loss spike after checkpoint reload #480
Comments
|
|
|
Thanks for the code @williamFalcon! Do you see this loss spike only using |
|
lightning’s ddp is pytorch ddp. except it routed the forward call to train_step or val_step. but otherwise the same |
|
You can replicate this by doing the following: Run the above script using a slurm script on a node with 2 gpus (i used 2 v100s with 32gb each). set the walltime to 10 mins (so the loss can go down). At 7 mins it'll resubmit itself and you'll see the problem. Although MNIST might be too trivial. I'd try cifar-10 perhaps? |
|
Here's a full working example to replicate. Make sure to install lightning from master: import torch
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR100
import torchvision.transforms as transforms
from test_tube import Experiment, SlurmCluster, HyperOptArgumentParser
import numpy as np
import pytorch_lightning as pl
PORT = np.random.randint(12000, 20000, 1)[0]
SEED = 2334
torch.manual_seed(SEED)
np.random.seed(SEED)
"""
To run in interactive node:
python issue.py
To run as a cluster job (submits job to cluster):
python issue.py --cluster
"""
class CIFAR100LM(pl.LightningModule):
def __init__(self, save_path):
super(CIFAR100LM, self).__init__()
self.save_path = save_path
self.l1 = torch.nn.Linear(32 * 32*3, 1028)
self.l2 = torch.nn.Linear(1028, 2048)
self.l3 = torch.nn.Linear(2048, 100)
def forward(self, x):
x = x.view(x.size(0), -1)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = self.l3(x)
return x
def training_step(self, batch, batch_nb):
x, y = batch
y_hat = self.forward(x)
return {'loss': F.cross_entropy(y_hat, y)}
def validation_step(self, batch, batch_nb):
x, y = batch
y_hat = self.forward(x)
return {'val_loss': F.cross_entropy(y_hat, y)}
def validation_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
return {'avg_val_loss': avg_loss}
def configure_optimizers(self):
# can return multiple optimizers and learning_rate schedulers
return torch.optim.Adam(self.parameters(), lr=0.0002)
@pl.data_loader
def tng_dataloader(self):
return DataLoader(CIFAR100(self.save_path, train=True, download=True,
transform=transforms.ToTensor()), batch_size=32)
@pl.data_loader
def val_dataloader(self):
return DataLoader(CIFAR100(self.save_path, train=True, download=True,
transform=transforms.ToTensor()), batch_size=32)
def main(*args, **kwargs):
log_path = '/log/path'
exp = Experiment(
name='apex_bug_test',
save_dir=log_path,
autosave=False,
description='amp test'
)
exp.save()
data_path = '/data/CIFAR100'
model = CIFAR100LM(data_path)
trainer = pl.Trainer(
gpus=[0, 1],
use_amp=True,
experiment=exp,
min_nb_epochs=200,
distributed_backend='ddp'
)
trainer.fit(model)
def launch_cluster_job(args):
# enable cluster training
slurm_log_path = '/log/path'
cluster = SlurmCluster(
log_path=slurm_log_path,
hyperparam_optimizer=args
)
# email for cluster coms
cluster.notify_job_status(email='your@email.com', on_done=True, on_fail=True)
# configure cluster
cluster.per_experiment_nb_nodes = 1
cluster.per_experiment_nb_gpus = 2
cluster.job_time = '00:10:00'
cluster.memory_mb_per_node = 0
cluster.per_experiment_nb_cpus = 2
# any modules for code to run in env
cluster.add_command('source activate your_conda_env')
cluster.add_command('export NCCL_SOCKET_IFNAME=^docker0,lo')
cluster.add_command('export NCCL_DEBUG=INFO')
cluster.add_command('export PYTHONFAULTHANDLER=1')
cluster.add_command(f'export MASTER_PORT={PORT}')
cluster.load_modules(['NCCL/2.4.7-1-cuda.10.0'])
cluster.python_cmd = 'python'
cluster.add_slurm_cmd(cmd='constraint', value='volta32gb', comment='use 32gb gpus')
cluster.add_slurm_cmd(cmd='ntasks-per-node', value=2, comment='1 task per gpu')
# name of exp
job_display_name = 'apex_bug_test'
# run hopt
print('submitting jobs...')
cluster.optimize_parallel_cluster_gpu(
main,
nb_trials=1,
job_name=job_display_name
)
if __name__ == '__main__':
parser = HyperOptArgumentParser()
parser.add_argument('--cluster', dest='cluster', action='store_true')
args = parser.parse_args()
if args.cluster:
launch_cluster_job(args)
else:
main() |
|
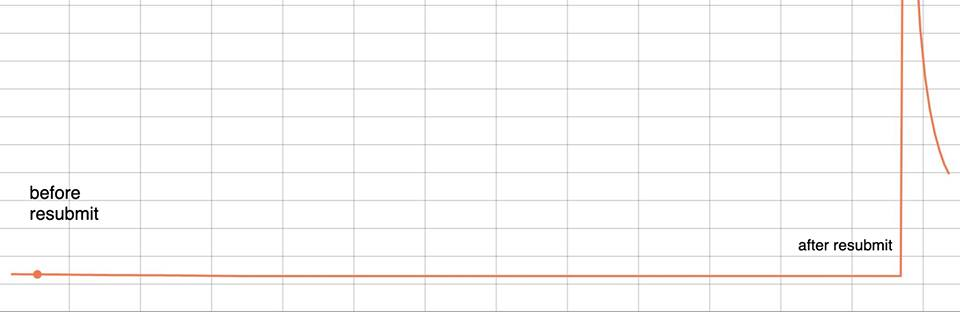
This is from the above example. orange before checkpointing blue after resuming training |
|
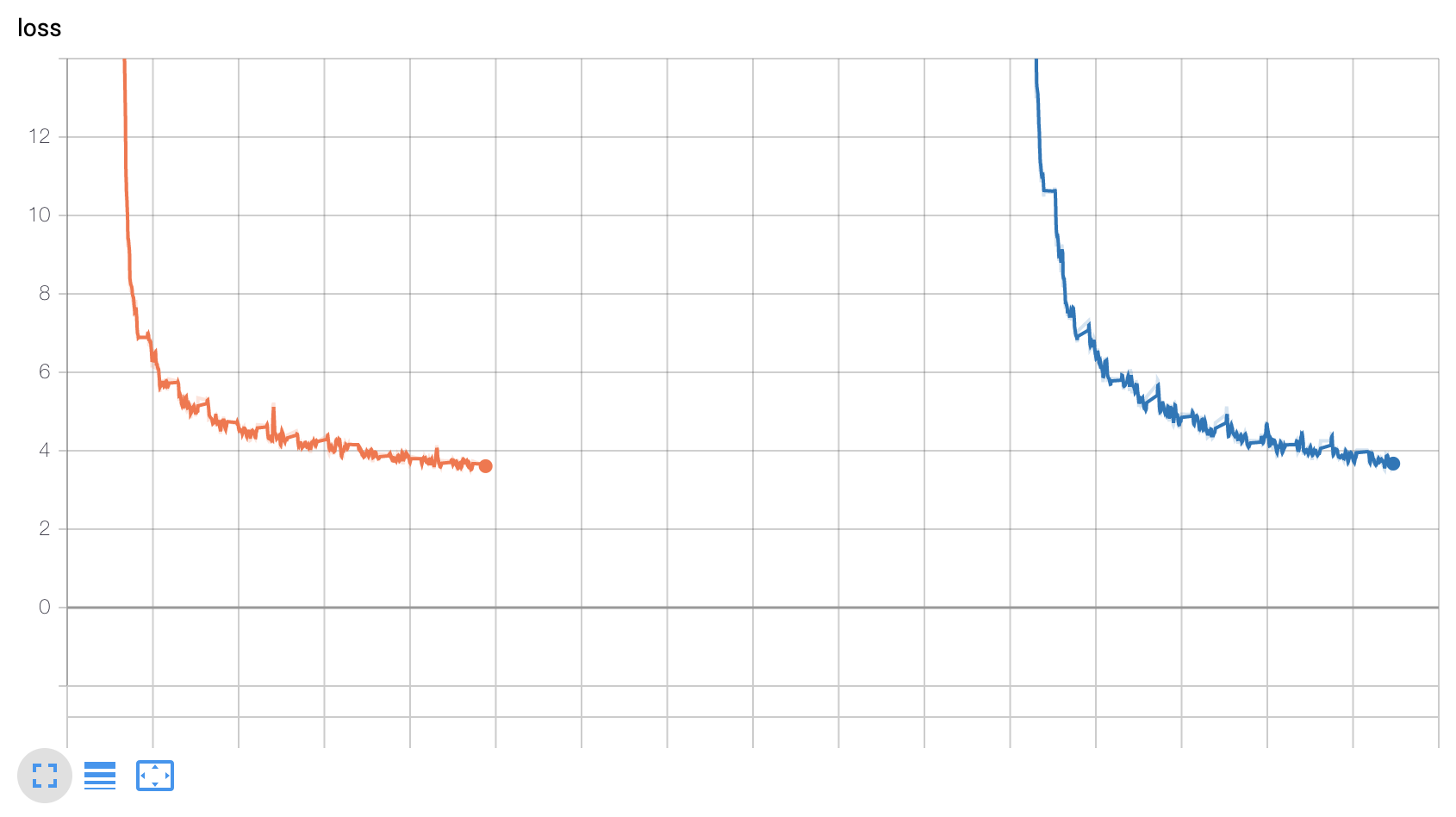
ok, digging into this more... Here is the loss after 3 reloads (each color a different reload). However, when tracking the training accuracy i see that it remains high even after reload even when the loss spikes.
This suggests that the model loads correctly, but the scaling is off (which has to do with amp.load_state_dict()). In this simple model it's not a problem, but on more complex ones with losses sensitive to scaling, it nans out the losses after the model restarts. |


|
@williamFalcon, @ptrblck did you guys figure this out? we are having the same problem. |
|
Turns out the problem is related to reloading the |
|
@ibeltagy Could you please explain how you're warming up the optimizer? All that is coming to mind for me is calling I'm dealing with a model that explodes after the first step upon reload, so aside from reloading and training with optim level O0, I'm not sure what to do. |
|
I mean slowly increasing learning rate from zero to the value you want. |
|
We also encountered the same issue for PyTorch's DDP. @ptrblck The loss becomes quite large when we reload the checkpoint. |
|
Same issues here. Loss spikes after loading checkpoint . Not loading the optimizer helps sometimes but not always. Nvidia needs to fix this asap. I don't see quick responses from them in GitHub. |
|
I found an ugly hack but it seems to work. It goes like this, |
|
So amp is expecting one optimizer step before loading the checkpoint smoothly? Has anyone looked into the source code to find the root cause ? |
|
no, |
|
Unfortunately, I cannot get the workaround to work. I may have to disable fp16 entirely - unless I find that the loss spike is harmless in terms of actual model improvement. I am grateful for fp16, but this does seem like a nearly show-stopping issue! It should be possible to restart from a checkpoint and continue where you left off - right? I'm a bit surprised this isn't a bigger issue - are folks not using fp16? |
|
i don’t remember how we solved this but we did in pytorch lightning. you could try running it there with fp16 enabled |
|
@williamFalcon, couldn't find the relevant code (not here https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pytorch_lightning/trainer/training_io.py#L374), and also didn't find |
|
@daniel347x FWIW, I've found the severity of the bug to be somewhat task dependent. For some tasks, the loss spike disappears quickly, and it's indiscernible whether or not it had a lasting effect on convergence. For others, it will legitimately ruin the model. My current best rule of thumb is that classification tasks are most affected, and particularly, as the number of possible classes increases, the worse the spike affects the model. |
|
Can this be because model params are actually FP16 when they are saved. After loading optimizer gets the FP16 params as FP32 which causes loss in precission? |
|
I have also encountered the same problem, and the loss diverged at O2 level. But I found @ibeltagy 's hack is useful. |
|
@ptrblck Any updates on this? |
|
we’re now using native amp with pt 1.6+ on pytorch lightning. I would just switch to that. |
|
Add optimizer.load_state_dict right before the first optimizer.step works for me too. (I basically add a manual checkpoint loading in optimizer_step of LightningModule) For general pytorch user, this is what I have: It seems the reason is when you load the first time, the saved states will be cast to fp16, while at this time the states are not properly initialized because of the lazy_init. After the first time to call amp.scale_loss, the states of optimizer are properly initialized and the states will be recast to fp32, and the precision difference here will cause the problem. However if amp_lazy_init earlier, the loss still spikes (but not that bad.) |
When running a model using apex+ddt my loss spikes dramatically after the model restarts.
If i disable apex, it works fine.
Currently, I've set up apex this way:
Actual code is here:
The text was updated successfully, but these errors were encountered: