SLEIGH: assembly template not following the usual mnemonic + operands #315
Comments
|
Neat, I would love to use that module when it is finished for baseband REing. |
|
I dug a little bit into Ghidra's source code and I am now certain that fixing the second issue requires major changes to the current architecture. Let me present my findings if anyone is interested:
So now I am left wondering if I should make any modifications at all. I definitively could us some advice from the main developers on wether or not it is a good idea to implement those changes, and if they would be willing to merge these hypothetical changes in the next release. Or to make them themselves. |
|
Nice work there! I think it would be nice to make the changes necessary or at least provide a patch for them. How you are used to a syntax makes a lot when it comes to how fast one can get a grip of what's going on when it comes to assembler; not in an all cases but in the common case I've encountered this all over with mediocre REers (you should know who you are). |
|
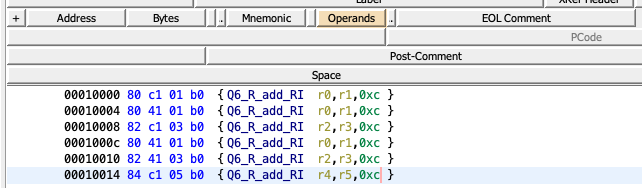
I've been giving it some more thought. Here's what I'm currently thinking: Can you say, for each of these instructions, which part is the mnemonic? I know I can't. Because Sleigh only supports templates in a simple shape ( For example, This would make the My current idea is to programmatically override the class representing a disassembled instruction so that it returns different mnemonic / operands values when used for the listing display. I don't know yet at which level this should be performed:
I'm also unsure how to do it from a processor module: using Java reflection maybe? Then we could either have the mnemonic field display an empty string and move everything into the operands field, or we could create a new special field This still leaves the issue of the @nsadeveloper789 @emteere @ryanmkurtz @ghidra1 @d-millar @saruman9 @dragonmacher @dev747368 and others, could you offer some pointers on how to proceed? Many thanks! |
|
Looking at the file that defines the properties of a processor specification, I've found: It looks like the first one can be useful to override the rendering of the instructions. Update: I've added a
Now I still need to override the instruction template, but I'm more confident that I was this morning. 😄 |
|
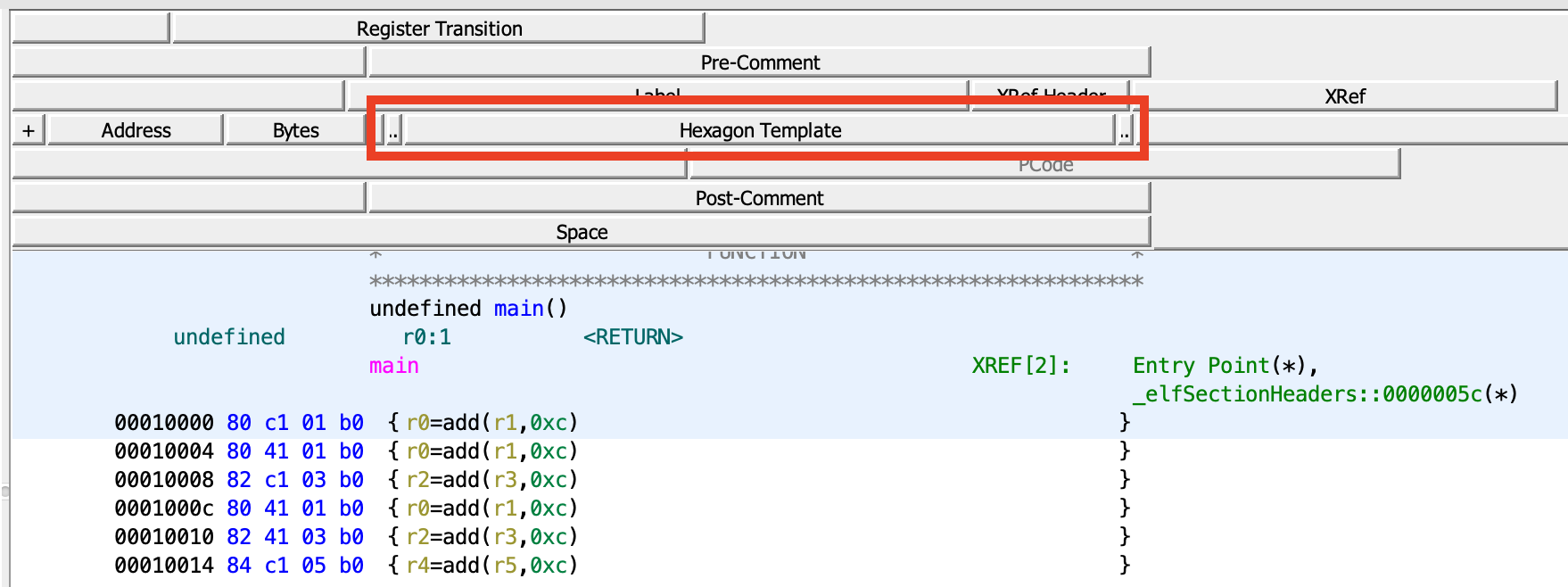
I have kinda been able to do what I wanted by defining 3 custom fields: Hexagon Prefix / Hexagon Suffix to display the
I'm not a big fan of my solution because the user is forced to add these 3 custom fields, and worse, the remove the existing Mnemonic / Operands fields. These fields are also used to display data, e.g. Mnemonic might be @nsadeveloper789 @emteere @ryanmkurtz @ghidra1 @d-millar @saruman9 @dragonmacher @dev747368 and others, if anyone is reading this issue, could you offer some feedback? |
|
I took a look at the instruction manual for this processor. The processor is quite a beast, and the format of the instructions are somewhat unique. |
|
Thank you for your answer @emteere, it is very much appreciated!
If you ever got time to work on this, please keep me updated. In the meantime, I might continue to work on this, but I should definitively open-source what I have already done (even though it is not pretty). |
|
One ramification I can think of is for the "Patch Instruction" command. It will still expect the syntax that appears in the usual Mnemonic/Operands fields. Maybe that's not a problem, but it's something to consider. |
|
@NeatMonster Have you release what you have as open source? I looked on your github and did not see anything. If you could release what you have as open source that'd be awesome. Thanks. |
Hello,
I'm trying to add support for the Qualcomm's Hexagon V5x architecture to Ghidra.
However, I am facing 1 non-blocking and 1 blocking issue:
{and the suffix}, like so:Because Ghidra strips whitespace from the beginning of the display section, I end up with:
I've been using
.as a second space character, but while it works it isn't pretty.^. The whole line is now being treated as part of the mnemonic, and the operands are not being recognised.Is there any solution to these issues? If not, I'm guessing the Sleigh language has to be modified.
For reference, here is my current code:
The text was updated successfully, but these errors were encountered: