RFC: cross entropy changes #9
Comments
|
The notation is based on this paper and the book Support Vector Machines. There The current way of how it is implemented is not really general. The derivative is based on the assumption that the prediction-function is a sigmoid, which it usually is. Where I wanted to go is to have this simplification in the tldr: you are absolutely right |
If we're considering refactoring, it might be worthwhile to consider longer, more descriptive names: |
|
I used to think that the variables should be close to the math, but I agree in this case. |
|
|
|
Back on names... how do you feel about would now become: I'd also prefer to use longer names like Thoughts? |
|
👍 |
|
note though that currently Edit: you wrote it correctly of course, I just wanted to recapitulate that since I recognise it is a somewhat confusion notation |
|
You have variables |
|
you are right with |
|
hmm... can you think of a good, short variable name to use in place of |
|
There doesn't seem to be a description in the book and I can't think of a good name. Since I have to leave right now, but I'll think of something and get back to you. Let's rename that one later (I could do that refactoring once we found a name) |
|
I can't think of a good name for that, but here are a few things I considered (and didn't love)... maybe it'll spark an idea for you:
I'll leave it as-is for now. |
That doesn't really fit because it's still a real number. It's a curious trick, really. (Note: Please don't interpret the following as me trying to "educate you" or something. I am just trying to put my understanding of it into words, which helps me structure my thoughts) the the "margin" is defined to be the hyperplane at Now the neat trick is the target vector convention which says that
So basically the result, currently called So how about we call it |
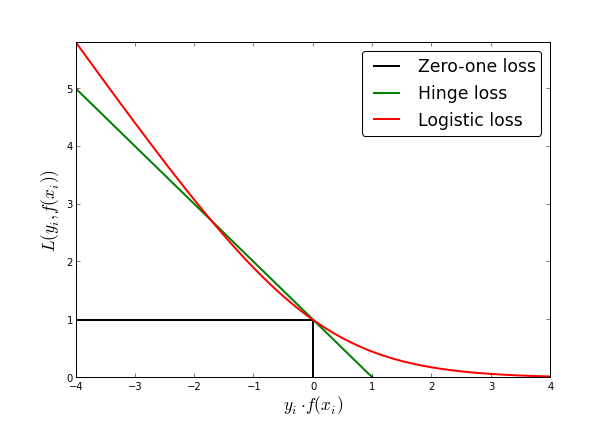
|
This was a well explained and thoughtful argument. I like |
I think this is wrong. I just did a quick back-of-the-napkin derivation, and I think the "deriv" should be dE/dy (not dE/ds):
crossentropy_deriv.pdf
code should probably be:
Note I switched y/t in the value function (I'm assuming y is the estimated probability and t is the target value)
Note that these calculations only make sense for y in (0,1)... if y is exactly 0 or 1 then we start to get infinities/NaNs. Do we want to check for this somehow?
Note that most computations actually care about the sensitivity of the error to the input to a sigmoid function. So if
y = sigmoid(s), we actually care aboutdelta = dE / ds = (dE / dy) * (dy / ds). When you work out the math of the derivative of the sigmoid times the derivative of the cross-entropy function, you end up with the simple:delta = y - t, which is what you see everywhere. The problem is that for generic libraries, the two derivatives need to be computed in different abstractions (loss vs activation).The text was updated successfully, but these errors were encountered: