RAdam Instability vs AdamW / Adam #54
Comments
|
Thanks for asking! I have noticed something similar to this. Setting Specifically, I believe this issue is caused by that the gradient is too large in the begining of training. If the gradient is larger than one, then SGD would have larger step sizes than Adam/AdamW--adaptive optimizer scales learning rates with gradients' second momentom, if the second momentom is larger than one, directly removing it would leads to larger learning rate, which could potentially be over-large. Thus, in this situation, you can set |
|
Thanks for the quick reply!! Appreciate it! So I tried the suggestion where we set lr_t = -1* lr instead of lr_t = lr / (1 - beta1**t). The first image shows lr_t = -lr, [lr = 1e-3]. When p < 5, the loss is still very large [17 zeros] The second image is when lr_t = lr / (1 - beta1**t). When p < 5, the loss is even larger than the first image [26 zeros]. So it partially solves the issue. I'm currently trying to see how I can reduce the loss [maybe by change other params.] Anyways thanks once again for the swift reply! |


|
So I might have solved some of the issue.
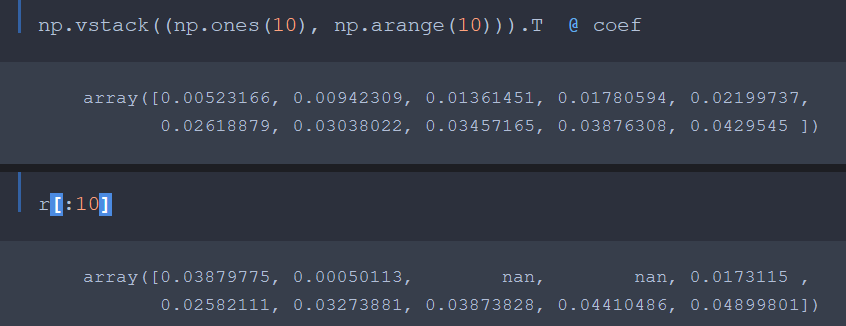
So I just fit a line to do "analytic continuation" to kinda "derive" r when (p < 5). Not sure if this kinda reverts to back to using AdamW and variants. [r = 0.00523166 + 0.00419143*t] when (p < 5)
You can see when t = 1, r = 0.00942309 or so. Until p = 5, then r uses the original equation.
Maybe one way to alleviate this issue is when p < 5, RAdam trains alongside AdamW. If RAdam goes haywire (like norm explodes), then RAdam reverts back to using AdamW. [PS SGD with Momentum = 0.9 also diverges on unstandardized data]. |



|
I also tried comparing AdamW / Adam's sensitivity to standard deviation of each feature. As std(X)->inf, obvi the MSE would get larger. However, AdamW's loss doesn't diverge. On the other hand due to RAdam using Momentum when (p<5) only, the MSE diverges after when std(X) exceeds 5 or so. Even at staggering large std(X)'s [like 100], AdamW successfully reduces the loss. On the other hand, RAdam, well, diverges. So maybe from empirical tests, RAdam should default to AdamW if std(X) exceeds some number, say 5 or even 4? Otherwise, the loss can quickly diverge. |




|
Actually sorry on further investigation, it's not std(X) thats causing the issue. It's rather the max(abs(X)) thats the issue. From experiments, during the first batch, I found if What I find interesting is when standardization is on, in both RAdam and Adam(W), the norm of the second moment is ALWAYS a small number, whilst the norm of the first moment is much larger. So for now, if I find after the first batch that |
|
Hi, thanks for the discussion. For the implementation, setting lr to negative is not enough, I added a condition at https://github.com/LiyuanLucasLiu/RAdam/blob/master/radam/radam.py#L88 to skip updates when the learning rate is negative. Without adding this condition, the algorithm would do gradient ascent in the first few updates, which would cause serious problems. |
|
Ohhhhh oops I might have missed that! I'll read about it! Thanks again! OHHH your right! Essentially if step_size < 0, you're skipping the first few SGD updates, then after the 5th iteration, the parameters get updated. Very interesting fix! My bad I didn't notice that! |
|
So you're right! Though Glorot init kinda caused RAdam to have higher MSE than Adam. LSUV kinda solved this issue. Now, both RAdam and Adam even on weirdly large inputs seem to work.
Anyways thanks once again for the quick replies! |

Late to the party, but once again good work to you all @LiyuanLucasLiu !
So I was testing RAdam vs AdamW on simple linear models [ie Logistic Regression / Linear Regression]. Obviously for these small problems, using new methods is a bit overdoing it, but trying them on small problems [Sklearn datasets like Boston, MNIST, Wine] is also important :)
After finding the best LR using the Learning Range Finder (which turns out to be the same LR for both [0.046]) + using gradient centralization + batch size = 16, with careful bias intialization (mean(y)), RAdam does seem more "stable" than AdamW.

However, I noticed that if you do NOT standardize your data, RAdam's gradient diverges dramatically. The LR Range Test on NOT standardized data gave LR = 6.51e-05, which is super small. But, RAdam diverges.

AdamW [lr = 1e-3] also has higher error when not standardized, however, the loss doesn't diverge a lot.

I also tried before (p < 5), to manually clip gradients by dividing by its norm. It's now much closer to AdamW.

So my Q is: is this expected of RAdam to diverge if the dataset is not standardized? Should AdamW be used instead? Is it because of SGD + Momentum when (p < 5) that this divergement is seen?
The text was updated successfully, but these errors were encountered: