17/01/2020 : Introduction au DataCamp avec Notre chère Professeure Mme Agathe Guilloux. L'objectif de cette compétition et les rendus attendus nous ont été présentés. Un suivi hebdomadaire du DataCamp est mis en place et sera supervisé par M. Simon Bussy.
24/01/2020 : Cette séance nous a permis de créer les différents fichiers liés au projet. Vous trouverez une presentation globale du projet et de la structure du répertoire dans le fichier Readme. Nous avons aussi procédé à une répartition des tâches. Nous n'avons pas choisi une structure avec un chef de groupe mais plutôt un responsable pour chacune des parties du projet. Ci dessous, une vision globale de cette répartition :
| Mohamed Niang | Fernanda Tchouacheu (Nando-512) | Hypolite Chokki |
|---|---|---|
| Data exploration | Desciptive Statistics | Naive Bayes |
| Missing Data Problem | Memory reduction | Resampling techniques |
| Imbalanced problem | LGBM Classifier | Logistic Regression |
| Preprocessing | KNearest Neighbors | |
| XGBoost Classifier | Features engineering | |
| LGBM Classifier | Logistic Regression | |
| Magic features | DecisionTree | |
| Neural Network | Random Forest | |
| Notebook final | Rapport |
Nous avons aussi effectué une exploration de nos données. Ces dernières sont subdivisées en 4 :
-
train_transaction & test_transaction :
- TransactionDT: qui mesure le temps en seconde
- TransactionAMT: montant du paiement de la transaction en USD
- ProductCD: code produit, le produit pour chaque transaction
- card1 - card6: informations de carte de paiement
- addr: adresse
- dist: distance
- Domaine de messagerie P_ et (R__): domaine de messagerie de l'acheteur et du destinataire
- C1-C14: comptage, par exemple le nombre d'adresses associées à la carte de paiement, etc
- D1-D15: timedelta, comme les jours entre la transaction précédente, etc
- M1-M9: correspondance, comme les noms sur la carte et l'adresse, etc
Caractéristiques catégoriques: ProductCD card1 - card6 addr1, addr2 Pemaildomain Remaildomain M1 - M9 -
train_identity & test_identity :
Les variables de ce tableau sont les informations d'identité - les informations de connexion réseau (IP, FAI, proxy, etc.) et la signature numérique (UA / navigateur / os / version, etc.) associées aux transactions.
Ils sont collectés par le système de protection contre la fraude de Vesta et les partenaires de sécurité numérique.
Les noms de champ sont masqués et le dictionnaire par paire ne sera pas fourni pour la protection de la vie privée et l'accord de contrat.
Caractéristiques catégoriques:
DeviceType
DeviceInfo
id12 - id38
31/01/2019 : cette séance nous a permis de mieux explorer les données.Nous avons commencé par faire une exploration des données, visualiser les problèmes que souffrent nos données. Nous avons aussi fait quelques analyses statistiques et descriptives sur les données afin de comprendre ce que nous avons comme données.
14/02/2020 :Cette séance nous a permis de finir avec la partie statistique descriptive et la première partie de traitement des données, vu qu'il y avait beaucoup de missing value dans les données. Vu le problème de classe non balancée, il nous est primordial de le corriger avant de s'attaquer aux méthodes d'apprentissages classiques et d'apprentissages profonds. En effet, lorsque les données présentent des classes non équilibrées, il sera pas du tout ingenieux d'utiliser les memes techniques classiques pour résoudre le problème posé. Il est recomandé aux Data Scientist de revoir soit la métrique à utliser pour évaluer la performance des modèles (matrice de confusion, f1_score, precision, recall, etc), soit d'utiliser une technique de resampling, soit d'utiliser les algorithmes ensemblistes (XGBOOST, LGBM, etc) pour contourner le problème de classe non équilibrée.
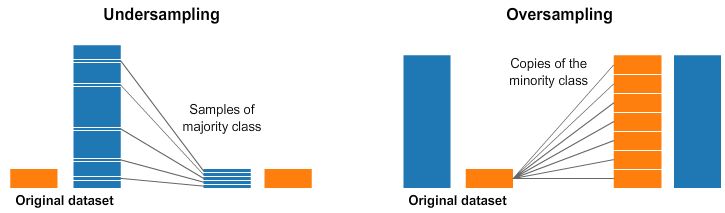
Pour ce faire, dans cette séance, nous avons commencé à tester les méthodes de resampling. Premièrement, nous avons fait du oversampling qui consiste à ajouter des exemples sur la classe minoritaire pour équilibrer les classes. Cet ajout d'exemple s'appuie juste sur un tirage avec remise de l'échantillon constituant la classe minoritaire, donc non robuste si on présente beaucoup de données. Cette dernière méthode a été testé mais n'a pas donné de bon résultat. Du coup, en faisant un peu de recherche, on s'est appercu qu'il existe d'autres techniques de resampling plus sophistiquées en utlisant le module imbalanced-learn de Python.
Au lieu de créer des copies exactes des individus de la classe minoritaire, nous pouvons introduire de petites variations dans ces copies, créant ainsi des échantillons synthétiques plus diversifiés. Mais malheuresement, cette méthode n'a pas aussi marché. Du coup, on s'est tourné à utiliser une autre technique de ré-échantillonnage, le SMOTE.
Le SMOTE (Synthetic Minority Oversampling Technique) consiste à synthétiser des éléments pour la classe minoritaire, en se basant sur ceux qui existent déjà. Elle consiste à choisir au hasard un point de la classe minoritaire et à calculer les voisins les plus proches pour ce point. Les points de synthèse sont ajoutés entre le point choisi et ses voisins.
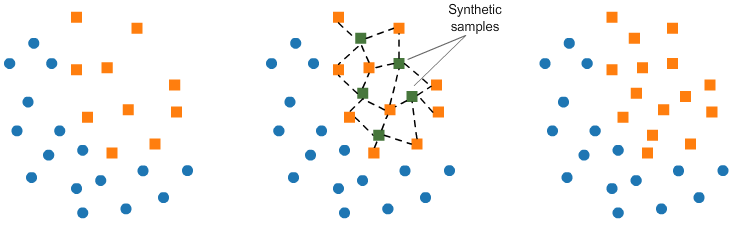
Cependant, meme le SMOTE n'arrivais pas à nous donner de bon résultat. Ainsi pour contourner le probléme, nous avons proceder à une simple stratification lors du split du jeux de données initiales en apprentissage et validation.
Dans le cas d’un problème de classification, on s’efforce généralement de créer les k folds de sorte à ce qu’elles contiennent à peu près les mêmes proportions d’exemples de chaque classe que le jeu de données complet. On cherche à éviter qu’un jeu d’entraînement ne contienne que des exemples positifs et que le jeu de test correspondant ne contienne que des exemples négatifs, ce qui va affecter négativement la performance du modèle, c'est ce que l'on appelle la stratification.

21/02/2020 : Cette séance nous a permis de lancer nos premiers modèles qui sont robustes sur données non banlancée et présentant des missing. Ces derniers sont : le XGBoost et le LGBM. Ces modèles sont non seulement efficace pour les données présentant des problèmes de classe non balancée mais aussi pour des données présentant des outliers, des features non standardisées, des features collinéaires et des missing values.
XGBoost



LGBM

XGBOOST and LGBM working

XGBOOST and LGBM Magic working
Les variables magiques se font en trois étapes. D'abord, nous avons besoin d'une variable UID pour identifier les clients (cartes de crédit). Ensuite, nous devons créer des caractéristiques de groupe agrégées. Et enfin, nous retirons l'UID. Supposons que nous ayons 10 transactions
A, B, C, D, E, F, G, H, I, Jcomme ci-dessous.

Si nous n'utilisons que les FeatureX, nous pouvons classer correctement 70 % des transactions. Ci-dessous, les cercles jaunes correspondent aux transactions "isFraud=1" et les cercles bleus aux transactions "isFraud=0". Après que le modèle d'arbre ci-dessous ait divisé les données deux groupes gauche et droite, nous prédisons
isFraud=1pour le groupe de gauche etisFraud=0pour le groupe de droite. Ainsi, 7 prédictions sur 10 sont correctes.

Supposons maintenant que nous ayons un UID qui définit les groupes et que nous fassions une caractéristique agrégée en prenant la moyenne de FeatureX dans chaque groupe. Nous pouvons maintenant classer correctement 100 % des transactions. Notez que nous n'utilisons jamais l'UID de la caractéristique dans notre arbre de décision.

The Cross-Validation Procedure
Dans la validation croisée, nous exécutons notre processus de modélisation sur différents sous-ensembles de données pour obtenir de multiples mesures de la qualité du modèle. Par exemple, nous pourrions avoir 5 plis ou expériences. Nous divisons les données en 5 morceaux, chacun représentant 20% de l'ensemble des données.

Nous menons une expérience appelée expérience 1, qui utilise le premier pli comme un ensemble de données d'entraînement, et tout le reste comme des données d'entraînement. Cela nous donne une mesure de la qualité du modèle basée sur un ensemble de 20 % de données d'attente, comme nous l'avons obtenu en utilisant la simple répartition train-test.
Nous effectuons ensuite une deuxième expérience, où nous retenons les données du deuxième pli (en utilisant tout sauf le deuxième pli pour l'entraînement du modèle). Nous répétons ce processus, en utilisant chaque pli une fois comme données de référence. Au total, 100 % des données sont utilisées comme données de référence à un moment donné.
28/02/2020 : Pour cette séance, nous avons reussi à faire notre première soumission kaggle pour le modèle XGBoost avec un accuracy de 97% sur le test. Ainsi nous allons poursuivre avec les autres modèles dérivés du Gradient Boosting et faire les soumissions.
06/03/2020 : Nous avons réussi à faire l'optimisation des paramètres du premier modèle XGBoost et nous obtenu un accuracy de 98% sur le test. Ce modèle a pu amélioré le score public et privé sur Kaggle après soumission. Après ceci, nous avons lancé le modèle LGBM avec optimisation des hyperparamètres pour lequel aussi on a eu un accuracy de 98%. Toutefois puisqu'on est en présence de classe non balancée, on peut s'attendre à ce que l'accuracy surestime la précision. Ainsi pour la suite, nous allons aussi nous basé sur le score AUC pour mesuré le pouvoir prédictif des modèles. En poursuivant la modélisation, nous avons enrichit le modèle XGBOOST, cette fois ci en faisant du local validation et cross validation et en créant de nouvelles features obtenues par aggrégation d'autres features, qui nous a donné un score public de 0.950164 et un score privé de 0.921794 après soumission sur Kaggle. Pour la suite, nous allons poursuivre avec le modèle LGBM en faisant aussi la meme chose comme pour le XGBOOST. En meme temps, nous avons débuter avec la rédaction du rapport.
16/03/2020 : Nous allons finir avec la modélisation et faire les dernières soumissions Kaggle. Ensuite, nous allons poursuivre avec la rédaction du rapport. Avec le modèle LGBM, nous avons obtenu un accuracy de 99% et un AUC de 97,68%. Ce modèle a pu amélioré le score privé sur Kaggle après soumission qui est ainsi devenu 0.921948 mais n'a pas amélioré le score public. Mais quand meme avec l'aggregation des features, on voit qu'on obtient de très bon résultat. Ainsi, nous allons poursuivre et finir avec l'apprentissage profond , et nous avons lancées notre premier réseau de neurone (MLP) avec quelques spécifications.
27/03/2020: Notre réseau de neurones est assez standard. Nous avons utilisé la couche d'intégration pour que les catégories et les données numériques passent au travers des couches denses à propagation directe.
Nous avons crée des couches d'intégration de manière à avoir autant de lignes que de catégories et la dimension de l'intégration est le log1p + 1 du nombre de catégories. Cela signifie donc que les variables catégorielles à très haute cardinalité auront plus de dimensions, mais pas de manière significative, de sorte que les informations seront toujours comprimées à environ 18 dimensions seulement et que le nombre de catégories ne sera que de 2 à 3.
Nous avons ensuite passer les encastrements à travers une couche d'exclusion spatiale qui réduira les dimensions à l'intérieur de l'encastrement par lots, puis les aplatira et les concaténera. Nous avons concatené ensuite ces éléments aux caractéristiques numériques et avons appliqué la norme des lots (batch normalization), puis nous avons ajouté des couches plus denses par la suite.
Notre réseau de neurone a donnée les performances suivantes :

Il ressort de l'analyse de la matrice de confusion, d'une part, qu'il y a 1958 False-Positive c'est-à-dire une transaction non frauduleuse prédite comme étant une transaction frauduleuse et d'autre part, qu'il y a 183 False-Negative c'est-à-dire une transaction frauduleuse prédite comme étant une transaction non frauduleuse.
A cela, s'ajoute le fait qu'on observe que le modèle de LGBM donne un nombre plus signifiant de True-Negative (c'est-dire les tansactions qui sont correctement classées comme frauduleuse).

A la lumière du graphique ci-dessus, il ressort que l'aire en dessous de la courbe est de 0.955, c'est-à-dire que nous avons un AUC de 0.955. Ce qui prouve souligne la robustesse de notre réseau de neurone malgré les nombreux problèmes que nous avons rencontré.
Les modèles classiques comme le KNN, les Arbres de Décision et le Logistic Regression n'ont pas pu donner de meilleurs résultats par rapport aux modèles ensemblistes que nous avons fait plus haut. Vu les nombreuses anomalies que nous avions eu sur les données, c'était bien évidente que ca se passe ainsi.
Ainsi, ayant finit avec la modélisation, nous allons consacré le reste de notre temps sur le rapport.