topic -1 #485
Comments
|
A feature of HDBSCAN is that it does not force datapoints in clusters but recognizes that some could be outliers. Often, outliers are found when using reduced sentence embeddings together with HDBSCAN. In practice, this should not be an issue as it helps to accurately extract the topic representations. Since there is little noise in the clusters, it becomes easier to extract relevant words. There are two ways to deal with many outliers. First, use In other words, you could use the resulting probability_threshold = 0.01
new_topics = [np.argmax(prob) if max(prob) >= probability_threshold else -1 for prob in probs]Second, in the FAQ you can find instructions for reducing the amount of outliers. Do note that lowering the number of outliers comes with a risk: if you remove all outliers in the training step then it is likely that clusters contain much more noise which could hurt the topic representation. |
|
Hi, I tried the solution of assigning the topic by the probabilities. And then I was surprised to find that It is possible that bertopic will assign a text to one topic but the max prob of the text will be another topic. What can I understand from such a situation? |
|
Yes, that might happen. I believe there is some instability between fitting the HDBSCAN model (hard-clustering) and extracting the probabilities from it (soft-clustering). From what I could gather reading through the HDBSCAN repo, although it might happen the clusters it is being assigned to should still be similar. You can find a bit more information about that here. |
|
Hello, I would also like to use your proposed solution of forcing documents out of the outlier topic by using |
|
@aileen-reichelt That is possible by using the BERTopic/bertopic/_bertopic.py Lines 657 to 661 in 681ac26 Here, you can pass in your updated |
|
Hi, my question is if there is another solution to this problem? thank you before after |


|
Hi MaartenGr The code: The Error: |

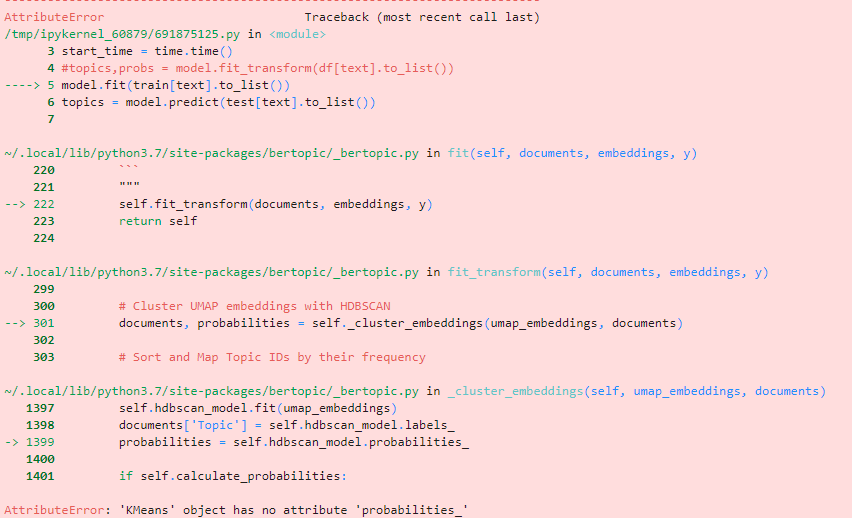
|
@roik2500 Based on your output, my guess would be that you are not using BERTopic v0.10. In that version, the feature of using different clustering models was introduced. Upgrading the version with |
|
Hi @MaartenGr, I have assigned the outliers generated by my model (with topic - 1) to the clusters based on a threshold, as you suggested above, however, when I pass |
|
@DieSpekboom To also update the counts aside from the topic representation, you will have to run the following: import pandas as pd
import numpy as np
# Extract new topics
probability_threshold = 0.01
new_topics = [np.argmax(prob) if max(prob) >= probability_threshold else -1 for prob in probs]
# Update the internal topic representation of the topics
# NOTE: You can skip this step if you do not want to change the topic representations
topic_model.update_topics(docs, new_topics)
# Update topic frequencies
documents = pd.DataFrame({"Document": docs, "Topic": new_topics})
topic_model._update_topic_size(documents)
|
|
Since this was active a while ago, I am going ahead and will close this issue. If, however, you want to re-open this issue, please let me know! |
|
Hi! I wonder if it's possible to remove the -1 topic entirely by setting the threshold to be 0 and get the full list of new topics? It looks like the model does not allow using And just to confirm, does the probability of topics for each document change through the process? Thank you! |
|
@Syarotto Yes, by setting the threshold to 0 all documents will be assigned to a non-outlier topic. The problem, however, with assigning all documents to a non-outlier topic in model itself is that it will likely hurt the topic description as outliers are now found within the cluster which typically adds noise. For that reason,
That depends on the process you are referring to. Having said that, the probability should remain stable after training. |
Thank you for confirming! It looks like k-means does not have probability associated with that, if I got it correctly. Does it mean that we have to choose between the outlier topic and the probabilities? |
Although it does not generate probabilities, you could calculate the distance between the point and the cluster's center as a proxy for that. How you would like to use that depends on your use case and whether you want some sort of normalization procedure for calculating the distances.
I am not sure, but I believe that in scikit-learn there currently are no clustering models that directly give back probabilities and model no outliers. However, you can use most clustering models in BERTopic, so if you find any that support both, you could use those. |
That's great to know, thank you so much for your help :) |
i use with berttopic to analyze text in social media, dividing the docs to topics and looking for some common and important words in each division.
in some case, my model input is 150,000 docs and after the transform, the frequency of topic -1 is very high( 35%-40%).
so I want to know what exactly is topic -1 and what the problem cause is...
Thank you all
The text was updated successfully, but these errors were encountered: