请教embedding和fc层的区别 #2910
Comments
|
关于 embedding 的作用:
|
|
embeding层可以理解为从一个矩阵中选择一行,一行对应着一个离散的新的特征表达,是一种取词操作。 推荐系统中的例子,embedding 可以简单的看作是将离散特征转化为实向量特征表达,从整体的计算逻辑上:
|
|
针对你的四个问题:
|
|
我不理解的问题是,这个embedding层是如何实现的呢?因为从one-hot到distributed representation,是要通过序列或者context-target文本对进行训练的。但是我看到的网络结构中,并没有任何这方面的对应关系,那么, |
|
|
good-question |
|
|
我觉得你把“如何学习词向量”和 如果你需要“context-target去训练一个三层的网络” ,例子在这里: |
这个问题,没有绝对的“最好”。上面也解释过,如果不是序列输入,并且 有一个最粗暴的原则,不管什么模型,先拟合住再说。 |
|
我不知道理解的对不对,对于原始输入 -- embedding -- fc 在训练反向传播的时候,是传播到原始的输入层(下图中篮框),还是传播到embedding(下图中红框)就截止了? embedding仅仅是起到编码的作用? |

|
embedding 有参数需要学习,因此在BP时,会接收到梯度。反向传播不会在embedding层截止。 |
|
https://keras.io/layers/embeddings/ keras的embedding是参考https://arxiv.org/pdf/1512.05287.pdf 这个实现的,类似对输入数据进行dropout,同好奇paddle的embedding是怎么实现的 |
|
paddle的embedding是用table_projection实现的,具体代码见这里: table_projection的公式是 |
|
区别在embedding layer与前后层的兼容上 |
|
Closing this issue due to inactivity, feel free to reopen it. |
我看到book中推荐系统的网络结构,从用户、电影的原始输入,到feature之间,都是embedding_layer + fc_layer:
请问:
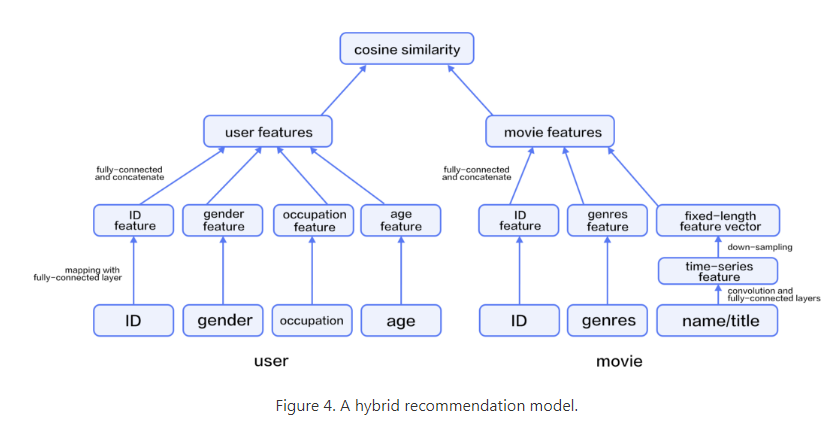
1)这里embedding的作用是什么?
2)embedding和fc有什么区别呢?
另外我了解的embedding层,主要作用除了降维之外,embedding的输出结果还可以近似表达词之间的相关程度,这就需要训练的时候将输入切分成:context -> target的训练对语料:
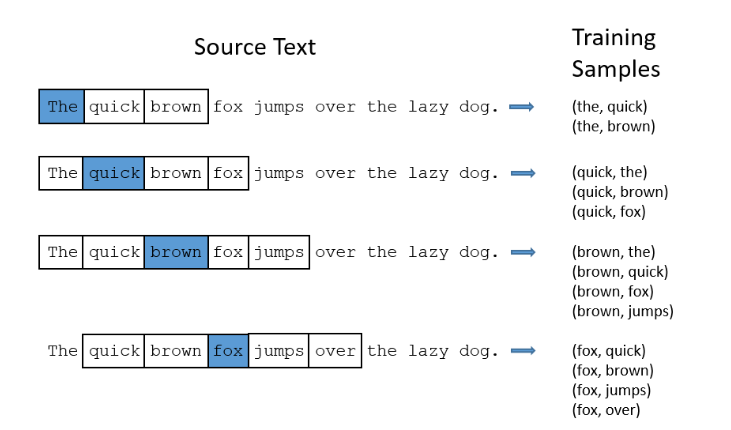
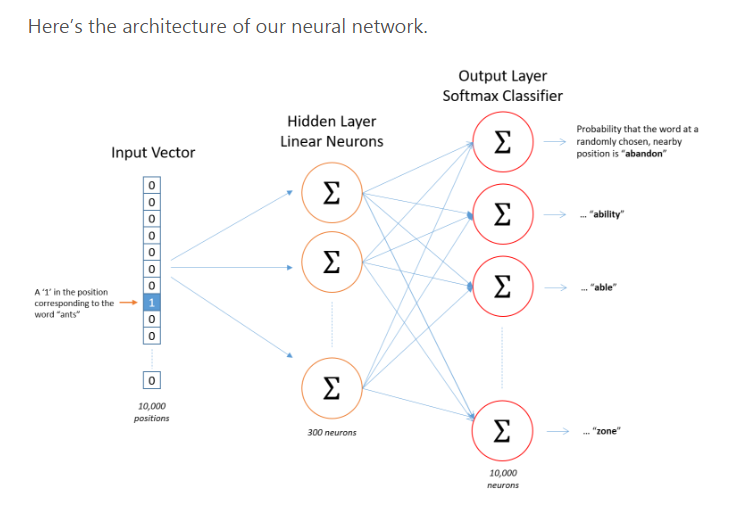
实际上这样是一个三层的网络(输入,隐藏,输出),当使用的时候舍去输出层,用隐藏层的矩阵作为输出结果
请问:
3)咱们paddle的embedding_layer,是上述的概念么?
还有一个问题:
4)我看推荐这个例子中,用户的职业,性别等,都是one-hot,如果加入一个用户兴趣,那么兴趣可能是一组多个维度为1的vector,那么这中vector的输入,在embedding和fc层的输出结果,有什么区别呢?
问题比较多,希望各位大侠赐教!
The text was updated successfully, but these errors were encountered: