Train ds2 on THCHS30 (WIP) #133
Comments
|
After some digging, a serious bug is found in |

|
您好,此issue在近一个月内暂无更新,我们将于今天内关闭。若在关闭后您仍需跟进提问,可重新开启此问题,我们将在24小时内回复您。因关闭带来的不便我们深表歉意,请您谅解~感谢您对PaddlePaddle的支持! |
|
After some digging, a serious bug is found in |
|
您好,此issue在近一个月内暂无更新,我们将于今天内关闭。若在关闭后您仍需跟进提问,可重新开启此问题,我们将在24小时内回复您。因关闭带来的不便我们深表歉意,请您谅解~感谢您对PaddlePaddle的支持! |
I am trying to train ds2 on THCHS30 which is a mandarin dataset. A phenomenon is that we encounter error explosion easily when
batch_sizeis big liking 64, 128 or 256. I try to clip the error to 1000 wheninfappears. The clipping operation is very tricky, I catchinfand clip inpaddle/v2/trainer.pyas following:We can train ds2 normally after adding the clipping operation. I have tried to train the model using
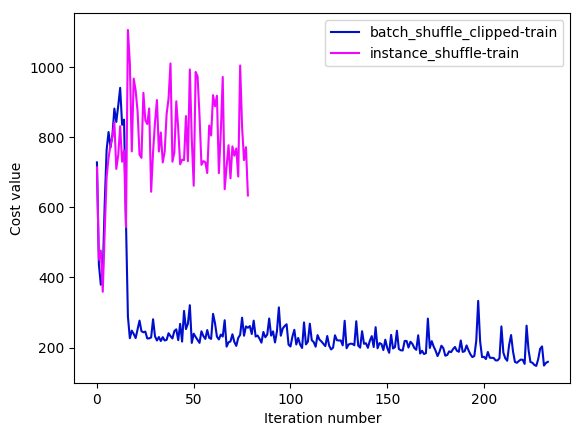
batch_shuffle_clippedprovider andinstance_shuffleprovider. The learning curves are as following:As we can see,
instance_shuffleconverges badly and I abandon this configuration after training several iterations. Thebatch_shuffle_clippedconfiguration looks like converging very slowly when the training cost goes down to 170~. The key settings of above experiments are:I also product another experiment on a tiny dataset which only contains 128 samples (first 128). Training data and validation data both use the tiny dataset. Training settings are same with above. Following are the learning curves:
From the figure above we can learn that the convergence is very unstable and slow. There exists a unreasonable gap between training curve and validation curve. Since the training data and validation data are same, the difference of two curves should be minor. Will figure out the reason of the anomalies.
The text was updated successfully, but these errors were encountered: