[English ver]
Implement regular expression matching with support for '.' and '*'.
'.' Matches any single character.
'*' Matches zero or more of the preceding element.
The matching should cover the entire input string (not partial).
The function prototype should be:
bool isMatch(const char *s, const char *p)
Some examples:
isMatch("aa","a") → false
isMatch("aa","aa") → true
isMatch("aaa","aa") → false
isMatch("aa", "a*") → true
isMatch("aa", ".*") → true
isMatch("ab", ".*") → true
isMatch("aab", "c*a*b") → true
Notice that , matching should cover the entire input string ,and '*' can be 0 , and it means preceding element doesn't exist , it could be cover the entire input string .
class Solution {
public boolean isMatch(String text, String pattern) {
if (pattern.isEmpty()) return text.isEmpty();
boolean first_match = (!text.isEmpty() &&
(pattern.charAt(0) == text.charAt(0) || pattern.charAt(0) == '.'));
//if the pattern.charAt(1) == '*' it means your have two way to get it right , you can keep the '*' and it's preceding element or you can discard they and check the rest of them.
if (pattern.length() >= 2 && pattern.charAt(1) == '*'){
return (isMatch(text, pattern.substring(2)) ||
(first_match && isMatch(text.substring(1), pattern)));
} else {
return first_match && isMatch(text.substring(1), pattern.substring(1));
}
}
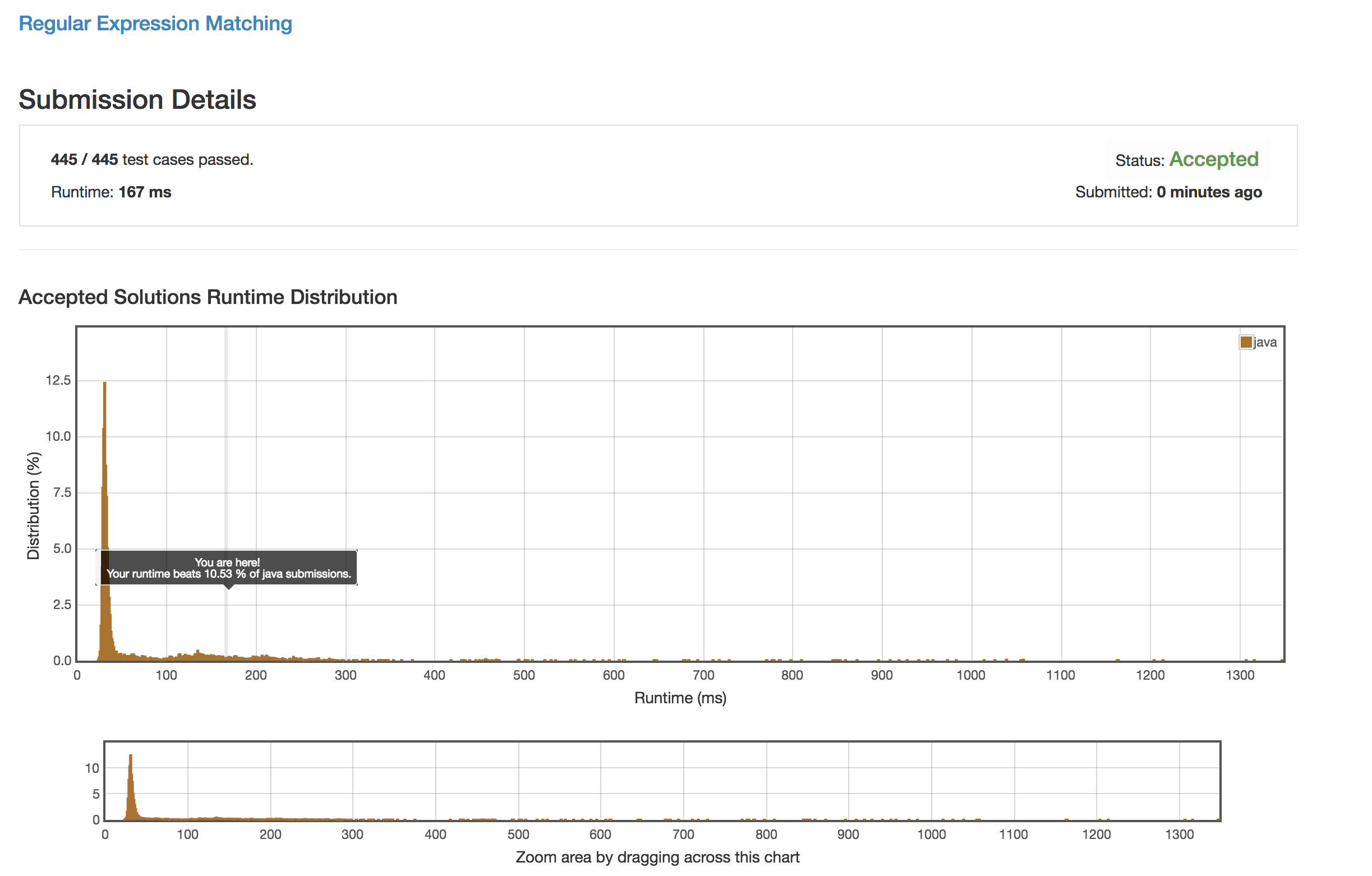
}
Analysis Use recursion is a easy way to understand , first we compare the first digit , there are some situation , if the pattern's next digit is '*' ,then it could be discard or keep the result of these two digit . update text and pattern and then keep camparing the digit of text and pattern .
Time complexity :
Let T,P be the length of text and pattern respectively .
In the worst case ,isMatch(text[i:], pattern[2j:]) would be call to i+j times ,
( i )
and strings of the order O(T - i) and O(P - 2*j) will be made , so the time complexity is
T p/2 i+j [T+2P]
∑ ∑ ( i )O(T+P-i-2j) , in some translation we could get it's bounder O((T+P)2 ).
i=0 j=0
Space complexity :
every time we call isMatch ,we will create strings as described upon ,it may be duplicates .
[T+2P]
if memory don't free , it will cost O((T+P)2 ) space .
2 2
Even P and T only request for O( T + P ) unique suffixes .
//Todo complexity
Top-Down Variation
enum Result {
TRUE, FALSE
}
class Solution {
//cache the intermediate result
Result[][] memo;
public boolean isMatch(String text, String pattern) {
memo = new Result[text.length() + 1][pattern.length() + 1];
return dp(0, 0, text, pattern);
}
public boolean dp(int i, int j, String text, String pattern) {
if (memo[i][j] != null) {
return memo[i][j] == Result.TRUE;
}
boolean ans;
if (j == pattern.length()){
ans = i == text.length();
} else{
boolean first_match = (i < text.length() &&
(pattern.charAt(j) == text.charAt(i) ||
pattern.charAt(j) == '.'));
//if the pattern.charAt(1) == '*' it means your have two way to get it right , you can keep the '*' and it's preceding element or you can discard they and check the rest of them.
if (j + 1 < pattern.length() && pattern.charAt(j+1) == '*'){
ans = (dp(i, j+2, text, pattern) ||
first_match && dp(i+1, j, text, pattern));
} else {
ans = first_match && dp(i+1, j+1, text, pattern);
}
}
memo[i][j] = ans ? Result.TRUE : Result.FALSE;
return ans;
}
}
Bottom-Up Variation
class Solution {
public boolean isMatch(String text, String pattern) {
boolean[][] dp = new boolean[text.length() + 1][pattern.length() + 1];
dp[text.length()][pattern.length()] = true;
for (int i = text.length(); i >= 0; i--){
for (int j = pattern.length() - 1; j >= 0; j--){
boolean first_match = (i < text.length() &&
(pattern.charAt(j) == text.charAt(i) ||
pattern.charAt(j) == '.'));
if (j + 1 < pattern.length() && pattern.charAt(j+1) == '*'){
dp[i][j] = dp[i][j+2] || first_match && dp[i+1][j];
} else {
dp[i][j] = first_match && dp[i+1][j+1];
}
}
}
return dp[0][0];
}
}
Analysis
This method actually use the recursion of Approach 1 , but it cache the intermediate results which save a lot of cost .
Time complexity :Let T, P be the lengths of the text and the pattern respectively. The work for every call to dp(i, j) for i=0, ... ,T; j=0, ... ,P is done once, and it is O(1) work. Hence, the time complexity is O(TP). Space complexity : The only memory we use is the O(TP) boolean entries in our cache. Hence, the space complexity is O(TP).
If you have any suggestions to make the logic and implementation more better , or you have some advice on my description. Please let me know!Thanks!