Replies: 17 comments 5 replies
-
|
Looks nice... is a c# version available? |
Beta Was this translation helpful? Give feedback.
-
|
Sadly no just Python, go and rust, no c# that I could find |
Beta Was this translation helpful? Give feedback.
-
|
OK, it's fairly easy to do this... it guess it comes down to two issues:
|
Beta Was this translation helpful? Give feedback.
-
|
Well after looking around some more I think I have found something better it even has c# versions |
Beta Was this translation helpful? Give feedback.
-
|
OK, an early test version is up now: https://github.com/SubtitleEdit/subtitleedit/releases/download/3.6.4/SubtitleEditBeta.zip
To activate this tool - press Ctrl+shift+alt+F12 in the main SE windows. Works in OCR or in Fix common errors: |

Beta Was this translation helpful? Give feedback.
-
|
So we can use the tool to generate word lists to improve the correction when we run ocr or fix common errors? |
Beta Was this translation helpful? Give feedback.
-
|
Yes - but this feature will require some testing + tuning... also, it's not using the |
Beta Was this translation helpful? Give feedback.
-
|
It works quite well already though its not perfect. To make it really accurate you would need to generate word lists for each language as well as word pair frequency etc by ingesting large amount of text for each language which is not really feasible. People being able to generate word list for languages they use will be good enough for most people. |
Beta Was this translation helpful? Give feedback.
-
|
The Seems to work okay, but I'll test more - and try adding "names" |
Beta Was this translation helpful? Give feedback.
-
|
Please test :) |
Beta Was this translation helpful? Give feedback.
-
|
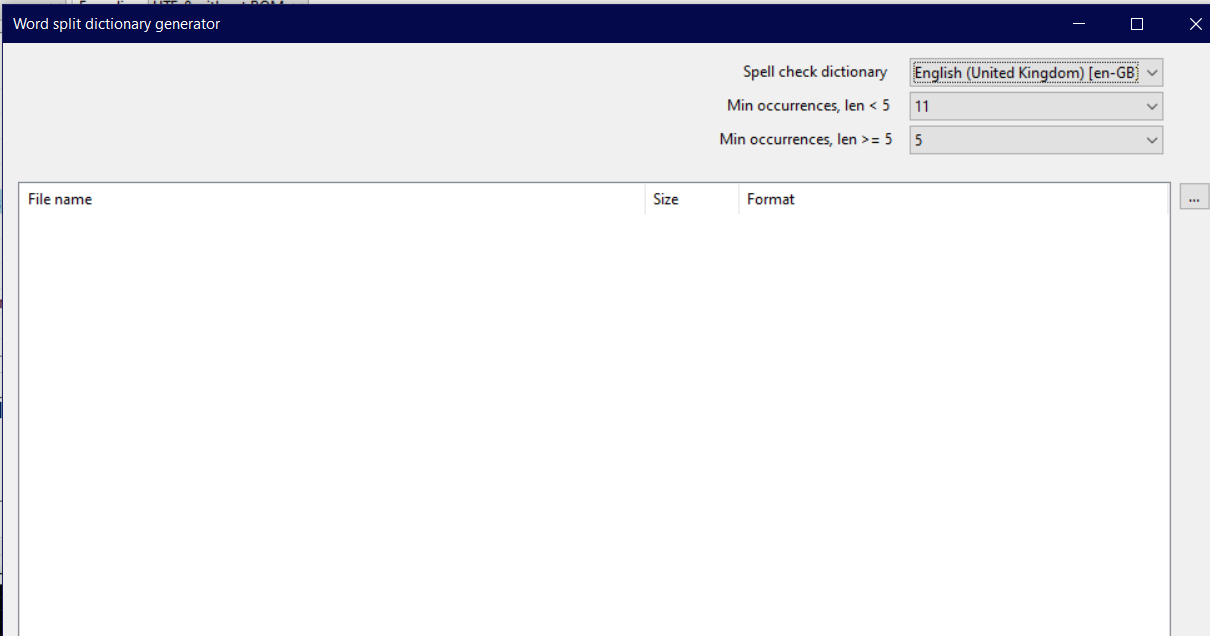
The split dictionary now is showing the actual dictionaries. I tried combining a few names does not seem to work |
Beta Was this translation helpful? Give feedback.
-
|
I need more details and concrete examples to check anything. The "Word split dictionary generator" is only for generating a new word-split-list. |
Beta Was this translation helpful? Give feedback.
-
|
ThisiscityofNanxing is the subtitle. Nanxing is the name included in the name list. It stays the same when run thorough the fix common OCR errors. When I change it to Thisiscityof Nanxing then the words gets separated out properly to This is city of Nanxing . After some testing the names are no longer being split up once added to the name list. But they are not separated out either so if a name is in a string of text contains a name it is not separated out. |
Beta Was this translation helpful? Give feedback.
-
|
After running the generator on 1000 srt files that I had the resulting wordsplit dictionary seems to work very well. A better curated word list I expect would give even better results. I have question as I no longer have access to the files that were giving me long string of text when using subtitle edit ocr. I am wondering is the wordsplit working before we get the ocr results as I am not getting similar long strings like previously |
Beta Was this translation helpful? Give feedback.
-
|
OK, names list is now sorted (by word length descending) into the word-split-list + spell check after split is improved to use name list, so Yes, the word-split-list is working in the OCR (fixes should be visible in logs/guesses). |
Beta Was this translation helpful? Give feedback.
-
|
I've improved the split word a bit: ignore workin' (and other *in' words) + include more words in the word split list + added some words to the English user dic. Also, not having words like "stepmom" or "badass" in the normal dictionaries gives some annoying results - so this works best if the spell checker is not missing too many informal words often used in dialog. https://github.com/SubtitleEdit/subtitleedit/releases/download/3.6.4/SubtitleEditBeta.zip |
Beta Was this translation helpful? Give feedback.
-
|
I think the last version is almost perfect with rare manual intervention required and that mostly for names only. There is one error I keep getting though I think it has to do with tesseract rather than the split word but just in case I am attaching the files. Sometime when the sentence starts with "I'm" the sentence seems to break down to single letters or double letters. I am attaching 3 files 2 where it happens 1 where it does not. Using tesseract 5 with original tesseract setting other settings disabled. For image preprocessing invert colors and crop transparent colors are used.
|



Beta Was this translation helpful? Give feedback.
-
|
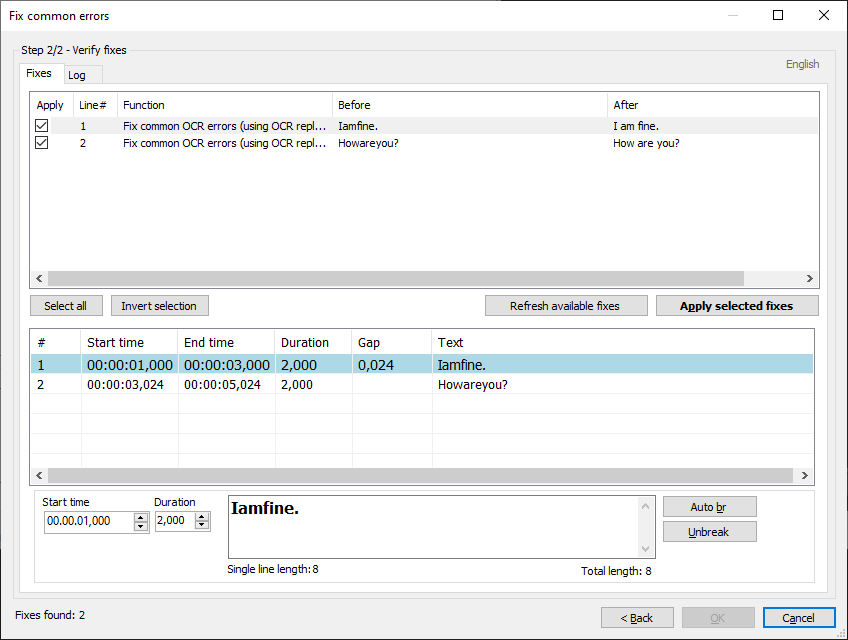
A huge thank you for this! Just tried it out and it worked beautifully. Saved hours of time. Just BTW, here's how your fix solved my problem: I had a set of subtitles for a TV series (a couple dozen .srt files). In every file there were many instances where two lines had been combined into one long line with no space between the two (I'm not sure if these were originally created with OCR, but somehow this error had been introduced). Example: I'm driving into town today and willattend a meeting at the new library. Should be: I'm driving into town today and will I was working my way (tediously) through each file, manually breaking the lines. I had the thought, "I wish there was some solution that could detect where the lines needed to be broken and do this for me. But, no, that's pie in the sky." However, I decided to do some googling and lo-and-behold, your amazing fix was just included in the latest release! I used these three steps:
And voilà! Worked like a charm. Thank you again for saving hours of dreary editing for me, but more importantly, for creating a tool that improves subtitle files and enhances the viewing experience for many, many people. :-) P.S. New member -- prompted to sign up so I could leave this "thank you." |
Beta Was this translation helpful? Give feedback.
-
|
Nice to hear your experience :) |
Beta Was this translation helpful? Give feedback.
-
|
Yes, it seems Tesseract has issues with this font (not related to word splitting) |
Beta Was this translation helpful? Give feedback.
-
|
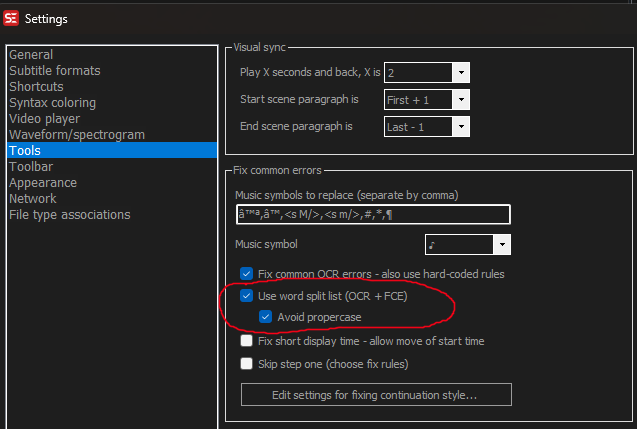
And this feature can be turned on/off in Settings.xml via the tag "OcrUseWordSplitList" |
Beta Was this translation helpful? Give feedback.
-
|
Or in UI - Options - Settings - Tools:
|
Beta Was this translation helpful? Give feedback.
-
A sometimes after ocr the text come out as long string of combined words. Using wordninja specially with subtitle edit dictionary where we have added the names etc should make it a lot easier to clean up the text. It could be part of the spell check or just another option to fix text.
https://github.com/jiawenhao2015/wordninja
Beta Was this translation helpful? Give feedback.
All reactions