+++ title = "Spark on YARN:借助 YARN 的资源管理和计算调度,打造高效的 Spark 架构" date = "2023-09-01T21:30:00+08:00" tags = ["Spark"] keywords = ["Spark", "YARN", "Spark on YARN", "分布式", "资源管理"] images = ["https://spark.apache.org/docs/latest/img/cluster-overview.png"] toc = true +++
{kind=link}
摘要:本文介绍了 Spark on YARN 架构 的基本原理和特点。文章首先介绍了 Hadoop YARN 架构 的两个核心组件:资源管理和计算调度,然后介绍了 Spark 架构 的主要组成部分和功能。文章最后总结了 Spark on YARN 架构 的优势和应用场景。
Hadoop YARN 架构 1
YARN 本身是一个资源调度框架,负责对运行在内部的计算框架进行资源调度管理。其为分布式计算任务提供两个..独立..的进程:
- 资源管理
- 计算调度
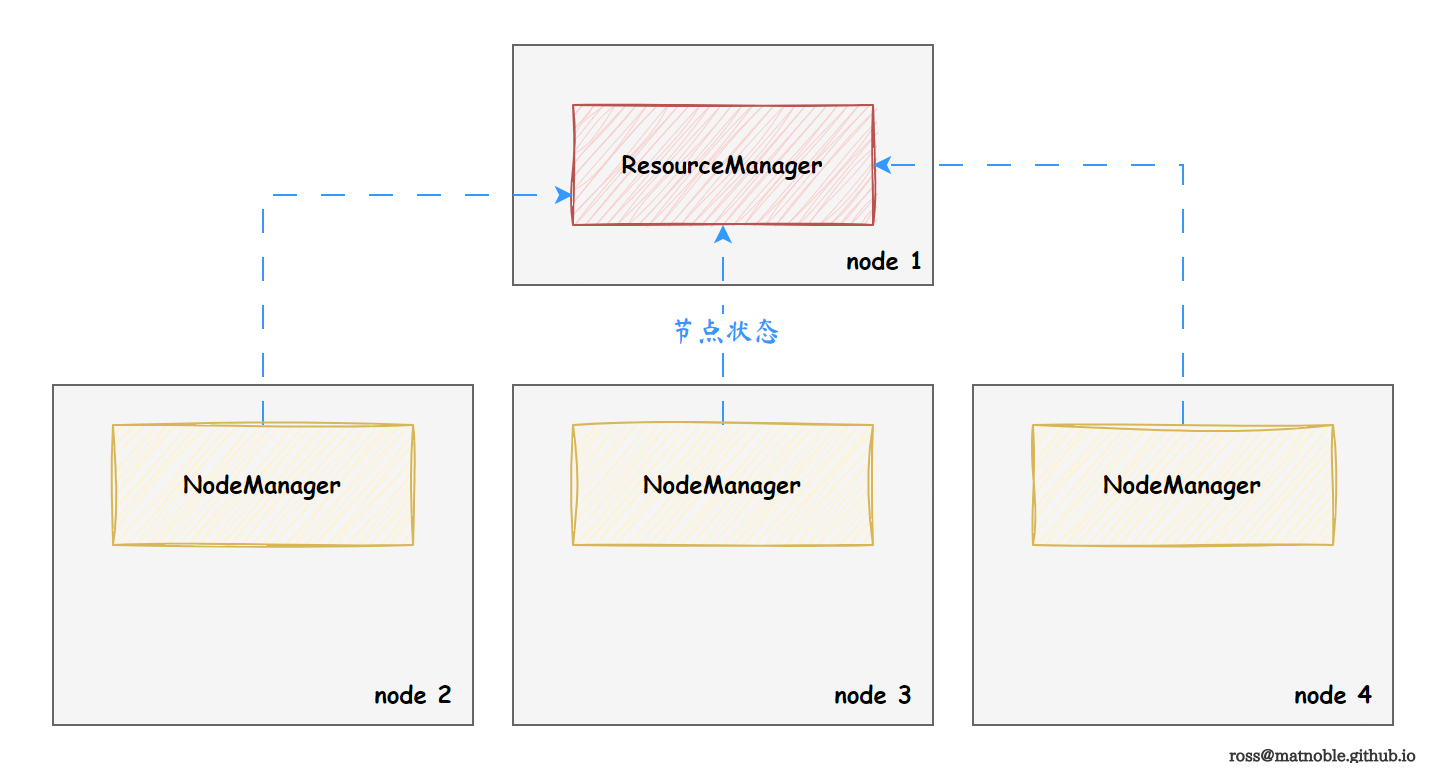
{{< imgcap src="https://cdn.jsdelivr.net/gh/MatNoble/Images/win/yarn1-202309012128542.png" title="资源层面" >}}
{kind=link}
在集群中,管理资源有两个角色,组成数据计算框架
ResourceManager
负责为各任务分配资源NodeManager
每个计算节点上仅且仅有 1 个NodeManager,负责向ResourceManager“上报” 节点信息(CPU,内存,磁盘,网络等监控信息)
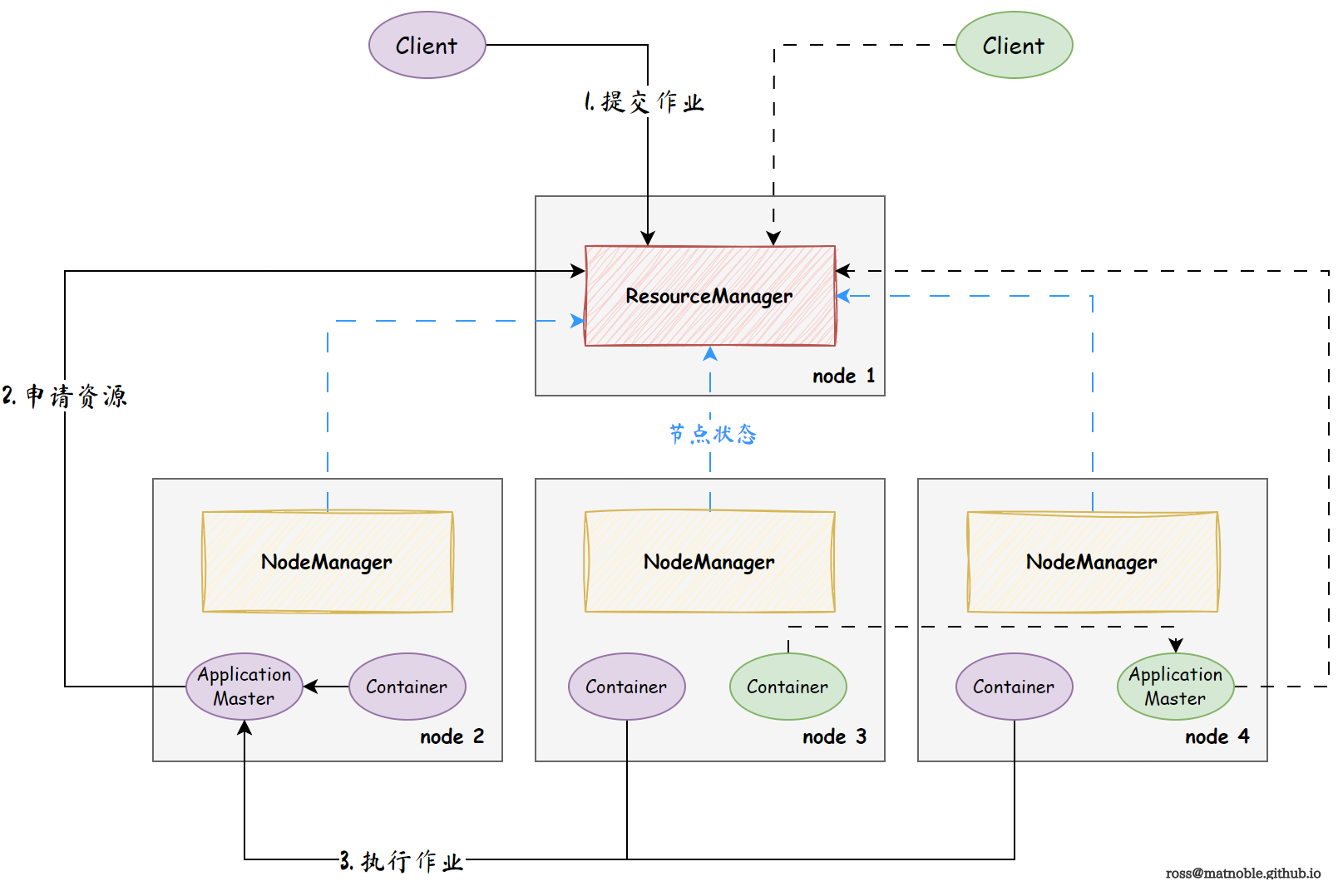
{{< imgcap src="https://cdn.jsdelivr.net/gh/MatNoble/Images/win/yarn3-202309012130754.png" title="计算层面" >}}
{kind=link}
..计算..发生在 NodeManager 所在的节点上,有两个角色:
ApplicationMaster负责向ResourcesManager申请资源,并调度作业(Task)Container负责执行具体的计算作业
在 YARN 中,每个应用程序都有一个 ApplicationMaster ,负责与 ResourceManager 交互申请资源,并与 NodeManager 交互启动和监控任务。
{{< imgcap src="https://spark.apache.org/docs/latest/img/cluster-overview.png" title="Spark 架构" >}}
Spark 与 YARN 非常类似,都有资源管理模块和计算模块,这两个模块都有各自的管理进程和执行进程。
Spark 架构 由以下几个部分组成:
- Driver 程序:负责创建 SparkContext 对象,并将应用程序逻辑划分为多个 Task
- Executor 进程:负责执行 Task,并将结果返回给 Driver
- Cluster Manager :负责管理集群中的资源和节点,可以是 YARN ,也可以是其他类型
- SparkContext 对象:负责与 Cluster Manager 交互申请资源,并创建 Executor
- RDD :弹性分布式数据集,是 Spark 的核心抽象,表示一个不可变、分区、可并行操作的数据集合
- DAGScheduler :负责将 RDD 的操作转换为 DAG (有向无环图),并将 DAG 划分为多个 Stage
- TaskScheduler :负责将 Stage 划分为多个 Task,并将 Task 分配给 Executor 执行
Spark on YARN 是指将 Spark 应用程序运行在 YARN 集群上,利用 YARN 提供的资源管理和计算调度功能。在这种架构下,Spark 中的角色和 YARN 中的角色一一对应:
ClusterManager相当于ResourceManager,负责资源调度WorkerNode相当于NodeManager,负责管理节点状态Driver相当于ApplicationMaster,负责调度作业,可以运行在集群外部的客户端,也可以运行在集群内部的某个节点上Executor相当于Container,负责具体的计算任务
Spark on YARN 架构的优势:
- 可以充分利用 YARN 集群的资源,实现资源的动态分配和共享,避免资源的浪费和冲突
- 可以与其他运行在 YARN 上的应用程序协同工作,实现数据的高效处理和分析
- 可以享受 YARN 提供的高可用性、安全性、监控和管理等功能,提高 Spark 应用程序的稳定性和可靠性
- 可以灵活地选择 Spark 应用程序的运行模式,根据不同的场景和需求进行优化和调整
Spark on YARN 架构的应用场景
- 需要处理大规模、多样化、复杂的数据,例如机器学习、数据挖掘、图计算等
- 需要与其他运行在 YARN 上的应用程序进行数据交互,例如 Hadoop MapReduce、Hive 等
- 需要在同一个集群上运行多个 Spark 应用程序,实现资源的合理分配和利用
- 需要保证 Spark 应用程序的高可用性、安全性、监控和管理等功能
本文介绍了 Spark on YARN 架构 的基本原理和特点,以及它的优势和应用场景。Spark on YARN 架构 是一种将 Spark 应用程序运行在 YARN 集群上的架构,可以充分利用 YARN 提供的资源管理和计算调度功能,实现数据的高效处理和分析。Spark on YARN 架构适合处理大规模、多样化、复杂的数据,与其他运行在 YARN 上的应用程序协同工作,以及在同一个集群上运行多个 Spark 应用程序。