Get Absolute distances value from the Kitti GT Depth map #6
Comments
|
Note that kitti_gt depth is sparse, so that "obstacle_depth = depth_map[y1:y2, x1:x2]" has many 0 values. You should exclude them first, and then find the min() or mean() value. |
|
@JiawangBian thanks for your inputs. it Worked !! |
|
@JiawangBian I used the kitti pretrained model to infer on some images using the inference.sh script The depth map were stored in the .npy dir structure. we read the file in the following way
Now to get the distance from this map what should be done, do we have to use the focal length and baseline formulation for it or we can directly lay the bbox on it and retrieve the distances byt min or mean |

|
Do not need to use the focal length and baseline. However, you need to know the scaling ratio between the predicted depth and ground truth. The monocular depth estimation is up to an unknown scale, so you need to recover it from an external source. Fortunately, the scale-consistent depth method ensures that our predicted depths on all images have the same scale. It means that you can recover the scale by using one image (where you have ground truth and you can compute median scaling, like in evaluation code), and then you can apply this scale on all other images. |
|
@JiawangBian Thanks for your quick reply I checked the test.py and found that an function compute_errors is called to calculate the errors which call the compute_error method when i run the test eval script i get the following output A bit confused on two parts
|

|
@JiawangBian I tried with above approch as illustrated in the following code base : When compared with the GT from KT there was 5 -6m @JiawangBian your inputs may be helpful |


@JiawangBian Thanks for the wonderful work !!
I wanted to get the absolute distances for objects from the Kitti GT depth map provided. I have downloaded the kitti raw dataset provided in the repo
To load the kitti GT depth map used the following code
the resulted out is as shown below
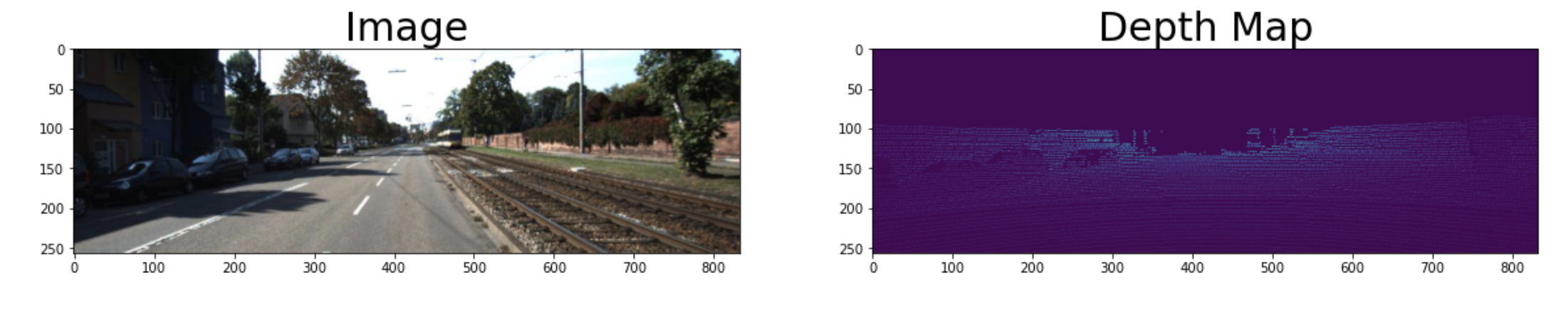
Than to get the bbox used an Yolov4 model
Overlayed the bbox on the depth map and took the depth value from the center point as shown
the resulted out is this where we get 0m distances

Do we have to any other pre-processing prior to using the kitti gt depth maps ?
The text was updated successfully, but these errors were encountered: