RuntimeError: DF dataloader error: ThreadJoinError("Any { .. }") when attempting to train DeepFilterNet #187
Comments
|
Update: this was caused by not specifying --mono when using prepare-data.py on mono wav files to generate the hdf5 files |
|
@AnonymousEliforp on which version did this error occur? On main there is no |
Not sure if this is what you mean, but I was using deepfilternet2 on the main branch |
|
At what exact commit? The main branch has changed and does not fit to your stack trace. |
As far as I can tell from |
|
Hm there is also no unwrap call on DeepFilterNet/libDF/src/dataset.rs Line 1134 in bc6bd91 Your stack trace above said something else: |
|
|

|
Ah, now I see. You used the main branch, but installed the rust modules from pypi. The error is since you don't have any noise samples in your dataset. If you run train.py with |
|
|
|
You only have speech datasets. |
|
Ok, but I meant for the hdf5 files ending with NOISE to be the noise datasets and in dataset.cfg, I have tried to follow the example dataset configuration. |

|
No in your prepare_dataset usage. |
|
ah ok that is my bad then I have realised my mistake now so sorry for this and thanks for your help |
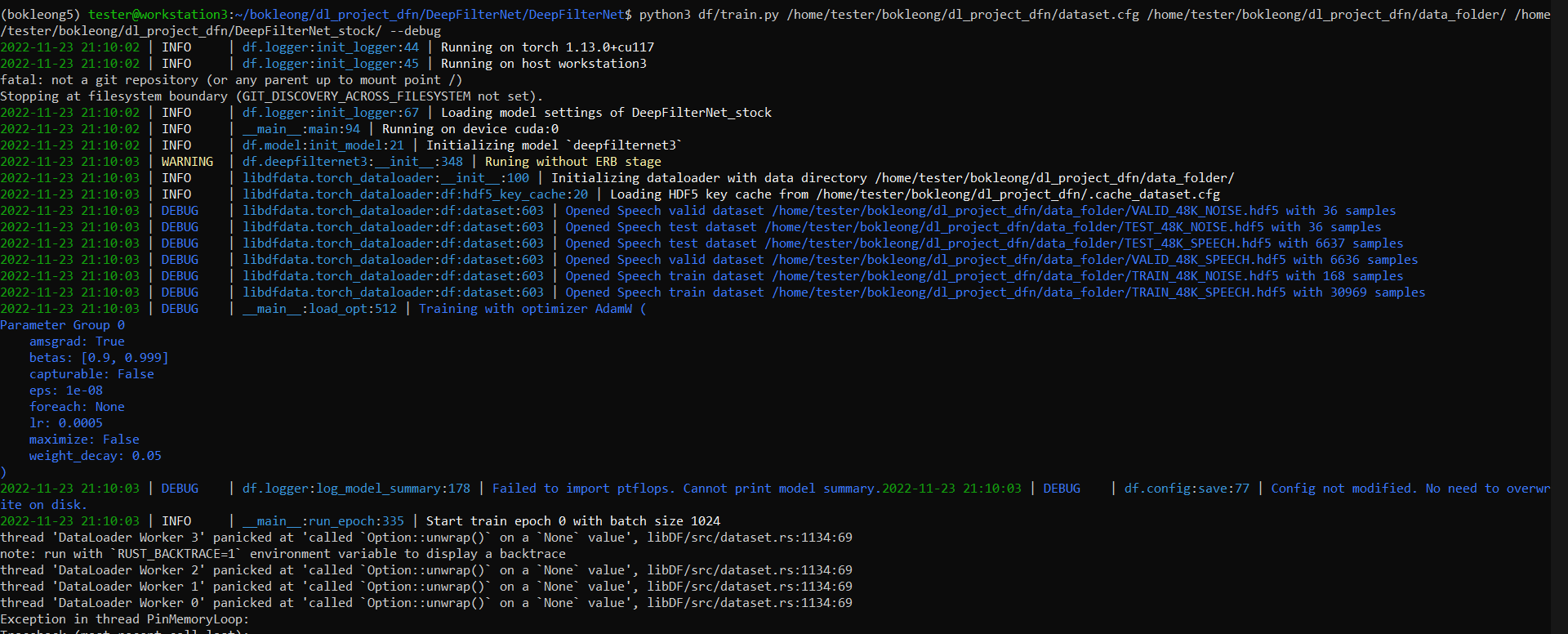
I am trying to train DeepFilterNet but I am running into the following error when training:
RuntimeError: DF dataloader error: ThreadJoinError("Any { .. }").What I did
I installed DeepFilterNet via PyPI using:
Then I generated the following HDF5 dataset files:
and placed them into the same directory
.../data_folder.I also created a
config.inifile with the following contents:config.ini
and put it in a directory
.../log_folder.I also created a
dataset.cfgfile with the following contents:dataset.cfg
{ "train": [ [ "TRAIN_SET_SPEECH.hdf5", 1.0 ], [ "TRAIN_SET_NOISE.hdf5", 1.0 ] ], "valid": [ [ "VALID_SET_SPEECH.hdf5", 1.0 ], [ "VALID_SET_NOISE.hdf5", 1.0 ] ], "test": [ [ "TEST_SET_SPEECH.hdf5", 1.0 ], [ "TEST_SET_NOISE.hdf5", 1.0 ] ] }Lastly, I ran the command to train the model:
and this is the output that I get:
Appreciate any help on this, thank you!
The text was updated successfully, but these errors were encountered: