video_path is what ? #4510
Comments
|
but no, So what's the para 's meaning ? |
|
您好,哪个模型呢 |
|
the --video_path argument is designed to point to the video file to be processed, it can be 'D:/python36/new/dyrandom/mvideo_0.mp4'. However, only models such as TSN, TSM, StNet and NONLOCAL in PaddleVideo support processing a video file of MP4 or other format. |
|
@SunGaofeng |
This is similar to those used in the training dataset, where all the feature data are transformed from the Youtube-8M original data and stored in the pickle format. For details, you can refer to this document https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/video/data/dataset#Youtube-8M数据集 If you use your own video file, you can use a pertained model to extract the rgb/audio feature data for each frame. For each video, the data format is a dictionary as:
|
|
@SunGaofeng |
|
some other question So could U please help me ? |

|
If you have different frame numbers for audio and video, just set different 'nframes' value for them.
|
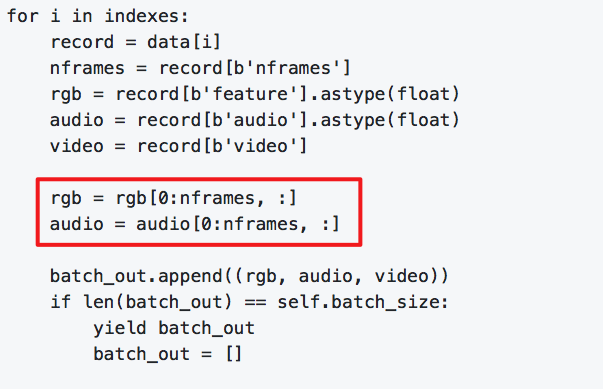
|
@SunGaofeng |
hi,dear
in the predict.py,
what's the meaning ?
video_path is the video what I want to test/infer ?
thx
The text was updated successfully, but these errors were encountered: