Parallelize Loaders #96
Comments
|
As discussed, I propose dropping the ABC library, if this creates problems. |
|
To be honst, I don't quite understand the issue, as I don't know how your loaders work. Why do you need to picle the class? Can't you create a delayed dataframe, like in the mpes and generic loader? |
Since we were using multiprocessing module to parallelize the data, it uses pickling in the backend to seralize the data. |
|
@daviddoji we'd like to parallelize the loading of the files for all loaders. It could possibly be a method in the BaseLoader class. Do you have any suggestions regarding this? |
Take into account that I'm using a node in Maxwell cluster to do this, so in my use case, memory is less of an issue. Having said that, here are my suggestions:
|
|
I think I still don't understand. What is the advantage compared to handling the data access and parallelization with dask? |
|
Let me contextualize this a little: what we want to achieve is to transform each .h5 file, composed of multiple tables with 3 different indexes (very fast, fast and very slow). These need to be aligned to form a single table, which we save as a parquet file. This parquet file is then loaded again and we "explode" it to have all channels with the common "very fast" index. We do this process using pandas and multiindex for each file. As each file is indipendent of the others, we can do this parallely, loading n-files simultaneously and generating the n parquet files, which we later can concatenate and explode when needed. This worked in hextof processor, and @zainsohail04 is now trying to find a more elegant way to achieve this here, where the loader has a parent class which might be common to different loaders from different end-stations. @daviddoji do you have suggestions in this direction? it is unrelated to he binning, only re-sorting tables with different indexes, if you want. |
|
Why do you have to go the way via the parquet files? Can't you assemble and explode the columns on-the-fly and directly generate the delayed Dask dataframe from the h5 files, as the mpes loader does? |
I'd never use pandas for anything involving 'fast' access. Did you have a look to polars? |
|
I looked a little into polars, as it might help to generate the parquets we need in the first step. However it does not seem to support hdf5 and thy suggest to use pandas instead to load... any thoughts on this? @daviddoji |
Using |
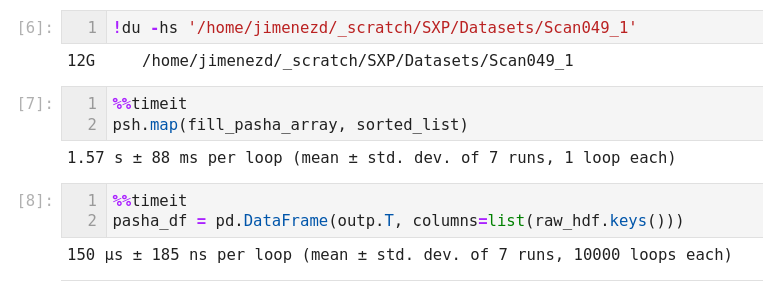
We never really use the hdf5 method from pandas to read our data so I think directly using polars should work okay, no? We are just creating numpy arrays from the different groups that are defined in config.
This also looks very promising for our FlashLoader at the very least. |
|
As @steinnymir very well mentioned, you can't really read directly hdf5 directly into a polars df, but you can definitely use the same trick as I did above (creating a numpy array and then converted it to a df) |
|
This looks interesting, and you are right @zainsohail04, we read the hdf5 files with h5py, not pandas, so we might be able to use polars directly. |
|
I think we should understand where the bottleneck lies. @Prun can help. |
|
Definitively, you should time your loaders and, as @rettigl says, find where the bottleneck is. Concerning the numbers I showed above, bare in mind that I run my code on Maxwell, which uses GPFS as filesystem. This is not an SSD from a laptop! |
|
@zain-sohail is this still relevant? FLASH has fully parallel loaders, and we don't really have other loaders to parallelize... |
I think improvements can def be made but flash loader is plenty fast as of now so closing for now. |
Describe the solution you'd like
The loaders should be able to load the files in parallel. Ideally, all loaders, otherwise at least flash and lab.
Describe alternatives you've considered
With abstract class, it currenty can not pickle and unpickle data for multiprocessing module. Hence, it doesn't work. Using multiprocessing on the BaseLoader level would be ideal, as then things should work.
The text was updated successfully, but these errors were encountered: