[TOC]
这是一份来自深圳市政府数据开放平台的深圳通刷卡数据,时间区间为 2018-08-31 到 2018-09-01,总计 1,337,000 条记录,大小为 335 M,包含 11 个字段。
深圳通是由深圳市运输局监制、深圳市公共交通结算管理中心发行的一款即可优惠乘坐深圳市公交车,深圳地铁和商店消费的一种储值卡。
源数据存的是 json 格式的数据,先使用 python 对数据做一下清洗,然后保存为 csv 数据文件。
### 解析 json 数据文件
path = r"C:\Users\Administrator\Desktop\2018record3.jsons"
data = []
with open(path, 'r', encoding='utf-8') as f:
for line in f.readlines():
data += json.loads(line)['data']
data = pd.DataFrame(data)
columns = ['card_no', 'deal_date', 'deal_type', 'deal_money', 'deal_value', 'equ_no', 'company_name', 'station', 'car_no', 'conn_mark', 'close_date']
data = data[columns] # 调整字段顺序
data.info()
### 输出处理
# 全部都是 交通运输 的刷卡数据
print(data['company_name'].unique())
# 删除重复值
# print(data[data.duplicated()])
data.drop_duplicates(inplace=True)
data.reset_index(drop=True, inplace=True)
# 缺失值
# 只有线路站点和车牌号两个字段存在为空,不做处理
# print(data.isnull().sum())
# 去掉脏数据
data = data[data['deal_date'] > '2018-08-31']
### 数据保存
print(data.info)
# 数据保存为 csv
data.to_csv('SZTcard.csv', index=False, header=None)把清洗好的数据文件上传到 hdfs ,然后加载到 impala,后续就可以直接用 impala 进行数据分析。
与 hive 不同,impala 不支持加载本地数据文件,只能加载 hdfs 数据文件,所以需要先把数据文件上传到 hdfs。
# csv 上传到 hdfs
hdfs dfs -put SZTcard.csv /tmp/-- 建表
CREATE TABLE `sztcard`(
`card_no` string COMMENT '卡号',
`deal_date` string COMMENT '交易日期时间',
`deal_type` string COMMENT '交易类型',
`deal_money` float COMMENT '交易金额',
`deal_value` float COMMENT '交易值',
`equ_no` string COMMENT '设备编码',
`company_name` string COMMENT '公司名称',
`station` string COMMENT '线路站点',
`car_no` string COMMENT '车牌号',
`conn_mark` string COMMENT '联程标记',
`close_date` string COMMENT '结算日期'
)
row format delimited
fields terminated by ','
lines terminated by '\n';
-- 加载数据
LOAD DATA INPATH '/tmp/SZTcard.csv' OVERWRITE INTO TABLE sztcard;数据加载完成后,查看一下数据情况,发现有两个金额字段,但是没有给出数值单位。通过红色框框出来的这个旅途(卡号AEAAAACHG ,草铺>>少年宫),到网上 搜一下 ,可以看到票价是 4 元,可见这两个字段都是单位都是 分。并且,deal_value 就是票价,而 deal_money 就是实际的消费金额,所以本次是半价,结合目的地,AEAAAACHG 可能是一张学生卡。
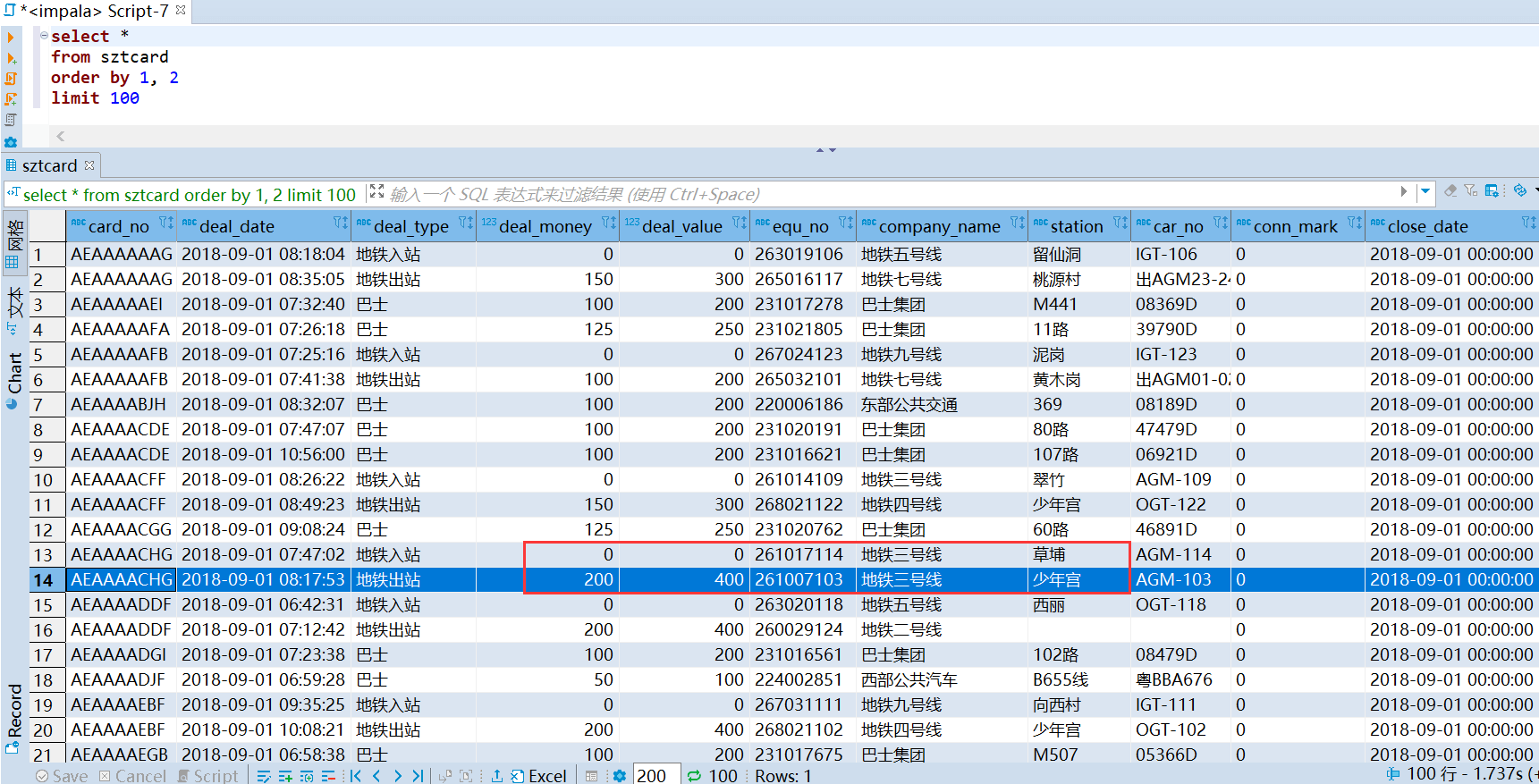

然后再查看一下数据集的日期分布,可以看到 2018-09-01 数据量比较大,但是时间范围只有半天。而 2018-08-31 相比之下数据量非常少,但是时间范围是一整天,后续在做一些时间上的分析,应该注意到这点。
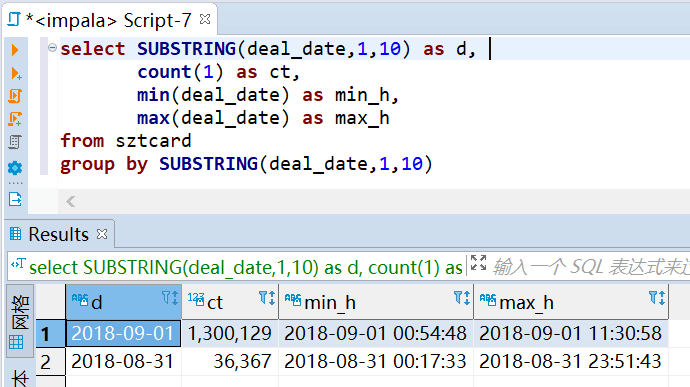
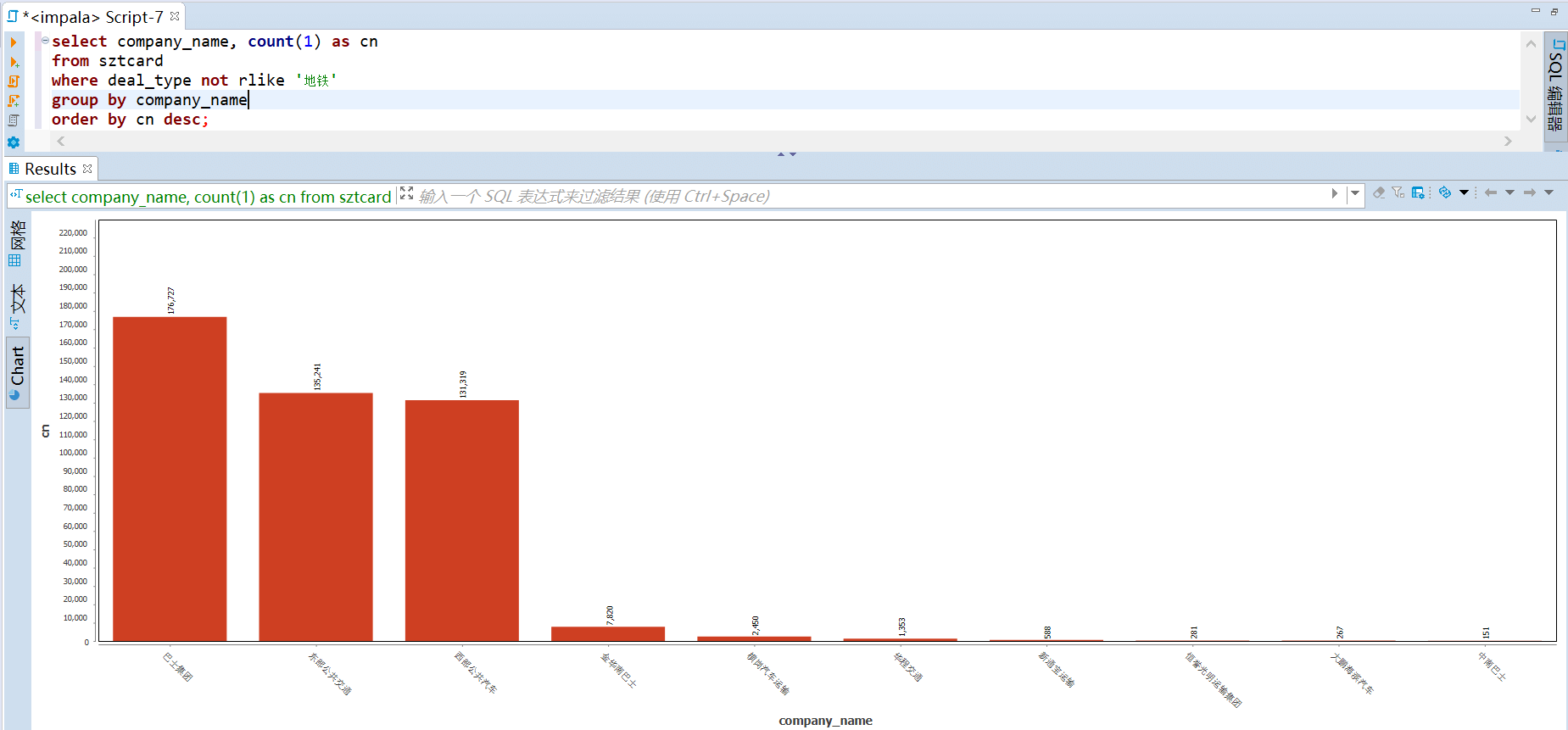
最后在看下公司名称分布情况,没有看到什么 某某便利店之类的名称,可见该数据集并没有商店消费的数据,全部都是交通出行的数据。
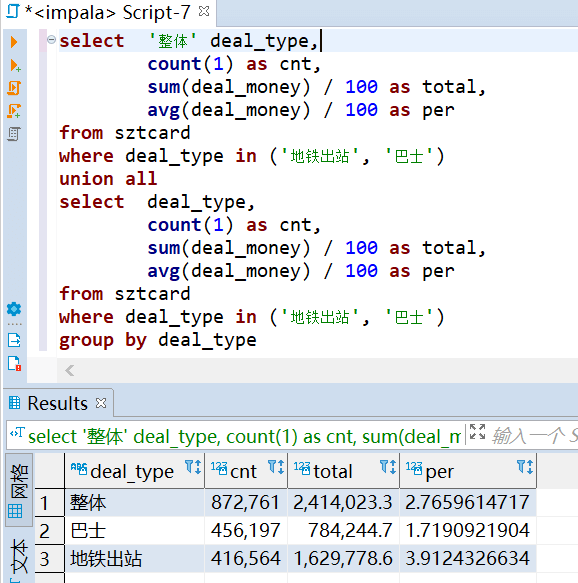
整体的通勤次数为 872,761 人次,总费用为 2,414,023 元,平均每次出行花费 2.76 元。
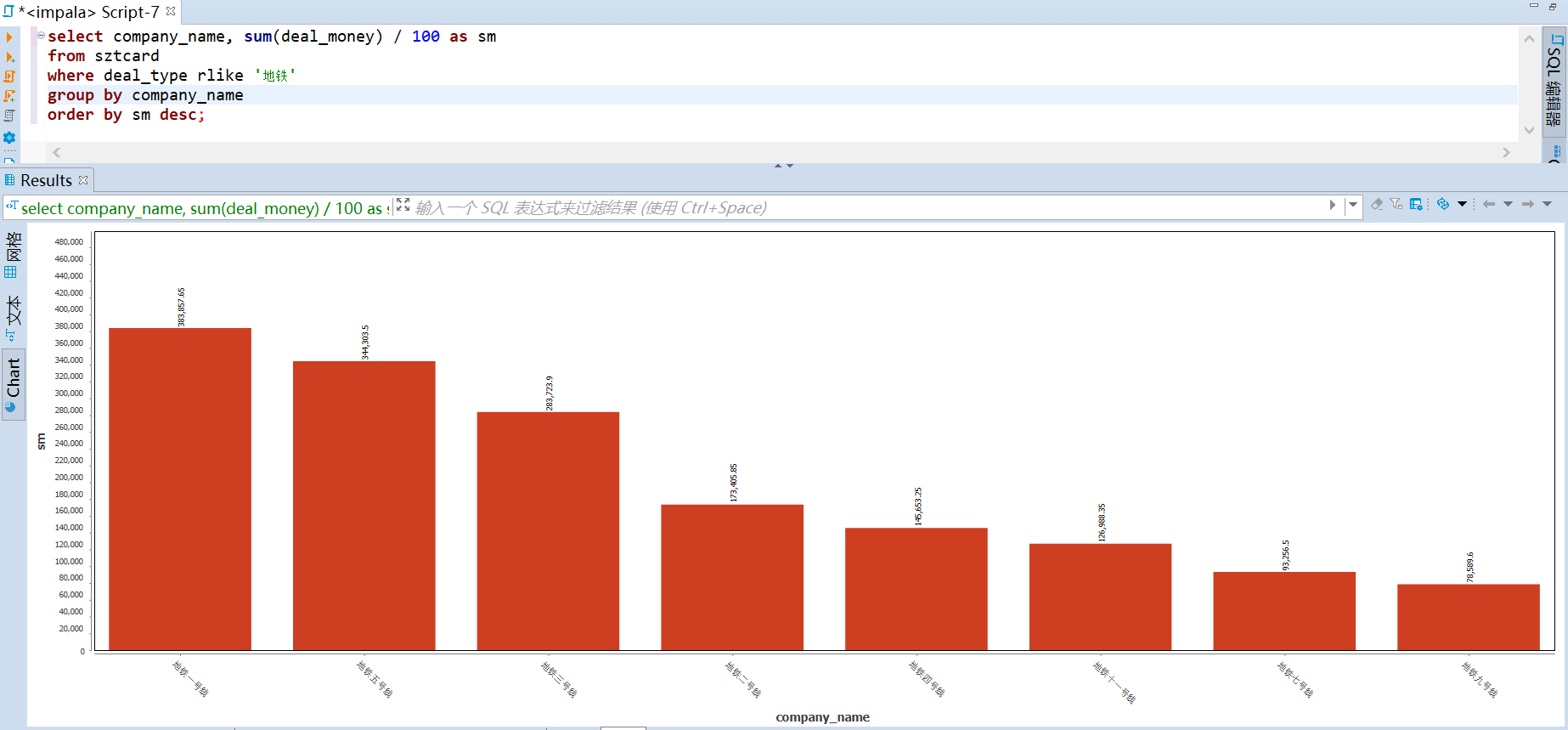
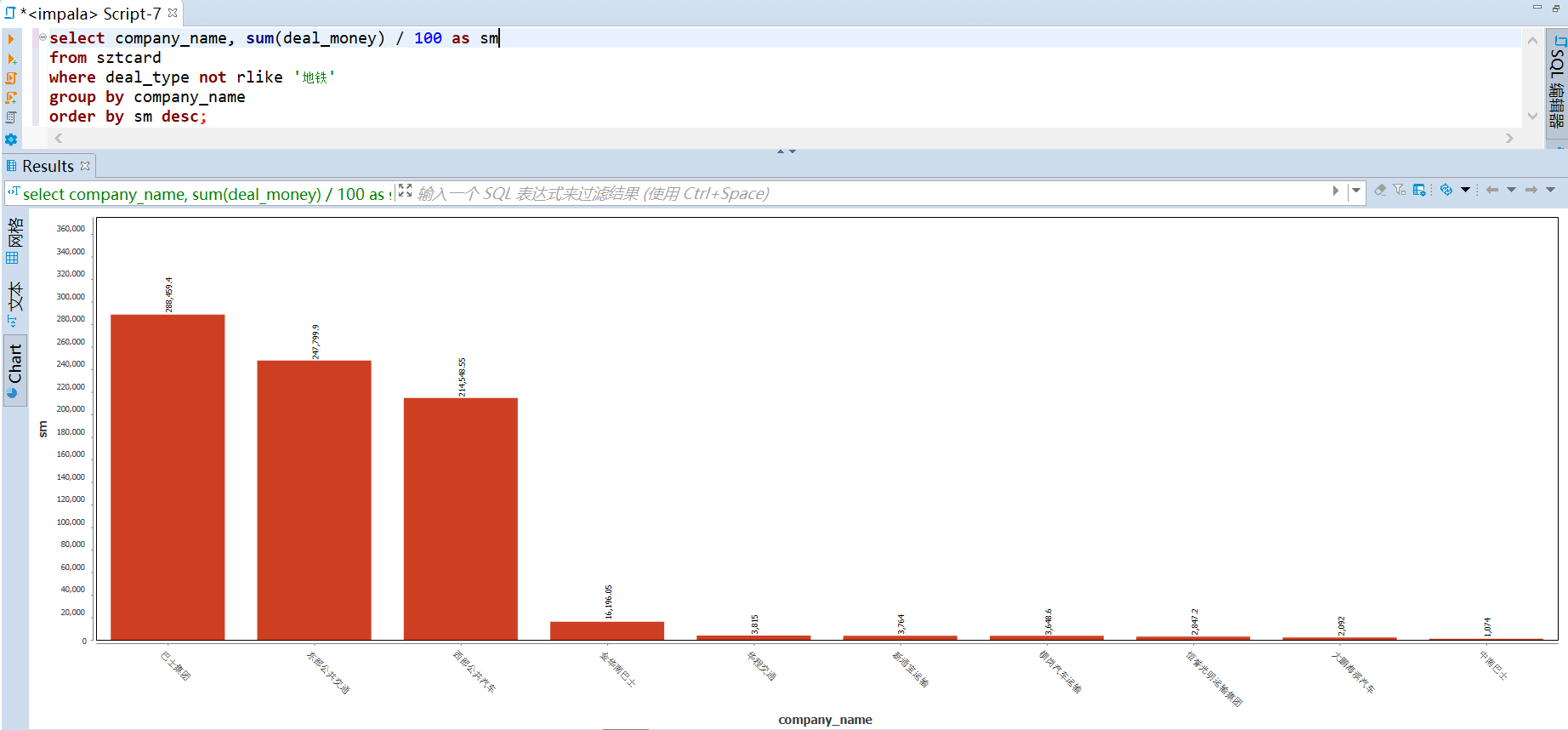
交通工具上来看,坐巴士平均每次为 1.7 元,坐地铁则要 3.9 元。
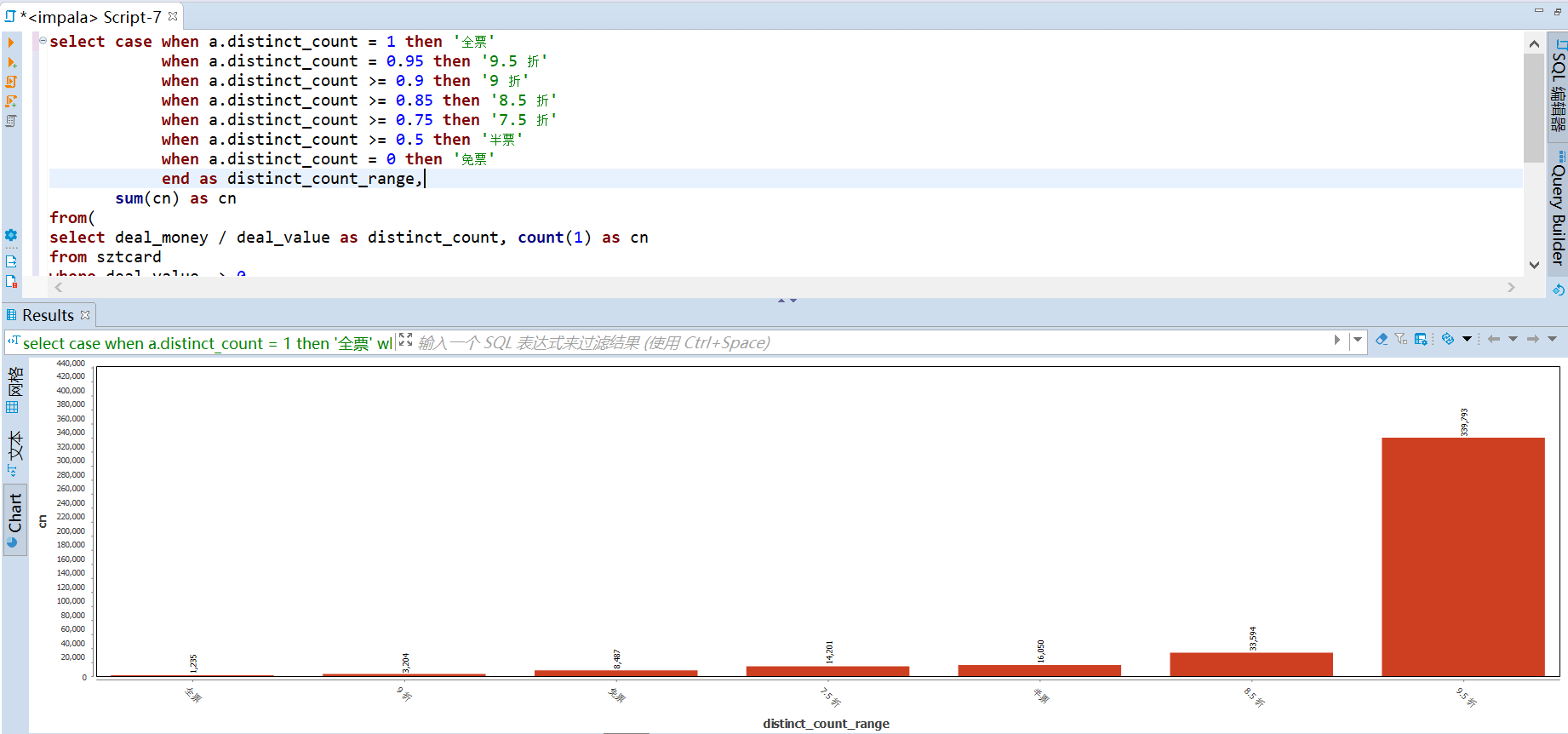
从交通优惠的普及情况来看,受众还是非常广的,只有 1,235 人次是购买的全票,占比仅为千分之一(1,235 / 872,761)。
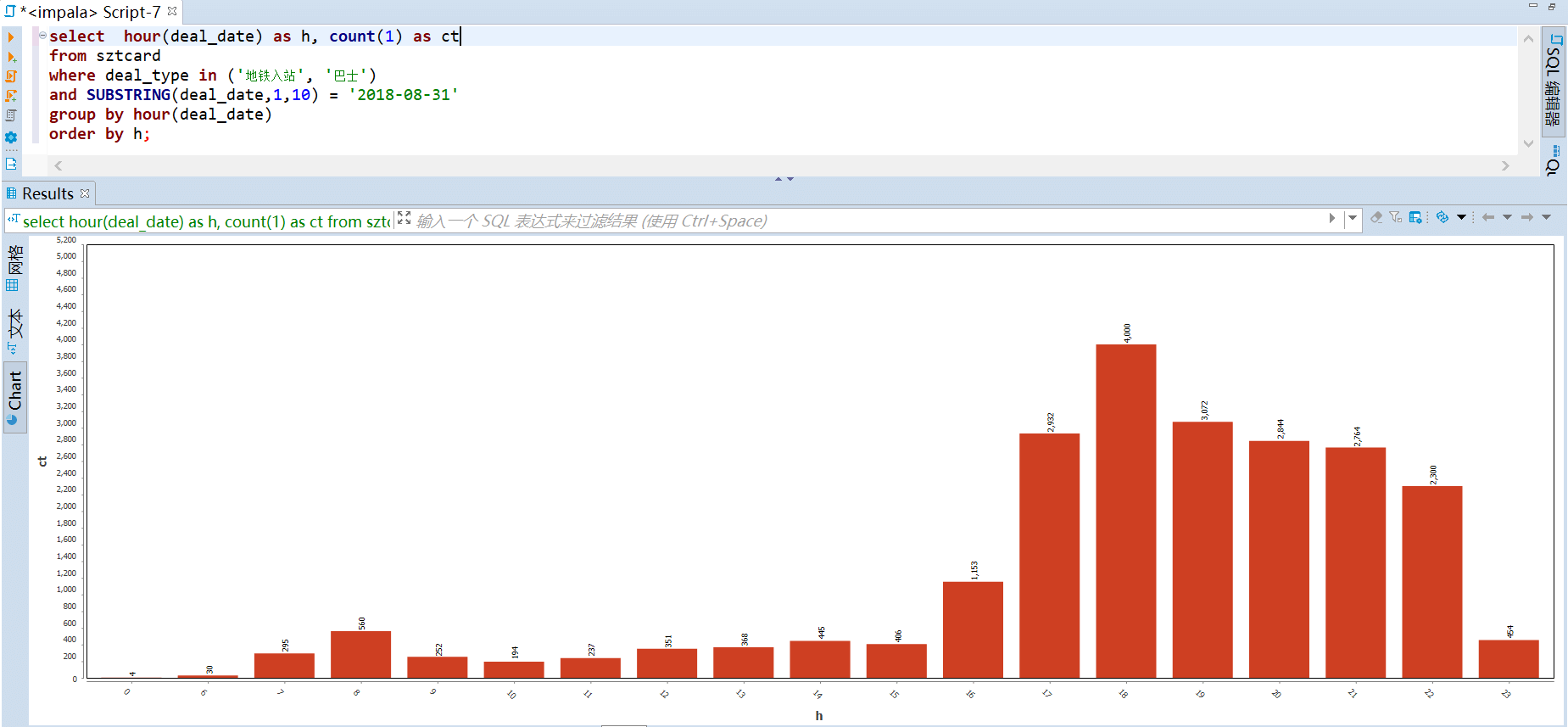
2018-08-31 每小时的出行人次,从中可以看到晚高峰是在 18-19 点之间,早高峰在 8-9 点之间,可能由于数据集本身的不完整,所以早高峰看起来不是很明显。
2018-09-01 每小时的出行人次,从中可以看到早高峰在 8-9 点之间,由于只有半天的数据,所以看不到晚高峰。

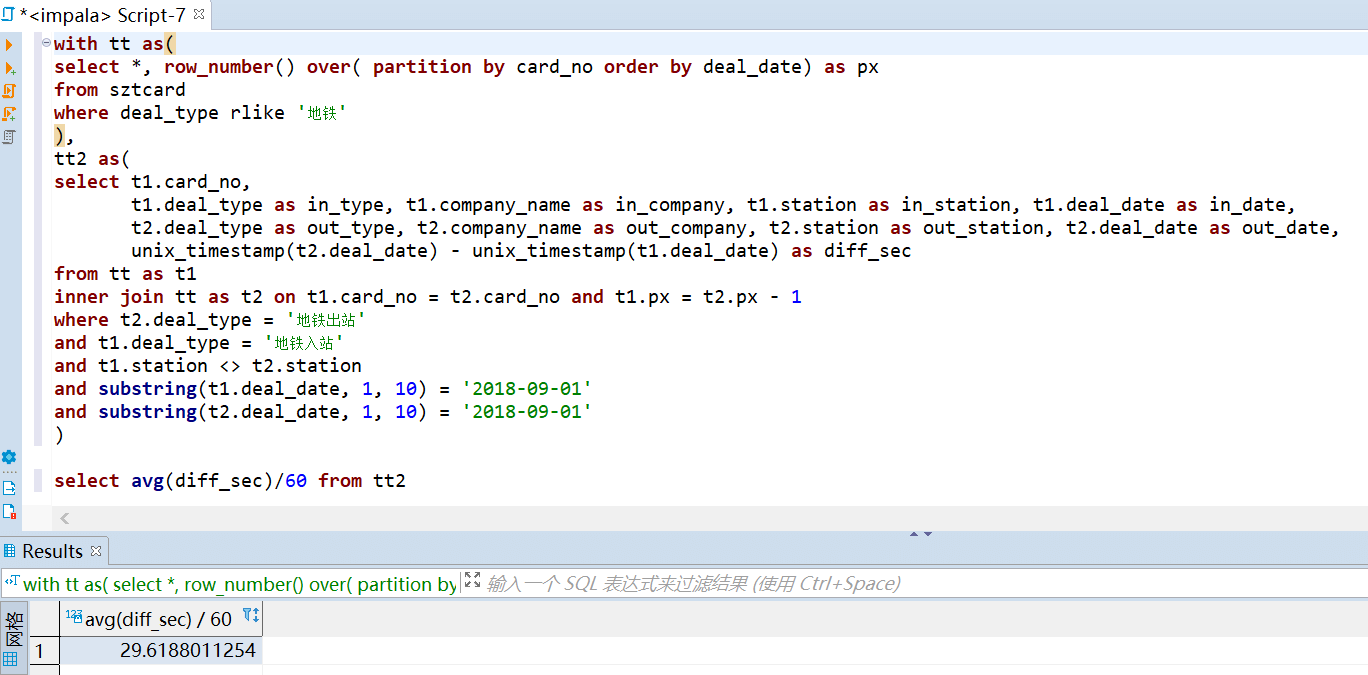
由于地铁是进出站都要刷卡,所以可以通过二者之差来计算地铁的通勤时间。平均通勤时间为 29.6 分钟。
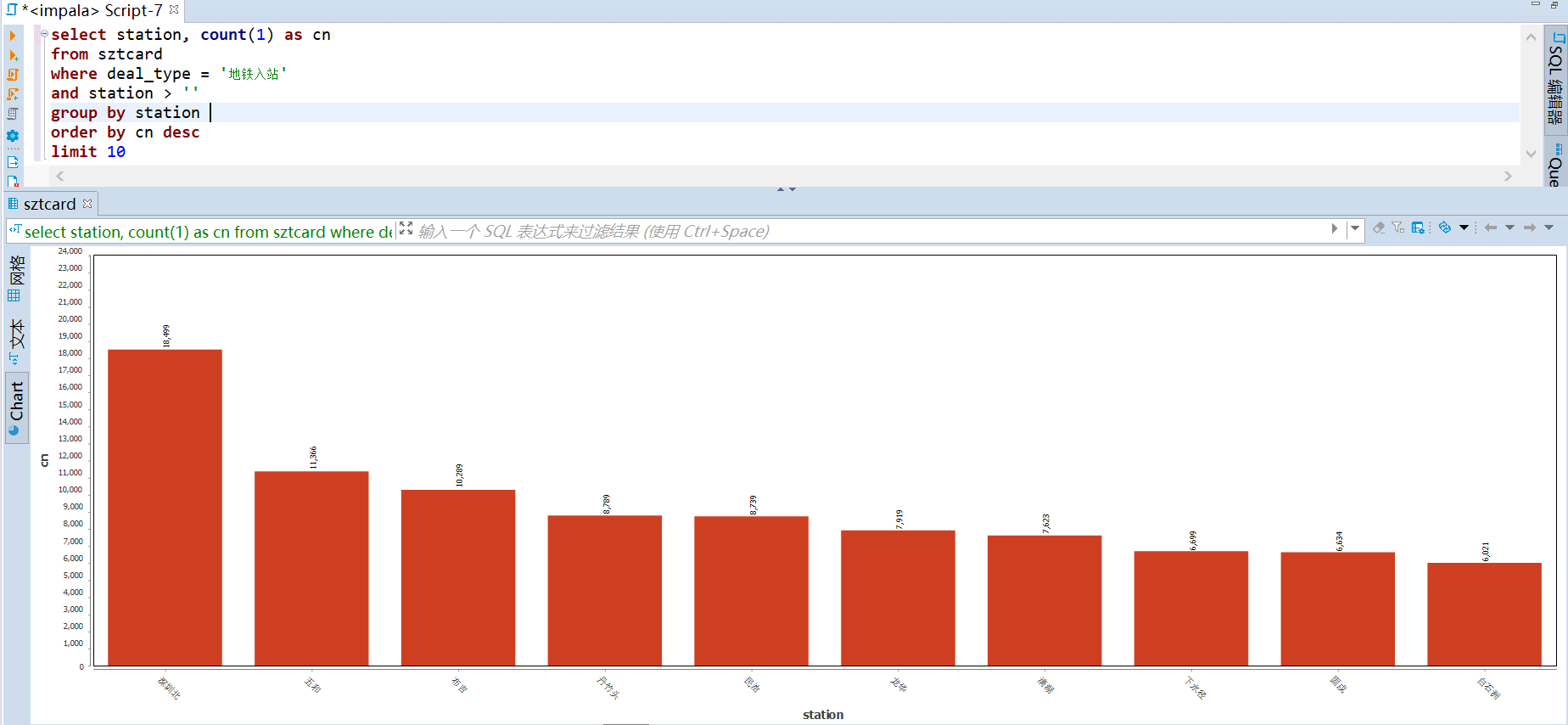
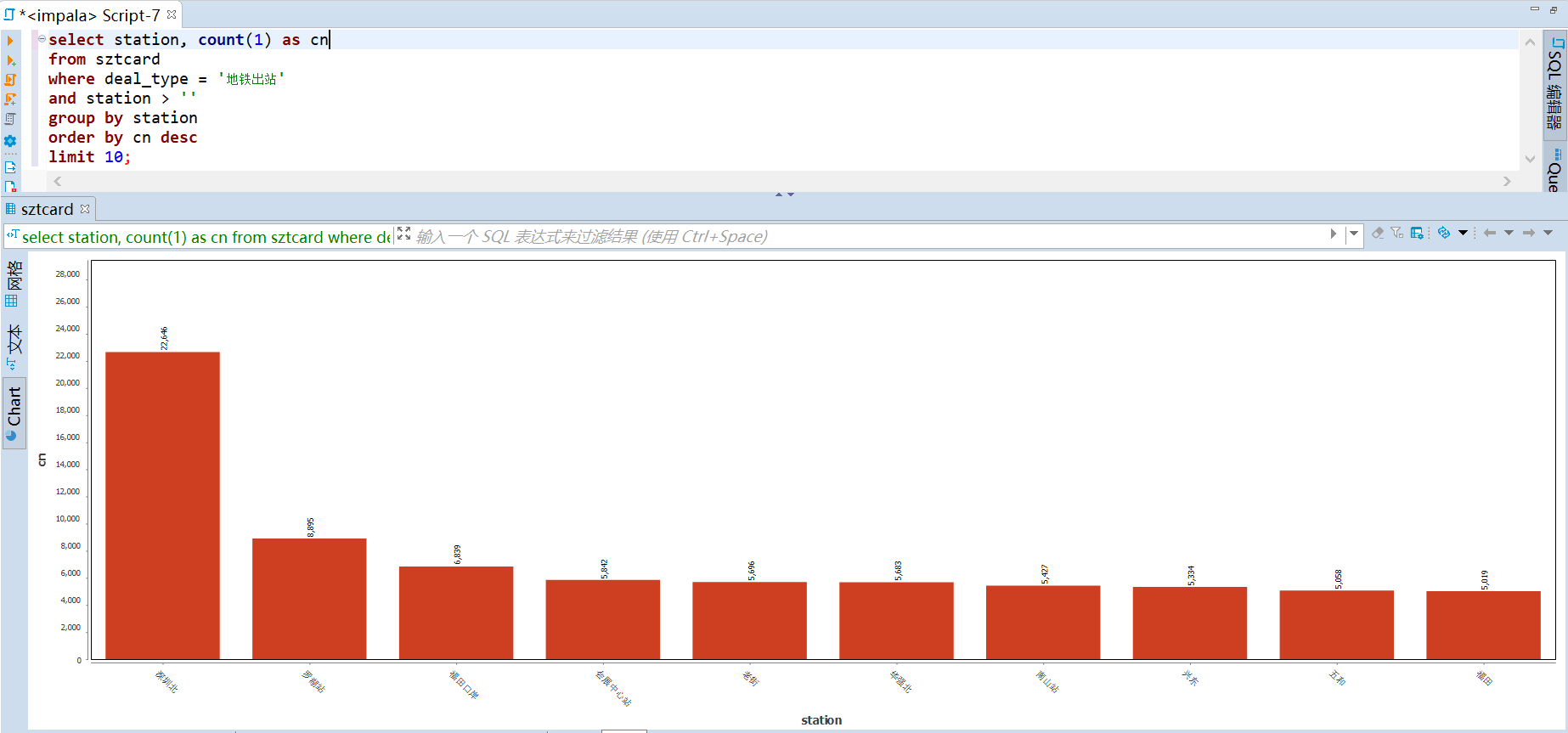
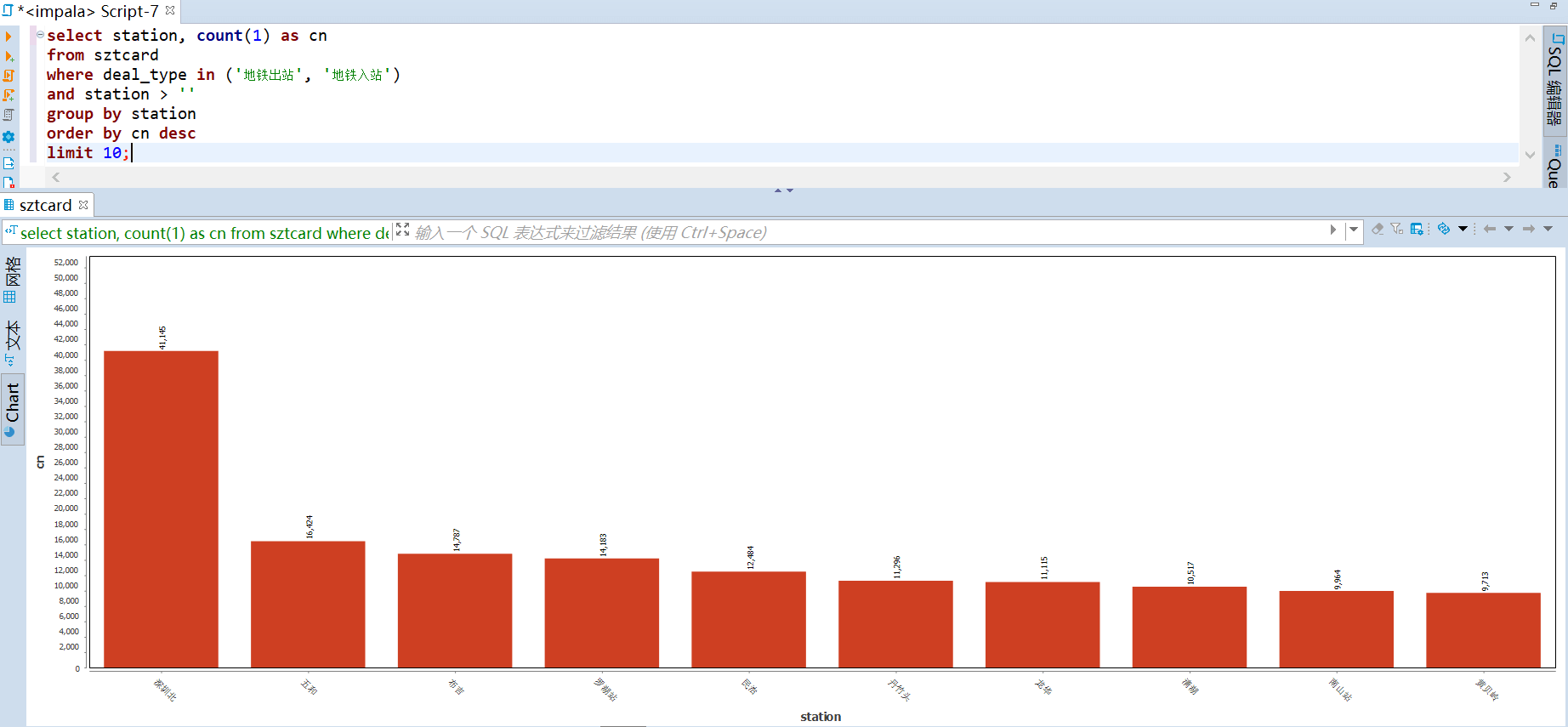
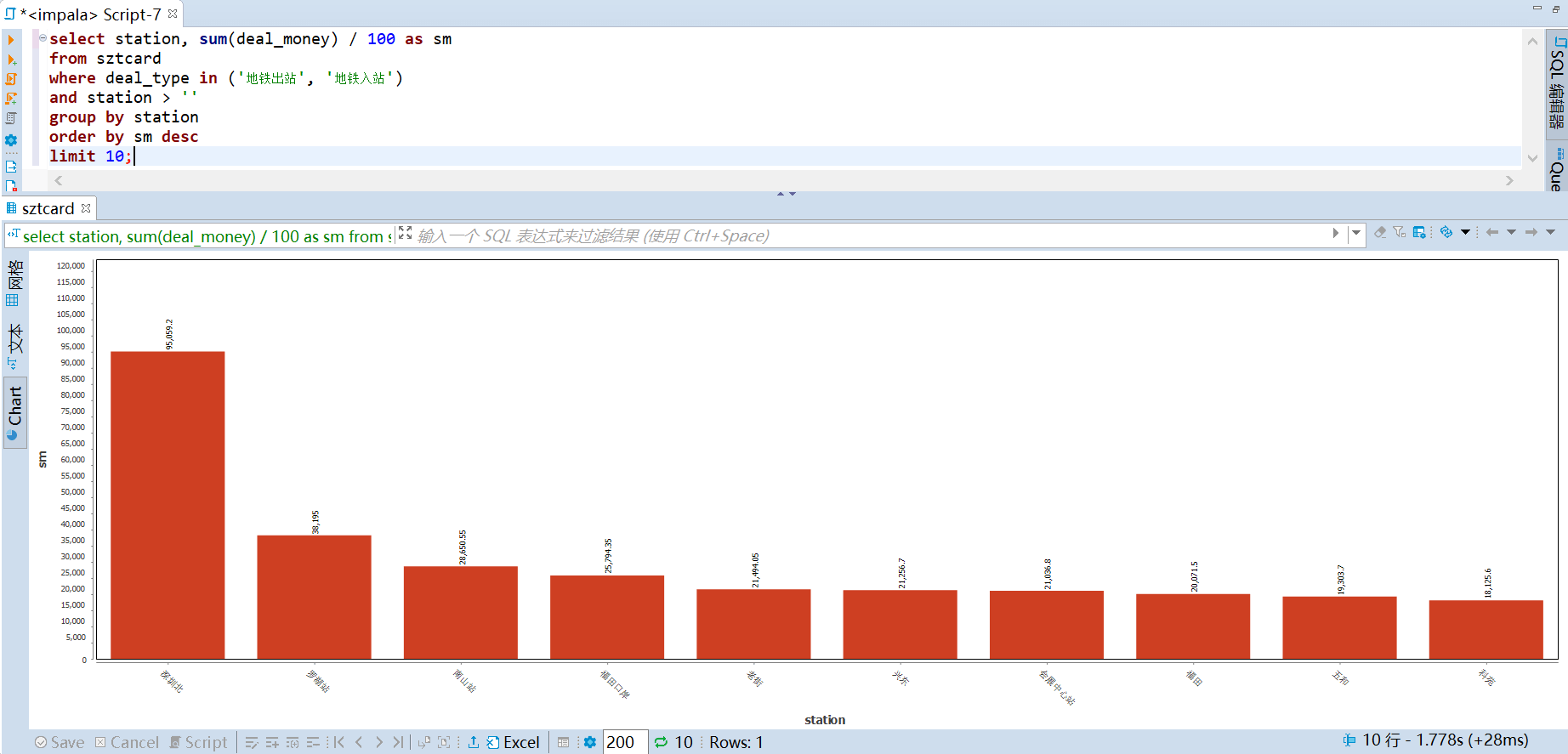
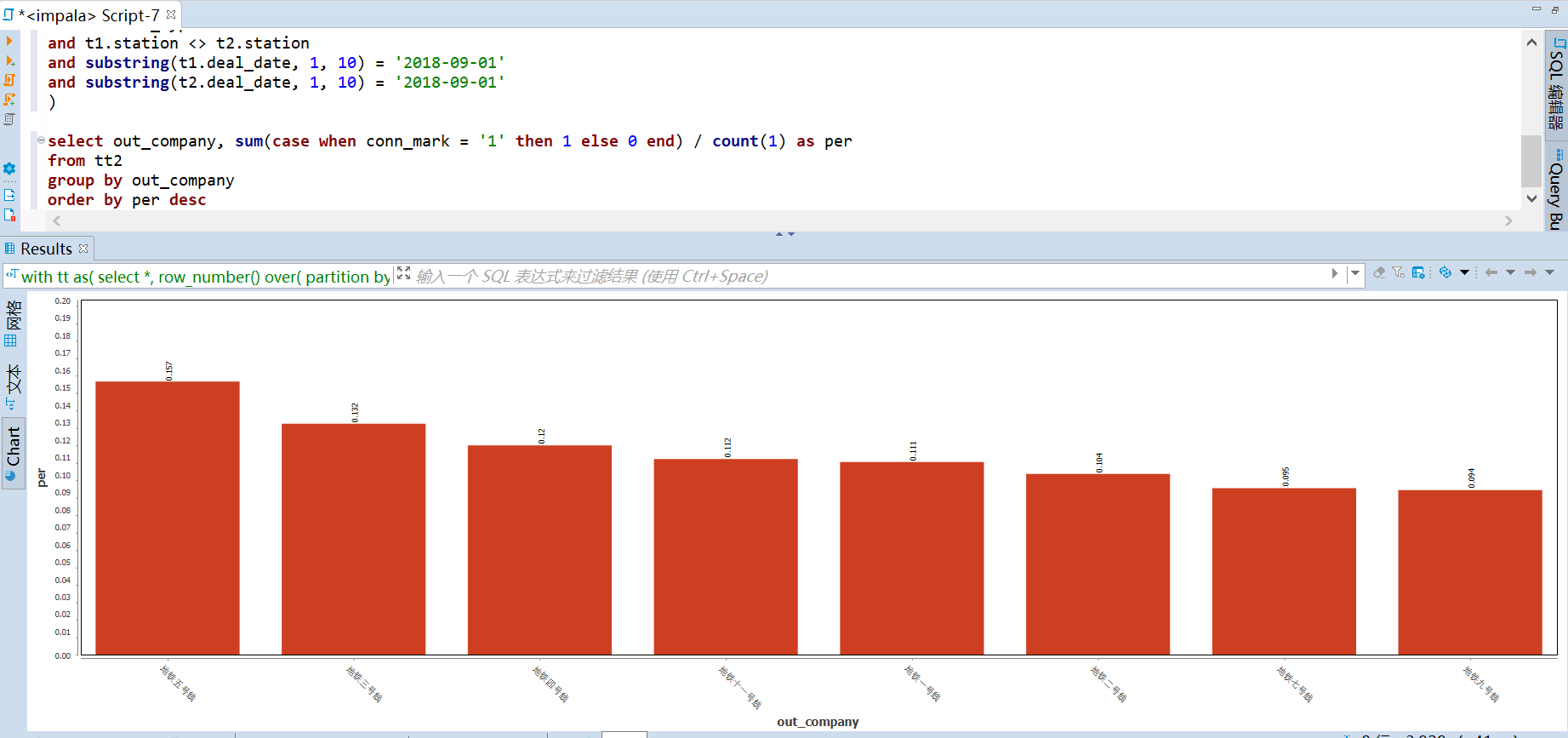
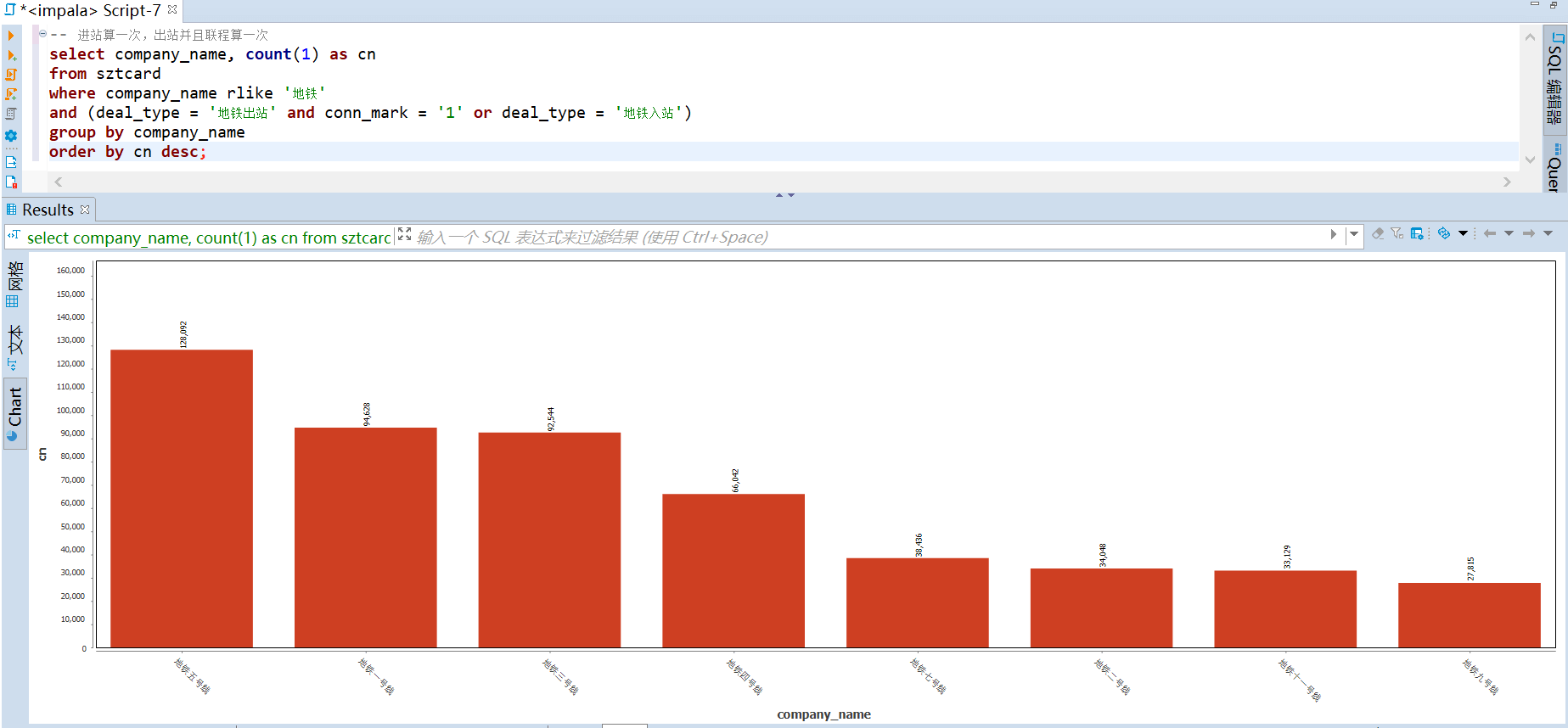
运输贡献度计算规则:进站算一次,出站并且联程算一次。从下图可以看到 五号线的运输贡献度最高,九号线的贡献度最低。
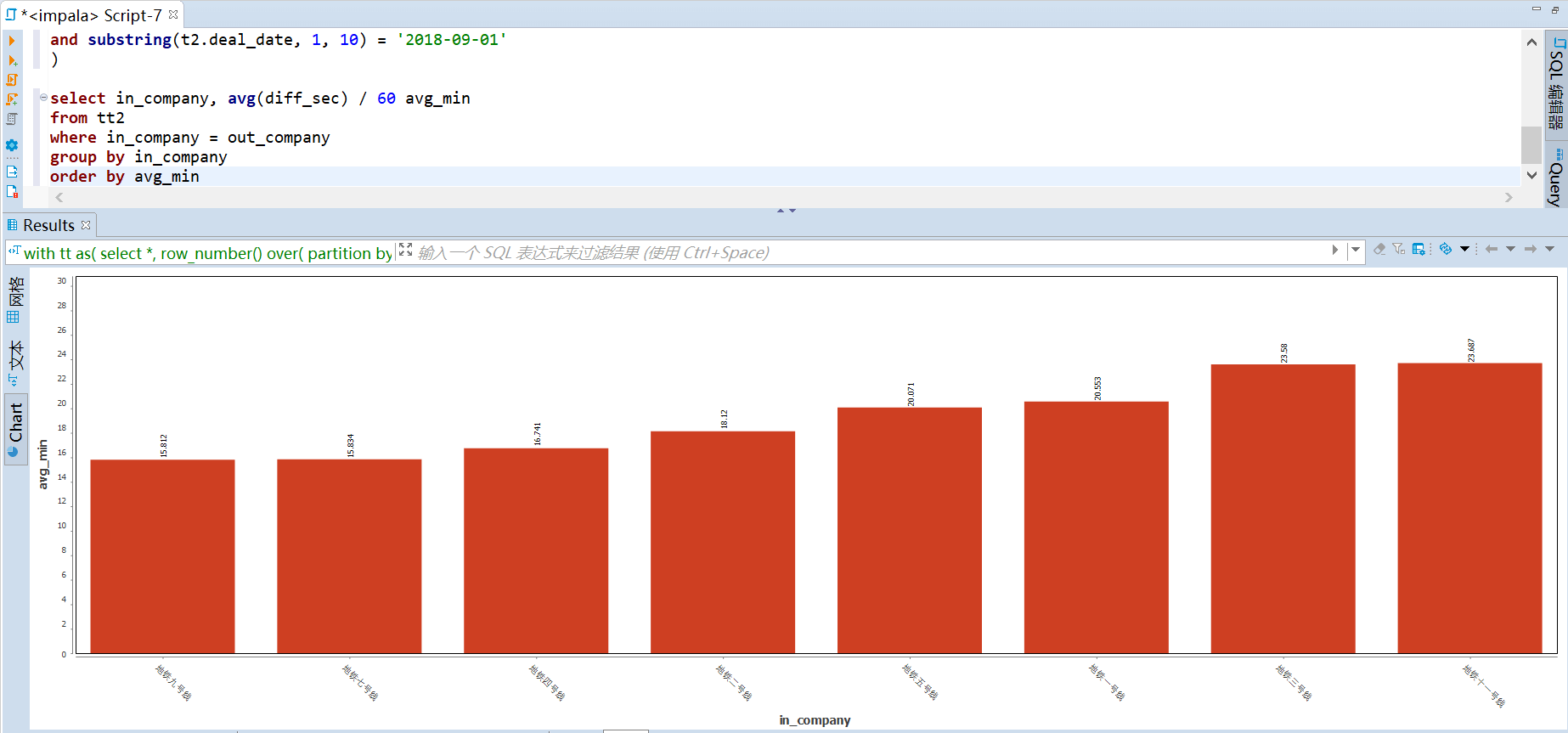
单程直达每乘客的平均通勤时间可以体现运输效率,从下图可以看到,地铁 9 号线的运输效率最高,平均为 15.81 分钟/人次。
从地铁出来后还需要换乘的乘客占比,可以看到 五号线 的换乘比例最高 15.7 %,九号线 换乘比例最低 9.4 %