Knowing array size at compile time does not always help #33927
Labels
performance
Must go faster
Comments
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
I have a custom array type where the size is stored as one the type parameters. I hoped to increase performance in tight looping, since the indexing limits would be known at compile time. However, I have noticed that this approach can result in variable performance, depending on the size.
I managed to get a MWE, that does not use my custom array type, but shows the same symptoms. It consists of two
mysumfunctions, looping over a 3D Julia array. In the firstmysum1the indexing bounds are known at compile time, in the othermysum2, they are calculated at runtime.The data is as follows:
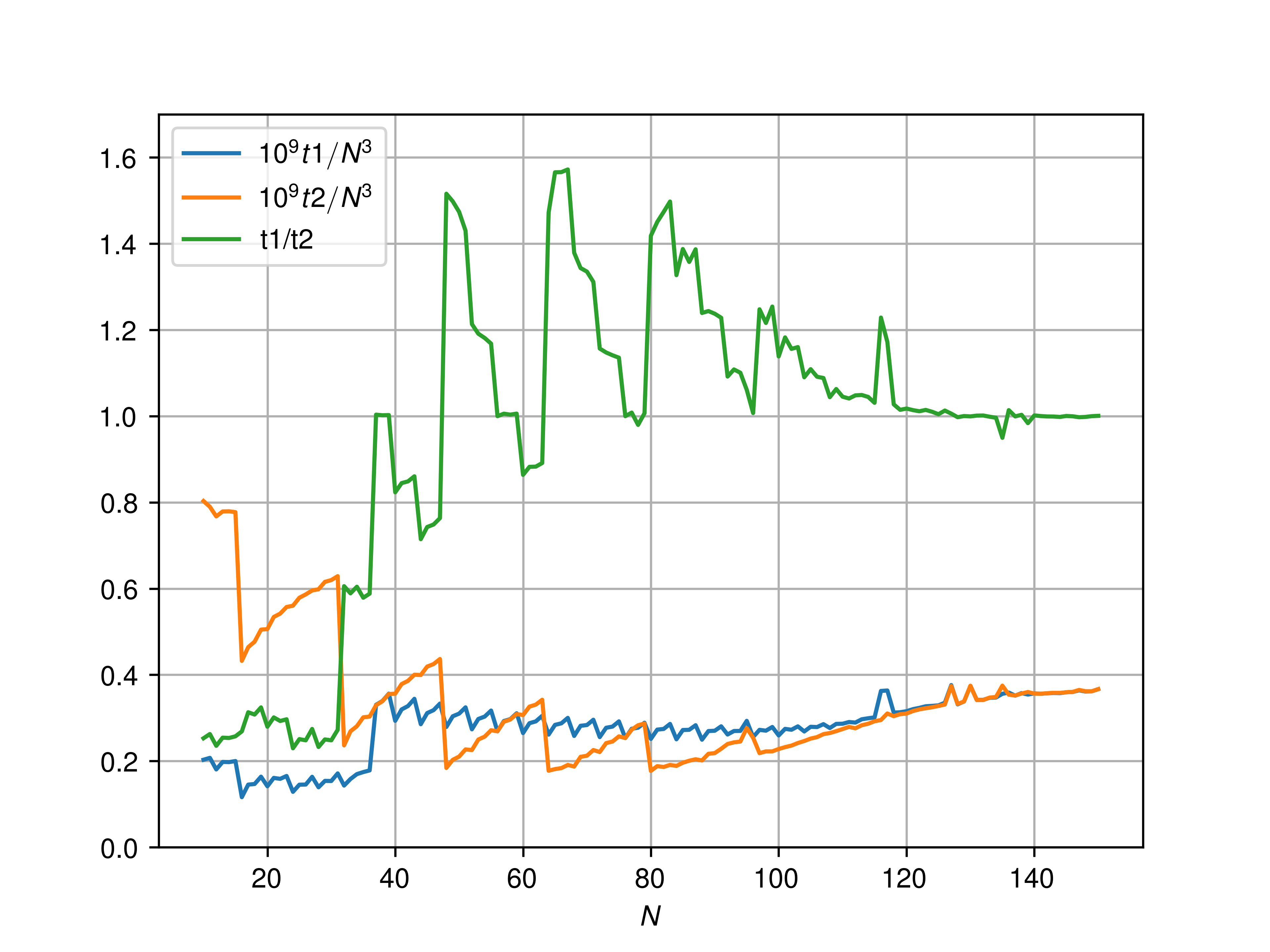
There seem to be a threshold around
N = 36below which knowing the array size at compile time is always advantageous. Above that, the speed up with respect to not knowing the size can vary significantly.I have examined the
@code_llvmoutput and both functions usually produce vectorised code. However, it appears that whenmysum2is faster thanmysum1, there is quite some unrolling going on.For instance, at
N=64, we have frommysum1(slower)while for
mysum2(faster):Note this is on
The text was updated successfully, but these errors were encountered: