Tacotron2: Everything become nan at 53k steps #125
Comments
|
hi @tekinek, i never get nan when training with Tacotron-2 but i can give you some suggests :)):
And also, let pull the newest code and run it with newst tensorflow version may help you solve the nan problem. I guess disble guided attention loss is the solution for nan problem, but let try :v. BTW, can you share ur alignment figure ? |
|
@dathudeptrai thanks for your quick reply. I will try loss_att * 0.0 if my current run gets nan again. Now it is at 51k. Here are some predicted alignments at 50k steps. Do they look fine? stopnet seems have long way to go, right? :)
|






|
@tekinek hmm, it's not as good as ljspeech and other datasets i tried before, the alignment is not strong but i hope it's still enough to get duration for fastspeech2 training with windown masking trick. There is something wrong in ur preprocessing, did you add stop symbols in the end of charactor_ids ?, did you lower all ur text and did you change english cleaner to ur target language cleaner ? |
It seems I haven't done that explicitly. Every sentence in the dataset ends with one of ".?!". or do you mean I should append
No, because in the transcript used in dataset, lower and upper cases of same letter represent different character (that is due to more than 26 letters in alphabet of my language).
Yes, I did. FYI: I have formatted my dataset into LJSpeech style including folder structure and metadata.csv. |
|
@dathudeptrai restarting from 50k seems solved the "nan" problem
|

|
@dathudeptrai where is |
|
@tekinek it is on generator function in tacotron_dataset.py |
|
By your suggestion, I got back to the dataset and prepossessing. Yes, there are some issues: long silences between words, and bad min/max freq level settings for mel-spec. I realize that inconsistent and long silences in between words are somehow common in my dataset. Sure, almost every utterance has long leading and trailing silence, but they should have been handled by My initial setting for mel-spec min/max freqs were 60-7600. But I found that 0-8000 is much better by doing: Now, I can see alignment is becoming stronger, but model still fails to stop at right location in most cases. What might be other reasons? thanks! (blue one is a fresh run on newly cleaned data)
|














|
@tekinek it seem ok, the alignment is strong enough to extract duration for fastspeech. For stop token, I think the reason is that you don't add the stop_token to the end of sentence. And in you might need to train it to 100k to be able inference without teacher forcing :D. |
|
@dathudeptrai thanks for your quick response.
How should I interpret this sentence? Should I manually append stop_token "_" to each sentence in my dataset before prepossessing? I see this happening as default behavior in tacotron_dataset.py (not in inference time?) |
|
@tekinek in inference time you should add eos token as tacotron2_dataset does :d |
|
@dathudeptrai I got it, thanks. |
|
@dathudeptrai Sorry, wait a minute. The above figures are taken from predictions folder generated by |
|
@tekinek the yellow line you see is padding, everything is fine :))) |
|
Hi @dathudeptrai, Here is learning curve and some mels from fs2:
How these figures look to your eyes? what is wrong with energy and f0 losses?
Thanks! |






|
@tekinek a mel for fastspeech2 very good i think. You need to train mb melgan to get better audio. GL always noise. |
|
Hi @dathudeptrai , [train]: 0%| | 0/4000000 [00:00<?, ?it/s] Traceback (most recent call last): |
|
@tekinek are u using newest code ? If no let try newest code then i can easily debug |
|
@dathudeptrai Yes, it was an older code base. But updating to the newest introduced new error. It seems your recent update to the |
|
@tekinek let replace generator_params to multiband_generator_params |
|
@dathudeptrai i'll send you tensorboard image shortly |
|
before clipping after clipping at 5 and applying tanh , it fixes the issue i guess :)) |


|
@tekinek what is ur upper bound value :))). @manmay-nakhashi 5.0 is magic number haha :)) i guess 4.0 is a best number :v. |
|
@dathudeptrai haha i'll try it with 4.0 :P |
|
@dathudeptrai i was looking into discriminator loss and it doesn't have real vs fake loss in master branch is it needed ? |
|
@manmay-nakhashi so for now, everything is still ok ?. I think we should apply sigmoid function for discriminator :))). Can you try apply sigmoid for the last convolution ? here (https://github.com/TensorSpeech/TensorFlowTTS/blob/master/tensorflow_tts/models/melgan.py#L411-L416). Then retrain and report the training progress here ? |
|
@dathudeptrai generator trained properly till 200k steps once i start discriminator it becomes unstable after 5k steps |
|
@dathudeptrai it's been 20k steps and traning is mimicking english graph pattern so i am hoping it'll converge better after sometime. i'll post tensorboard after 50k training steps |
|
opps here:( My mb-melgan training still seems problematic. Mine was 10.0 clip for stft losses and tanh to synthesis output. Should I try 4.0, and is resuming from 200k fine?
|


|
@tekinek what is ur discriminator parameter? |
|
@dathudeptrai i have tried sigmoid function , but as discriminator starts it starts adding beep to the waveform , then i replaced it with swish and it started working for me but there is an edge effect in the audio "straight spikes" , i think can be handled with padding or filtering (or may be it'll go away as model converges ) |
|
@dathudeptrai I haven't touch the defaults. |
|
@tekinek there is no problem about stft loss in ur tensorboard. The problem is about discriminator :D. Let check ur current code and this line (https://github.com/TensorSpeech/TensorFlowTTS/blob/master/tensorflow_tts/models/melgan.py#L379-L380). |
|
@dathudeptrai have you encountered edge effects in initial discriminator training ? |
|
It is like this: A quick debug shows values of all that downsample_scales are 4. |
|
@tekinek what is a number of parameter on ur discriminator ?. All downsample_sacles are 4 is correct. |
|
@dathudeptrai Parameter number of discriminator is 3,981,507 |
|
FYI: this pytorch implementation of mb-melgan worked before with the same dataset. TensorFlowTTS/tensorflow_tts/models/melgan.py Lines 379 to 380 in 7d9e497 |
that is totally wrong somehow, the correct parameter is > 16M. That is why ur discrimiator loss convergence at 0.25 :)). everything is ok :)). |
|
@dathudeptrai I see. Then what causes such a big difference in #of params under default settings? |
|
@tekinek sorry. it should be: Let me check the private framework again :)). |
Something is weird here. I ran into the same problem, and I notice that y_mb_hat become either 1 or -1. Once it's in that state, masking loss wouldn't help. |
|
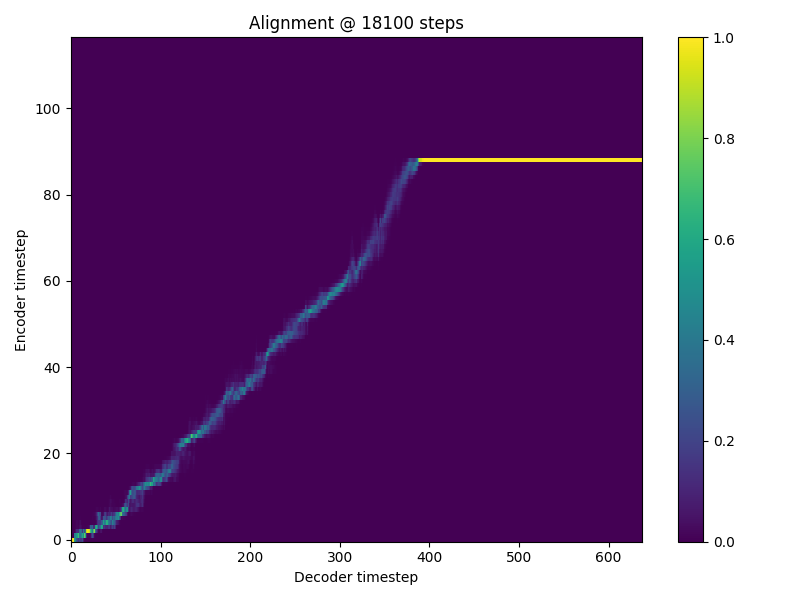
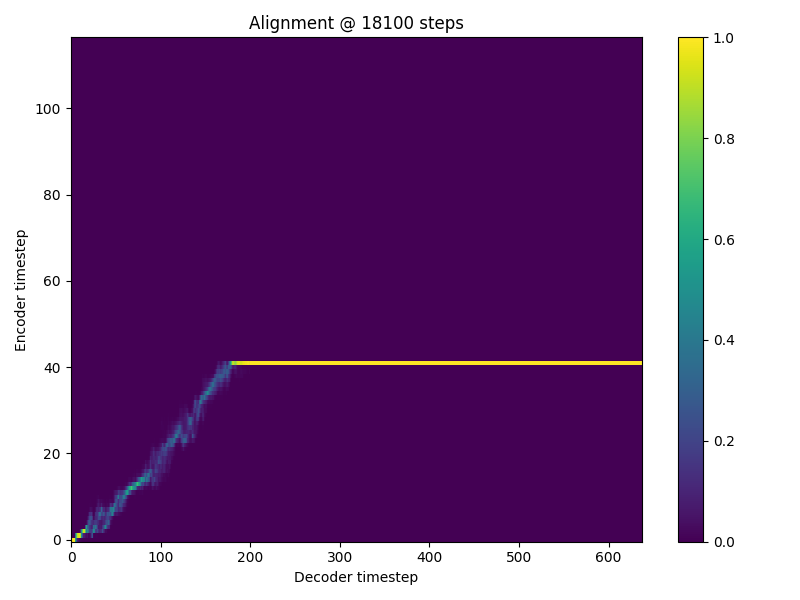
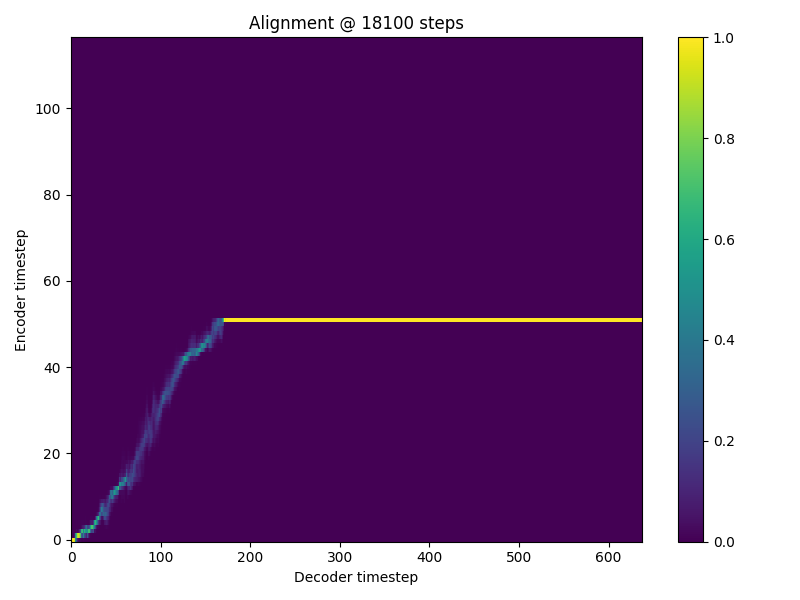
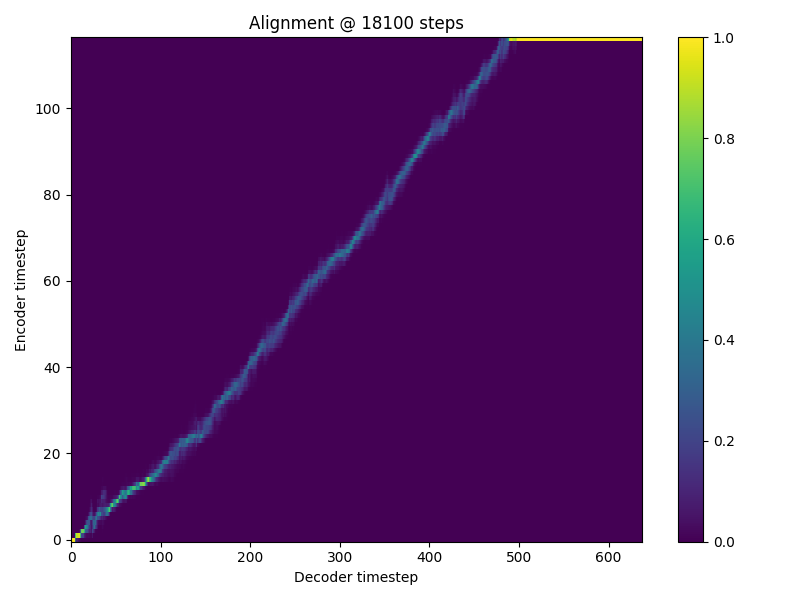
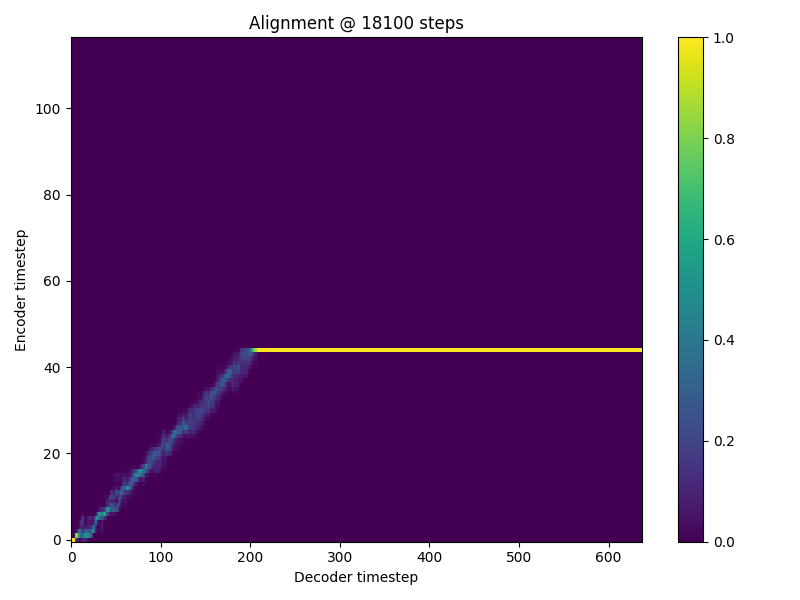
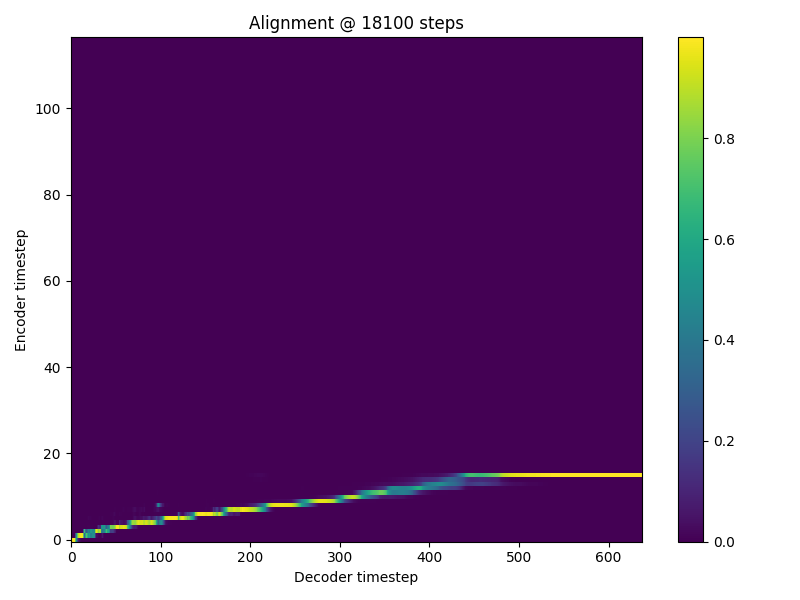
Hi there, I am getting the NaN problem when training my Tacotron2. it occurs between 18.1k and 18.2k iterations. 18,100 itr
18,200 itr
I have tried setting loss_att * 0.0 but still occurs. I am training on my own dataset which is much smaller than ljspeech but is still english. I use the ljspeech preprocessor. Any idea what is causing this? |





|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. |
|
I am experiencing this issue when training non english data set. I have about 1 hour audio with text to test this model and after 18k steps, i see the mel_loss gets to nan and won't recover. I tried seting attention loss as suggested by multiplying it to 0 like below. I realize that the data set I have might be too small but all I was hopping to aquire more data set if I got a small light of success that this is working. I created preprocessors and modifications for this datasource based on the existing samples but I am not certain if I am doing this right. My changes are in this fork https://github.com/bemnet4u/TensorFlowTTS @dathudeptrai or @GavinStein1 any advice on how to overcome this?
More training logs |

Hi, I am not that experienced in TTS, so I've faced many problem before get the code running with my non-English dataset which has about 10k sentences (~26h long) . However, still some issues and questions.
So I stopped training and resumed from 50k; I will wait until 53.5k and see if it happens again.
By the way, do my figures look fine? looks like model is overfitting; should I wait for a "surprise"?
My language is somehow under-resourced and there is no (at least I couldn't find one) phoneme dictionary to train a G2P and MFA model. However, unlike English, a character roughly represents a phone, except some vowels sound longer or shorter according to meaning of host word. So character-based model seems fine with me. This tacotron2 has been trained just for duration extraction.
Which step seems best for duration extraction so far?
How can I improve the quality of duration extraction?
extract_duration.py extracts durations from model prediction but they are supposed to be used with ground-truth mels. Although, the sum of tactron2-extracted durations is forced to match the length of ground-truth mels by
alignment = alignment[:real_char_length, :real_mel_length], this is just based on an assumption that predicted mels and their ground-truth counterparts are roughly one-to-one (from index 0).So, when the goal of training a tactron2 is to extract good duration only, is it a good idea to use whole dataset for training and make a severely over-fitted model (maybe up to 200k steps or more in my case)?
Any idea on MFA model training for a language with no phone dictionary available?
Has anyone tried making a fake phone dictionary like this to force MFA align character instead of phoneme.
....
hello h e l l o
nice n i c e
....
Thanks.
The text was updated successfully, but these errors were encountered: