# 递归转换当前路径下所有文件编码为UTF-8
convmv -f gbk -t utf-8 -r --notest ./*
man ascii
# 设置时间
datetimectl -h
# 半连接队列默认大小,syn
sysctl -a | grep 'tcp_max_syn_backlog'
# 全连接队列,accept
ssl -tnl
# 创建多个文件夹
mkdir /data/nginx/{ip,domain,port}
# linux后台运行进程
command &
nohup command
# 标准错误重定向到标准输出,标准输出重定向到test.log,&挂在到root进程
nohup java -Xms1024m -Xmx1024m -Xmn384m -jar test.jar > test.log 2>&1 &
# 查看yum源
ls /etc/yum.repos.d
yum repolist
# 关闭selinux,重启生效
vim /etc/sysconfig/selinux
# 本次关闭selinux
setenforce 0
# 网络相关
ss -tnl
netstat -nlpt
ps -ef | grep nginx
# 网卡能识别的ip
hostname -i
# 复制到另一台主机
scp -r /test/test.log root@192.168.1.106:/test/test.log设置 rsyslogd 和 systemd-journald
# centos7日志系统为 journald
mkdir /var/log/journal
mkdir /etc/systemd/journald.conf.d
cat > /etc/systemd/journal.confg.d/99-prophet.conf << EOF
[Journal]
# 持久化保存到磁盘
Storage=persistent
# 压缩历史日志
Compress=yes
SyncIntervalSec=8m
RateLimitInterval=45s
RateLimitBurst=1200
# 最大占用空间
SystemMaxUse=10G
# 单日志最大
SystemMaxFileSize=200M
# 日志保存时间
MaxRetentionSec=2week
# 不把日志转发到syslog
ForwardToSyslog=no
EOF
####################################
systemctl restart systemd-journald# cpu核信息
lscps
# 查看每个cpu核信息
cat /proc/cpuinfo
# 进程运行状态
# load average表示系统1m、5m、15m系统负载情况
top
# 查看系统负载
uptime
# -d高亮
watch -d uptime
# 一般来说,系统平均负载升高意味CPU使用率上升,但它们没有必然联系
# I/O密集、很多进程处于不可中断也会导致负载升高,但cpu的利用率不高,此时应该考虑I/O读写
#stress 是一个系统压测工具
yum install stress
# --cpu 8: 8个进程不停执行sqrt()
# -- io 4: 4个进程不停执行sync()io操作(刷盘,讲数据从buffer刷新到磁盘)
# --vm 2: 2个进程不停执行malloc()内存申请
# --vm-bytes 128M: 限制每次malloc()申请内存大小
stress --cpu 8 --io 4 --vm 2 --vm-bytes 128M --timeout 10s# 使用stress -c 1模拟cpu高负载
stress -c 1
watch -d uptime
# mpstat查看每秒cpu每核变化信息,同top
mpstat -P ALL 1
# 每隔1s输出当前OS进程、cpu数据
pidstat -u 1
# stress -i 1来模拟I/O瓶颈,即死循环执行sync()刷盘
stress -i 1
watch -d uptime
# 虚拟机buffer较小可能看不出问题,使用stress-ng
# hdd 代表读写临时文件
stress-ng -i 1 -hdd 1 --timeout 600# 模拟24进程
stress -c 24
watch -d uptime
mpstat -P ALL 1
pidstat -u 1CPU上下文:CPU执行每个任务都需要知道任务从哪加载、从哪开始运行。PC和CPU寄存器被称为CPU上下文
CPU上下文切换有三种类型:
- 进程上下文切换
不同进程的线程切换:首先中断切换到核心态,替换PCB信息、虚拟内存、再切换回用户态
一般需要几十纳秒 ~ 几微妙
- 线程上下文切换
同一进程的线程切换,只需要替换私有数据比如栈和寄存器
- 中断上下文切换
打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件
# vmstat查看系统内存,cpu上下文切换,中断次数
# 每秒输出
# cs:每秒切换次数
# in:每秒中断次数
# r:就绪队列长度,正在运行或等待CPU的进程
# b:不可中断水淼状态的进程数
vmstat 1
# pidstat -w查看具体进程上下文切换次数
# cswch/s自愿上下文切换(无法获取所需资源导致切换,比如I/O,内存不足)
# nvcswch/s 非自愿上下文切换(CPU时间片已到)
pidstat -w -p 1366 1
# sysbench工具模拟上下文切换问题
sysbench --threads=64 --max-time=300 threads run
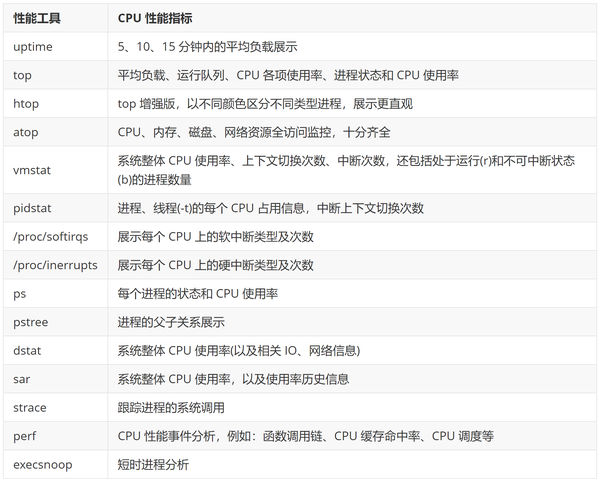
- 基本优化:程序逻辑的优化比如减少循环次数、减少内存分配,减少递归等等。
- 编译器优化:开启编译器优化选项例如
gcc -O2对程序代码优化。 - 算法优化:降低算法复杂度,例如使用
nlogn的排序算法,使用logn的查找算法等。 - 异步处理:例如把轮询改为通知方式
- 多线程代替多进程:某些场景下多线程可以代替多进程,因为上下文切换成本较低
- 缓存:包括多级缓存的使用(略)加快数据访问
- CPU 绑定:绑定到一个或多个 CPU 上,可以提高 CPU 缓存命中率,减少跨 CPU 调度带来的上下文切换问题
- CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。
- 优先级调整:使用 nice 调整进程的优先级,适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用得到优先处理。
- 为进程设置资源限制:使用 Linux cgroups 来设置进程的 CPU 使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源。
- NUMA 优化:支持 NUMA 的处理器会被划分为多个 Node,每个 Node 有本地的内存空间,这样 CPU 可以直接访问本地空间内存。
- 中断负载均衡:无论是软中断还是硬中断,它们的中断处理程序都可能会耗费大量的 CPU。开启 irqbalance 服务或者配置 smp_affinity,就可以把中断处理过程自动负载均衡到多个 CPU 上。
###############################
# Kernel相关命令与参数
###############################
# 内核版本
uname -r