Computing the inverse of Hessian in Newton's method #832
Comments
|
Is That said, not very many people have looked at how it works, and there is surely room for improvement. |
|
@timholy You are right. So
But it seems that no modification on Hessian leads to quicker convergence. I am not sure if this means that the current code has a room for improvement. |

|
Speed of convergence is often problem-dependent, so your results here may not be reflective of general trends. The bottom line is that Optim can't ignore this issue, because without it you can find situations where it would converge to a saddle point rather than a minimum. For example, try an unconditioned algorithm on "eigenvalue minimization" f(x) = (x'*(A*x))/(x'*x)for some matrix There's a long literature on Hessian modification but none of it is terribly satisfying. This is discussed a bit in section 3.4 of Nocedal & Wright. The steps taken by Optim---particularly the second one---do seem a bit unfortunate. That's what I mean by "potential room for improvement." You could analyze the algorithm in PositiveFactorizations for opportunities that make this less bad. |
|
Let me add another comment although Tim already answered above. Before we added these corrections the typical complaint was: why is my Newton run failing? We need a safeguarded method as the default choice. I can't remember if we allow for a linsolve choice, but if we don't it's in the making. Thanks for the question though! |
I am new to Julia. Recently, I tried to use the Optim package to optimize the Rosenbrock function with the Newton's method. The code is given as follows,
However, the path from Optim (green) looks different from what I obtained based on own code (orange).
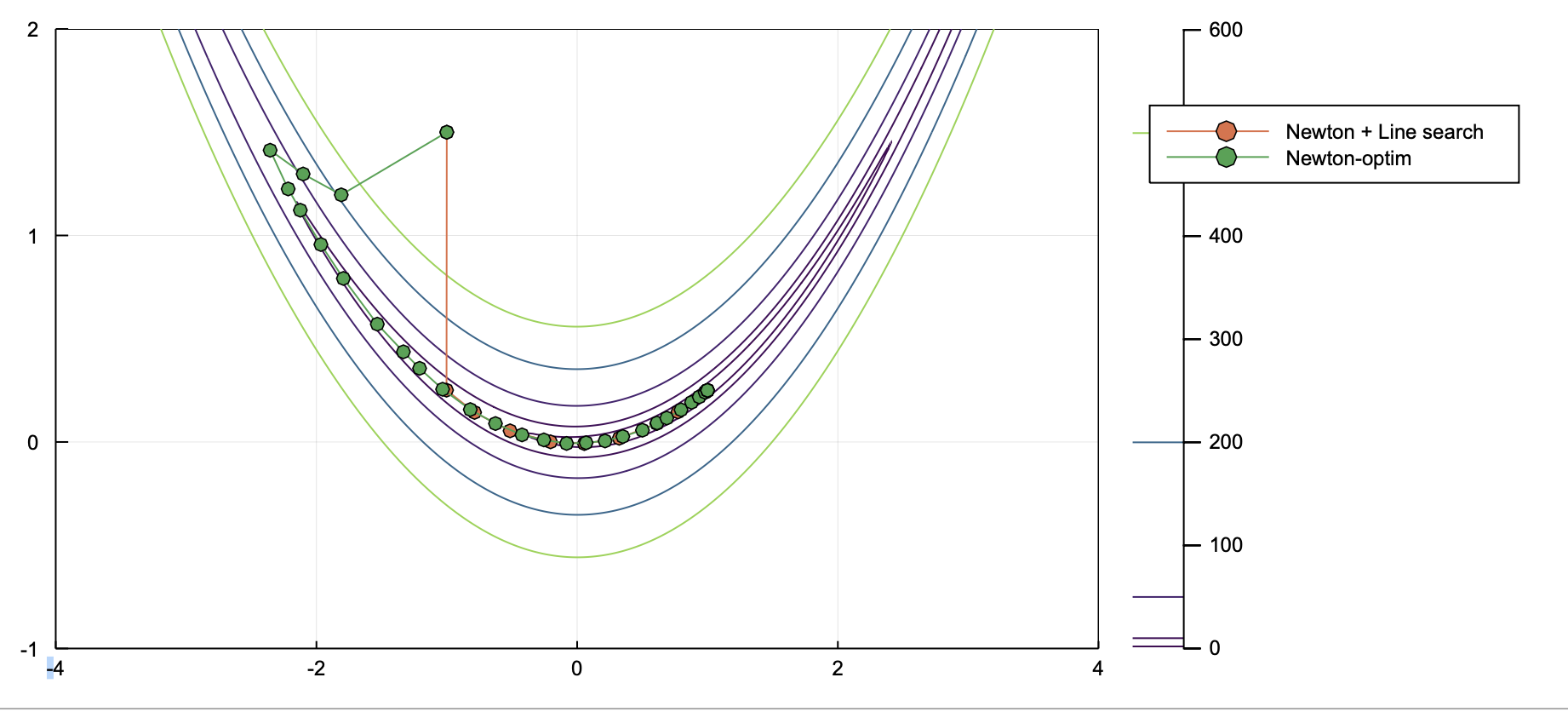
Clearly, the Newton SOLVER from Optim chose a different direction at the first step. By checking the code, I realized that the code used the cholesky factorization by default to compute inverse hessian.
Optim.jl/src/multivariate/solvers/second_order/newton.jl
Lines 64 to 77 in 0794f44
For a simple problem like 2*2 hessian, do we really need to do the cholesky factorization? Perhaps, it is better to have an option to let user compute H^-1 directly when H has a small size.
The text was updated successfully, but these errors were encountered: