmetry code-grayed out. |
|
Current code: |
|
It is well in the second part 574:579, USE_SYMMETRY is not defined. Line 574 in ea13121 |
Yes |
|
Hi @JeanLucPons
I generated keys randomly, duplicates are excluded. I also created a file with the keys and ran the test again to make sure that there were no duplicate keys and the results were correct. I tested the keys and in a small range (2^32 - 2^63) in all ranges the speed of finding the key increases. I use Four kangaroo method. The problem is that the more kangaroos you use, the slower the key will be found. Optimal use 4 kangaroos - 2T and 2W. You can find research on it. |
|
@AndrewBrz when you say 4 kangaroos, you mean 4 herds of kangaroos? I've read something to that extent T1 T2, W1 W2. How are you implementing that? |
|
@CatfishCrypt |
|
Wow...Doesn't seem right, mathematically speaking. Huge space, with only 4 kangaroos versus thousands/millions. |
|
Ok Make test on 40 or 48 bit range and large number of trials to get good average estimation. Note that the error in proportional to 1/sqrt(trials). Rather than giving a time comparison, give the ratio of sqrt(N), Standard method is 2.08sqrt(N) , for 4 kangaroos (non paralell) around 1.78sqrt(N). Take also in consideration the GPU handle large number of kangaroos, there is some users with several GPU that use 2^24 or more kangaroos with large distinguished bit number on large range. I will work soon on a distributed version (client/server) where the server will handle DP and collision check. |
You can create many kangaroo herds, but all of them should work independently of each other, but you can try and add communication between them (I still have no idea how to do this without sacrificing speed). There should be 4 kangaroos in one herd. This is mathematically correct |
I will do all the tests as I finish on the OpenCL version |
|
The server version is exactly what I was thinking! That would be awesome...and I believe would reduce solution time by Eleventy Gabillionsqrt(N) :) |
You write an OpenCL version for the standard method of for 4 kangaroo method ? |
|
I tested tested the Wild in [-N/8..N/8], 1000 trials, 40 bits search. Original code: With the modification above: Gain: 15% |
Standart, three method and 4 method. There are not big changes in the code, so you can add and remove kangaroos for tests. |
how much kangaroo was used T and W? |
|
@JeanLucPons This change will only check X coordinates. Another optimization is to calculate only the X coordinate, which allows us to accelerate the speed of calculations (there are research and you can find and read them) |
|
What changes have you experimented with for starting and jump points? More interested in how you changed your start points, you change them to start other than around the center? |
|
Thanks Andrew for your job ;)
|
|
@AndrewBrz if you make AMD support please share with others |
I think he will not be share. After your proposal, he does not respond. |
|
That's too bad. I hope he will share his work. |
|
when I finish working on the algorithm, I will share the code |
It's great. I'm glad you took the opportunity to make a tool for red cards. |
|
@AndrewBrz hi! Any new about AMD support? Tnx |
|
@kpot87 hi! These are the results of kernel testing, they indicate that the kernel is optimized as much as possible |

|
Hi Andrew, |
Hi... any progress on opencl version? |
|
hi @RB61 This is the BitCrack OpenCl kernel |
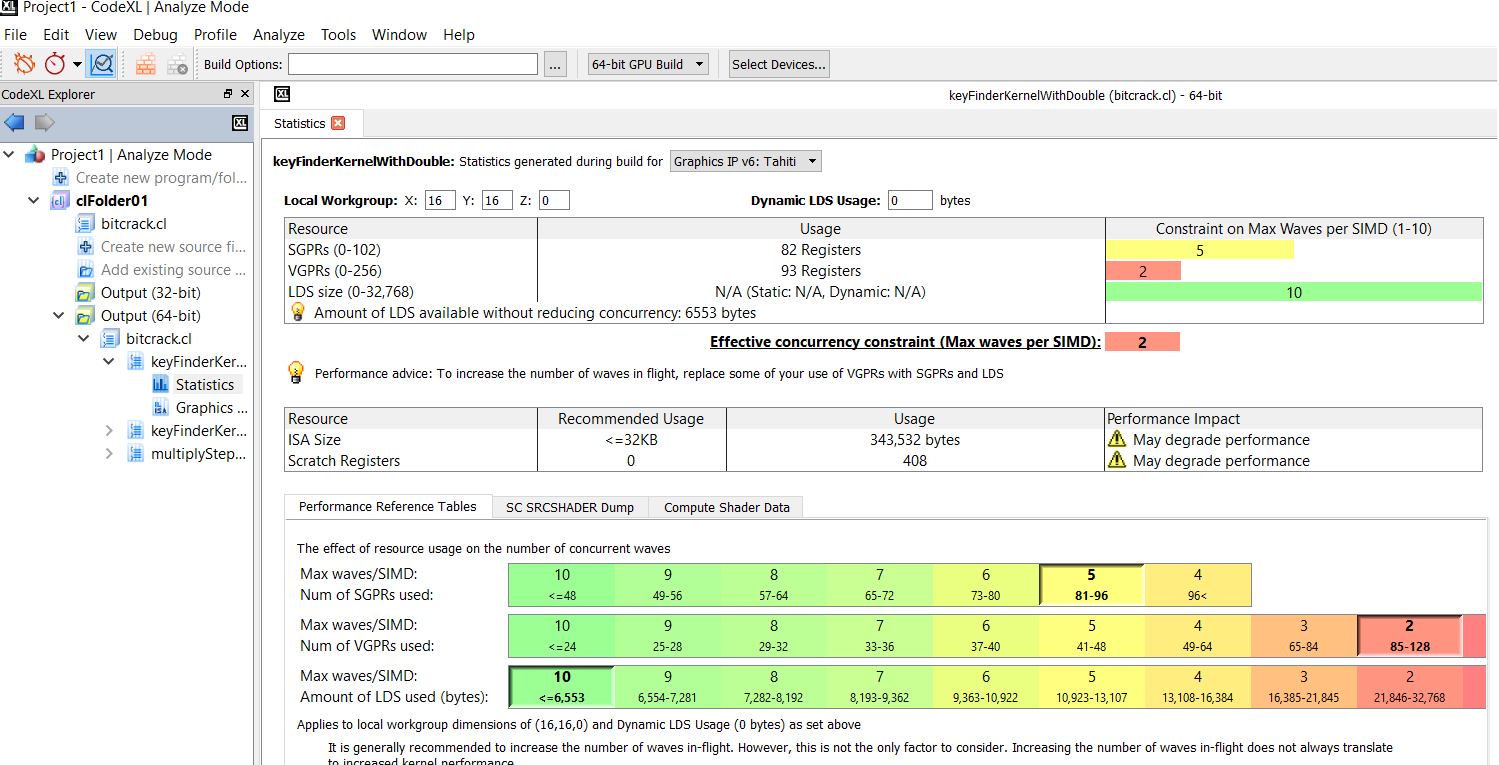
The opencl code as has a huge bug that brichard19 has not fixed. The cuda version works fine. |
|
Hi @AndrewBrz ... any progress? |
I changed the starting points and limited the number of kangaroos. I am currently working on a CPU and I have received the following results:
CPU i3, 534.2K j/s, 64 bit key, 100 tests - mean runtime ~ 3 hours
I have to say how the tests were conducted so that there were no questions about this. Each time a key was found, a new random 64-bit key was created and the search algorithm was run again
Now I'm busy porting code to OpenCL, this is a big and complicated job for me.
I think it's still possible to optimize the key finding time by calculating the correct jump size for each kangaroo.
Any ideas?
The text was updated successfully, but these errors were encountered: