[TOC]
功能实现
- 运用AngularJS前端框架的常用指令
- 完成品牌管理的列表功能
- 完成品牌管理的分页列表功能
- 完成品牌管理的增加功能
- 完成品牌管理的修改功能
- 完成品牌管理的删除功能
- 完成品牌管理的条件查询功能


前端框架 AngularJS 四大特征
- MVC 模式
- Model: 数据,其实就是angular变量($scope.XX);
- View: 数据的呈现,Html+Directive(指令);
- Controller: 操作数据,就是function,数据的增删改查;
- 双向绑定 框架采用并扩展了传统HTML,通过双向的数据绑定来适应动态内容,双向的数据绑定允许模型和视图之间的自动同步。遵循声明式编程应该用于构建用户界面以及编写软件构建,而指令式编程非常适合来表示业务逻辑的理念。
- 依赖注入 对象在创建的时候,其依赖对象由框架来自动创建并注入进来。即最少知道法则。
- 模块化设计
- 高内聚低耦合法则 1)官方提供的模块 ng、ngRoute、ngAnimate 2)用户自定义的模块 angular.module('模块名',[ ])
常见指令
-
ng-app 定义 AngularJS 应用程序的根元素,表示以下的指令 angularJS 都会识别,且在页面加载完时会自动初始化。
-
ng-model 指令用于绑定变量,将用户在文本框输入的内容绑定到变量上,而表达式可以实时地输出变量。
-
ng-init 对变量初始化或调用某方法。
-
ng-controller 用于指定所使用的控制器,在控制器中定义函数和变量,通过scope 对象来访问。
-
ng-click 单击事件指令,点击时触发控制器的某个方法。
-
ng-if 判断语句,条件不存在就不执行。
-
ng-repeat 指令用于循环集合变量。
-
$index 用于获取 ng-repeat 指令循环中的索引。
-
$http 内置服务,用于访问后端数据。
-
$location 服务,用于获取链接地址中的参数值。
$location.search()['id']id对应的值。(注:地址中 ? 前需要添加 # )eg: http://localhost:9102/admin/goods_edit.html#?id=149187842867969
-
ng-bind-html 指令用于显示 html 内容
-
app.filter 过滤器,通过 | 来调用过滤器
-
$sce 服务 严格控制上下文访问,为防止 跨站XSS。该服务可以实现安全控制,比如允许html标签的插入转换。
复选框的使用
定义一个用于存储选中 ID 的数组,当我们点击复选框后判断是选择还是取消选择,如果是选择就加到数组中,如果是取消选择就从数组中移除。在后续点击删除按钮时需要用到这个存储了 ID 的数组。
// 存储当前选中复选框的id集合
$scope.selectIds = [];
$scope.updateSelection = function($event, id){
if ($event.target.checked) { // 当前为勾选状态
$scope.selectIds.push(id); // 向selectIds集合中添加元素
} else {
var index = $scope.selectIds.indexOf(id);
$scope.selectIds.splice(index, 1); // 参数1:移除的下标位置,参数2:需要移除的元素个数
}
}前端分层开发
运用 MVC 的思想,将 js 和 html 代码分离,提高程序的可维护性。
实现方式:自定义服务,同后端的 service 层,封装一些操作,比如请求后端数据。在不同控制器通过依赖注入相关服务,即可调用服务的方法。将代码分为前端页面、前端服务层、前端控制层。
主键回填
修改 Mapper.xml 文件
<selectKey resultType="java.lang.Long" order="AFTER" keyProperty="id">
SELECT LAST_INSERT_ID() AS id
</selectKey> 对于规格与具体规格选项,可以创建一个组合实体类,包括 规格 和 规格选项的集合。在插入规格之后,通过主键回填,获取规格 ID ,然后将 ID 作为外键添加到规格选项中去。

select2 组件-多选下拉列表
-
引入 select 2 相关的 js 和 css。
-
设置数据源
$scope.brandList={data:[{id:1,text:'联想'},{id:2,text:'华为'},{id:3,text:'小米'}]}; // 品牌列表
-
实现多选下拉框
<input select2 select2-model="entity.brandIds" config="brandList" multiple placeholder=" 选择品牌(可多选)" class="form-control" type="text"/>
multiple 表示可多选 Config 用于配置数据来源 select2-model 用于指定用户选择后提交的变量
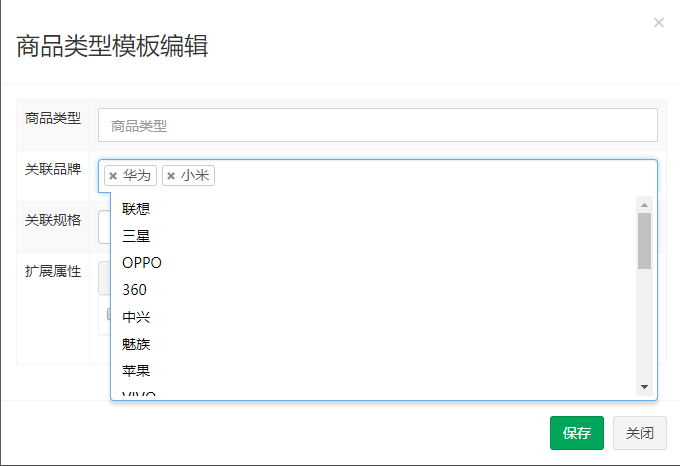
模板列表显示
将从后台获取的 json 字符串中的某个属性的值提取出来,用逗号分隔,更直观的显示。
// 提取 json 字符串数据中某个属性,返回拼接字符串逗号分隔
$scope.jsonToString = function(jsonString,key){
var json=JSON.parse(jsonString); // 将 json 字符串转换为 json 对象
var value="";
for(var i=0;i<json.length;i++){
if(i>0) value += ",";
value += json[i][key];
}
return value;
}
为基于 Spring 的企业应用系统提供声明式的安全访问控制的解决方案。提供一组可以在 Spring 应用上下文中配置的 Bean。
使用步骤
- 引入 jar 包
<dependency>
<groupId>org.springframework.security</groupId>
<artifactId>spring-security-web</artifactId>
<version>4.1.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.security</groupId>
<artifactId>spring-security-config</artifactId>
<version>4.1.0.RELEASE</version>
</dependency>- web.xml 文件中引入 spring-security.xml 配置文件
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring/spring-security.xml</param-value>
</context-param>
<listener>
<listener-class>
org.springframework.web.context.ContextLoaderListener
</listener-class>
</listener>
<filter>
<filter-name>springSecurityFilterChain</filter-name>
<filter-class>org.springframework.web.filter.DelegatingFilterProxy</filter-class>
</filter>
<filter-mapping>
<filter-name>springSecurityFilterChain</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>- spring-security.xml 配置文件设置页面拦截规则、认证管理器以及不拦截的资源(静态资源、登陆页面)
<!-- 设置页面不登陆也可以访问 -->
<http pattern="/*.html" security="none"></http>
<http pattern="/css/**" security="none"></http>
<http pattern="/img/**" security="none"></http>
<http pattern="/js/**" security="none"></http>
<http pattern="/plugins/**" security="none"></http>
<!-- 页面的拦截规则 use-expressions:是否启动SPEL表达式 默认是true -->
<http use-expressions="false">
<!-- 当前用户必须有ROLE_USER的角色 才可以访问根目录及所属子目录的资源 -->
<intercept-url pattern="/**" access="ROLE_ADMIN"/>
<!-- 开启表单登陆功能 -->
<form-login login-page="/login.html" default-target-url="/admin/index.html" authentication-failure-url="/login.html" always-use-default-target="true"/>
<csrf disabled="true"/>
<headers>
<frame-options policy="SAMEORIGIN"/>
</headers>
<logout/> <!-- 退出登录 -->
</http>
<!-- 认证管理器 -->
<authentication-manager>
<authentication-provider>
<user-service>
<user name="admin" password="123456" authorities="ROLE_ADMIN"/>
<user name="yang" password="123456" authorities="ROLE_ADMIN"/>
</user-service>
</authentication-provider>
</authentication-manager> CSRF(Cross-site request forgery)跨站请求伪造,也被称为“One Click Attack”或者Session Riding,通常缩写为CSRF或者XSRF,是一种对网站的恶意利用。
XSS(跨站脚本攻击)利用站点内的信任用户,往Web页面里插入恶意Script代码 。
CSRF通过伪装来自受信任用户的请求来利用受信任的网站。
安全控制
- 自定义认证类,创建类 UserDetailsServiceImpl.java 实现 UserDetailsService 接口
- 实现类中添加 SellerService 属性、和 setter 注入方法,修改 loadUserByUserName 方法。
- 配置 spring-security.xml。认证管理器中 authentication-provider 引用userDetailService 的bean,同时通过 dobbo 去依赖一个 sellerService 对象。
BCrypt 加密算法
用户表的密码通常使用 MD5 等不可逆算法加密后存储,为防止彩虹表破解更会先使用 一个特定的字符串(如域名)加密,然后再使用一个随机的 salt(盐值)加密。 特定字符串是程序代码中固定的,salt 是每个密码单独随机,一般给用户表加一个字段单独存储,比较麻烦。 BCrypt 算法将 salt 随机并混入最终加密后的密码,验证时也无需单独提供之前的 salt,从而无需单独处理 salt 问题。
/**
* 认证类
* @author YCQ
*
*/
public class UserDetailsServiceImpl implements UserDetailsService{
private SellerService sellerService;
public void setSellerService(SellerService sellerService) { // 通过配置的方式添加
this.sellerService = sellerService;
}
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
// System.out.println("执行 UserDetailsServiceImpl 认证");
// 构建角色列表
List<GrantedAuthority> grantAuths = new ArrayList<>();
grantAuths.add(new SimpleGrantedAuthority("ROLE_SELLER"));
TbSeller seller = sellerService.findOne(username);
if (seller!=null && "1".equals(seller.getStatus())) {
return new User(username, seller.getPassword(), grantAuths);
}else {
return null;
}
}
}spring-security 配置
<!-- 认证管理器 -->
<authentication-manager>
<authentication-provider user-service-ref="userDetailService">
<password-encoder ref="bcryptEncoder"></password-encoder>
</authentication-provider>
</authentication-manager>
<!-- 认证类 -->
<beans:bean id="userDetailService" class="com.pinyougou.service.UserDetailsServiceImpl">
<beans:property name="sellerService" ref="mSellerService"></beans:property>
</beans:bean>
<!-- 引用dubbo 服务 -->
<dubbo:application name="pinyougou-shop-web" />
<dubbo:registry address="zookeeper://107.191.52.91:2181"/>
<dubbo:reference id="mSellerService" interface="com.pinyougou.sellergoods.service.SellerService"></dubbo:reference>
<beans:bean id="bcryptEncoder" class="org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder"></beans:bean>注:浏览器控制台提示 [DOM] Input elements should have autocomplete attributes (suggested: "current-password") 为浏览器表单默认的记忆功能,可以在 input 标签中添加 autocomplete="off|on" 即可。
多级分类列表
将商品分类分为三级,进入页面首先显示所有一级分类(主分类),点击查询下级,可查看当前主分类下的次分类,再次点击进入三级分类。三级分类为最后一级,列表中不显示查询下级按钮,同时更新面包屑导航。直接点击面包屑导航,可以实现直接层级跳转。
面包屑导航
// 当前面包屑等级
$scope.grade = 1;
$scope.setGrade=function(value){
$scope.grade = value;
}
$scope.selectList=function(p_entity){
if ($scope.grade == 1) {
$scope.entity_1 = null;
$scope.entity_2 = null;
} else if ($scope.grade == 2){
$scope.entity_1 = p_entity;
$scope.entity_2 = null;
} else {
$scope.entity_2 = p_entity;
}
$scope.findByParentId(p_entity.id);
}
页面配置
<li><a href="#" ng-click="grade=1;selectList({id:0})">顶级分类列表</a></li>
<li><a href="#" ng-click="grade=2;selectList(entity_1)">{{entity_1.name}}</a></li>
<li ng-if="entity_2!=null"><a href="#" ng-click="grade=3;selectList(entity_2)">{{entity_2.name}}</a></li>修改商品分类
实现类型模板的下拉框,采用 select2 组件实现。
<td>类型模板</td>
<td><input select2 ng-model="entity.typeId" config="itemList" placeholder="商品类型模板" class="form-control" type="text"/>
</td> config 为数据来源
ng-model 绑定类型对象数据
itemList 的来源:itemCatController 中 findItemList() 方法 -> typeTemplateService 的 selectOptionList() 方法 -> 请求后端 /typeTemplate/selectOptionList -> TypeTemplateService 服务层 -> TypeTemplateMapper 层方法
删除商品分类
判断所选分类下是否存在子分类,存在则不能删除。
/**
* 批量删除
* @param ids
* @return
*/
@RequestMapping("/delete")
public Result delete(Long[] ids){
try {
// 判断当前所有分类是否存在子分类
boolean flag = false; // 不存在
for (Long id : ids) {
if(itemCatService.findByParentId(id)!=null && itemCatService.findByParentId(id).size()!=0){
flag = true;break;
}
}
if (flag) return new Result(false, "当前所选分类存在子分类,切勿删除");
itemCatService.delete(ids);
return new Result(true, "删除成功");
} catch (Exception e) {
e.printStackTrace();
return new Result(false, "删除失败");
}
}SPU 与 SKU
SPU (标准产品单位)为商品信息聚合的最小单位是一组可复用、易检索的标准化信息的集合,该集合描述了一个产品的特性。属性相同、特性相同的商品为一个SPU。
SKU (库存量单位) 为物理上不可分割的最小存货单元。不同的规格、颜色、款式为不同的SKU。
分布式文件服务器 FastDFS
FastDFS 是用 c 语言编写的一款开源的分布式文件系统。FastDFS 为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS 很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务。 FastDFS 架构包括 Tracker server 和 Storage server。
-
Tracker server (追踪服务器、调度服务器)作用为负载均衡和调度。
-
Storage server (存储服务器)作用为文件存储。
客户端请求 Tracker server 进行文件上传、下载,通过 Tracker server 调度最终由 Storage server 完成文件上传和下载。
服务端角色:
-
Tracker : 管理集群,tracker也可以实现集群,每一个节点地位平等,一种备份的机制。tracker负责收集 storage 集群的存储状态。
-
Stroage :实际保存文件。分为多个组,组内文件相同,起到备份作用。组间文件不同,起到分布式存储。

商品分类级联刷新
通过 Angular JS 变量监控方法,实现选择一级分类之后,初始化二级分类的列表信息。
// angularjs变量监控方法,查询二级分类信息
$scope.$watch('entity.goods.category1Id',function(newValue, oldValue){
if (newValue != undefined && newValue != "") {
// alert("category1Id"+newValue);
itemCatService.findByParentId(newValue).success(
function(response){
$scope.itemCat2List = response;
$scope.entity.goods.category2Id = "";
}
);
}
});
商品录入【SKU商品信息】
对于同一个产品分为多种不同的规格组合。根据选择的规格录入商品的 SKU 信息,当用户选择相应的规格,下面的 SKU 列表就会自动生成。

实现思路: (1)我们先定义一个初始的不带规格名称的集合,只有一条记录。 (2)循环用选择的规格,根据规格名称和已选择的规格选项对原集合进行扩充,添加规格名称和值,新增的记录数与选择的规格选项个数相同
// 创建SKU列表
$scope.creatItemList=function(){
// 列表初始化,规格对象、价格、库存量、状态、是否默认
$scope.entity.itemList = [ {spec:{},price:0,num:9999,status:'0',isDefault:'0'} ];
var items = $scope.entity.goodsDesc.specificationItems;
for (var i = 0; i < items.length; i++) {
$scope.entity.itemList = addColumn($scope.entity.itemList, items[i].attributeName, items[i].attributeValue);
}
}
/**
* $scope.entity.itemList:
* [{"spec":{"网络":"移动3G","机身内存":"16G"},"price":0,"num":9999,"status":"0","isDefault":"0"},
* {"spec":{"网络":"移动3G","机身内存":"32G"},"price":0,"num":9999,"status":"0","isDefault":"0"},
* {"spec":{"网络":"联通3G","机身内存":"16G"},"price":0,"num":9999,"status":"0","isDefault":"0"},
* {"spec":{"网络":"联通3G","机身内存":"32G"},"price":0,"num":9999,"status":"0","isDefault":"0"}]
*/
// 深克隆方法 原集合、列名、列值
addColumn=function(list, columnName, columnValues){
var newList = [];
for (var i = 0; i < list.length; i++) {
var oldRow = list[i];
for (var j = 0; j < columnValues.length; j++) {
var newRow = JSON.parse( JSON.stringify(oldRow) );
newRow.spec[columnName] = columnValues[j];
newList.push(newRow);
}
}
return newList;
}商家后台列表显示

状态显示:
商品信息表(goods)中状态子段为 audit_status 。存储的为数字,0表示未审核、1表示已审核、2表示审核未通过、3为已关闭。从后台获取的状态值,直接在前端进行修改。通过一个status数组存储:
$scope.status=['未审核','已审核','审核未通过','关闭'];//商品状态
然后列表中显示为 {{status[entity.auditStatus]}}。
分类信息显示:
商品分为三级分类。存储于 tb_item_cat 表中。包括 id、父级id、分类名称、对应绑定的类型id。但是为了避免商品查询时重复的关联查询,可以采用现将所有分类信息读取到本地,然后在前端进行分类id到分类名称的转换操作。
$scope.itemCatList = [];
// 全部商品分类查询,存储在itemList数组中,然后再前端页面通过数组下标直接将商品分类ID转换为商品分类名称,避免后端连接查询。
$scope.findItemList = function(){
itemCatService.findAll().success(
function(response){
for (var i = 0; i < response.length; i++) {
$scope.itemCatList[response[i].id] = response[i].name;
}
}
);
} 将分类结果 response 对象封装为数组类型,数组下标为商品分类id,数组值为商品分类的名称。然后在列表项中通过 {{itemCatList[entity.category1Id]}} 将id转换为名称。
存在的问题
pinyougou-shop-web 模块中分页插件提示 ClassNotFoundException。但是页面可以访问。

<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>${pagehelper.version}</version>
</dependency> 如上配置之后,又出现下图错误,导致商品列表无法显示。(但是 manager-web 模块中也没有引入pagehelper,但是没有出现问题)

商品删除
逻辑删除,通过修改数据库表中的 is_delete 字段为1,然后过滤掉商品。然后查询时,在 findPage() 方法中添加 criteria.andIsDeleteIsNull() 条件。
注解式事务配置
创建 applicationContext-tx.xml 配置文件
<!-- 事务管理器 -->
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- 开启事务控制的注解支持 -->
<tx:annotation-driven transaction-manager="transactionManager"/> 然后在方法或服务实现类上添加 @Transactional 注解。
网站前台广告服务
设计为广告分类表(id、name)与广告内容表(id、categoryId、title、url、pic、status、order)。广告有首页轮播广告、今日推荐、各品类楼层广告等分类。
Redis 缓存数据库用于解决高访问量对后端数据库造成的很大的访问压力。(另一种解决方案为网页静态化)
Spring Data Redis 提供了在 srping 应用中通过简单的配置访问 redis 服务,对 reids 底层开发包(Jedis, JRedis, and RJC)进行了高度封装,RedisTemplate 提供了 redis 各种操作、异常处理及序列化,支持发布订阅,并对 spring 3.1 cache 进行了实现。
spring-data-redis 针对 jedis 提供了如下功能: 1.连接池自动管理,提供了一个高度封装的“RedisTemplate”类。 2.针对 jedis 客户端中大量 api 进行了归类封装,将同一类型操作封装为 operation 接口
操作样例:
key-value 键值对操作
插入:redisTemplate.boundValueOps("name").set("mindyu");
读取:redisTemplate.boundValueOps("name").get();
删除:redisTemplate.delete("name");
Set 类型操作(无序集合)
插入:redisTemplate.boundSetOps("nameset").add("曹操");
读取:redisTemplate.boundSetOps("nameset").members();
删除:redisTemplate.boundSetOps("nameset").remove("曹操"); // 单一元素
redisTemplate.delete("name"); // 整个集合
List 集合 (有序)
rightPush() 、leftPush()、读取:range(0,10)、index(1)、remove(1, "value") // 1 表示删除数据的个数
Hash 类型
put("key","value")、读取所有键:keys()、读取所有值:values()、get(“key”)、delete("key")
使用 Redis 缓存时,需要注意,当数据修改时需要清除缓存数据,使其达到一致性约束。必须修改广告时,如果修改了该广告所属的分类,那么需要同时清除原分类以及新分类的缓存信息。
出现的问题:
首页在加载广告模块时,出现 “Failed to load resource: net::ERR_BLOCKED_BY_CLIENT” 错误,是因为谷歌浏览器的广告插件,导致无法加载该图片。
简介
Solr 是一个开源搜索平台,用于构建搜索应用程序。 它建立在 Lucene(全文搜索引擎)之上。 Solr 是企业级的,快速的和高度可扩展的。 使用 Solr 构建的应用程序非常复杂,可提供高性能。Solr 是一个可扩展的,可部署,搜索/存储引擎,优化搜索大量以文本为中心的数据。
安装及配置
- 安装 Tomcat,解压缩。
- 解压 solr。
- 把 solr 下的 dist 目录 solr-4.10.3.war 部署到 webapps 下(去掉版本号,方便访问)。
- 启动 Tomcat 解压缩 war 包
- 把solr下 example/lib/ext 目录下的所有的扩展 jar 包,添加到 solr 的工程中(\WEB-INF\lib目录下)。
- 创建一个 solrhome 。solr 下的 /example/solr 目录就是一个 solrhome。复制此目录到 D 盘改名为 solrhome
- 关联 solr 及 solrhome。需要修改 solr 工程的 web.xml 文件。
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>d:\solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>- 启动 Tomcat 。访问 http://localhost:8080/solr 即可

中文分析器 IK Analyzer
IK Analyzer 是一个开源的,基于 java 语言开发的轻量级的中文分词工具包。
配置
-
把 IKAnalyzer2012FF_u1.jar 添加到 solr 工程的 lib 目录下
-
solr 工程下创建 WEB-INF/classes 文件夹,用于存放扩展词典、停用词词典、配置文件。
-
修改 Solrhome 中的 schema.xml 文件,配置一个 FieldType,使用 IKAnalyzer
<fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
配置域
域相当于数据库的表字段,用户存放数据,用户可根据业务需要去定义相关的 Field(域),一般来说,每一种域对应着一种数据,用户对同一种数据进行相同的操作。域的常用属性:
- name 域的名称
- type 域的类型
- indexed 是否索引
- stored 是否存储
- required 是否必须
- multiValued 是否多值
复制域:
将某一个域中的数据复制到另一个域中。比如商品查询时,同样一个关键字可能是品牌、商品标题、商品分类、商家名称等多种可能。此时就需要复制域。
动态域:
对于字段名称不固定的情况下,用于动态扩充字段。比如商品的规格的值不是固定的(不同商品可能存在不同的规格项)。
出现的错误
- 前端可以从后台获取数据( itemsearch/search.do正常获取数据 ),但是控制台显示" TypeError: Cannot read property 'success' of undefined "错误。

原因是因为:
app.service('searchService', function($http){
this.search=function(searchMap){
return $http.post('itemsearch/search.do',searchMap);
}
});angularjs 服务层的search方法并未 return。
2. 服务启动超时:com.alibaba.dubbo.remoting.TimeoutException: Waiting server-side response timeout. start time: 2018-12-02 08:35:41.093, end time: 2018-12-02 08:35:46.094, client elapsed: 0 ms, server elapsed: 5001 ms, timeout: 5000 ms。
- 网站前台 portal-web 模块出现的原因是因为没有启动 redis 服务器。然后前台广告数据获取不到。
- 搜索模块 search-web :就很奇怪,dubbox 服务正常、solr 服务正常。昨天晚上还是正常的,上午纠结了半天,然后不知道为啥突然又好了。。。 烦躁
批量数据导入 solr 系统
将商品数据导入到 solr 系统。
- 创建 solr-util (jar),引入 dao 模块以及 spring 相关依赖。
- 创建spring 的配置文件,添加包扫描。
<context:component-scan base-package="com.pinyougou.solrutil"> </context:component-scan>
-
依赖 pojo 模块,为实体类添加 @Field 注解。
-
pojo 中引入 spring-data-solr 依赖(会自动引入其所依赖solr包)动态域中@Dynamic 注解是该包提供的
-
添加 solr.xml 配置文件与 spring 目录中。
<!-- solr 服务器地址 --> <solr:solr-server id="solrServer" url="http://127.0.0.1:8080/solr" /> <!-- solr 模板,使用 solr 模板可对索引库进行 CRUD 的操作 --> <bean id="solrTemplate" class="org.springframework.data.solr.core.SolrTemplate"> <constructor-arg ref="solrServer" /> <bean>
-
通过 spring 注入 SolrTemplate 模板类对象。
-
使用 SolrTemplate 对象执行相应的方法。
关键字搜索模块
通过注入 SolrTemplate 对象,使用该对象实现关键字搜索。
@Service(timeout=5000) // 超时5S,默认是1S
public class ItemSearchServiceImpl implements ItemSearchService{
@Autowired
private SolrTemplate solrTemplate;
@Override
public Map search(Map searchMap) {
Map map = new HashMap();
Query query = new SimpleQuery("*:*");
Criteria criteria = new Criteria("item_keywords").is(searchMap.get("keywords"));
query.addCriteria(criteria);
ScoredPage<TbItem> page = solrTemplate.queryForPage(query, TbItem.class);
map.put("rows", page.getContent()); // page.getContent() 返回一个 List 集合
return map;
}
}搜索结果高亮显示
将搜索关键字在搜索结果中,高亮显示出来。实现原理也就是在关键字前后添加html标签:关键字
后端实现代码:
@Override
public Map search(Map searchMap) {
Map map = new HashMap();
/*
Query query = new SimpleQuery("*:*");
Criteria criteria = new Criteria("item_keywords").is(searchMap.get("keywords"));
query.addCriteria(criteria);
ScoredPage<TbItem> page = solrTemplate.queryForPage(query, TbItem.class);
map.put("rows", page.getContent()); // page.getContent() 返回一个 List 集合
*/
// 高亮显示
HighlightQuery query = new SimpleHighlightQuery();
// 构建高亮选项
HighlightOptions highlightOptions = new HighlightOptions().addField("item_title"); // 高亮域(可以为多个)
highlightOptions.setSimplePrefix("<em style='color:red'>"); // 前缀
highlightOptions.setSimplePostfix("</em>"); // 后缀
query.setHighlightOptions(highlightOptions); // 为查询设置高亮查询
Criteria criteria = new Criteria("item_keywords").is(searchMap.get("keywords"));
query.addCriteria(criteria);
HighlightPage<TbItem> page = solrTemplate.queryForHighlightPage(query, TbItem.class);
// 高亮入口集合(每条高亮结果的入口)
List<HighlightEntry<TbItem>> entryList = page.getHighlighted();
for (HighlightEntry<TbItem> entry : entryList) {
// 获取高亮列表(高亮域的个数)
List<Highlight> hightLightList = entry.getHighlights();
/*
for (Highlight highLight : hightLightList) {
// 每个域可能存在多值(复制域)
List<String> sns = highLight.getSnipplets();
System.out.println(sns);
}*/
if (entry.getHighlights().size()>0 && entry.getHighlights().get(0).getSnipplets().size()>0) {
TbItem item = entry.getEntity();
item.setTitle(entry.getHighlights().get(0).getSnipplets().get(0)); // 用高亮标签结果替换
}
}
map.put("rows", page.getContent());
return map;
} 前端实现:
angularJS 会将后端插入的html标签原样输出,而不会去解析。这是防止html攻击采取的一种安全策略。可以使用 $sce 服务的 trustAsHtml 方法来实现转换。
// 定义过滤器
app.filter('trustHtml', ['$sce', function($sce){
return function(data){ // 传入参数时,被过滤的内容
return $sce.trustAsHtml(data); // 返回的是过滤后的内容(信任html的转换)
}
} ]);然后在页面通过 <div class="attr" ng-bind-html="item.title | trustHtml"></div>来调用转换方法。
搜索模块
- 用户输入搜索关键字,显示列表结果和商品分类信息。因为一个关键字可能对应多种商品分类
- 根据第一个商品分类,默认查询该分类的模板ID,然后根据模板ID查询品牌列表和规格列表
- 当用户点击某一个商品分类时,则显示该分类对应商品结果,同时根据该分类的模板ID查询对应的品牌列表和规格列表
- 当用户点击商品品牌列表时,筛选出当前所选的品牌商品信息
- 当用户点击商品规格列表时,筛选出当前所选的规格所对应的商品信息
- 用户点击价格区间时,商品信息根据价格进行过滤
- 用户点击搜索面板上的条件时,隐藏该条件
系统搜索量很大,所以需要将搜索信息放置到 Redis 缓存数据库中。
缓存商品分类信息
private void saveToRedis() {
// 将模板ID放入缓存 分类名称作为key,模板ID作为value
List<TbItemCat> itemCatList = findAll();
for (TbItemCat itemCat : itemCatList) {
redisTemplate.boundHashOps("itemCat").put(itemCat.getName(), itemCat.getTypeId());
}
System.out.println("将模板ID放入缓存");
}缓存所有的品牌信息和规格信息
private void saveToRedis() {
List<TbTypeTemplate> typeTempList = findAll();
for(TbTypeTemplate template : typeTempList) {
Long id = template.getId();
// 将模板ID作为key 品牌列表作为value
List brandList = JSON.parseArray(template.getBrandIds(), Map.class); // {id:1,text:联想}
redisTemplate.boundHashOps("brandList").put(id, brandList);
// 将模板ID作为key 规格列表作为value
List<Map> specList = findSpecList(id);
redisTemplate.boundHashOps("specList").put(id, specList);
}
System.out.println("完成品牌列表、规格列表缓存");
}分类列表查询(spring data solr 条件查询)
private List<String> searchCategoryList(Map searchMap) {
List<String> list = new ArrayList<>();
Query query = new SimpleQuery("*:*");
// 根据关键字查询
Criteria criteria = new Criteria("item_keywords").is(searchMap.get("keywords")); // where ...
query.addCriteria(criteria);
// 设置分组选项
GroupOptions groupOptions = new GroupOptions().addGroupByField("item_category"); // group by ....(可以有多个分组域)
query.setGroupOptions(groupOptions);
// 获取分组页
GroupPage<TbItem> queryForGroupPage = solrTemplate.queryForGroupPage(query, TbItem.class);
// 获取分组结果对象
GroupResult<TbItem> groupResult = queryForGroupPage.getGroupResult("item_category");
// 获取分组入口页
Page<GroupEntry<TbItem>> groupEntries = groupResult.getGroupEntries();
// 遍历获取每个对象的值
for(GroupEntry<TbItem> entry : groupEntries) {
list.add(entry.getGroupValue());
}
return list;
}过滤条件的构建
当点击搜索面板的分类、品牌和规格时,实现查询条件的构建。查询 条件以面包屑的形式显示。当面包屑显示分类、品牌和规格时,要同时隐藏搜索面板对应的区域。点击面包屑查询条件的撤销链接时,重新显示搜索面板相应的区域。
面包屑其实就是显示搜索对象。可将搜索对象定义为$scope.searchMap={'keywords':'','category':'','brand':'',spec:{}};。然后实现添加查询条件和取消查询条件。
// 搜索
$scope.search = function() {
searchService.search($scope.searchMap).success(function(response) {
$scope.resultMap = response; // 搜索返回的结果
});
}
// 添加查询搜索项
$scope.addSearchItem=function(key,value){
if (key == 'brand' || key == 'category') { // 如果点击品牌和分类
$scope.searchMap[key] = value;
}else{
$scope.searchMap.spec[key]=value;
}
$scope.search();
}
// 取消查询条件
$scope.removeSearchItem=function(key){
if (key == 'brand' || key == 'category') { // 如果点击品牌和分类
$scope.searchMap[key] = "";
}else{
delete $scope.searchMap.spec[key];
}
$scope.search();
}价格区间筛选
点击搜索面板的价格区间,实现按价格筛选相应的商品。和上述的过滤条件类似,前端依然将价格区间以字符串的形式放入到 searchMap 集合中(如 'price':'500-1000')。然后后端通过字符串的截取获得相应的价格区间,然后进而筛选。
自定义搜索结果分页
前端将当前页数和页大小通过 searchMap 传给后端,然后后端通过构建 solr 的 query 对象实现分页效果。然后返回当前页数据和总页数以及总记录数。$scope.searchMap={'keywords':'','category':'','brand':'','spec':{},'price':'','pageNo':1,'pageSize':40 };//搜索条件封装对象
通过当前页数、总页数然后构建分页标签。
// 构建分页标签
buildPageLable=function(){
$scope.pageLable=[];
var firstPage = 1; // 开始页码
var lastPage = $scope.resultMap.totalPages; // 截止页码
$scope.firstDot = true;
$scope.lastDot = true;
if (lastPage > 5){
if ($scope.searchMap.pageNo<=3){ // 当前页码小于3,显示前五页
lastPage = 5;
$scope.firstDot = false;
}else if ($scope.searchMap.pageNo>=lastPage-2) { // 当前页码大于总页数-2,则显示后5页
firstPage = lastPage - 4;
$scope.lastDot = false;
}else {
firstPage = $scope.searchMap.pageNo - 2;
lastPage = $scope.searchMap.pageNo + 2;
}
}else{
$scope.firstDot = false;
$scope.lastDot = false;
}
for (var i = firstPage; i <= lastPage; i++) {
$scope.pageLable.push(i);
}
}多关键字搜索
在搜索时,分词器首先会将我们输入的关键字进行分词,然后对每个分词都会去搜索对应的结果,然后求得并集。比如搜索“三星手机”时,会将“三星”的搜索集合和“手机”搜索结构都返回给我们。这样做可以显示更多数据,让用户有更多的选择。同时会根据搜索的关键字匹配度进行排序。
此时注意:当搜索关键字有空格时,中文分词无法进行分词,那么就会导致搜索出来的结果较少或者没有。然后可以采用在后端去掉关键字中所有的空格。原来如此,我平时搜索的时候经常喜欢敲空格,以为这样多个条件就能更精准的搜索我想要的额,套路套路。
搜索数据排序
根据综合、价格升降序、新品的来实现排序。前端传递两个参数,分别为待排序的字段名称和排序方式(升序or降序)。
// 1.7 排序
String sortValue = (String) searchMap.get("sort"); // 升序 or 降序
String sortFiled = (String) searchMap.get("sortFiled"); // 升序字段
if (!"".equals(sortValue) && !"".equals(sortFiled)) {
if (sortValue.equals("ASC")) { // 升序
Sort sort = new Sort(Sort.Direction.ASC, "item_"+sortFiled);
query.addSort(sort);
}else if(sortValue.equals("DESC")) {
Sort sort = new Sort(Sort.Direction.DESC, "item_"+sortFiled);
query.addSort(sort);
}
} 销量和评价的排序(待完成):
增加域 item_salecount 用于存储每一个 SKU 的销量信息,然后定时更新每一个 SKU 的销量数据(固定时间,比如一个月,否则会导致新上架的商品无法排在前列),同时每天定时更新一次销量数据。
隐藏品牌列表
当用户搜索的关键字包含品牌时隐藏品牌列表。也就是判断搜索关键字中是否存在返回的品牌列表中的信息。这个过程中发现,搜索关键字 searchMap.keywords 和输入框进行了绑定。那么当我们修改输入框的时候,可能就会影响品牌列表的显示。 此处将 search 重载,添加一个带 keywords的方法。然后搜索框就不和搜索关键字进行绑定,而是以传递参数的形式赋值给 searchMap。
首页和搜索页对接
在首页输入框中输入关键字,然后跳转到搜索页面,查询对应关键字的数据。
首页通过 链接的形式传递参数location.href="http://localhost:9104/search.html#?keywords="+$scope.keywords; 然后搜索模块使用 $location 服务接受参数。
// 引入 $location 服务
// 接受首页跳转
$scope.loadKeywords=function(){
$scope.searchMap.keywords = $location.search()['keywords'];
$scope.search();
}索引库的增量更新
实现在商品审核之后将数据更新到 solr 索引库,在商品删除的时候删除 solr 索引库中相应的记录。(增量更新)
商品审核是对商品表(SPU信息)进行操作,但是索引库中存储的是SKU信息,所以首先需要通过商品的 SPU 信息查询该商品对应的 SKU 信息,然后将查询到的集合提交给 solrTemplate。删除可以直接根据 goodsId 集合进行条件删除。