Languages we speak and write are made up of several words often derived from one another. When a language contains words that are derived from another word as their use in the speech changes is called Inflected Language
"In grammar, inflection is the modification of a word to express different grammatical categories such as tense, case, voice, aspect, person, number, gender, and mood. An inflection expresses one or more grammatical categories with a prefix, suffix or infix, or another internal modification such as a vowel change" [Wikipedia]
The degree of inflection may be higher or lower in a language. As you have read the definition of inflection with respect to grammar, you can understand that an inflected word(s) will have a common root form. Let's look at a few examples,
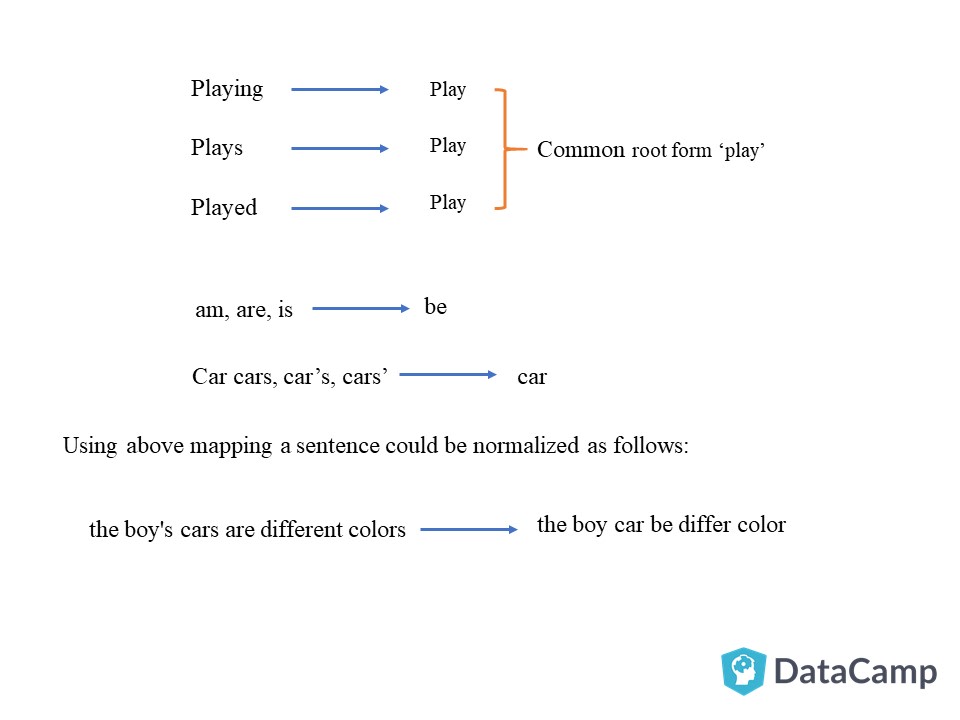
Above examples helps us to understand the concept of normalization of text, although normalization of text is not restricted to only written document but to speech as well.
The Normalization in this context can be of two Types
- Stemming
- Lemmatization
Stemming and Lemmatization helps us to achieve the root forms (sometimes called synonyms in search context) of inflected (derived) words.Stemming is different to Lemmatization in the approach it uses to produce root forms of words and the word produced. We will Learn more about this below.
"Stemming is the process of reducing inflection in words to their root forms such as mapping a group of words to the same stem even if the stem itself is not a valid word in the Language."
Stem (root) is the part of the word to which you add inflectional (changing/deriving) affixes such as (-ed,-ize, -s,-de,mis). So stemming a word or sentence may result in words that are not actual words. Stems are created by removing the suffixes or prefixes used with a word.
There are various Stemming Algorithms / methods in the NLTK library, These methods can be seen in the following diagram.
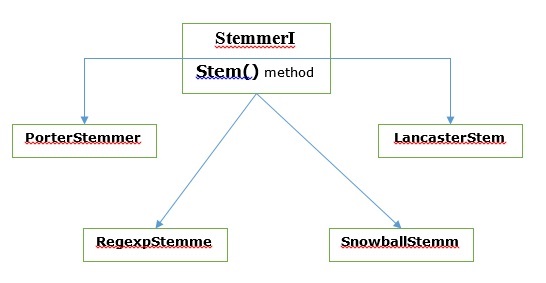
- Porter stemmer: This stemming algorithm is an older one. It’s from the 1980s and its main concern is removing the common endings to words so that they can be resolved to a common form
- Snowball stemmer: This algorithm is also known as the Porter2 stemming algorithm. It is almost universally accepted as better than the Porter stemmer, even being acknowledged as such by the individual who created the Porter stemmer.
- Lancaster stemmer: Just for fun, the Lancaster stemming algorithm is another algorithm that you can use. This one is the most aggressive stemming algorithm of the bunch.
- Regular Expression stemm: It basically takes a single regular expression and removes any prefix or suffix that matches the expression.
Some basic Examples of Stemming-
"Lemmatization, unlike Stemming, reduces the inflected words properly ensuring that the root word belongs to the language. In Lemmatization root word is called Lemma. A lemma (plural lemmas or lemmata) is the canonical form, dictionary form, or citation form of a set of words."
For example, runs, running, ran are all forms of the word run, therefore run is the lemma of all these words. Because lemmatization returns an actual word of the language, it is used where it is necessary to get valid words.
Some Examples of Lemmatization are as follows -

After Reading the full article we can derive the following inferences about the difference between Lemmatization and stemming.
- Stemming and Lemmatization both generate the root form of the inflected words. The difference is that stem might not be an actual word whereas, lemma is an actual language word.
- Stemming follows an algorithm with steps to perform on the words which makes it faster. Whereas, in lemmatization, we use WordNet corpus and a corpus for stop words as well to produce lemma which makes it slower than stemming.

We can see how the meaning of the word is conserved in Lemmatization as compared to Stemming