RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn #498
Comments
|
Hi @superctj I have not yet been able to reproduce the issue based on the traceback posted above. Could you please post a short code snippet that produces the issue? |
|
Hi @beat-buesser Thank you for your quick response. Here is a screenshot of my code |

|
Hi @superctj I have run this script similar to yours but without a data loader and it works: Could you please try to run your script with (adding |
|
Hi @beat-buesser Thank you for your suggestion. Unfortunately, it doesn't fix the error. Could you please try to replicate the error by using a PyTorch data loader? |
|
Hi @superctj The script below seems to work with a How do you define your data loader? |
|
I have tried to debug this myself but haven't got any luck. I thought the issue was related to the gradient attribute, the tensor type, or the axis order but none of them helps. Basically, I have a custom dataset instance and wrap it with the PyTorch data loader. Do you have any ideas? I attach the data loader code for your reference.
|


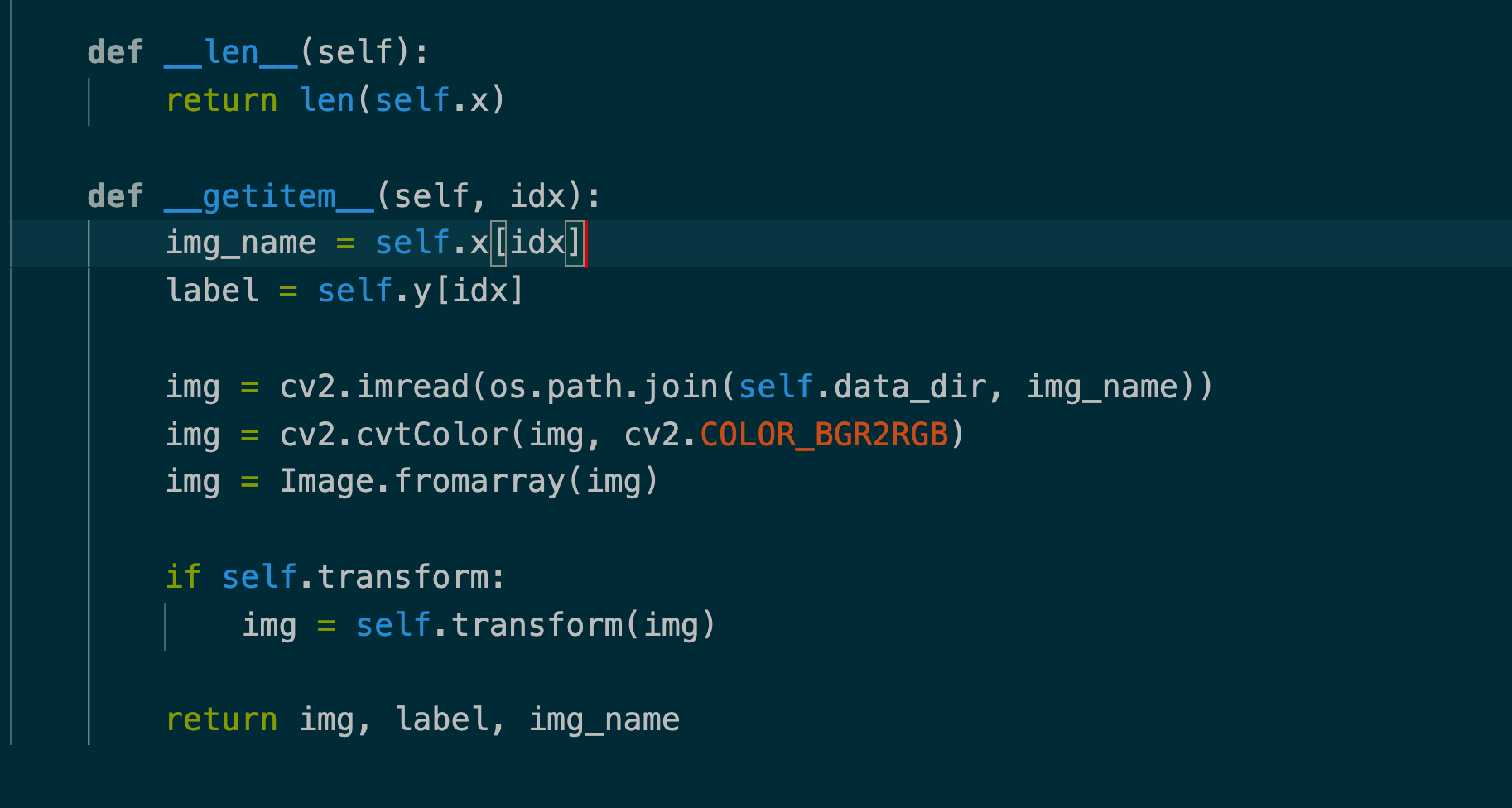
|
Does the error occur for the first or last batch? |
|
What is the type of the elements in |
|
|
How do you define your model? Can you also show the output of a forward pass with your model e.g. the output of |
|
I load a pre-trained model and wrap it into an ART PyTorch classifier. The output of
|

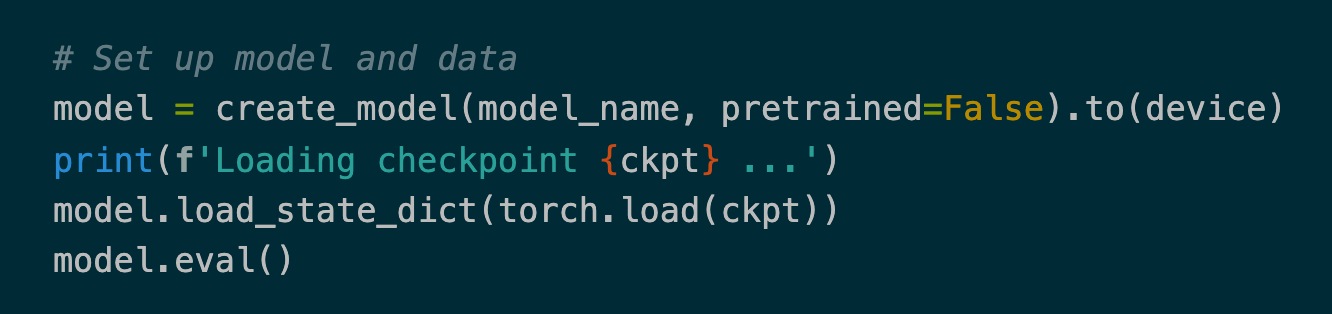

|
Could you replicate the error if you set |
|
|
|
Nah. I just thought it could be the difference between your and my code. Are you saying that you can reproduce the error outside the |
|
No, unfortunately not, it's just that |
|
Another debugging approach could be to test the your script by running the line |
|
Unfortunately, the error persists when I run on CPU only. Could it be a problem with PyTorch? I am using PyTorch 1.4.0. |
|
It should not, I have also been using PyTorch 1.4.0. |
|
Cool, the error doesn't show up if I create |
|
Can you print the type and content of |
|
|

|
I think I found the bug, in your first script above a line has a typo: A second question: Is it correct that all the labels are 0 for this batch? |
|
That was a typo. I found that as well yesterday but it didn't fix the error lol. Yeah, I didn't shuffle the test set so it starts with images from label 0. |
|
Hi @beat-buesser. I create a minimal example to reproduce the error. Could you please take a look and see if you can reproduce the error? |
|
With the help of my labmate, we found the problem was with |
|
Hi @superctj Thank you very much for the minimal example, that's great! Do you mean the |
|
Yeah, after removing that line, I can run the PGD attack smoothly. |
|
Ok, that makes sense, great catch, I hadn't noticed it. White-box attacks like It is very likely possible that black-box attacks, like |
|
That's good to know! Thank you very much for your time and patience. I appreciate it. |
Describe the bug
I encountered the error "RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn" when generating adversarial examples using AutoProjectedGradientDescent. It looks like input tensors do not have 'requires_grad' set to True when the loss is backpropagated.
To Reproduce
Steps to reproduce the behavior:
Expected behavior
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
Screenshots

System information (please complete the following information):
The text was updated successfully, but these errors were encountered: