FastSpeech2 training with MFA and Phoneme-based #107
Comments
|
@ZDisket see here https://github.com/TensorSpeech/TensorflowTTS/blob/master/examples/fastspeech2/train_fastspeech2.py#L116-L117. Loss f0/duration/energy is fine but loss mel-spectrogram missmatch length. I pretty sure that ur sum(duration) != len(mel), maybe just some samples or maybe all samples :D. Pls ref this comment (#46 (comment)) |
|
which duration value you use when training ground truth or predict? If you use gt duration then the only reason comes in my mind is that some sample has sum of duration different with length of Melspectrogram. You could use the following code to ignore outlined sample while loading data. Then filtering difference ids |
|
@l4zyf9x @dathudeptrai Thanks, I'll see how deep the problem goes. |
|
It seems that the length of the normalized mels is slightly higher than that of the sum of durations. |
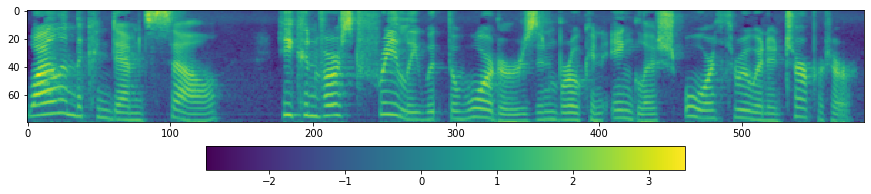
|
@abylouw do you have any thought ? .@ZDisket it seems the length missmatch too much, in my preprocess for F0/energy, i also padding or drop some last elements to make the length is equal but the mismatch is just 1 frame. cc: @azraelkuan |
|
@dathudeptrai I don't think it's too much when considering that these are phonetic durations. I'm considering just adding the difference to the last duration for every utterance, but I want to hear what you guys think about it first. |
|
@dathudeptrai I've gone ahead and it's training fine, the very first loss values look fine and predictions at 3000 steps.zip (very early) look normal. ming024 stated in his README.md that it only takes an hour of training on a GTX 1080 to start producing decent samples. |
|
@ZDisket let see, i don't know what is the proper way to solve the length missmatch is this case, hope the model don't have any problem at the end of the mel :D |
|
@ZDisket One question. Do you train Tacotron and extract duration with the same Mel that you use to train FastSpeech2? |
|
@l4zyf9x Those are extracted durations on ground truth LJSpeech audio from Montreal Forced Aligner. I didn't use a teacher model. |
|
As @dathudeptrai mention before. I think you should reference this comment #46 (comment). I think the solution is that you config MFA have the same time resolution. For example: frame_rate=16000, hop_length=256. So you need set rate of MFA = 1000 * 256 / 16000 = 16(ms). Finally, it will be possible to mismatch 1 to 2 frame, you just need pad or drop the last frame |
|
@l4zyf9x If that was the problem then it'd be much worse. I already took that into account for my second to frame conversion, taking it from here. |
|
Although with some problems, the model at 30k is capable of generating speech. Here's a notebook. |
|
@ZDisket the mel looks good at 30k steps, let training it around 150k steps and compared the performance. note that fastspeech2_v2 is small version |
|
@dathudeptrai Does the small version lower quality, or is it supposed to be the same or higher? |
|
@ZDisket need to tune :)). I think we can tune and find the smaller version without worse quality. Let see the performance after 150k steps. |
|
@ZDisket I just have look at your code and MFA documentation. Following your code, when config MFA, frame_shift should be 1000*256/22050~11.61. What is your MFA frame_shift |
|
@l4zyf9x My relevant code is: I didn't read that part of the documentation and since both ming024 and I are getting results, it's not necessary. |
|
Is we basically trim the first and last labels of the phones: where the |
|
@dathudeptrai After 110k steps, the performance is pretty bad, you can see samples in the notebook. I think I'll instead cut the mels at the time of data loading and train fastspeech2_v1. I also added training instructions here |
|
@ZDisket thanks, i will take a look, phoneme based should better than charactor fastspeech2 v1 here. I am review everything now then release first version. After that i will train phoneme, support multigpu/tpu ... |
|
@dathudeptrai Are you going to train the current version which adds the difference to the last duration? There are a few problems in the ends of the audio samples, although I suspect it could be just fastspeech2 v2 being bad. |
|
@dathudeptrai |
|
@Dicksonchin93 you can combine :)), i can't since i don't have enough disk space to train VCTK :v |
|
@dathudeptrai @ZDisket Do you guys have any idea on how to reduce the metallic effect to make it more natural? I'm looking in some manual audio processing to remove some of these metallic sounds |
|
@Dicksonchin93 If you can isolate the metallic noise to use as a noise profile then a conventional noise reduction filter (like the one found in Audacity) might be enough. Otherwise, try to train it more or with a better dataset, or train v1 which is heavier and higher quality if you're doing v2. |
|
can anyone help me write a correct code for phoneme_to_sequence id in https://github.com/TensorSpeech/TensorflowTTS/blob/master/tensorflow_tts/processor/ljspeech.py :(. I just want to train tacotron-2 with phoneme now :(. Here is my code :( |
|
@dathudeptrai I just take the phonetic equivalent of the transcription (I do it from the MFA output, you'll have to run G2P on it) and modify metadata.csv to have those wrapped between curly braces {AA1, ...} before doing any preprocessing steps. The LJSpeech preprocessor is capable of handling the rest. |
|
@ZDisket ok, i'm training with phoneme based on G2P now :D |
|
@dathudeptrai i have espeak based phoneme to sequence will it work ? |
|
@manmay-nakhashi i think G2P is faster than espeak :v. |
|
@dathudeptrai but less language support , i couldn't find anyway to load custom g2p model into python |
|
@manmay-nakhashi As you can see, every languages/datasets should have its own preprocessor.py. The important is not that G2p less language support, this is divide and conquer strategy. Almost each language have its own framework to convert charactor to phoneme, we don't need use general framework for this :v. In my point, interms of model implementation, more general is good. But interms of preprocessing code, more general -> less flexible :v, also less readable. |
|
@dathudeptrai you are right in term of flexibility but if we can make a system as a custom model for G2P based on user defined phoneme output then we can make both flexible and generic. |
|
@manmay-nakhashi yes, that is on my plan, make preprocessing stage as class based so user can inherit base_preprocessing class to implement their preprocessing class. As base_trainer here :D |
|
@dathudeptrai exactly that would make this framework more robust, and scalable |
|
@dathudeptrai thx |

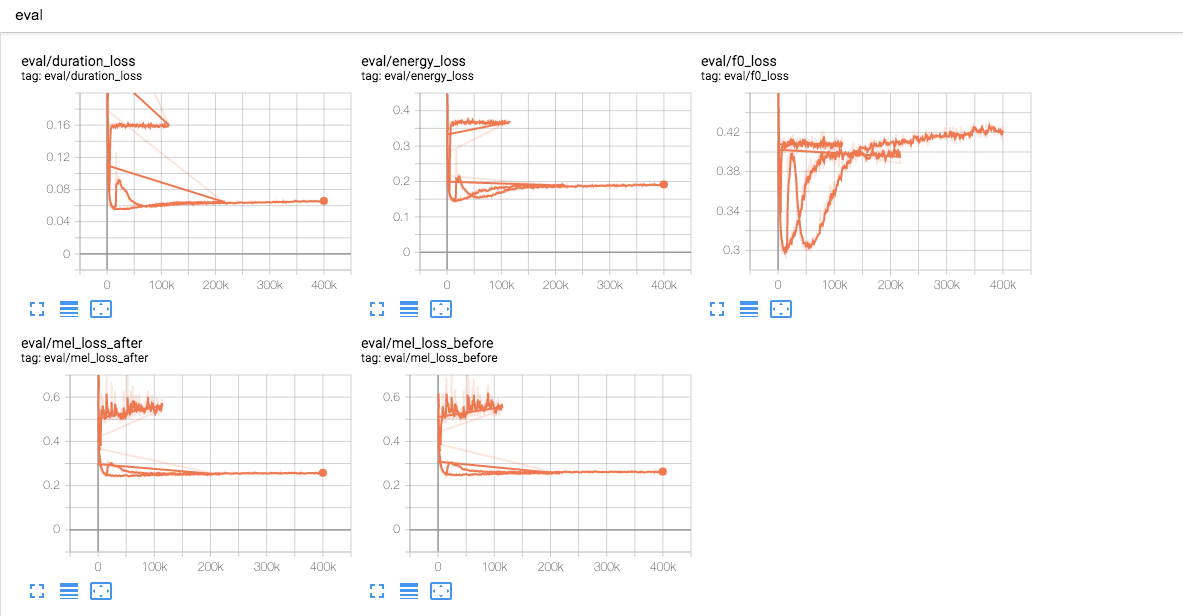
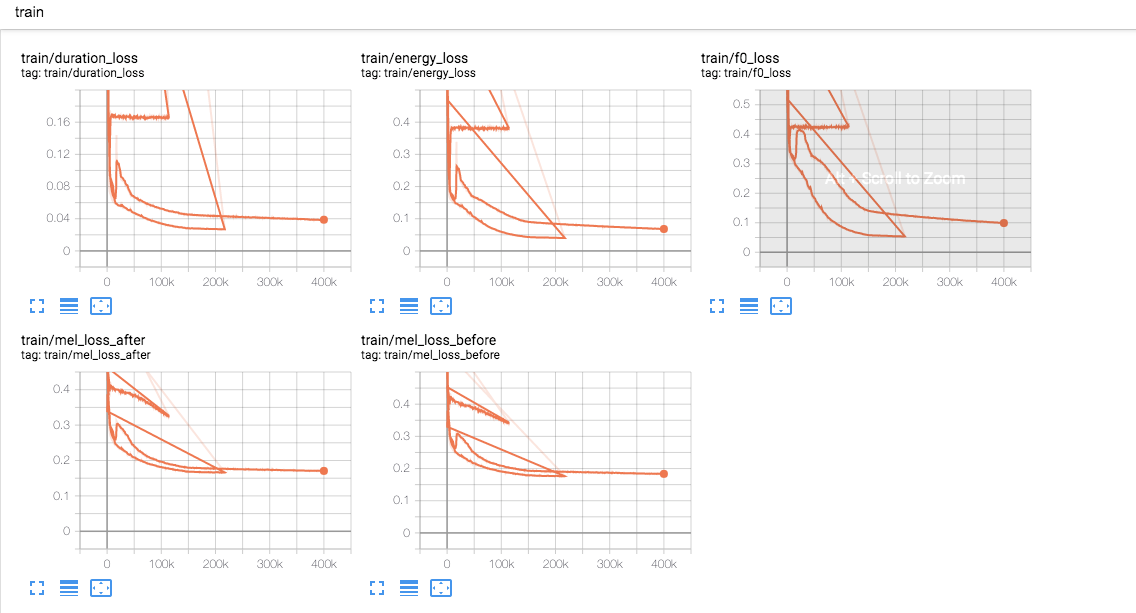
|
@janson91 everything ok., the mel looks good. GL is just to check the output is correct or not, it always generates bad audios. You should train vocoder such as mb-melgan |
|
@dathudeptrai |
|
@janson91 the batch_size in the config is for 1 gpu and it's 64. If you training with 8gpus, i suggest you training with batch_size = 8 or 16 :)). If you use batch_size = 64 that mean global_batch_size is 64 * 8 = 512 :))). Mb -Melgan need to be train around 1M steps with batch_size 64 :D. |
|
Ok thx @dathudeptrai |
|
@dathudeptrai hi, thx |

|
@janson91 the |
|
@dathudeptrai sampling_rate of two config is same. So are there other possible parameters that lead to incorrect result? |
|
@janson91 could you create a new issue ? and ofc, please give us ur preprocessing config and training config :D . |
|
fastspeech + MFA is supported in (https://github.com/TensorSpeech/TensorFlowTTS/tree/master/examples/fastspeech2_multispeaker). I will close this issue, thanks for all ur help :D |
@ dathudeptrai what's the progress of migrating fastspeech to TPU? |
i have to ask, i checked the phoneme conversions of MFA vs the g2p_en phoneme conversions, they do not match. I can see that the base processor in your repo used g2p_en. The MFA produces different phoneme to the same word also g2p_en preserves punctuation but MFA doesn't. can you comment on this? |
When training FastSpeech2 (fastspeech2_v2) with phonetic alignments extracted from MFA I get the error described:
I did everything I could think of to rule out my durations as the problem including verification that length is the same, so I don't know what happened.
Interestingly enough, when training with mixed_precision off the same error happens but with different values:
Am I missing something?
The text was updated successfully, but these errors were encountered: