[Question]: taskflow('document_intelligence') 和 直接使用预模型ernie-layoutx-base-uncased 做预测有什么区别? #3517
Comments
|
taskflow('document_intelligence') 中的模型是基于ERNIE-Layout模型通过大量文档信息抽取、文档问答相关语料微调之后的模型参数,layoutxlm-base-uncased 是基础的预训练模型 |
|
是否可以基于taskflow('document_intelligence') 的模型进行fine-tuning.而不是基于layoutxlm-base-uncased,按您的描述我们自己的小样本微调layoutxlm-base-uncased 达到的效果估计是还不如taskflow('document_intelligence')的模型。 |
taskflow('document_intelligence')的模型是一个静态图部署的模型,目前我们还没有放开静态图微调能力,在11月份我们会放开端到端多模信息抽取相关的微调能力,包括整体数据标注方法、小样本微调、部署相关能力 |
|
这里我有个疑惑,在多模态layout这个场景上,我关注到unilm layoutlm和paddlenlp layoutlm两种方案。我是希望能够使用paddle,因为我认为paddle在中文语料训练做的更好。但是如果无法利用taskflow('document_intelligence') 中的模型的结果,就有点尴尬了。同时关于11月分这个节点能否预估个具体时间,因为我的项目大约在11月初就需要具备demo能力。同时这个端对端微调,是否支持直接输入doc原始文档,而不需要手动转换图片在切割分页,在合并预测结果 |
|
taskflow('document_intelligence') 目前的能力没有办法完全你的业务场景吗? |
|
我现在做法是分页预测在合并结果,现在有发现一个问题,就是如果实体出现多次在一个页上,会出现识别错误的情况,在布局层面 |
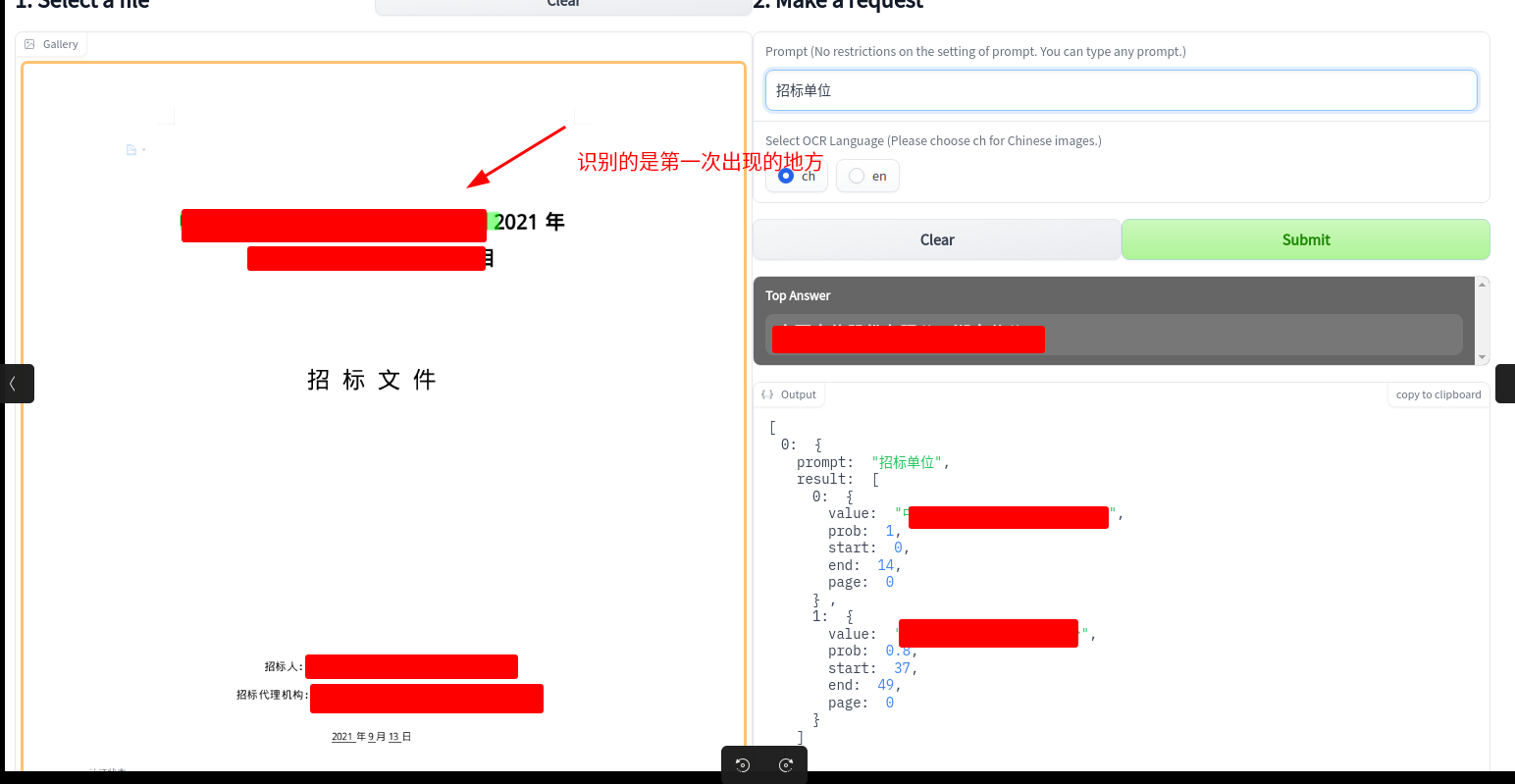
|
而且由于您说的taskflow('document_intelligence') 目前无法微调,万一出现预测错误的情况,我无法通过标记去优化模型 |
|
要是能提供动态图模型的参数就好了,我也遇到这个问题。我试了静态图转动态图直接就报错了。 |
能发布动态图的模型参数吗 |
现在就是必须要有微调能力,但是不希望从基础的layoutxlm-base-uncased进行微调,希望能有paddle庞大的语料库 |
|
这个场景应该还是和具体的业务场景关系比较大,需要微调 |
|
有没有尝试过ernie-layoutx,https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout |
|
是啊,有动态图模型的参数就可以微调了,可以参考UIE。 |
@wawltor 不好意思,我应该是发错了,不是layoutx-base-uncased ,而是 ernie-layoutx-base-uncased 和 taskflow('document_intelligence')是否是一致的模型 |
这个不就是taskflow('document_intelligence') 的基模型吗,从您上面的答复里面看,taskflow('document_intelligence') 的基模型就是ernie-layout,不知道有没有理解错。 |
|
在application目录下https://github.com/PaddlePaddle/PaddleNLP/blob/develop/applications/document_intelligence/doc_vqa/Extraction/run_train.sh 这个脚本,上面用的layoutx-base-uncased模型 |
我使用ernie-layoutx进行自有训练集cls分类训练,似乎是没效果。 |
您是怎么做数据标记的,能参考下吗?我还在处理标记的事情,没开始训练,建议可以打印下模型,确认下是否被冻结了 |
我查看了下ernie-layoutx模型下的voc词文档,疑惑是不是要自己组织自己的词。 |
|
留个联系方式,细说一下吧。 |
862112830 QQ |
请问,发现taskflow('document_intelligence')这种方式,是在.cache/下会生成docprompt_params.tar文件,解压后有一个模型文件inference.pdiparams和inference.pdmodel。而使用autoModel,是下载预训练模型。
我想知道是否使用taskflow效果会更好,还是和直接使用预训练模型(没经过ft)进行预测效果一致。两者的训练数据是否是一样,是不是就是一个东西?
The text was updated successfully, but these errors were encountered: