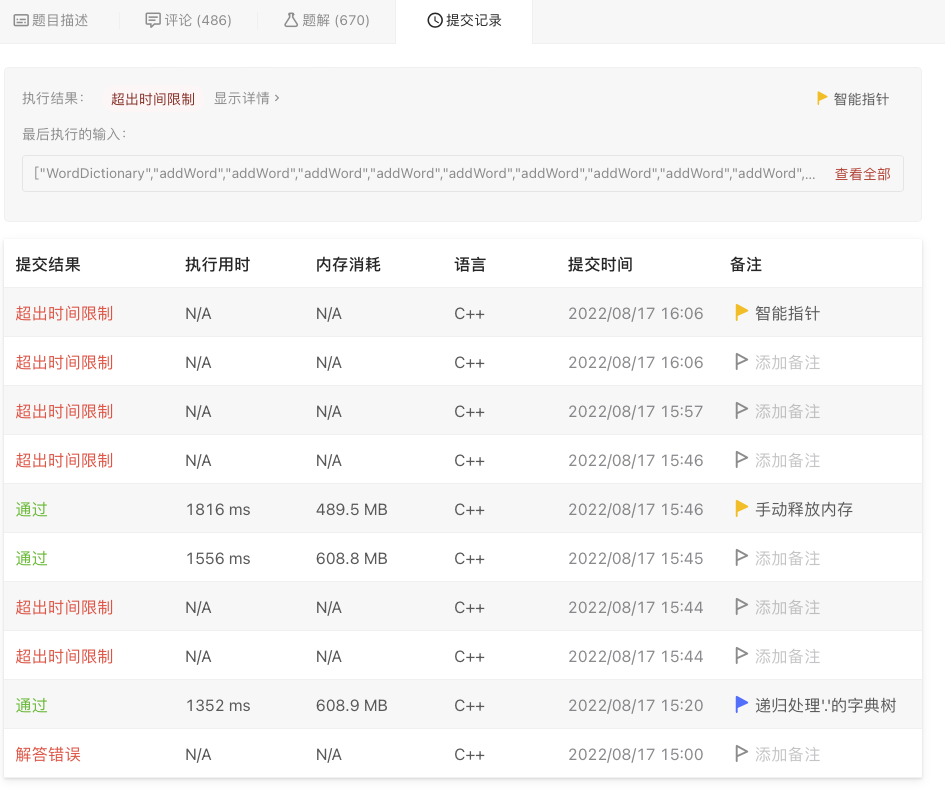
211.添加与搜索单词 - 数据结构设计 C++提交无故超时 #8693
Comments
|
首先,这个issue应该是无效的,你写的代码中有明显耗时操作。 struct TrieNode {
bool isEnd;
// 通过智能指针优化内存
vector<shared_ptr<TrieNode>> next;
TrieNode(): isEnd(false), next(26, nullptr) {}
};
class WordDictionary {
private:
shared_ptr<TrieNode> root;
public:
WordDictionary() {
root = make_shared<TrieNode>();
}
// 通过插入单词新建字典树
void addWord(string word) {
// 注意这里保存一个副本,维持在初始结点
auto node = root;
for (char& c: word) {
if (node->next[c-'a'] == nullptr) {
node->next[c-'a'] = make_shared<TrieNode>();
}
node = node->next[c-'a'];
}
// 最后一定要标识为叶子结点
node->isEnd = true;
}
bool find(const TrieNode* res, string& prefix, int idx) {
if (res != nullptr) {
if (prefix.size() == idx) {
return res->isEnd;
}
if (prefix[idx] == '.') {
for (auto& child: res->next) {
if (find(child.get(), prefix, idx+1)) {
return true;
}
}
} else {
return find(res->next[prefix[idx]-'a'].get(), prefix, idx+1);
}
}
return false;
}
bool search(string word) {
return find(root.get(), word, 0);
}
};本题使用智能指针,显然只是为了实现自动释放内存。这里并不涉及内存共享,因此完全可以用unique_ptr优化。 struct TrieNode {
bool isEnd;
vector<unique_ptr<TrieNode>> next;
TrieNode(): isEnd(false), next(26) {}
};
class WordDictionary {
private:
unique_ptr<TrieNode> root;
public:
WordDictionary() {
root = make_unique<TrieNode>();
}
// 通过插入单词新建字典树
void addWord(string word) {
// 注意这里保存一个副本,维持在初始结点
auto node = root.get();
for (char& c: word) {
if (node->next[c-'a'] == nullptr) {
node->next[c-'a'] = make_unique<TrieNode>();
}
node = node->next[c-'a'].get();
}
// 最后一定要标识为叶子结点
node->isEnd = true;
}
bool find(const TrieNode* res, string& prefix, int idx) {
if (res != nullptr) {
if (prefix.size() == idx) {
return res->isEnd;
}
if (prefix[idx] == '.') {
for (auto& child: res->next) {
if (find(child.get(), prefix, idx+1)) {
return true;
}
}
} else {
return find(res->next[prefix[idx]-'a'].get(), prefix, idx+1);
}
}
return false;
}
bool search(string word) {
return find(root.get(), word, 0);
}
};leetcode默认开-O2,我记得unique_ptr在开-O1的情况下就能把额外代码优化掉。所以,不知道是我代码写得有问题,还是leetcode的-O2比较拉胯。 |
|
@zhenliang153 感谢您!使用 unique_ptr 优化之后确实可以A,能不能解释一下为啥 unique_ptr 比 shared_ptr 性能更好呢 另外还有一个TLE的问题也想请教一下,关于 745. 前缀和后缀搜索 中我的 C++代码 使用的两个前缀树,可以通过14个用例 提交详情在这,同样的Java代码就可以A |
|
@EricPengShuai 745中有些可以用 引用传递 代替 值传递 的地方,修改后就可以AC了,不到500ms。主要应该是在 class Trie {
public:
vector<Trie*> children;
vector<int> indexList;
Trie(): children(26), indexList() {}
void insert(const string& word, int i) {
Trie* root = this;
for (auto c : word) {
int id = c - 'a';
if (root->children[id] == nullptr) {
root->children[id] = new Trie();
}
root = root->children[id];
// 注意维护下标数组
(root->indexList).push_back(i);
}
}
vector<int>* startsWith(const string& prefix) {
Trie* root = this;
for (auto c : prefix) {
int id = c - 'a';
if (!root->children[id])
return nullptr;
root = root->children[id];
}
// 返回指定前缀的下标数组
return &(root->indexList);
}
};
class WordFilter {
public:
Trie *rt, *tr;
WordFilter(vector<string>& words) {
rt = new Trie();
tr = new Trie();
int cnt = 0;
// 新建两个字典树
for (auto& word : words) {
rt->insert(word, cnt);
reverse(word.begin(), word.end());
tr->insert(word, cnt);
cnt++;
}
}
int f(string pref, string suff) {
vector<int>* pv1 = rt->startsWith(pref);
if (pv1 == nullptr) {
return -1;
}
reverse(suff.begin(), suff.end());
vector<int>* pv2 = tr->startsWith(suff);
if (pv2 == nullptr) {
return -1;
}
vector<int>& v1 = *pv1;
vector<int>& v2 = *pv2;
if (v1.size() == 0 || v2.size() == 0) return -1;
// 找出指定前缀下标数组和指定后缀下标数组的最大公共元素,逆序找
int i = v1.size() - 1, j = v2.size() - 1;
while (i >= 0 && j >= 0) {
if (v1[i] == v2[j]) {
return v1[i];
}
if (v1[i] > v2[j]) i--;
else j--;
}
return -1;
}
};
/**
* Your WordFilter object will be instantiated and called as such:
* WordFilter* obj = new WordFilter(words);
* int param_1 = obj->f(pref,suff);
*/
/**
* Your WordFilter object will be instantiated and called as such:
* WordFilter* obj = new WordFilter(words);
* int param_1 = obj->f(pref,suff);
*/ |
一般而言, |
|
@zhenliang153 感谢解答!学习了👍 |
20220820个更新: struct TrieNode {
bool isEnd;
array<unique_ptr<TrieNode>, 26> next;
TrieNode(): isEnd(false) {}
}; |
|
@zhenliang153 感谢,我试试了,确实可以进一步优化,您太细节了!👍 |
你的 LeetCode 用户名
coder_ps
Bug 类型
描述
C++ 提交的代码无故超时
你使用的语言
C++
你提交或者运行的代码
期望行为
不超时
屏幕截图
The text was updated successfully, but these errors were encountered: