- plagiarism detector following this paper that examines a text file and performs binary classification; labeling that file as either plagiarized or not, depending on how similar the text file is to a provided source text.
- Plagiarism is defined as “the appropriation of another person's ideas, processes, results, or words without giving appropriate credit”, so our goal here to try to find a solution for this by using some comparing between original and target text after making some preprocessing techniques for text before fitting it into Machine learning model to classify this model is plagiarized or not, according to the paper mentioned above will try to make some text processing after calculating containment and longest common subsequence using dynamic programming algorithm.

Created features.
- before we prepare our final dataset I'm made multiple features using multiple N-gram with containment and longest common subsequence, then try to calculate a correlation matrix to ignore very high correlated columns

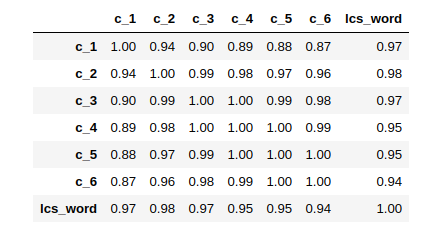
Correlation Matrix.
- This data is a slightly modified version of a dataset created by Paul Clough (Information Studies) and Mark Stevenson (Computer Science), at the University of Sheffield. You can read all about the data collection and corpus, at their university webpage
Citation for data: Clough, P. and Stevenson, M. Developing A Corpus of Plagiarised Short Answers, Language Resources and Evaluation: Special Issue on Plagiarism and Authorship Analysis,
-
Data Exploration
-
Defining Features
-
Train and Deploy Model into AWS SageMaker