These Redis vs RavenDB benchmarks have been made into a bar chart for a better visualization.
Seeing that Redis v2.0 has been just been released and Oren Eini (aka @ayende) has just checked in performance optimization improvements that show a 2x speed improvement for raw writes in RavenDB, I thought it was a good time to do a benchmark pitting these 2 popular NoSQL data stores against each other.
For the best chance of an Apples to Apples comparison I just copied the RavenDB’s benchmarks solution project and modified it slightly only to slot in the equivalent Redis operations. The modified solution is available here. Redis was also configured to run in its ‘most safest mode’ where it keeps an append only transaction log with the fsync option so the operation does not complete until the transaction log entry is written to disk. This is so we can get Redis to closely match RavenDB’s default behaviour. Enabling this behaviour in Redis is simply a matter of uncommenting the lines below in redis.conf:
appendonly yes
appendfsync always
To use this new configuration simply run ‘redis-server.exe /path/to/redis.conf’ on the command line. Other changes I made for these new set of benchmarks was to remove batching from the Redis benchmark since its an accidental complexity not required or useful for the Redis Client.
Here are the benchmarks with these new changes in place:
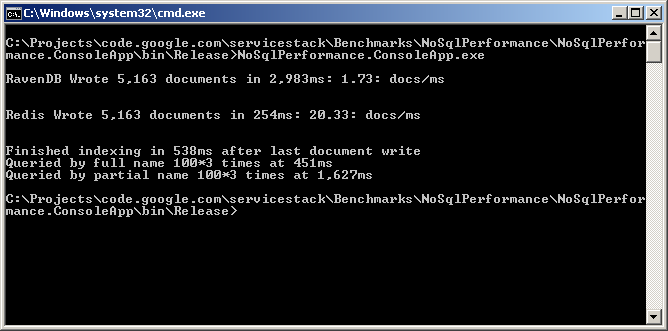
Which for this scenario show that:
Note: The benchmarks here are of Redis running on a Windows Server through the Linux API emulation layer - Cygwin. Expect better results when running Redis on Unix servers where it is actively developed and optimized for. It is understood that the Cygwin version of redis-server is 4-10x slower than the native Linux version so expect results to be much better in production.
I attribute the large discrepancy between Redis and RavenDB due to the fact that Redis doesn’t use batches so only pays the ‘fsync penalty’ once instead of once per batch.
The ‘appendfsync always‘ mode is not an optimal configuration for a single process since Redis has to block to wait for the transaction log entry to be written to disk, a more sane configuration would be ‘appendfsync everysec‘ which writes to the transaction log asynchronously. Running the same benchmark using the default configuration yields the following results:
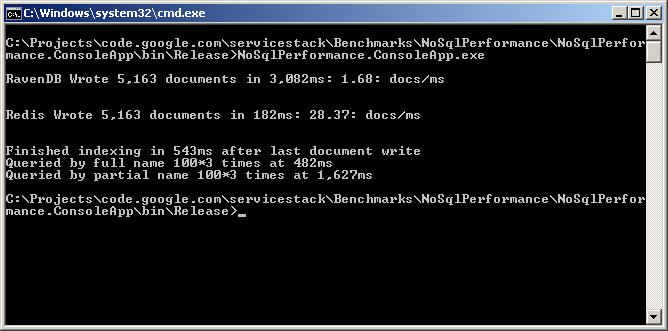
Which is a 39% improvement over the previous benchmarks where now:
Which unless I hear otherwise? should make this the fastest NoSQL solution available for .NET or MONO clients.
Measuring raw write performance using Redis is a little unfair since it has a batchful operation MSET specifically optimized for this task. But that is just good practice, whenever you cross a process boundary you should be batching requests to minimize the number of your calls minimizing latency and maximizing performance.
Even though performance is important, its not the only metric when deciding which NoSQL database to use. If you have a lot of querying and reporting requirements that you don’t know up front then a document database like RavenDB, MongoDB or CouchDB is a better choice. Likewise if you have minimal querying requirements and performance is important than you would be better suited to using Redis – either way having a healthy array of vibrant choices available benefits everybody.
Since these benchmarks just writes entities in large batches to a local Redis or RavenDB instance using a single client, I don’t consider this to be indicative of a real-world test rather a measure is raw write performance, i.e. How fast each client can persist 5,163 entities in their respective datastore.
A better real-world test would be one that accesses the server over the network using multiple concurrent clients that were benchmarking typical usage of a real-world application rather than just raw writes as done here.
Based on the comments below there appears to be some confusion as to what Redis is and how it works. Redis is a high-performance data structures server written in C that operates predominantly in-memory and routinely persists to disk and maintains an Append-only transaction log file for data integrity – both of which are configurable.
For redundancy each instance has built-in support for replication so you can turn any redis instance into a slave of another, which can also be trivially configured at runtime. It also features its own Virtual Machine implementation so if your dataset exceeds your available memory, un-frequented values are swapped out to disk whilst the hot values remain in memory.
Like other high-performance network servers e.g. Nginx (the worlds fastest HTTP server), Node.js (a popular, very efficient web framework for JavaScript), Memcached, etc it achieves maximum efficiency by having each Redis instance run in a single process where all IO is asynchronous and no time is wasted context-switching between threads. To learn more about this architecture, check out Douglas Crockford (of JavaScript and JSON fame) imformative speech comparing event-loops vs threading for simulating concurrency.
It achieves concurrency by being really fast and achieves integrity by having all operations atomic. You are not just limited to the available transactions either as you can compose any combination of Redis commands together and process them atomically in a single transaction.
Effectively if you wanted to create the fastest NoSQL data store possible you would design it just like Redis and Memcached. Big kudos to @antirez for his continued relentless pursuit of optimizations resulting in Redis’s stellar performance.
Behind the scenes the Redis Client automatically stores the entities as JSON string values in Redis. Thanks to the ubiquitous nature of JSON I was easily able to develop a Redis Admin UI which provides a quick way to navigate and introspect your data in Redis. The Redis Admin UI runs on both .NET and Linux using Mono – A live demo is available here.
The benchmarks (minus the dependencies) are available in ServiceStack’s svn repo.
I also have a complete download with including all dependencies available here: http://servicestack.googlecode.com/files/NoSqlPerformance.zip (18MB)
Redis is sponsored by VMWare and has a vibrant pro-community behind it and been gaining a lot of popularity lately. Already with a library for every popular language in active use today, it is gaining momentum outside its Linux roots with twitter now starting to make use of it as well as popular .NET shops like the StackOverflow team taking advantage of it.
Unlike RavenDB and MongoDB which are document-orientated data stores, Redis is a ‘data structures’ server which although lacks some of the native querying functionalities found in Document DBs, encourage you to leverage its comp-sci data structures to maintain your own custom indexes to satisfy all your querying needs.
If these results have piqued your interest in Redis I invite you to try it out. If you don’t have a linux server handy, you can still get started by trying one of the windows server builds.
Included with ServiceStack is a feature-rich C# client which provides a familiar and easy to use C# API which like the rest of Service Stack runs on .NET and Linux with Mono.
I also have some useful documentation to help you get started:
- Designing a NoSQL Database using Redis
- A refactored example showing how to use Redis behind a repository pattern
- Painless data migrations with schema-less NoSQL datastores and Redis
- How to create custom atomic operations in Redis
- Publish/Subscribe messaging pattern in Redis
- Achieving High Performance, Distributed Locking with Redis