We present a semantic model evaluation dataset: SimRelUz - a collection of similarity and relatedness scores of word pairs for Uzbek language. The dataset consists of more than a thousand pairs of words carefully selected based on their morphological features, occurrence frequency, semantic relation, as well as annotated by eleven native Uzbek speakers from different age groups and gender. Additionally, we also present a web-based tool to annotate similarity and relatedness scores. We also share the code to generate the scatter-plot to visualize word-pairs in a vector space.
There are many language models that have been created that yield good quality semantic knowledge, yet their evaluation depends on gold standard datasets that have word/concept pairs scored by their semantic relations (such as synonymy, antonymy, meronymy, hypernymy, etc.), that come with cost due to their time-consuming context-generation process and high dependence on human annotators.
Current project aims to present, to our knowledge, the first semantic similarity and relatedness dataset for Uzbek language. Furthermore, this repository includes a publicly-availabel code for the web-based tool created for semantic evaluation annotation.
Feel free to use the dataset and the tool presented in this project, and if you find it useful, plese make sure to cite the paper here (coming soon...) Demo of the web-based annotation tool can be seen here.
Programming language used:
These are the major libraries used inside Python:
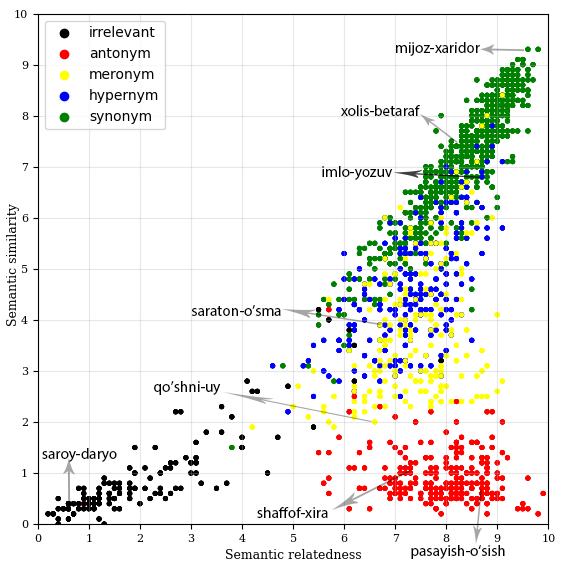
The visual representation of the dataset (word-pairs of database in the vector space) can be seen at the above diagram. The dataset is composed of 1418 word pairs from different word types (nouns, adjectives and verbs), different word forms (root, inflectional, derivational), with different frequencies (high, mid, low frequencies, rare and OOV words), and with diverse pre-established semantic relations (synonym, antonym, meronym, hypernym, not related). All the pairs have two scores, one for semantic similarity, while the other is for semantic relatedness. No field in the dataset was left empty (as was requested from annotators in the guidelines, even for the OOV cases).
More detailed information can be seen in the table below:
| Word classes | Word forms | Word frequencies | |||
|---|---|---|---|---|---|
| Nouns | 1154 | Root form | 995 | High frequency | 1136 |
| Verbs | 351 | Infelctional | 423 | Medium frequency | 448 |
| Adjectives | 457 | Derivational | 544 | Low frequency & OOV | 378 |
| Total number of unique words: 1962 |
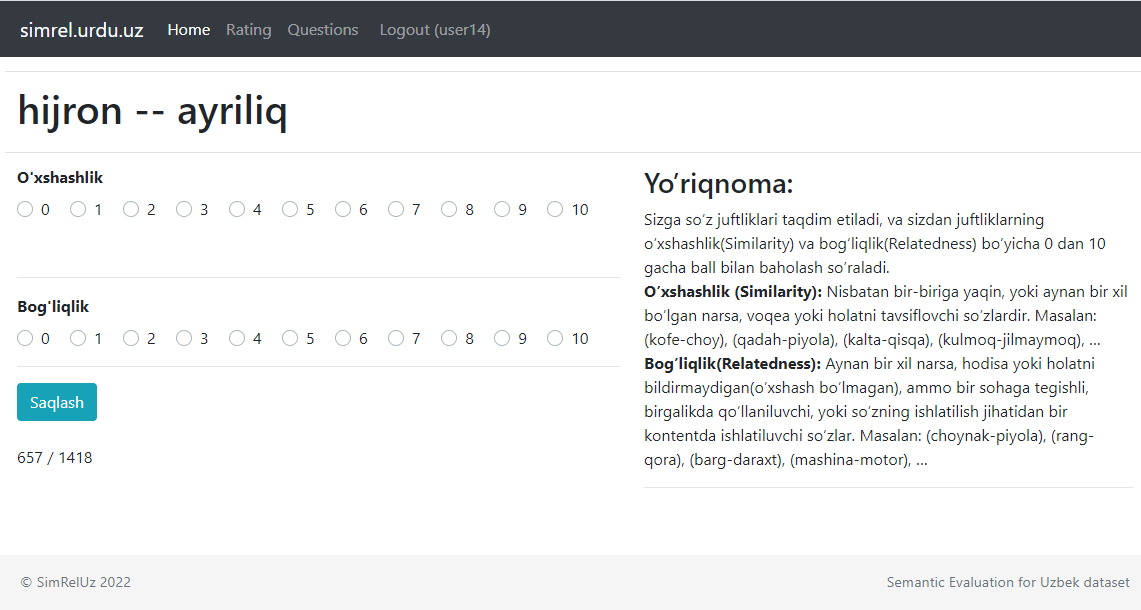
The user-interface of the presented web-based semantic evaluation tool designed for multiple-user annotation can be seen below in this picture:
Distributed under the GNU GENERAL PUBLIC LICENSE. See LICENSE.txt for more information.
We would like to thank the NLP team of the Department of Information Technologies, Urgench State university for their huge help with the annotation.
We are grateful for these resources and tutorials for making this repository possible: