Pretrained fastspeech2 libritts model for testing? #325
Comments
|
@ronggong I don't have enough resource to training libriTTS, i hope someone can try and make a pull request :D |
|
@dathudeptrai Hi, do you have an estimation about how much resource is needed in terms of GPUs and duration? |
with 2080TI, you can finish training fastspeech2 around 8 hours :D |
|
@dathudeptrai I tried with 2 gpus training with batch_size 16, which is slower than using 1 gpu with the same batch_size. Both gpus are consumed with the same amount of memory. Does the batch_size in the yaml means those for each gpu, so the actual batch_size is 32? |
yes :)). see here (https://github.com/TensorSpeech/TensorFlowTTS/tree/master/examples/fastspeech2#step-2-training-from-scratch). |
|
@dathudeptrai thanks! Here is an error in training. The error is in around here Why do we shift the enumerate counter to start from 1? |
|
@dathudeptrai @ZDisket I finished the libritts model training, however, I am still using the LJspeech multiband melgan vocoder. Also tried the vocoder of TuckerCarlson in TensorVox demo. None of them sounds good to me. Do you have a good vocoder to use? I found the multiband_melgan.v1_24k is somehow interesting, but it's trained with 2048 FFT and 300 hopsize, although the sampling rate is 24k, which corresponds well to the libritts training data. |
|
@ronggong The vocoder of Tucker Carlson is the |
|
@ZDisket Your Tucker Carlson model sounds much better than my libritts model on the same vocoder? Is your Tucker fastspeech2 model trained with data of 2048 FFT and 300 hopsize? My assumption the mismatch of the FFT and hopsize is the issue. |
Yes. First I upsampled LJSpeech to 24KHz and trained on the same config then took my 24KHz Tucker Carlson data and finetuned the 24-LJSpeech model. |
|
@ZDisket ok, I will retrain my libritts on this config. |
|
trim_silence: false # Whether to trim the start and end of silence. @ZDisket I am curious that you set trim silence and trim mfa both to false. Does this work better than setting to true. Btw, what does it mean trim_mfa, trimming the alignment results? |
|
@ronggong MFA trimming trims based on forced alignment results, and I turned both trims off because I found that MFA-aligned FS2 performs better without trimming (as the audio would end too abruptly), and due to the nature of my data collection scripts, most of my datasets already come pre-trimmed. |
|
@ZDisket The Libritts voice sounds a lot better now with FFT 2048 in preprocess, which correspond to the vocoder FFT size. However, the phrase ends very abruptly as you mentioned. I already disabled trim_silence and trim_mfa in preprocess. Do you have an idea why? This part is confusing to me https://github.com/ZDisket/TensorflowTTS/blob/e2660d50dd6baf43e83e0534e2595b95cf0e507d/examples/fastspeech2/mfa/postmfa.py#L135 |
|
@ronggong My script, which is entirely separate from the current MFA stuff, loads the sound file and exports trimmed WAVs, although I think there's a flaw with it.
Add SIL to the end of your input. I think the current inference only adds |
|
@ZDisket I added SIL and END, but it still ends abruptly. I probably will check the MFA alignment to see if the last phoneme is usually well aligned. Or another guess is when generating the data, maybe we didn't put the END at the end of a sentence as a label to differentiate the phoneme at the end from those in the middle of a sentence. |
yes :D |
|
Is there a way to workaround the warmup? If not, the way is to preload the model and do an dummy inference. |
|
@ZDisket It seems that keep punctuations and adding silence after that can mitigate the abrupt ending problem. I am not sure if the punctuation is used as phonemes in training, will check. |
|
@ronggong yeah :D i'm interested with ur libriTTS demo :D. |
|
@ronggong If u used preprocessing based on multispeaker there is a part of trimming END and SIL from the end based on MFA alignment and in my case models was working a lot better with trimmed based on both END and SIL token in the end of the sentence. Also it wasnt trimmed on librosa but only based on MFA phonmes :) If u use this trimming in inference time you should also remove SIL and END from the end of the sentence and the problem with abruptly ending sentence wasn't case in this configuration on Libri + my dataset. |
|
@machineko ok, thanks for the tips, let me try another trimmed version. |
|
@ronggong Also this => #296 (comment) |
|
I made the changes mentioned earlier in this thread and my model performs way better, and the end of the speech is not cut off after adding SIL and END to the end of my input ids :) |
|
For those training FS2 on LibriTTS, I tried switching my LibriTTS subset from My speaker selection involved picking the 100 speakers with the most speech from the subset. In I think perhaps adding speakers with small amounts of data (<20 mins) does not help the model. |
|
@dathudeptrai Here is the colab notebook with pretrained Libritts train-clean-100 data Fastspeech2 model. Any suggestions? https://colab.research.google.com/drive/1K-4KxwUGaElMxcLzbFXX1oGAaAJXROpf?usp=sharing |
|
@machineko @OscarVanL Where there is no SIL and END (1), the phrase ends abruptly. In case (2), the last vowel prolonged. In case (3), a vowel-like sound is added at the end. In case (4), a short pause is added to the end. This is only one example, can't generalize to other examples.
Then, model trained with non-trimmed data,
So for me, with either trimmed or non trimmed data, add SIL at the end is helpful. |

|
Yes, this is what I have been doing, I add SIL and END to the end of every speech :) Thank you for making a comparison so I know this is the right approach. |
|
@OscarVanL I am not sure if adding END make sense. If we use trim MFA, the text id of both SIL and END are also trimmed in the training text I suppose Which might means in training, the model probably never seen END symbol. |
|
Interesting, maybe the END is unnecessary then, but there is clearly a difference in your charts 2 and 3, so END must be doing something? |
|
@OscarVanL In the example, it adds some vowel-like noise. |
|
@ronggong MFA replacing punctuations before training has side effects. Like question marks don't make the sentence sound like a question anymore. Would somehow putting the punctuations back post MFA alignment make sense ? |
|
@aragorntheking I think you are right, the punctuations have been removed from the MFA alignment and as well from the training labels, as the labels are generated from the MFA alignment. I think it's worth to investigate the effect of putting the punctuations back. |
|
@aragorntheking I am going to have to time to investigate the punctuation of the MFA alignment. Do you want to collaborate on this? |
|
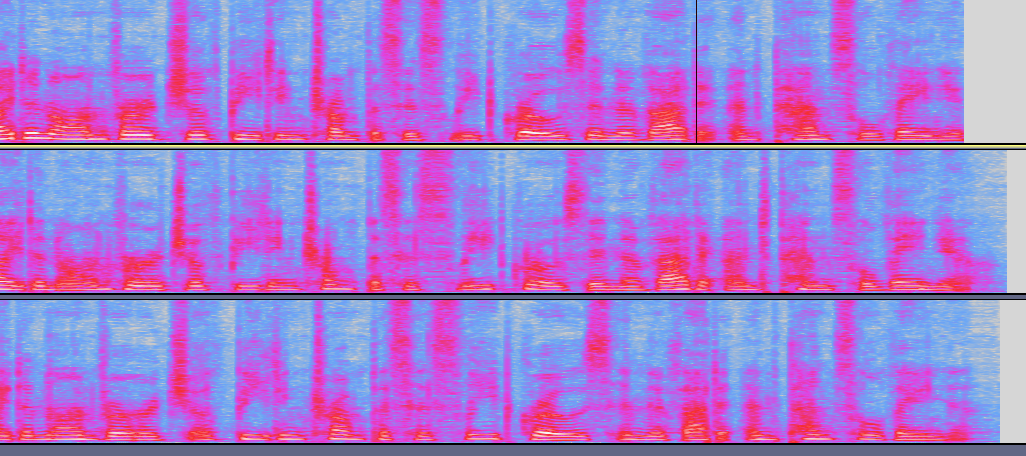
@OscarVanL @aragorntheking Adding back the punctuations to the transcriptions to train has an effect, although minor. We can hear the pitch change:
Below are the spectrogram of three sentences, pay attention to the ending pitch.
Audio examples |

|
@dathudeptrai Just reminder, the pretrained multispeaker libritts fastspeech2 colab is here https://colab.research.google.com/drive/1K-4KxwUGaElMxcLzbFXX1oGAaAJXROpf?usp=sharing if we want to share with others. |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. |
@ronggong where do you add the punctuations? do you change the MFA alignments or change the MFA to remain the punctuations? can you explain clearly what you do to solve this problem? |
Hi,
Thanks for the nice work. Is there a pretrained fastspeech2 libritts model for testing? Like the one trained with ljspeech data?https://colab.research.google.com/drive/1akxtrLZHKuMiQup00tzO2olCaN-y3KiD?usp=sharing
The text was updated successfully, but these errors were encountered: