-
创建数据库
-
CREATE DATABASE 数据库名即可创建相应的数据库,命令不限定大小写,注意在创建含有特殊字符的数据库名的数据库的时候,需要使用反标记字符(`)用于引用标识符,如 ' create database `my.contacts` ',数据表名同理。 -
可以在连接数据库的同时就指定要连接的数据库,如
mysql -uroot -p 数据库名,这样一连接上就进入了该数据库。 -
进入mysql后,使用
use 数据库名,进入和切换相应的数据库,使用SELECT DATABASE()可以查看当前进入的数据库是哪个。 -
数据库被创建为数据目录中的一个目录,使用
SHOW VARIABLES LIKE 'datadir',可以查看到该目录所在的文件夹位置。
-
-
创建表
-
在表定义的时候,应该指定列的名称、数据类型(整型、浮点型、字符串等)和默认值(如果有的话)。
-
mysql支持的类型
- 数字:tinyint、smallint、mediumint、int、bigint和big
- 浮点型: decimal、float和double
- 字符串: char、varchar、binary、varbinary、blob、text、enum和set
- spatial数据类型
- json数据类型
-
例:
CREATE TABLE IF NOT EXISTS `company`.`customers` ( `id` int unsigned AUTO_INCREMENT PRIMARY KEY, `first_name` varchar(20), `last_name` varchar(20), `country` varchar(20) ) ENGINE=InnoDB;解释:
句点符号:表可以使用database.table来引用,如果使用use进入到了该database下,则可以直接使用table
IF NOT EXISTS: 若在创建表的时候已经存在了一个同名的数据表,则指定了IF NOT EXISTS的情况下,只会抛出一个警告,否则若不指定,则报异常。
ENGINE:用于指定创建表的数据引擎。InnoDB是唯一的事务引擎,也是默认引擎。
注意: 最后一个value后不能有逗号 -
可以在同一的数据库中创建多个表
CREATE TABLE payments ( `customer_name` varchar(20) PRIMARY KEY, `payment` float ); -
列出所有的表:
SHOW TABLES -
查看表结构
-
SHOW CREATE TABLE 表名\G: 查看创建数据表的结构,以创建表的语句的形式出现。 -
DESC 表名: 查看表结构。
-
-
创建表后,MySQL会在数据库目录内创建相应的
.ibd文件,使用SHOW VARIABLES LIKE 'datadir',可以查看到该目录所在的文件夹位置。 -
克隆表结构(创建一个和已有的表具有相同结构的表):
CREATE TABLE 新表名 LIKE 已存在的表的表名
-
-
操作数据库
-
插入 *
INSERT IGNORE INTO `company`.`customers` (first_name, last_name, country) VALUES ('Mike', 'Christensen', 'USA'), ('Andy', 'Hollands', 'Australia'), ('Ravi', 'Vedantam', 'India'), ('Rajiv', 'Perera', 'Sri Lanka');解释:
IGNORE: 如果该行已经存在,此时加入了IGNORE,新添加的数据将被忽略,且INSERT操作被显示为成功,同时生成一个警告和重复数据的数目,否则报错。
若插入的是完整的数据内容,即不使用自增的值和默认值的话,可以不写(first_name, last_name, country) -
更新 *
UPDATE customers SET first_name='Rajiv', country='UK' WHERE id=4;解释:
WHERE:这是用于过滤的字句。用于筛选出特定的数据。若不添加,则默认更改所有的数据。
WHERE字句是强制性的。建议在事务中修改数据,以便在发现任何错误的时候轻松的回滚这些更改 -
删除
DELETE FROM customers WHERE id=4 AND first_name='Rajiv';解释:
WHERE字句是强制性的,若没有WHERE,则会删除表中所有的数据,建议在事务中修改数据,以便在发现任何错误的时候轻松的回滚这些更改 -
REPLACE、INSERT和ON DUPLICATE KEY UPDATE
-
在很多情况下,我们需要处理重复项。行的唯一性有主键标识。如果行已经存在,则REPLACE会简单地删除行并重新插入新行;如果该行不存在,则此时的REPLACE等同于INSERT。
使用REPLACE在插入重复项(主键是不能重复的)的时候,会显示更新了两行,这是因为,先删除了原先的记录,又添加了新的记录,所以显示改变了两行。 -
如果想在行已经存在的情况下处理重复项,则需要使用ON DUPLICATE KEY UPDATE。如果指定了ON DUPLICATE KEY UPDATE选项,并且INSERT语句在PRIMARY KEY中引发了重复值,则MySQL会用新值更新已有行。
使用场景(类似于update操作,但是是以插入数据的形式进行的):
INSERT INTO payments VALUES ('Mike Christensen', 200) ON DUPLICATE KEY UPDATE payment=payment+VALUES(payment); INSERT INTO payments VALUES ('Mike Christensen', 300) ON DUPLICATE KEY UPDATE payment=payment+VALUES(payment);解释:
第一条语句直接在表中创建了一条新的数据,执行第二条语句时会发现customer_name这一项的值重复了,此时ON DUPLICATE KEY UPDATE就会生效,会覆盖原有的值,相当于对数据进行了更新,此时值应该是500。同时,我们发现显示修改了两条数据,这是因为,先删除了原先的记录,又添加了新的记录,所以显示改变了两行。
VALUES(payment)代表的是INSERT语句给的值,而payment是表中的列的值。 -
-
TRUNCATE TABLE
- 删除整个表需要很长时间,因为MySQL需要逐行执行操作。删除表中的所有行(保留表结构)的最快方法是使用TRUNCATING TABLE语句。
TRUNCATE TABLE 表名,是DDL操作,一旦数据被清楚,不能回滚。
- 删除整个表需要很长时间,因为MySQL需要逐行执行操作。删除表中的所有行(保留表结构)的最快方法是使用TRUNCATING TABLE语句。
-
select选择
-
操作符:mysql支持许多操作符来筛选结果。
- equality:
- IN:检查一个值是否再一组值内:找出姓氏为Christ和Lamba的所有员工数,
select COUNT(*) from employees where last_name in ('christ','Lamba') - BETWEEN AND: 找出1986年12月入职的员工数,
select COUNT(*) FROM employees WHERE hire_date BETWEEN '1986-12-01' AND '1976-12-31' - NOT:否定结果,找出不是在1986年12月入职的员工数,
select COUNT(*) FROM employees WHERE hire_date NOT BETWEEN '1986-12-01' AND '1976-12-31'
-
简单模式匹配:可以使用LIKE运算符来是实现简单的模式匹配。使用下划线(_)来精准匹配一个字符,使用(%)来匹配任意数量的字符。
- 找出名字以Christ开头的所有员工总数:
select count(*) from employees where first_name like 'christ%'; - 找出名字以Christ开头并以ed结尾的所有员工总数:
select count(*) from employees where first_name like 'christ%ed'; - 找出名字中包含str的所有员工的数:
select count(*) from employees where first_name like '%str%' - 找出名字中以ser的所有员工的数:
%er - 以任意两个字符开头、后面跟随ka、再后面跟随任意数字符的所有员工数:
like '__ka%'
- 找出名字以Christ开头的所有员工总数:
-
正则表达式:可以利用RLIKE或REGEXP运算符在WHERE子句中使用正则表达式。(RLIKE和REGEXP使用方法一样,即可以相互替代)
- 查找出姓氏以ba结尾的所有员工数:
select count(*) from employees where last_name rlike 'ba$'; - 查找姓氏不包含元音(a、e、i、o和u)的所有员工的人数:
select count(*) from employees where last_name not regexp '[aeiou]';
- 查找出姓氏以ba结尾的所有员工数:
-
限定结果,使用limit来进行设置
- 查询hire_data在1986年之前的任何10名员工的姓名,
select first_name, last_name from employees where hire_data < '1996-01-01' limit 10;
- 查询hire_data在1986年之前的任何10名员工的姓名,
-
使用表别名,使用AS来设置别名
- 对COUNT(*)使用AS来设置别名,
select count(*) AS count from employees;
- 对COUNT(*)使用AS来设置别名,
-
对结果进行排序(order by),可以根据列或者别名对结果进行排序,也可以用DESC指定按降序或用ASC指定升序来排序。默认情况下,按照升序排序。可以将limit子句与ordery by结合使用以限定结果集。
- 查找薪水最高的前5名员工的编号,
SELECT emp_no, salary from salaries order by salary limit 6;,若想降序,则使用SELECT emp_no, salary from salaries order by salary desc limit 6; - 也可以通过指定要进行排序的列所有表中的位置进行指定,如本次排序的salary列在表中的位置为2,则使用
SELECT emp_no, salary from salaries order by 2 limit 6;即可。
- 查找薪水最高的前5名员工的编号,
-
对结果进行分组(聚合函数)
- 可以使用group by子句对结果进行分组,然后使用AGGREGATE(聚合函数),如COUNT、MAX、MIN和AVERAGE。还可以在group by子句的列上使用函数。
- 分别找出男性和女性员工的人数:
select gender, count(gender) as count from employees group by gender - 找出员工名字(first_name)中最常见的10个名字,
select first_name, count(*) as count from employees group by first_name order by count desc limit 10;,这里的count()内使用的是*。 - 查找每年给予员工的薪水总额,
select year(from_date), sum(salary) as sum from salaries group by year(from_date) order by sum desc;,分析,这句查询实际上是按照from_date字段进行查询的,只是使用了year()函数,将每个全日期显示为年份。 - 查找平均工资最高的10名员工,
select emp_no, avg(salary) as avg from salaries group by emp_no order by avg desc limit 10; - 可以使用DISTINCT过滤掉相同的数据,如过滤掉不同的书籍,
select distinct title from titles;,此处使用select title from titles group by title;也可以达到相同的效果 - 使用HAVING过滤,可以通过添加HAVING子句来过滤GROUP BY子句的结果,如找到平均工资超过140000美元的员工,
select emp_no, avg(salary) as avg from salaries group by emp_no having avg >140000 order by avg desc;,可以发现having和where的区别在于:where是对select的范围进行过滤,过滤的是查询的范围,而having是对查询到的结果进行过滤,过滤的是查询到的结果。
- 分别找出男性和女性员工的人数:
- 可以使用group by子句对结果进行分组,然后使用AGGREGATE(聚合函数),如COUNT、MAX、MIN和AVERAGE。还可以在group by子句的列上使用函数。
-
-
-
创建用户,事实上不应该使用root用户连接到mysql并执行语句,除非是localhost的管理任务。我们应该创建用户,限制访问,限制资源使用等等。
-
如何做(创建用户需要拥有CREATE USER权限)
- 使用root连接到mysql并执行create user命令来创建新用户。
CREATE USER IF NOT EXISTS 'company_read_only'@'localhost' IDENTIFIED WITH mysql_native_password BY 'company_pass' WITH MAX_QUERIES_PER_HOUR 500 MAX_UPDATES_FER_HOUR 100;
参数说明:
用户名:company_read_only
仅从localhost访问,可以限制对IP范围的访问,例如10.148.%.%。通过给出%,用户可以从任何主机访问。
密码:company_pass
使用mysql_native_password(默认)身份验证,还可以指定任何可选的身份验证,例如sha256_password、LDAP或Kerberos。
用户可以在一小时内执行的最大查询数为500。
用户可以在一小时内执行的最大更新次数为100次。
注意: 由于mysql8密码策略的问题,导致简单的密码是不能通过验证的,下面我们通过修改密码验证的策略,使其能够使用简单的密码进行登录验证。
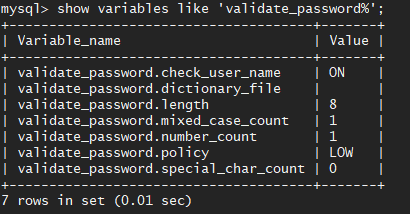
- 查看密码的验证策略:
show variables like 'validate_password%'进行查看
- 首先设置密码的验证强度等级,设置validate_password_policy的全局参数为LOW即可,设置语句为
set global validate_password_policy=LOW;进行设置。 - 使用类似的方法还可以设置密码的长度,但是默认最短不能低于4,所以一旦低于4,也是会默认为4的。
- 设置好后的效果,修改了密码验证的等级为LOW,修改了要求的特殊字符数为0。
关于 mysql 密码策略相关参数:
- validate_password.length 固定密码的总长度;
- validate_password.dictionary_file 指定密码验证的文件路径;
- validate_password.mixed_case_count 整个密码中至少要包含大/小写字母的总个数;
- validate_password.number_count 整个密码中至少要包含阿拉伯数字的个数;
- validate_password.policy 指定密码的强度验证等级,默认为 MEDIUM;
关于 validate_password_policy 的取值:
* LOW:只验证长度;
* MEDIUM:验证长度、数字、大小写、特殊字符;
* STRONG:验证长度、数字、大小写、特殊字符、字典文件; - validate_password.special_char_count 整个密码中至少要包含特殊字符的个数;
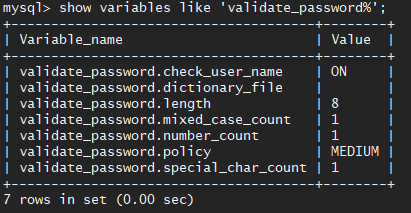
经过以上的设置,此时再重新创建用户即可,注意,由于我们设置了验证的强度为LOW,此时mysql服务器只会验证密码的长度是否符合要求,所以
CREATE USER IF NOT EXISTS 'company_read_only'@'localhost' IDENTIFIED WITH mysql_native_password BY 'company_pass' WITH MAX_QUERIES_PER_HOUR 500 MAX_UPDATES_FER_HOUR 100;是可以直接通过的。 - 使用root连接到mysql并执行create user命令来创建新用户。
-
授予和撤销用户的访问权限:可以限制用户的访问特定数据库或表,或限制特定操作,如SELECT、INSERT和UPDATE。需要拥有GRANT权限,才能为其他用户授予权限。
-
如何做: 可以通过root用户来授予权限,同时还可以创建管理员账户来管理用户。
-
将READ ONLY(只读权限SELECT)权限授予刚刚创建的company_read_only用户:
grant select on company.* to 'company_read_only'@'localhost';,该语句表示将对数据库company及其所有的表对本地访问的名为'company_read_only'的用户授予查询的权限 -
将INSERT权限授予新的company_insert_only用户:
grent insert on company.* to 'company_insert_only'@'localhost' indentified by 'xxx';,该语句在授予权限的时候同时创建新的用户。普通的创建用户的语句格式为create user "username"@"host" identified by "password"; -
将WRITE(即写权限,INSERT、UPDATE和DELETE)权限授予新建的company_write用户:
grant insert, delete, update on company.* to 'company_write'@'%' identified with mysql_native_password by 'xxxx'; -
限制查询指定的表。将employees_read_only用户限制为仅能查询employees表:
grant select on employees.employees to 'employees_read_only'@'%' identified with mysql_native_password by 'xxxx'; -
可以进一步将访问权限设置为仅能查询指定列。
grant select(first_name, last_name) on employees.employees to 'employees_read_only'@'%' identified with mysql_native_password by 'xxx';。 -
注意:在以上的语句在授予权限的同时都是创建新的用户,但是这是不被推荐的,在8.0.18版本已经不能这样使用了,推荐用法是先创建用户,再赋予权限。
-
扩展授权。可以通过执行新授权来扩展授权。将权限扩展到employees_col_ro用户,以访问薪资(salaries)表中的薪水:
grant select(salary) on employees.salaries to 'employees_ro'@'%';。 -
创建SUPER用户。需要一个管理员账户来管理该服务器。ALL表示出了GRANT权限之外的所有权限。
create user 'dbadmin'@'%' identified with mysql_native_password by 'DB@adln';。赋予权限grant all on *.* to 'dbadmin'@'%';。 -
授予GRENT权限,用户拥有GRANT OPTION权限才能授予其他用户权限。可以将GRENT特权扩展到dbadmin超级用户:
grant grant option on *.* to 'dbadmin'@'%';,注意权限的全称为grant option。 -
总结:授予权限使用的关键字是
grant,必须指明权限能访问的数据库和表on 数据库.表,必须指明授权的对象to 用户。
-
-
检查权限
- 检查所有用户的授权。检查employee_col_ro用户的授权:
show grants for 'employee_col_ro'@'%';
- 检查所有用户的授权。检查employee_col_ro用户的授权:
-
撤销权限
-
撤销'company_write'@‘%’用户的DETELE访问权限:
revoke delete on company.* from 'company_write'@'%';。 -
撤销employee_ro用户对薪水列的访问权限:
revoke select(salary) on employees.salaries from 'employees_ro'@'%'。
-
-
修改mysql.user表
- 所有用户的信息以及权限都存储在mysql.user表中,如果你有权访问mysql.user表,则可以直接通过修改mysql.user表来创建用户并授予权限。
如果你使用GRANT、REVOKE、SET PASSWORD和RENAME USER等账户管理语句间接修改授权表,则服务器会通知这些更改,并立即再次将授权表加载到内存中。
如果使用的是INSERT、UPDATE或者DELETE等语句直接修改授权表,则更改不会影响权限检查,除非重新启动服务器或指示其重新加载表。如果直接更改授权表,当忘记了重新加载表,那么在重新启动服务器之前,这些更改无效。
可以使用查询语句进行查询mysql表,可看到某个用户的具体权限的信息,select * from mysql.user where user='dbadmin'/G,使用update即可对权限进行更新,update mysql.user set host='localhost' where user='dbadmin';。
因为是对mysql表进行操作的,所以想要立即生效,必须使用flush privileges;使其立即生效。
- 所有用户的信息以及权限都存储在mysql.user表中,如果你有权访问mysql.user表,则可以直接通过修改mysql.user表来创建用户并授予权限。
-
设置用户密码的有效期
- 可以设置一段时间作为用户密码的有效期,当有效期过后用户需要修改密码,创建的用户的密码过期日期等于
default_password_lifetime变量的值,默认情况下用户被禁用。 - 创建具有多起密码的用户。
create user 'developer'@'%' identified with mysql_native_password by 'xxx' password expire;此时登录后,若要使用的话,会提示ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement.。此时就需要手动修改密码,使用``
未完待续
- 可以设置一段时间作为用户密码的有效期,当有效期过后用户需要修改密码,创建的用户的密码过期日期等于
-
-
-
查询数据并保存到文件和表中
-
可以使用select into outfile语句将输出保存到文件中。可以指定列和行分隔符,然后将数据导入其他数据平台。
- 另存为文件
- 要将文件保存早文件中,需要拥有file权限。file是一个全局特权,意味着不能设置为针对特定数据库的权限,使用
grant file授权。
- 要将文件保存早文件中,需要拥有file权限。file是一个全局特权,意味着不能设置为针对特定数据库的权限,使用
- 另存为文件
-
未完待续
-
-
表关联
-
使用join来关联两个表,为了能够关联,要求两个表必须有一个或者多个共同列。
查询编号为110022的员工的姓名和部门编号:select emp.emp_no, emp.last_name, emp.first_name, dept.dept_name from employees as emp join dept_manager as dept_mgr on emp.emp_no=dept_mgr.emp_no and emp.emp_no=110022 join departments as dept on dept_mgr.dept_no=dept.dept_no;,其中使用了as对表名起别名,and emp.emp_no=110022的位置不固定。 -
查找每个部门的平均工资:
select dept_name, avg(salary) as avg_salary from salaries join dept_emp on salaries.emp_no=dept_emp.emp_no join departments on dept_emp.dept_no=departments.dept_no group by dept_emp.dept_no order by avg_salary desc; -
join与on一起使用,为
join 关联的表 on 关联的条件(为两个表共有的项) -
关联的用法二:通过与自己关联找出重复项,如查找具有相同的first_name、相同的last_name的项。在join中指定要查找的重复项的列。
- 需要为每个表设置别名 可以不用as,而在不影响语义的情况下直接写别名。
- 需要为用来做关联的列添加索引。
alter table employees add index name(first_name, last_name); - 查询语句为:
select emp1.* from employees emp1 join employees emp2 on emp1.first_name=emp2.first_name and emp1.last_name=emp2.last_name and emp1.gender=emp2.gender and emp1.hire_date=emp2.hire_date and emp1.emp_no!=emp2.emp_no order by first_name, last_name;注意要指明emp1.emp_no!=emp2.emp_no。语义上不难理解,就是将两个一样的表的数据放到了一起,然后去除了编号相同的项,这样剩下的就是重复的了,理解上就是把两个表按照emp1.first_name=emp2.first_name的要求进行拼接组合。
-
使用子查询:
-
即在一个查询中且套另一个查询语句,将另个查询的结果集用作此时查询的范围:
select first_name,last_name from employees where emp_no in (select emp_no from titles where title='Senior Engineer' and from_date='1986-06-26'); -
查找工资最高的员工:
select emp_no from salaries where salary=(select max(salary) from salaries);
-
-
查找表之间不匹配的行(两个表结构一样,只是数据不同),在一个表中找到其他表没有的行,两种方法not in子句或者使用outer join。
-
找匹配的行,普通的join,不匹配的行需要使用outer join。
-
以现有表的数据创建新的表:
create table employees_list1 as select * from employees where first_name like 'aa%';
可见结构类似,但是不继承原表的约束条件。关于使用现有表创建新表的几个方法:
- 使用as关键字
a. 使用现有表中的数据创建新的表,
create table employees_list1 as select * from employees where first_name like 'aa%';,这种方法创建的新表会使用原有表的结构以及选择的相应的数据,但是不继承原有表的约束条件以及索引。 b. 只使用旧表的结构不使用数据,create table employees_list3 as select * from employees where 1=2;,这样只会复制表结构但是没有任何数据。只用where后的条件为假即可。 - 使用like关键字,可以创建完整表结构和全部索引。
create table employees_list4 like employees;即可创建完全一样的新表。
注意:其中的as关键字可以不写。
- 使用as关键字
a. 使用现有表中的数据创建新的表,
-
查找两个表都存在的数据,可以使用where in (select子查询)的方法,也可以使用join:
select * from employees_list1 where emp_no in (select emp_no from employees_list2);或者select employees_list1.* from employees_list1 join employees_list2 on employees_list1.emp_no=employees_list2.emp_no;,对应的,要查找存在于list1而不在list2中的数据,使用select * from employees_list1 where emp_no not in (select emp_no from employees_list2);或者select l1.* from employees_list1 l1 left outer join employees_list2 l2 on l1.emp_no=l2.emp_no where l2.emp_no is null;。 -
left outer join为第二个表中所有与第一个表中的行不匹配的行创建为null列。
-
未完待续
-
-
-
存储过程
-
是一组sql语句,没有返回值。是将所有语句封装在单个程序中,并在需要的时候调用这个程序,而不是每次都要发送所有的sql语句
-
除了sql语句外,还可以使用变量来存储结果并在存储过程中执行程序化内容。例如使用if、case子句、逻辑操作和while循环。
存储的函数和过程都称为存储例程 要创建存储过程,需要有create routine权限 存储函数具有返回值 存储过程没有返回值 所有代码都在begin和end块之间 存储函数可以直接在select语句中进行调用 可以使用call语句调用存储过程 由于存储例程中的语句应以分隔符;结尾,因此必须更改MySQL的分隔符,以便MySQL不会用正常的解释存储例中中的SQL语句,创建过程结束后,可以将分隔符改回默认值。
-
-
查询语句
-
select ...(输出) from ...(获取数据) where ...(过滤) group by ...(分组) having ...(过滤) order by ...(排序) limit ...(限定个数) ;
-
执行的顺序:1.from 2.where 3.group by 4.select 5.having 6.order by 7.limit
-
group by: *
-